

目 录
一、前言
二、TiDB 集群核心组件可用性概览
1. TiDB Server 的可用性
三、Multi-Raft 集群的可用性限制
1. Raft 简介
2. Raft Group 副本数的选择
3. PD 是单一 Raft Group
4. TiKV 是 Multi-Raft 系统
5. Multi-Raft 集群的可用性限制
四、规划 TiKV Label 以提升 TiKV 集群的可用性
1. TiKV Label 简介
2. Label 相关的 PD 调度策略解读
3. TiKV Label 的规划
4. 使用 Label 的注意事项
五、典型两地三中心跨中心高可用多活容灾备配置
1. 物理服务器主机配置
2. 服务器,机柜,机房,网络要求
3. 两地三中心集群的扩容策略
一、前言
分布式系统的核心理念是让多台服务器协同工作,完成单台服务器无法处理的任务。单点的硬件和网络等都是不可靠的,想要提高硬件的可靠性需要付出大量的成本,因此分布式系统往往通过软件来实现对于硬件的容错,通过软件来保证整体系统的高可靠性。
TiDB 集群中包含了串-并联系统,表决系统等,相对于一般的分布式系统更为复杂,TiDB 中所保存的数据的可用性由诸多因素控制,通过本篇文章的介绍,您可以了解到怎样在给定的资源下设计部署架构以尽可能地提高数据的可用性。
二、TiDB 集群核心组件可用性概览
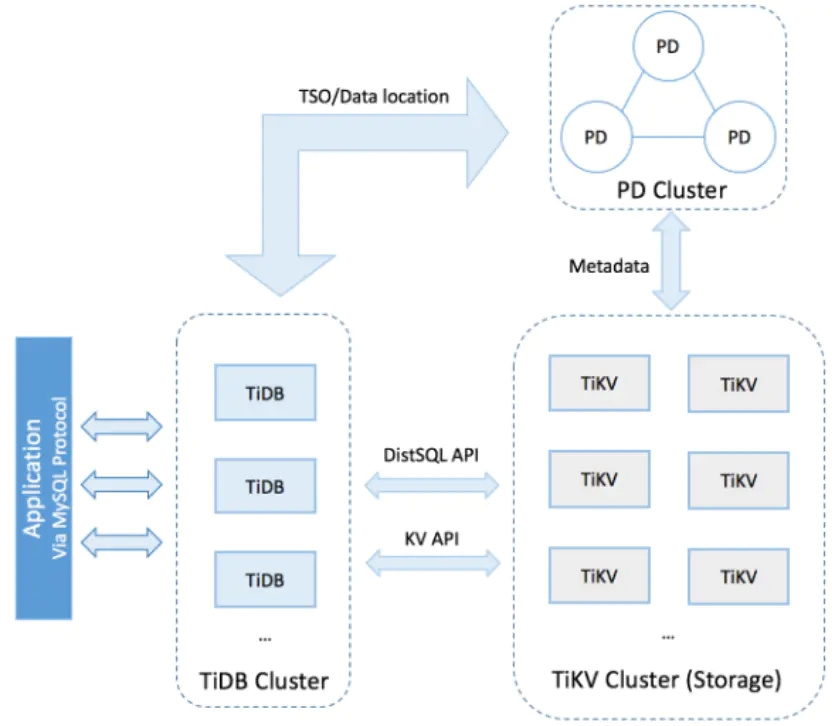
在 TiDB 集群的三个核心组件 PD,TiKV,TiDB 中,PD 和 TiKV 都采用 Raft 协议实现持久化数据的容灾以及自动的故障转移,有关 PD 和 TiKV 的可用性的详细解读,请参见第三章的内容。
1. TiDB Server 的可用性
TiDB Server 组件不涉及数据的持久化,因此 TiDB 被设计成了无状态的,TiDB 进程可以在任意位置被启动,多个 TiDB 之间的关系是对等的,并发的事务通过同一台 TiDB 发送给集群和通过多台 TiDB 发送给集群所表现的行为完全一致。单一 TiDB 的故障只会影响这个 TiDB 上当前的连接,对其他 TiDB 上的连接没有任何影响。
根据用户最佳实践,在 TiDB 之上一般会部署负载均衡器(F5,LVS,HAproxy,Nginx 等),因此负载均衡器所连接的 TiDB 越多,其整体可用性就越高,其整体所能承载的并发请求数量也越多。
在使用负载均衡器的场景下,建议使用的负载均衡算法为 least connection,当某个 TiDB 发生故障依然会导致当时连接到该 TiDB 上的请求失败,负载均衡器识别到 TiDB 的故障之后,将不再向此 TiDB 建立新的连接,而是将新的连接建立到可用的 TiDB 上,以此来实现整体的高可用。
三、Multi-Raft 集群的可用性限制
1. Raft 简介
Raft 是一种分布式一致性算法,在 TiDB 集群的多种组件中,PD 和 TiKV 都通过 Raft 实现了数据的容灾。Raft 的灾难恢复能力通过如下机制实现:
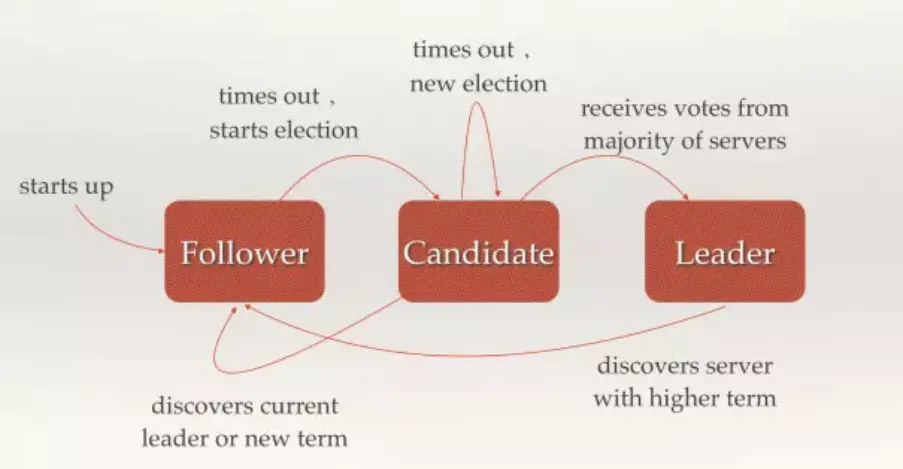
- Raft 成员的本质是日志复制+状态机。Raft 成员之间通过复制日志来实现数据同步;Raft 成员在不同条件下切换自己的成员状态(见下图),其目标是选出 leader 以提供对外服务。
- Raft 是一个表决系统,它遵循多数派协议,在一个 Raft Group 中,某成员获得大多数投票,它的成员状态就会转变为 leader。也就是说,当一个 Raft Group 还保有大多数节点时,它就能够选出 leader 以提供对外服务。
2. Raft Group 副本数的选择
Raft 算法本身以及 TiDB 中的 Raft 实现都没有限制一个 Raft Group 的副本数,这个副本数可以为任意正整数,当副本数为 n 的时候,一个 Raft Group 的可靠性如下:
- 若 n 为奇数,该 Raft Group 可以容忍 (n-1)/2 个副本同时发生故障
- 若 n 为偶数,该 Raft Group 可以容忍 n/2 -1 个副本同时发生故障
我们一般建议将 Raft Group 的副本数设置为奇数,其原因如下:
- 造成存储空间的浪费:3 副本可以容忍 1 副本故障,增加 1 个副本变为 4 副本后,容灾能力维持不变。
- 当副本数为偶数 n 时,如果发生了一个网络隔离,刚好将隔离开的两侧的副本数划分为两个 n/2 副本的话,由于两边都得不到大多数成员,因此都无法选出 leader 提供服务,这个网络隔离将直接导致整体的服务不可用。
- 而当副本数为奇数时,在只发生一个网络隔离的情况中,网络隔离的两侧中总有一侧能分到大多数的成员,可以选出 leader 以提供服务。
在一般的非关键业务场景下,建议将副本数选为 3;而在关键业务中建议将副本数选为 5。
遵循 Raft 可靠性的特点,放到现实场景中:
- 想克服任意 1 台服务器的故障,应至少提供 3 台服务器。
- 想克服任意 1 个机柜的故障,应至少提供 3 个机柜。
- 想克服任意 1 个机房或机房中 1 个楼层的故障,应至少提供 3 个机房或 3 个楼层。
- 想应对任意 1 个城市的灾难场景,应至少规划 3 个城市用于部署。
3. PD 是单一 Raft Group
PD 集群只包含一个 Raft Group,即 PD 集群中 PD 服务的个数决定了 PD 的副本数,3 PD 节点集群的 PD 副本数为 3,5 PD 节点集群的 PD 副本数为 5。
由上一段落中 Raft 原理可知,一个 Raft Group 的容灾能力随节点数增加而加强,在一般的非关键业务场景下,建议部署 3 个 PD;建议在关键业务中部署 5 个 PD。
4. TiKV 是 Multi-Raft 系统
TiKV 是一个 Key-Value 存储系统,它是一个巨大的 Map,TiKV 提供有序遍历方法。下图展示了 region 以 3 副本模式存储在 4 台 TiKV 节点上的数据分布,TiKV 中的数据被切分成了 5 份 —— region 1~5,每个 region 的 3 个副本构成了一个 Raft Group,集群中一共有 5 个 Raft Group,因此 TiKV 是 Multi-Raft 系统。

5. Multi-Raft 集群的可用性限制
如上图所展示,虽然这个集群当前有 4 个 TiKV 实例,但一个 region 的 3 个副本只会被调度到其中 3 个 TiKV 上,也就是说 region 的副本数与 TiKV 实例数量无关,即使将上图的集群扩容到 1000 个 TiKV 实例,它也仍然是一个 3 副本的集群。
前面说到 3 副本的 Raft Group 只能容忍 1 副本故障,当上图的集群被扩容到 1000 个 TiKV 实例时,这个集群依然只能容忍一个 TiKV 实例的故障,2 个 TiKV 实例的故障可能会导致某些 region 丢失多个副本,整个集群的数据也不再完整,访问到这些 region 上的数据的 SQL 请求将会失败。
而 1000 个 TiKV 中同时有两个发生故障的概率是远远高于 3 个 TiKV 中同时有两个发生故障的概率的,也就是说 Multi-Raft 集群在逐步扩容中,其可用性是逐渐降低的。
四、规划 TiKV Label 以提升 TiKV 集群的可用性
1. TiKV Label 简介
TiKV Label 用于描述 TiKV 的位置信息,在 inventory.ini 中,其写法如下:
[tikv_servers]
kv208-1 ansible_host=192.168.2.8 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc1,zone=z1,rack=r1,host=h208"
kv208-2 ansible_host=192.168.2.8 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc1,zone=z1,rack=r1,host=h208"
kv209-1 ansible_host=192.168.2.9 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc1,zone=z1,rack=r1,host=h209"
kv209-2 ansible_host=192.168.2.9 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc1,zone=z1,rack=r1,host=h209"
kv210-1 ansible_host=192.168.2.10 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc1,zone=z2,rack=r2,host=h210"
kv210-2 ansible_host=192.168.2.10 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc1,zone=z2,rack=r2,host=h210"
kv211-1 ansible_host=192.168.2.11 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc1,zone=z2,rack=r2,host=h211"
kv211-2 ansible_host=192.168.2.11 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc1,zone=z2,rack=r2,host=h211"
kv413-1 ansible_host=192.168.41.3 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc2,zone=z3,rack=r3,host=h413"
kv413-2 ansible_host=192.168.41.3 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc2,zone=z3,rack=r3,host=h413"
kv414-1 ansible_host=192.168.41.4 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc2,zone=z3,rack=r3,host=h414"
kv414-2 ansible_host=192.168.41.4 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc2,zone=z3,rack=r3,host=h414"
kv415-1 ansible_host=192.168.41.5 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc2,zone=z4,rack=r4,host=h415"
kv415-2 ansible_host=192.168.41.5 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc2,zone=z4,rack=r4,host=h415"
kv416-1 ansible_host=192.168.41.6 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc2,zone=z4,rack=r4,host=h416"
kv416-2 ansible_host=192.168.41.6 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc2,zone=z4,rack=r4,host=h416"
kv252-1 ansible_host=192.168.25.2 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc3,zone=z5,rack=r5,host=h252"
kv252-2 ansible_host=192.168.25.2 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc3,zone=z5,rack=r5,host=h252"
kv253-1 ansible_host=192.168.25.3 deploy_dir=/tikv1 tikv_port=20171 tikv_status_port=20181 labels="dc=dc3,zone=z5,rack=r5,host=h253"
kv253-2 ansible_host=192.168.25.3 deploy_dir=/tikv2 tikv_port=20172 tikv_status_port=20182 labels="dc=dc3,zone=z5,rack=r5,host=h253"
上面案例中规划了 4 层位置信息的 Label,Label 信息会随着 deploy.yml 或 rolling_update.yml 操作刷新到 TiKV 的启动配置文件中,启动后的 TiKV 会将自己最新的 Label 信息上报给 PD,PD 根据用户登记的 Label 名称(也就是 Label 元信息),结合 TiKV 的拓扑进行 region 副本的最优调度。用户可以根据自己的需要来定制 Label 名称,以及 Label 层级(注意层级有先后顺序),但需要注意 PD 会根据它读到的 Label 名称(含层级关系)去匹配 TiKV 的位置信息,如果 PD 读到的 TiKV Label 信息与 PD 中设置的 Label 名称不匹配的话,就不会按用户设定的方式进行副本调度。Label 名称的设置方法如下,在初次启动集群时,PD 会读取 inventory.ini 中的设置:
[pd_servers:vars]
location_labels = ["dc","zone","rack","host"]
非初次启动的集群,需要使用 pd-ctl 工具进行 Label 名称设置:
tidb-ansible/resource/bin/pd-ctl -u "http://192.168.2.6:2379"
config set location-labels dc,zone,rack,host
2. Label 相关的 PD 调度策略解读
从本质上来说,Label 系统是一种 PD 对 region 副本(replica)的隔离调度策略。
PD 首先读取到集群的 region 副本数信息*,假定副本数为 5。PD 将所有 TiKV 汇报给它的 Label 信息进行汇总(以本章第 1 小节的 TiKV 集群为例),PD 构建了整个 TiKV 集群的拓扑,其逻辑如下图所示:
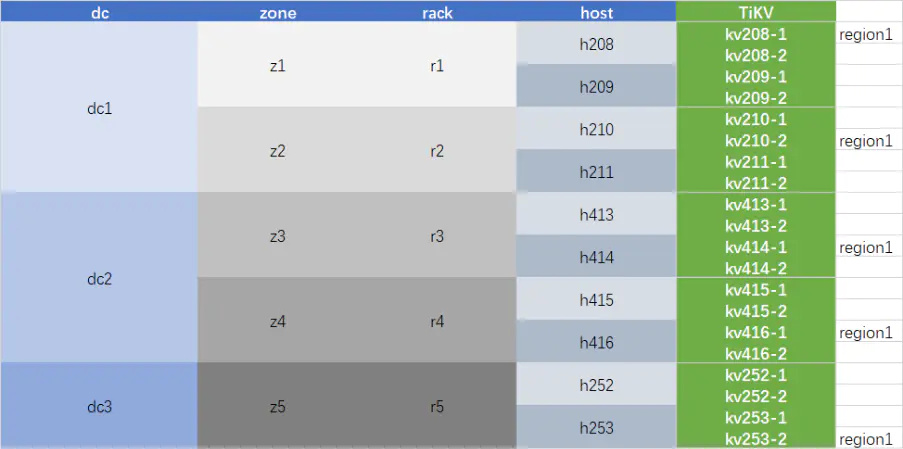
PD 识别到第一层 Label - dc 有 3 个不同的值,无法在本层实现 5 副本的隔离。PD 进而判断第二层 Label - zone,本层有 z1~z5 这 5 个 zone,可以实现 5 副本的隔离调度,PD 会将各个 region 的 5 个副本依次调度到 z1~z5 中,因此 z1~z5 各自所对应的 4 个 TiKV 所承载的 region 数量总和应完全一致。此时,PD 的常规调度策略,如 balance-region,hot-region 等 region 相关的 scheduler 将严格遵守 Label 的隔离策略进行调度,在带有 z1~z5 Label 信息的 TiKV 尚在的情况下不会将同一个 region 的多个副本调度到同一个 zone 中。如图,图中将 TiKV 按照 zone 做 4 个一组隔离开了,一个 region 的一个副本只会在本 zone 的 4 个 TiKV 之间调度。
PD 天生不会将同一个 region 的多个副本调度到同一个 TiKV 实例上,增加 Label 信息后,PD 不会将同一个 region 的多个副本调度到同一个 host 上,以避免单台服务器的宕机导致丢失多个副本。

当带有某一个 zone Label 的 TiKV 全部故障时,如图中所有带有 z5 Label 的几个 TiKV 实例 kv252-1,kv252-2,kv253-1,kv253-2 同时故障时,集群会进入缺失一个副本的状态,在达到 TiKV 最大离线时间的设置值(max-store-down-time,默认值 30min)之后,PD 便开始在其他 4 个 zone 中补全所有缺失副本的 region,同时遵循上面一段所提到的约束,在为 region1 补全副本时,PD 会避开所有包含 region1 的服务器(本例中的 host)h208,h210,h414,h416 所涉及的 8 个 TiKV 实例,而在另外 8 个 TiKV 实例中挑选一个进行副本补全调度。
*副本数设置方法如下,以 5 副本为例:
tidb-ansible/resource/bin/pd-ctl -i -u "http://192.168.2.6:2379"
config set max-replicas 5
3. TiKV Label 的规划
Label 登记的是 TiKV 的物理位置信息,PD 根据 TiKV 的物理位置进行最优调度,其目的是在具有相近物理位置的 TiKV 上只放置一个副本,以尽可能的提高 TiKV 集群的可用性。举个例子,假设某一时刻集群中一定要有两个 TiKV 同时发生故障,那么你一定不想它们上面存储着一个 region 的两个副本,而通过合理规划让同时故障的两个 TiKV 出现在同一个隔离区的概率变高,TiKV 集群的整体可用性也就越高。因此 Label 规划要与 TiKV 物理位置规划一起进行,两者是相辅相成的。
举例而言,机房可能会由于电源故障,空调故障,网络故障,火灾,自然灾害等原因而整体不可用;机柜可能由于交换机故障,UPS 故障,消防喷淋等原因而整体不可用;服务器可能由于常见的内存等故障而宕机。通过妥善的 Label 规划,使 region 调度按物理位置进行隔离,可以有效地降低一个区域故障造成的整体影响。
物理位置的层级结构一般为机房,机柜,服务器,在大型基础设施中还会在机房与机柜之间多一个楼层信息。设计 Label 层级结构的最佳实践是基于物理层级结构再加上一层逻辑层级,该逻辑层级专门用于控制保持与集群副本数一致,在本案例中,zone 就是逻辑层级,该层级的值在集群搭建初期与 rack 保持一一对应,用于控制副本的隔离。而不直接采用 dc,rack,host 三层 Label 结构的原因是考虑到将来可能发生 rack 的扩容(假设新扩容的 rack 编号是 r6,r7,r8,r9,r10),这个扩容会导致 rack 数变多,当多个 TiKV 实例同时发生故障时,这些故障的 TiKV 出现在在多个 rack 上的概率也会增加,也就是会将第三章提到的 Multi-Raft 集群的可用性随节点数增加而下降问题再次引入到集群中。而通过使用逻辑层级 zone 保持与副本数一致可以将多个故障的 TiKV 出现在不同的隔离区(本例中的 zone)的概率降至最低,将来扩容 rack 也可以充分的利用到更多的 rack 的物理隔离来提高可用性。
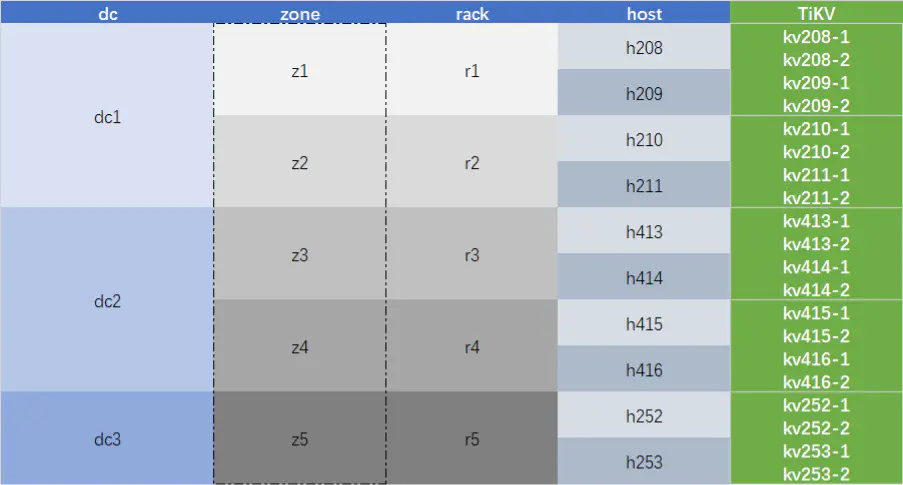
4. 使用 Label 的注意事项
在使用了 Label 隔离的集群中,存在以下限制:
- 假定所有的 TiKV 实例都使用同款磁盘,存储容量是一样的,那么所规划的 TiKV 总体数目必须是 region 副本数(max-replicas)的整数倍。
- 集群存储容量的上限为存储空间最低的隔离区(上例中的 zone),即存在木桶效应,因此应该对每个隔离区规划完全一致的容量。
- 扩容时也需要对每个隔离区进行容量一致的扩容。
- 除逻辑层级(上例中的 zone)之外,其他层级必须是真实物理隔离的,假设有一台服务器上部署了 5 个 TiKV 实例,在规划 Label 时通过虚假的 rack 和 host 信息将这 5 个实例分配到了 5 个隔离区,这台服务器就可能会承载某个 region 的多个副本,这台服务器的宕机就会导致数据丢失,这有违规划 Label 以提高可用性的目标。
五、典型两地三中心跨中心高可用多活容灾备配置
1. 物理服务器主机配置
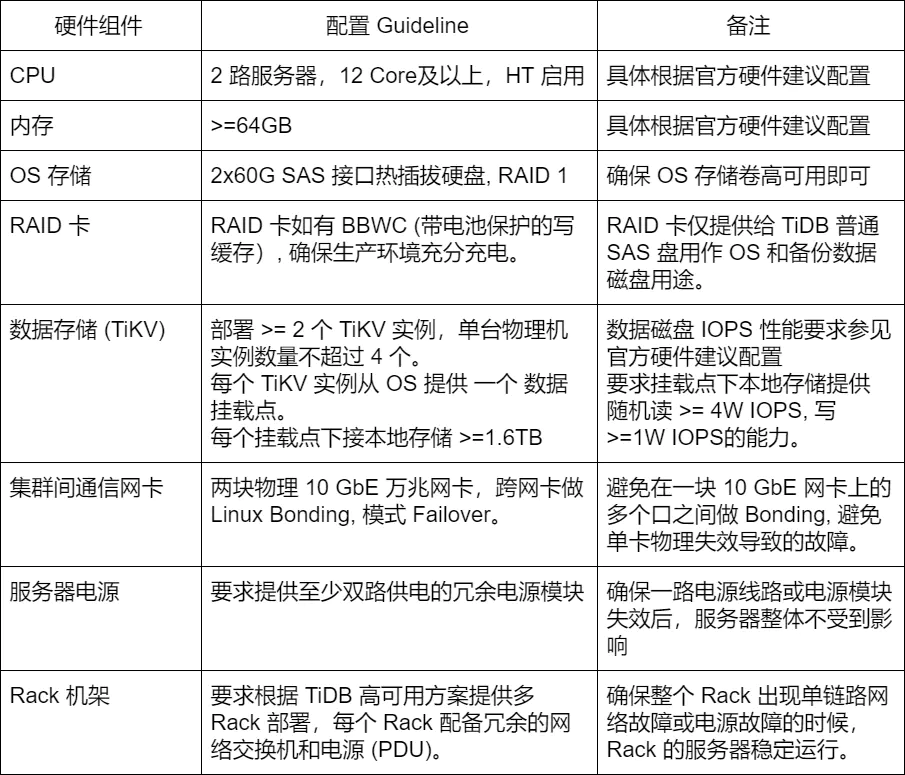
2. 服务器,机柜,机房,网络要求
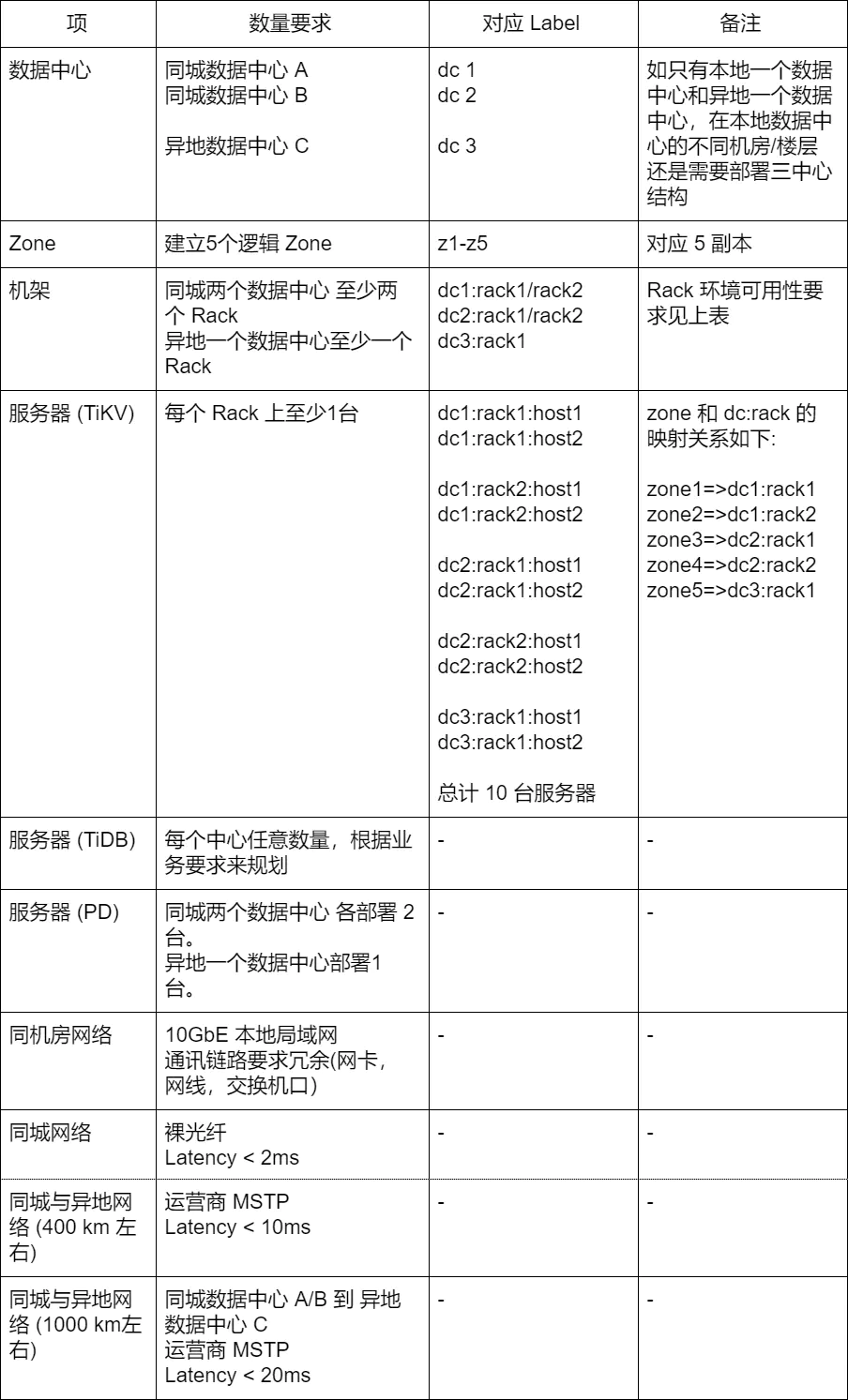
3. 两地三中心集群的扩容策略
规划了 Label 的集群再扩容时需要对每个隔离区进行容量一致的扩容,在本章的案例中,隔离区为 dc 和 rack 标示的位置,因此需要对每种 dc+rack 组合的区域进行容量一致的扩容,比如将要扩容 5 台 TiKV 服务器,其分配方法如下:
zone1=>dc1:rack1 增加一台 TiKV
zone2=>dc1:rack2 增加一台 TiKV
zone3=>dc2:rack1 增加一台 TiKV
zone4=>dc2:rack2 增加一台 TiKV
zone5=>dc3:rack1 增加一台 TiKV**