

【是否原创】是
【首发渠道】TiDB 社区
前言
前不久我们在混合部署架构下测试了TiDB 5.0的性能,测试过程可以参考TiDB 5.0 异步事务特性体验——基于X86和ARM混合部署架构。在测试中我们使用了3台X86的TiKV和3台ARM的TiKV,在双方的对比参照下,我发现了一个奇怪的问题,就是相同配置的机器下ARM平台的TiKV Server内存占用量总是比X86平台大,而且不是大了一点点,本文会详细还原这个问题的发现和排查过程,以及如何解决内存异常问题。
发现问题
在部署完TiDB 4.0集群后,我习惯性地打开Dashboard查看各节点的运行状态,在主机页面看到了和往常不一样的画面,一个刚创建完的空集群,有一部分节点内存占用明显偏高,此事必有蹊跷,特别是其中的3台TiKV几乎达到了80%,而另外3台TiKV却处于正常水平:
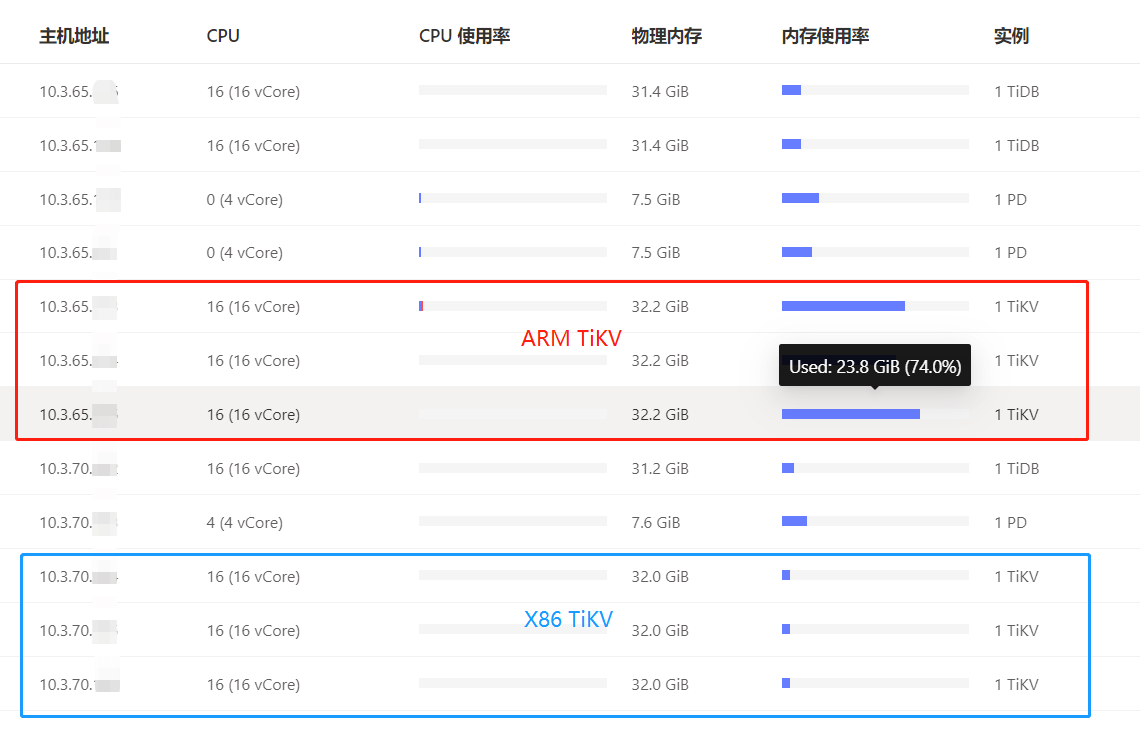
经过初步判断,超标的3台TiKV刚好都是ARM节点,首先想到的是4.0版本是不是在ARM上有bug,于是把集群升级到5.0后发现问题依旧,说明并不是版本问题。
仔细对比后,发现不仅仅是TiKV节点,其他ARM的TiDB和PD节点内存都比X86的要高,进一步怀疑是TiDB本身对ARM的兼容性问题。为了验证高内存确实由TiDB引起,我以X86节点为参照,开始做一步步排查。
排查问题
以其中一台ARM TiKV为排查对象,首先登录到服务器中查看资源占用情况,直接使用top命令:
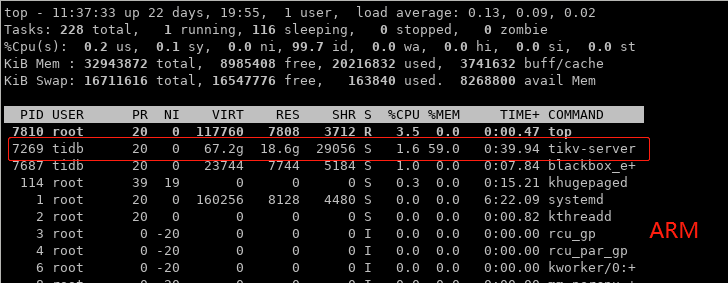
可以看到,内存占用最高的进程就是TiKV本身无疑,为了不冤枉它,我们还是要对比看看此时X86的情况:
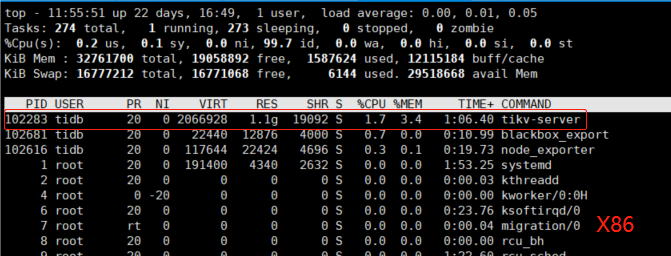
果然和我们预期的一致,面对铁证如山的事实,TiKV背锅背定了。
我们进一步分析此时的节点内存使用情况,使用cat /proc/meminfo命令查看:
[root@localhost ~]# cat /proc/meminfo
MemTotal: 32943872 kB
MemFree: 3809408 kB
MemAvailable: 1467264 kB
Buffers: 192 kB
Cached: 457856 kB
SwapCached: 669248 kB
Active: 26691328 kB
Inactive: 2040832 kB
Active(anon): 26565568 kB
Inactive(anon): 1726912 kB
Active(file): 125760 kB
Inactive(file): 313920 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 16711616 kB
SwapFree: 15044608 kB
Dirty: 256 kB
Writeback: 0 kB
AnonPages: 27385216 kB
Mapped: 75968 kB
Shmem: 18240 kB
KReclaimable: 37120 kB
Slab: 245440 kB
SReclaimable: 37120 kB
SUnreclaim: 208320 kB
KernelStack: 29696 kB
PageTables: 16384 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 33183552 kB
Committed_AS: 1009344 kB
VmallocTotal: 133009506240 kB
VmallocUsed: 0 kB
VmallocChunk: 0 kB
Percpu: 17408 kB
HardwareCorrupted: 0 kB
AnonHugePages: 18874368 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 524288 kB
Hugetlb: 0 kB
其中比较诡异的是AnonHugePages字段占到了18G内存,而实际的用户进程空间(Active)也才26G。
继续验证这里的AnonHugePages占用是否都来自TiKV Server进程(PID是3996),用如下命令筛选:
[root@localhost ~]# awk '/AnonHugePages/ { if($2>4){print FILENAME " " $0; system("ps -fp " gensub(/.*\"/([0-9]+).*/, "\"\"1", "g", FILENAME))}}' /proc/3996/smaps
/proc/3996/smaps AnonHugePages: 10485760 kB
UID PID PPID C STIME TTY TIME CMD
tidb 3996 1 0 May21 ? 04:40:06 bin/tikv-server --addr 0.0.0.0:20160 --advertise-addr 10.3.65.133:20160 --status-addr 0.0.0.0:20180 --advertise-status-addr 10.3.65.133:20180 --pd 10.3.65.130:2379,10.3.65.131:2
/proc/3996/smaps AnonHugePages: 8388608 kB
UID PID PPID C STIME TTY TIME CMD
tidb 3996 1 0 May21 ? 04:40:06 bin/tikv-server --addr 0.0.0.0:20160 --advertise-addr 10.3.65.133:20160 --status-addr 0.0.0.0:20180 --advertise-status-addr 10.3.65.133:20180 --pd 10.3.65.130:2379,10.3.65.131:2
从以上信息可以断定所有的AnonHugePages都是来自TiKV进程。
AnonHugePages统计的是透明大页(Transparent HugePages,THP)的使用量,它在RHEL 6以上的版本中是默认开启的。我们都知道操作系统对内存是以页(Page)为使用单位,通常这个大小是4KB,透明大页的设计初衷是尽可能地为应用程序分配大页面(比如2M)来提升性能,减少大内存寻址带来的开销,并且能实现对大页的动态分配和使用。
它对于需要大量内存并对性能敏感的应用程序来说有一些作用,但同时也带来了一个非常严重的问题就是内存泄漏。从RedHat官网的文档来看,它不推荐在数据库程序中开启THP:
THP hides much of the complexity in using huge pages from system administrators and developers. As the goal of THP is improving performance, its developers (both from the community and Red Hat) have tested and optimized THP across a wide range of systems, configurations, applications, and workloads. This allows the default settings of THP to improve the performance of most system configurations. However, THP is not recommended for database workloads.
THP支持三种类型的状态,分别是:
- always,启用状态,系统默认
- never,禁用状态
- madvise,应用程序通过MADV_HUGEPAGE标志自己选择
关于透明大页的介绍这里不做过多介绍,大家可以参考文章后面的推荐链接,写的非常详细。
好在RHEL预留了THP的启用开关,我们可以通过如下方式关闭透明大页特性:
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
# echo never > /sys/kernel/mm/transparent_hugepage/defrag
要注意的是,这种方式只是临时禁用,当系统重启后还是会恢复always状态。
通过以上命令关闭了3台ARM TiKV节点的THP后,我重启了TiDB集群:
tiup cluster restart tidb-test
再次登录到Dashboard查看集群中的节点状态,已经全部恢复正常:
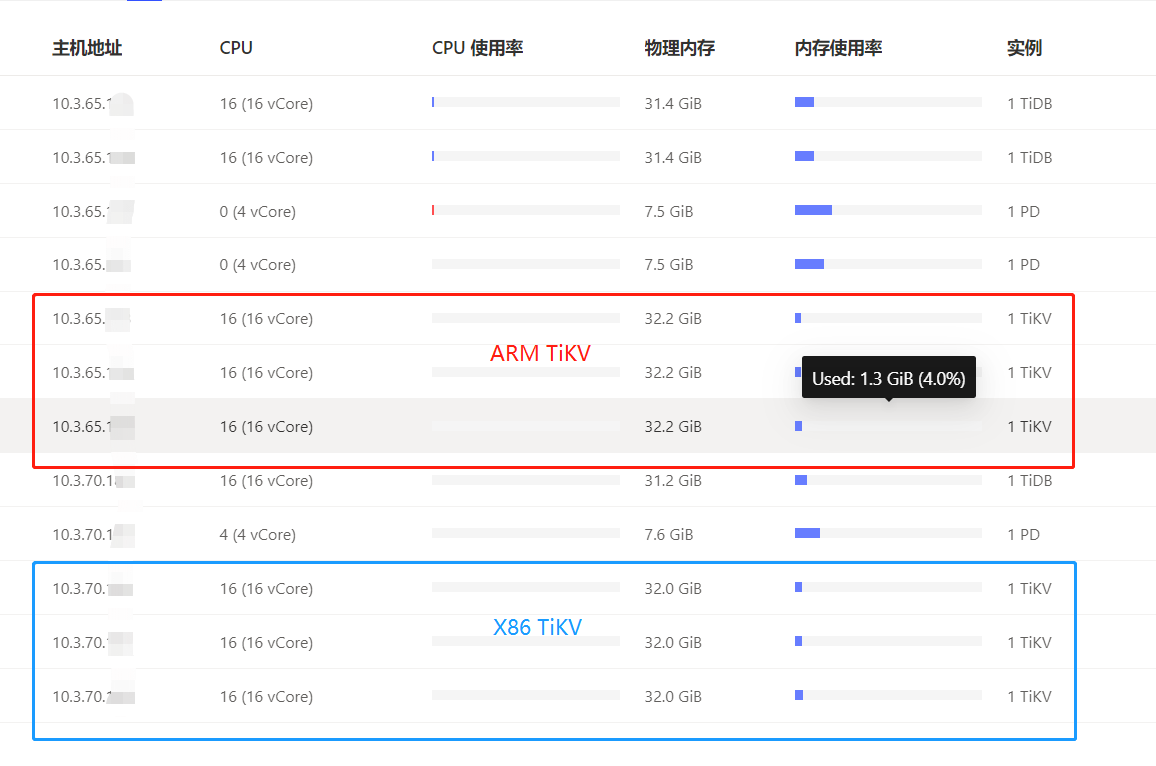
整个过程的内存变化情况通过Grafana的监控曲线看的更加明显:
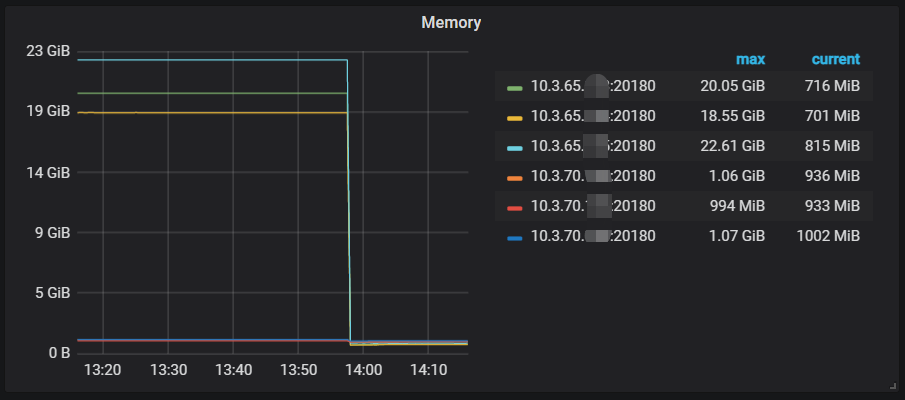
思考问题
虽然问题已经得到解决,但是仔细思考一下的话里面还有一些疑点没搞明白。
在X86的系统中同样也开启了THP特性,为什么内存使用没有出现明显异常呢?
还有一点就是,ARM的TiDB和PD节点虽然也出现了内存升高,但并不像TiKV节点这样特别明显,这又是什么原因?
我带着疑问去GitHub发起了Issue,不过遗憾的是还没找到问题的根本原因:
https://github.com/tikv/tikv/issues/10203
欢迎各路大佬来一起讨论。
如何避免
其实,因为服务器环境导致可能存在的性能问题TiDB官方已经帮大家考虑到了,并且提供了解决方案,只是这个步骤往往容易被忽略。
从TiDB 4.0版本开始,TiUP的Cluster组件可以提供对部署机器环境检测功能,我们使用 tiup cluster check命令就可以对部署拓扑文件或者是已有的集群进行监测,效果如下图所示:
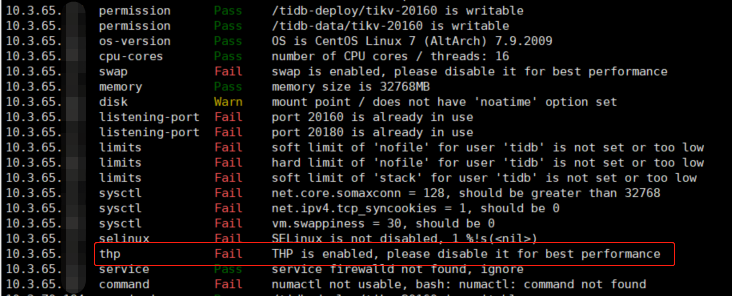
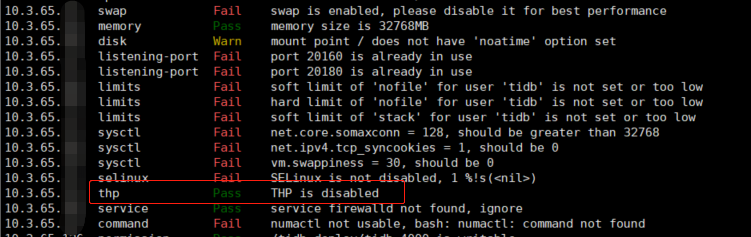
我们应该重点关注那些状态为fail的检查项,并且根据后面的提示做相应的调整,这一步对生产环境来说尤其重要。 以本文中的案例来说,tiup提示为了达到最好的性能请禁用THP,当我关闭了系统的THP特性后重新检测TiDB集群,会发现THP这一项已经变为pass状态:
有的人会说这么多检查项一个个去处理太麻烦了,有没有什么快捷的办法。还真有,tiup支持使用--apply参数对检测失败的项自动修复,不过也只是支持一部分可通过修改配置或系统参数调整的项目。
tiup cluster check <topology.yml | cluster-name> --apply
最后说一句,TIUP真香啊~
推荐阅读
/PROC/MEMINFO之谜
HUGE PAGES AND TRANSPARENT HUGE PAGES
How to use, monitor, and disable transparent hugepages in Red Hat Enterprise Linux 6 and 7?
CentOS 7 关闭透明大页
使用tiup在x86和arm上混合部署arm内存居高不下
部署机环境检查