

我今天分享的内容高度融合了很多跟 TiDB 相关内容。其实我在积极地助力 TiDB 在贝壳找房落地,因为我发现一个特点,如果我说开源解决方案很多,比如四层建模,都是离线 T+1,但很多需求是实时的。在这种情况下如果用服务链条、Spark、 Doris 等新技术,我会发现建模很耗精力,还是需要做一套解决方案把所有数据放在一起,并且应用在场景下,做出真正的数据挖掘层次。我现在所处的场景,不是 TiDB 的主攻场景,比如替换 MySQL 集群等,而因为我既是数据的使用方,也是数据的建设方,同时还是数据运维方,都是我的团队负责。这时候我就发现一个问题,既然大数据需要很多解决方案,怎么 All in?All in 哪个产品?目前我们的解决方式有 Flink、Spark、Kylin,TiDB 更向前——用在接入层,解决一切应用的场景。
这是 TiDB SQL 的解析过程。不论是什么产品,一旦到 SQL(也就是到底层)你会发现,所有的产品都非常的相似,都会经历解析-语法解析-语义解析-执行计划-逻辑计划。那么 TiDB 基于什么呢?基于很多 statistics 和 organizer 做优化器迭代。其实我个人认为,这个时代站在了很多巨人的肩膀上,可以少走弯路。Oracle 早年前是 RBO,基于规则必须走索引,否则就报错。后来发现,走索引不是最对的,才有优化器。TiDB SQL 解析过程当中,在生成物理执行计划时候,会收集所有统计信息反馈,并反补下一次解析,形成逐渐迭代的过程。所以我强烈推荐大家在实际的生产过程中,把 SQL 解析的每个步骤打成系列。

执行计划每一步怎么走,如何优化,优化的过程怎样,主要是看 Prior Organizer。整个优化器怎么去做,SQL 返回来之后如何解析、验证、调度,这是在 TiDB 分布式环节必须要有的。给大家一个结论参考:所有的开源圈当中,大家都在玩命迭代开发,实现客户的吐槽,自己变得更健壮。那么我其实强烈建议大家可以向一些优秀的产品靠一下,看一看 Oracle 怎么走。Oracle 其实走的是很前沿的,它完全是运营商级别的,大国企不允许出错。Oracle 有个特别厉害的地方,SQL 全部量化到统计信息、模型和反馈,所有参数级的调度,都到底层 Trace,包 Dtrace 和跟踪。TiDB 也是基于统计信息反馈迭代,这是一样的。
我一次性罗列了一些 SQL 常见问题和解决办法。比较常见的有 order by + limit,如果数据过多不可能全部打出来,我一定会做排序或者加 limit 模型。这里面有很多问题,比如 SQL 语句不加 limit 时候走索引,加 limit 的时候走 table。这个当然是一些 bugs,不应该从下面执行。TiDB 好就好在它不停迭代,row count 不准确这个问题已经在 3.0.0 rc1 中修复了。在这里对开源社区有个建议,当你发现一个问题很痛苦,困扰你很久的时,不要闷着,直接在社区里问有没有新版本可以修复,如果能直接打 fix 就好了。我个人认为产品没有完美的,但是解决方案一定有一个最适合你的,也给原厂一些时间迭代。
SQL 较简单时执行计划不准确,选错索引、不走索引,或者执行计划不稳定非常令人头疼,应该以预防为主。这种问题出现的原因可能有:统计信息过旧、query feedback 调整统计信息幅度过大(2.1.5 已修复)、直方图信息不准确、CMSketch 信息不准确。这些都是基于统计信息驱动的执行计划生成,我们应该在预演中多跑跑,在跑稳之后再上核心业务,预防出现峰值现场。
还有 SQL支持不完善的地方,比如说 where 条件与列数据不一致时存在执行计划不符合预期的地方。这个如果类比一下 Oracle,相当于引式转换,各种结构不一样导致信息对不上。解决这个问题我们试了很多方式,比如说和开发小伙伴沟通,让他们的理论跟我们一致,最后发现其实真正在互联网圈高频迭代的情况下很难落地。最后,我们尝试过一次性 SQL 代码审核总查改写,提交代码之后,我再用机器方式,改你的代码。还有标量子查询执行缓慢;count(*) 的时候可以走索引,但是走的扫描全表;执行结果不稳定,结果出错。
最后总结一下问题,CBO (Cost Based Organizer)模型基于成本,只要基于成本就有统计信息。如果 cost 模型的估算值不准确,比如数据量估算不准确、开销计算不准确、代价估算过高或过低,都可能导致问题。统计信息不准确,包括统计信息过期、pseudo 统计信息、直方图信息、CMSketch、多列关系选择性、query feedback。还有一些功能不完善的问题,比如函数索引、函数下推、逆序索引、multi-index scan。目前 TiDB 有一个非常优秀的优化层,SQL 优化小伙伴在不断迭代,我也希望大家可以和原厂一起迭代。

展开几个焦点,统计信息是基于 CPU 来做的,所以 TiDB 优化器根据统计信息来选择最优的执行计划。我列了几个参数,大家可以关注一下,比如说系统级的统计信息 tidb_auto_analyze_ratio,默认值 0.5,是自动更新的阈值。大家知道,一旦数据量过大,统计信息采集就非常耗资源。但是这些参数适不适你,是需要根据具体的业务场景调试的。比如说你做快递行业的,收件、快递只能晚上去派发,所以高峰期可能是在夜间。还有一些参数,下面都有对应的值,大家可以去参照设计。自动统计信息收集方面,TiDB是 60 秒,如果 60 秒内这个表没有别的修改,就不采集,这是符合我们以尽量少的代价去对表进行采集的规则的。当然横向对比,这个条件还是有点重的,如果我一分钟内没改表,但下一秒变化极大呢?在这方面 Oracle 还有百分比、热度情况等各种各样的、更细度的数据量化,然后做迭代,判断它到底是不是自动采集。表格如果小于一千行数据也没有意义,它也不会进行大的优化调整。

关于执行计划的调整我有些建议和方法,比如说可以加 hint,试一试 TiDB_SMJ (t1,t2)、TiDB_INTL (t1,t2) - TiDB_INTL (inner table)、TiDB_HJ (t1,t2) 这 3 个参数,join order 也可以用这种方式。你可以选择 use index (),ignore index (),这时候加 hint,进行对索引进行干预。这一页列出来的所有参数对于SQL优化都有效,但是大家可以猜一下,这个优化的收益百分比多少?改变参数、改变内容,如果这个参数中跟执行计划有关的占 20%,参数带来的只有10%。所以要做架构侧的优化,做预分区、表级和基于业务调整,收益几乎在 40% 以上。

SQL 优化还有些其他的改进方法,比如说快速增量统计信息 Fast | INREMENTAL ANALYZE,适用于全量统计信息采集比较慢,但希望在高峰期时候不要有干扰的时候;还有获取列之间的数据相关性的时候,业务信息相关性和直方图如果相关性不够的话,提供基于用户可配参数的启发式方式;3.0.0 - beta.1 版本中,join reorder 这个方式也做了一定的算法提速;其他还有诸如 Cascades 修改,包括优化 cost 模型这些,整个产品团队都付出了很多时间和精力。我们在 SQL 里发现问题时候,首先看优化器有没有最新迭代。对于别的小伙伴遇到的问题,我会进行打包,并且提前预防。

其他一些基础概念也有需要大家注意的地方,比如约束。 DBMS 中主键和唯一键都是表中数据的唯一约束,外键约束两个关系的相关性。但在TiDB 中需要注意:
- 主键必须在建表时声明,目前版本还不能为已有的表添加、修改或删除主键。这个我不是很能理解,我建个表想后续再添加主键,主键有业务性和非业务性的,这于对架构侧要求很高,非常麻烦。当然也是互联网圈当中有些特定场景就差主键,可以单独设计,但在一些灵活的应用场景中,这个就比较别扭。
- TiDB 唯一键可以在新建表时添加,也可以在已有表中进行添加或者删除操作。
- 外键 TiDB 目前还不支持,要去掉表结构中创建外键的相关语句。给大家讲一个故事,以前我们在进行第三层范式设计的时候,往往采用外键强约束的方式,我们对数据库层集中处理层是一种伤害,因为校验没有在应用层,应用层是比较廉价的,而 DB 层是非常昂贵的。变相来说,前期设计的时候有外键参照,但是在物理部署的时候,把所有外键全部删除,业务侧保证依赖关系。我只能把它理解为这是优化方案做到极致,只可以在业务侧实现。但我们在一些应用场景里对外键是有需求的,所以我也期待着后续 TiDB 能支持外键。
在互联网场景当中,写入热点是非常普遍的,而且最难场景是热点漂移。热点漂移是什么意思?就是此时此刻的热点,过了一段时间后它就不再是热点了,但是我要解决的是此时此刻的热点问题。热点产生的原因一般是因为批量计算的回写,TiKV 是一个按 range 切分的 KV 系统,KV 的 Key 决定了写入位置在哪个 Region,Key 的值取决于两种情况:一个是主键,如果是 int 和bigint,key就是主键;第二种情况是 TiDB 为表创建隐藏列,比如 _tidb_rowid,key 是该隐藏列。
那么怎么打散呢?比如说用 SHARD_ROW_ID_BITS 来设置隐藏列_tide_rowid 分片数量的 bit 位数,默认值为 0,即 2∧0=1 个分片。其实大家解决的方式都大同小异,所以大家更应该经常交流。写热点不管是在 Redis 还是在大数据场景当中都是非常普遍的,解决方式基本就这么几招:或是在业务侧做打散,比如说前置 ID 或 random;或是做一些业务侧的改造,在写入的时候就打散了;或是在技术侧建表时候做一些产品侧打散动作;再不济,就是用参数强改。只要是分布式的计算框架和分布式的存储框架,都是按照 Region 这种方式去打散的。
当然还有 Partitioned Table,也就是分区表技术,我很期待 TiDB 小伙伴们,能从 partition 这个角度把热点打散做得得更好、更稳定一些。Partition 对用户极其友好,我认为这是跟 MySQL 比,很重要的一个亮点。TiDB 既是分布式,又是关系型,DBA 在优化方面更有话语权一些,而且对用户更方便。说到这,我给大家的建议是多多积累别人和自己遇到的问题,以应对线上出现的各种情况。
下面我们来讲一讲锁。对于写代码的人,锁是一定避不开的。我推荐大家,多掌握一些基础能力,包括建模能力、设计能力,才能更好地理解某些基本功能。锁分为乐观锁和悲观锁,两种锁各有利弊,但是大家在平时写代码的过程中还是用悲观锁多一些。为什么呢?因为乐观锁在写表、建表和逻辑关系的时候,在列层面打得是 timestamp。我倾向于在能把业务需求盘点清楚的情况下,尝试用乐观锁,它更简单一些,不会带来加锁开销,对性能有好处。尤其在大规模数据使用场景下,锁出现问题是不可逆的。前期如果用比较高级别锁的话,后续遇到问题就会比较麻烦一些。悲观锁其实对开发框架并不友好,改造逻辑变化相对技术成本、开发成本比较高。乐观锁在事务冲突的情况下,会带来性能下降,事务失败率较高。在代老师广告业务的场景下,我在想是不是可以开 focus,性能飙升几十倍甚至几百倍,但是需要评估好对公司的成本消耗模型到底是多少。比如说消耗模型当中有 1% 消耗,但这个动作对客户好,在客户占了便宜的同时,我的价位得到质的飞跃。当然这个难就难在,如果我们单纯是一个支持部门或运维、优化部门,可能推不动。我建议往前走一步,我自己也是这么做的。我每次做方案的时候,都会强烈把业务方全都约过来聊,我会告诉他们这个方案的优劣势对比,然后我也会有倾向性地告诉他,只要做这个动作会给性能带来非常大地提升。你一定能说服你的业务方,然后采用最佳的架构而非技术手段来提高性能,最后你就能做到,你比业务还懂业务。

总结一下乐观锁对于开发侧的影响,比如说 affected rows 不可信,SQL 返回结果不可信,需要校验事务提交请求的返回值,这是硬伤。需要尽量避免冲突业务场景,通过业务来解决冲突,而不要让数据库不断的重试,可以通过关闭乐观事务的自动重试解决这个问题。一定要捕获数据库提交请求的异常,进行业务重试或处理。只要用乐观锁,都需要跟业务开发团队对接,指标优化本质上都是往前走,别在后面。

处理秒杀场景的最佳实践是将计数器功能转移到缓存中实现。秒杀场景一定是把所有的机器和设备全部扑上去,以保证硬件和性能,但是又不能用太硬的手段,比如悲观锁,否则一定达不到秒杀场景的性能要求。所以在这个场景中,业务需求提给你的时候,就必须做乐观锁的实践。谈优化的时候,你必须清楚,需求方的真实需求是什么,文字比较多大家可以具体看下面的图:

我最后列了一张图,是 benchmark 流程。这个流程大家都很熟,我把它列出来就是希望大家在压测时有完整的测试方案。我建议大家在选型的时候,可以把所有产品都并行测试一下。当真正压测的时候,你一定会考虑到把所有节点、硬件、模型卡都压满,在这个过程中,你需要知道业务特性,拿出最核心的场景,按照 benchmark 方式来对比。当你经历过,或者带领的团队经历过会发现,一次性的 Bug 全出来了。既然是压测,测试场景就是各种极端场景,你会发现选型的产品就是满足不了你的场景,这才叫真正好的测试场景。满足不了场景怎么办?就需要我们做一个 merge DB,或者从优化角度来说,就必须折衷地从架构侧去改,策略就不再依赖产品,而是依赖于自己的能力:建表及业务设计的时候,怎么修改性能指标。当指标达到要求的 80%,这个产品就可用了,并且在实际使用过程当中,你就发现这个产品非常好用,因为错误全部经历过。所以一定要走这个过程,POC 的时候测一下。在测试中把测试目标和测试用例定好,测试用例定的高一些,基准性测试、拓展性测试、产品附加测试出个报告,用这个报告和其他产品横向对比。这个测试,相信 TiDB 原厂也会积极地协助,原厂一定是对自己产品充分有信心的。当然 TiDB 原厂除了充分有信心之外还有初心,如果你真的考虑使用 TiDB,他们一定会帮你搞定。
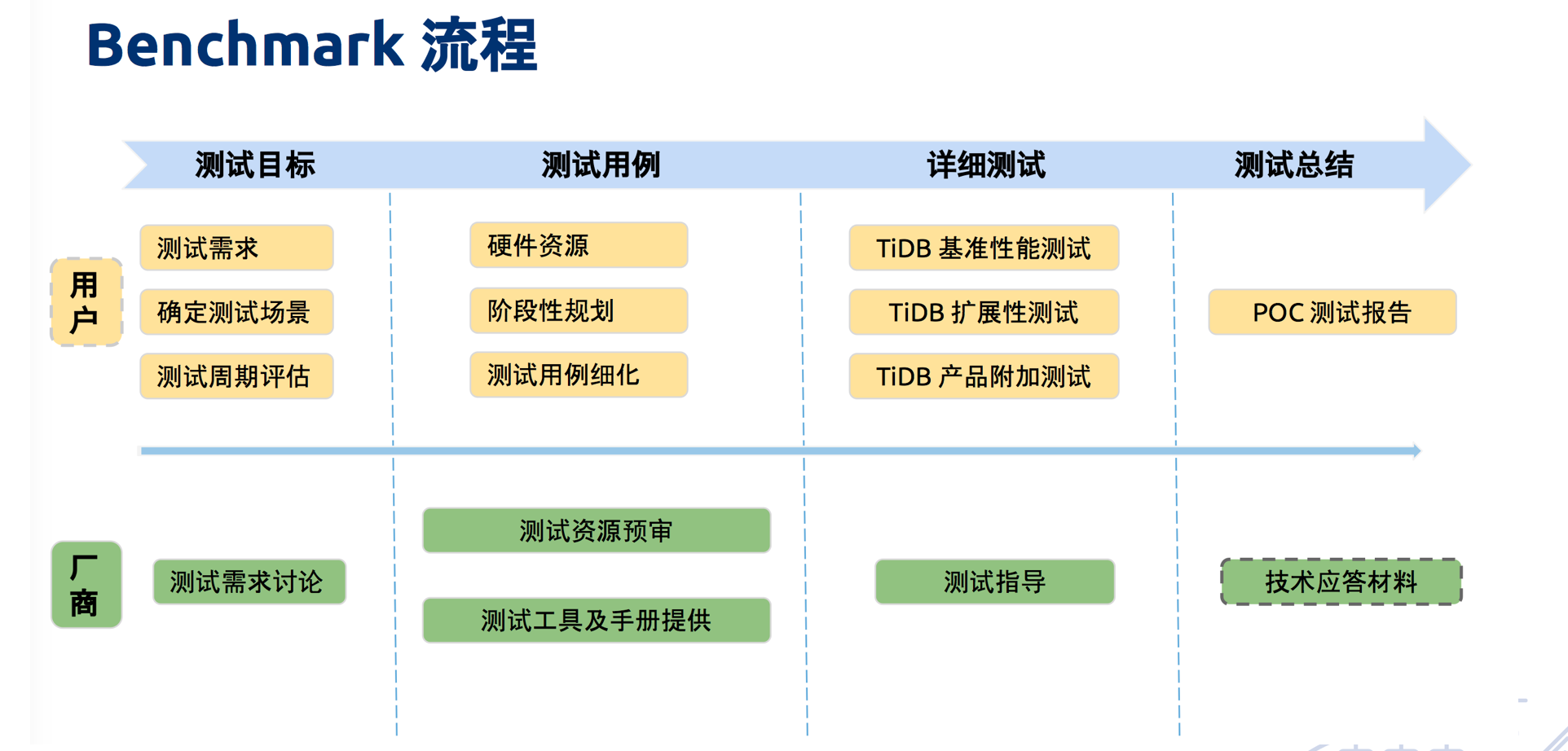
使用 TiDB 一定有一种方案,让产品的性能达到最高,但需要把你和原厂团队对产品的理解整合到一起,做到规避问题、提升效率。
作者:侯圣文,北京大学理学硕士,Oracle ACE 总监,阿里云 MVP,TUG 2019 年全国 Co-Leader,2019 年度 MVA,恩墨学院创始人,大数据联盟 BDA 创始人,Cloudera 大数据用户组(ACCUG)创始人,Oracle OCM 大师联盟创始人。