

- 近期备考PCTA认证过程中的学习笔记,主要是基于101课程记录的,目前考试已完成,分享出来供参考。
一、TiDB数据库架构概述
1.1 核心功能
- 水平扩容或者缩融
- 金融级高可用
- 实时HTAP
- 云原生的分布式数据库
- 兼容MySQL 5.7 协议
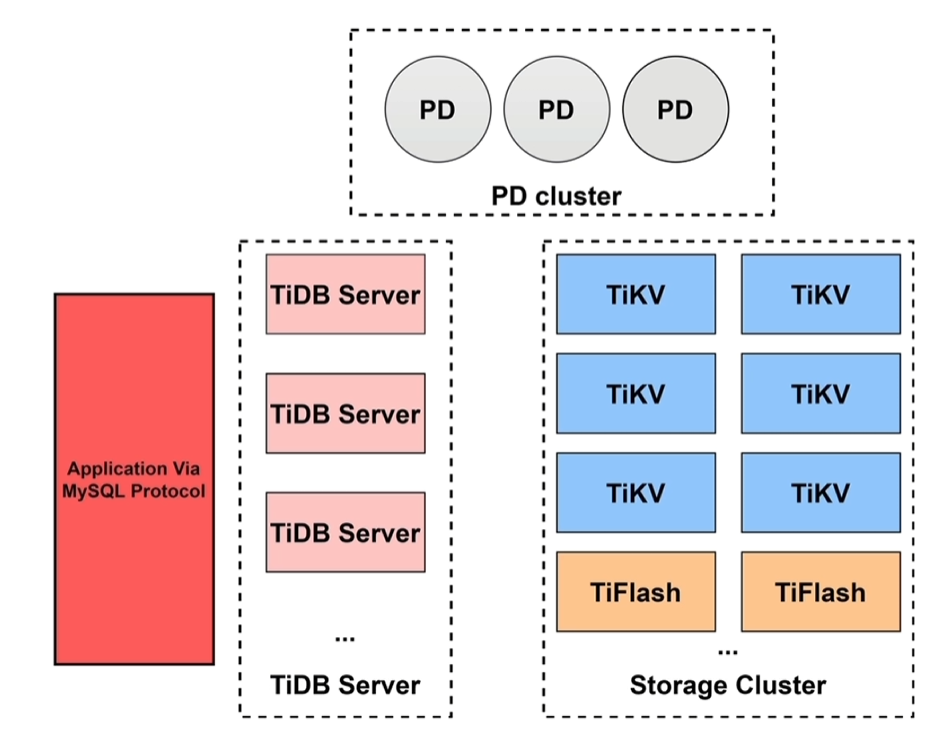
1.2 TiDB Server
核心作用
- 处理客户端的连接
- SQL语句的解析和编译
- 关系型数据与KV的转化
- SQL语句的执行
- 执行online DDL
- 垃圾回收(GC):tidb的修改删除都是新增KV键值对,不会更改原有数据,TiDB Server会定期将存储在TiKV中的无效数据清理回收。
- 热点小表缓存 V6.0
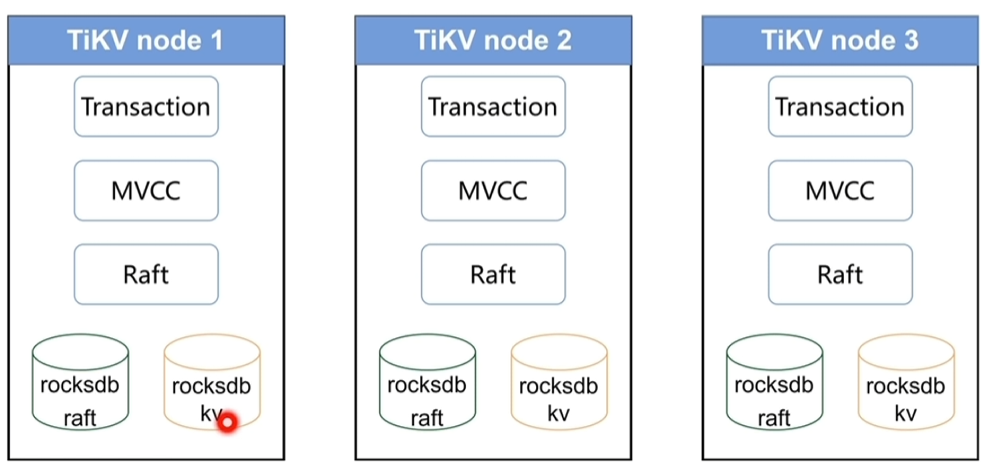
1.3 TiKV
- 数据持久化:每个节点存在2个rocksdb存储数据
- 副本的强一致性和高可用性:基于Raft协议
- MVCC (多版本并发控制)
- 分布式事务支持
- Coprocessor(算子下推):每个节点可以做一定的计算工作,如过滤、投影、聚合等。
1.4 Placement Driver
- 整个集群TiKV的元数据存储
- 分配全局ID和事务ID
- 生成全局时间戳TSO
- 收集集群信息进行调度
- 提供TiDB Dashboard服务
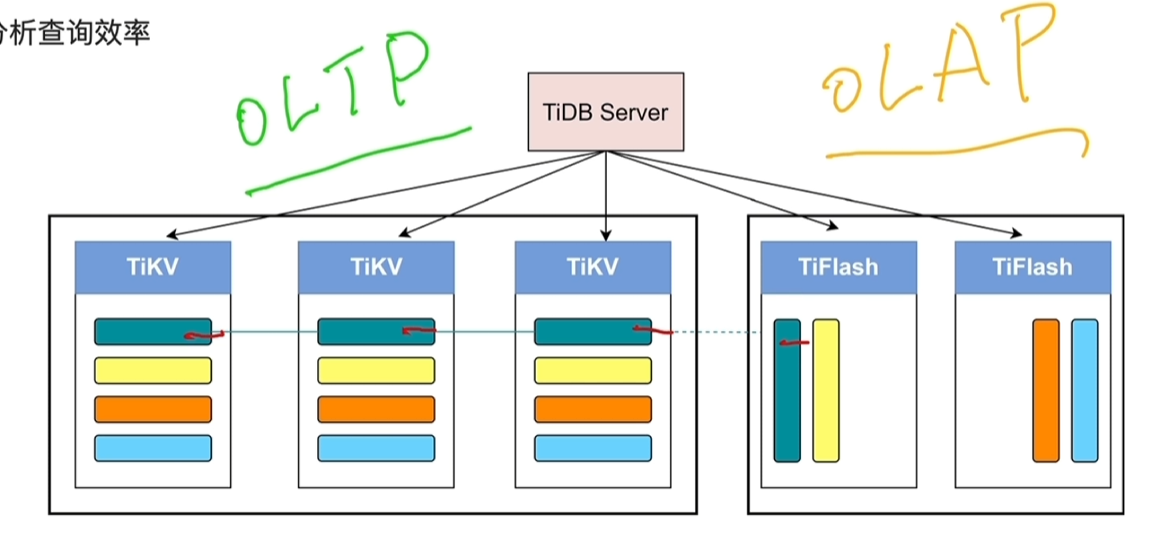
1.5 TiFlash
- 异步复制
- 一致性
- 列式存储提供分析查询效率
- 业务隔离
- 智能选择
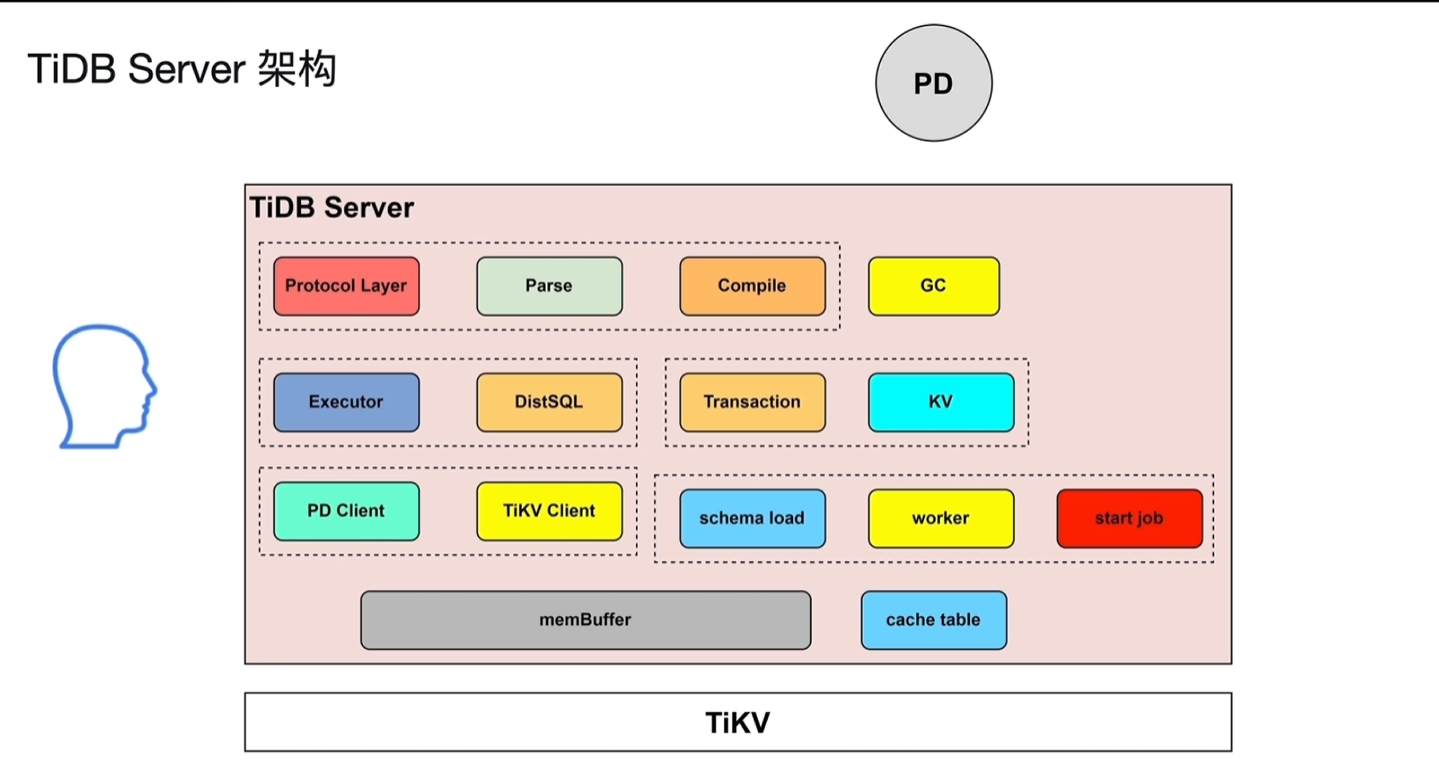
二、TiDB Server
2.1 架构
- SQL语句的解析编译:Protocol Layer、Parse、Compile 生成sql的执行计划 ,交给Executor Protocol Layer:处理客户端的连接 Parse+Compile:解析编译
- 分批的执行sql的执行计划:Executor、DistSQL、KV
- 事务的相关SQL执行:Transaction、KV
- 与PD、TiKV的交互:PD Client、TiKV Client
- Online DDL:schema load、worker、start job
- memBuffer:缓存读取出来的数据、元数据、登录认证信息等
2.2 作用、进程
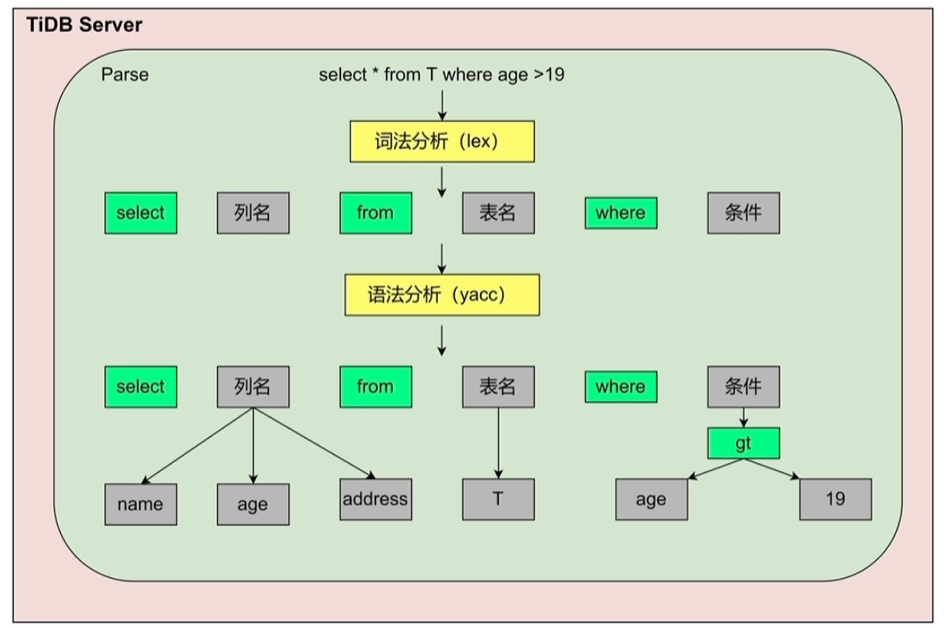
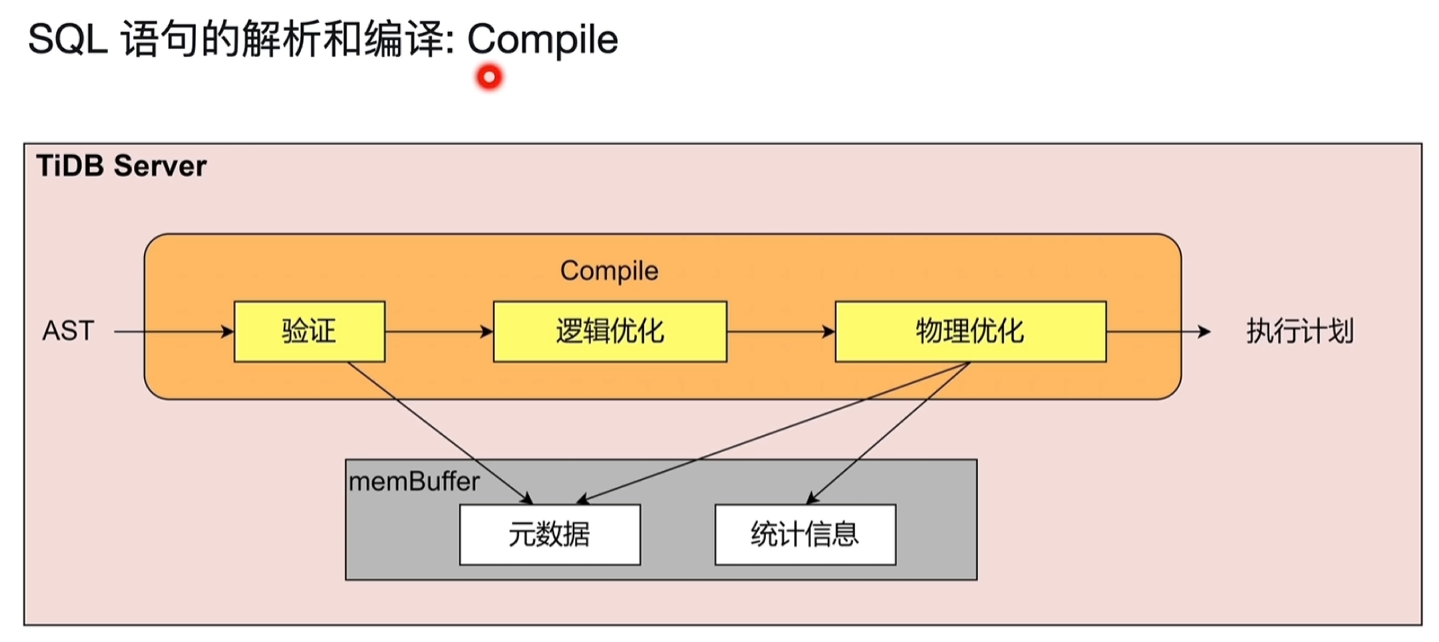
2.2.1 SQL语句的解析和编译
Parse:通过词法分析、语法分析,将sql解析成抽象语法树(AST),传递给Compile模块 Compile:
- 合法性验证:语句相关的表是否存在等等
- 逻辑优化:依据关系型代数的等价规则做一些逻辑变换,如列裁剪将不需要的列去掉、最大最小消除、投影消除、算子下推、子查询、外连接变内连接等等一系列在sql层面可以做的语句优化
- 物理优化:根据逻辑优化的结果,考虑数据分布、大小决定用哪个算子,即结合统计信息,决定走索引还是全表扫描,走索引的话走哪个索引
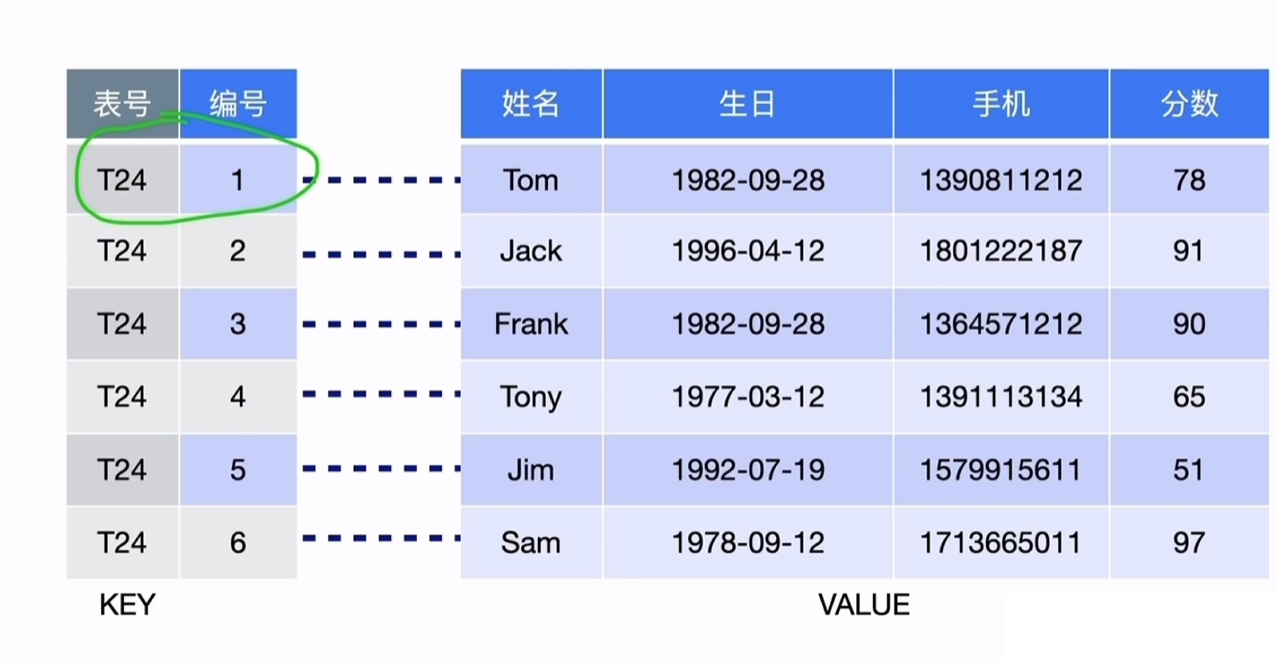
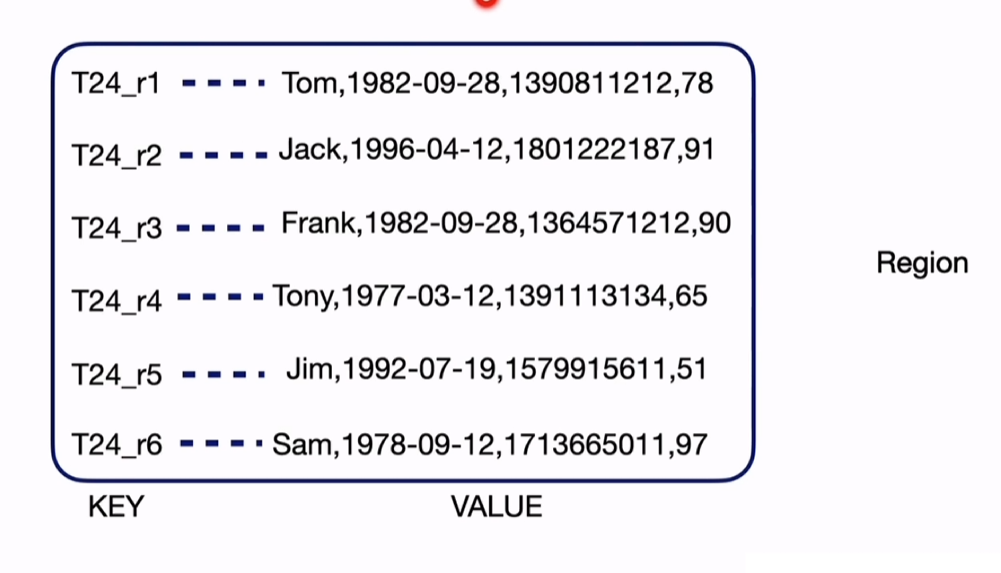
2.2.2 关系型数据与KV的转化
TiDb中的数据最终是存储成key-value的键值对。
这里讲的是聚簇表,key以表号+主键的形式组成key。(非聚簇表的key没有主键,是自动生成的rowid)
region:key value的数据集合组成region,默认96M,当达到144M时,会split分裂成2个region。(region是存储在TiKV中的)

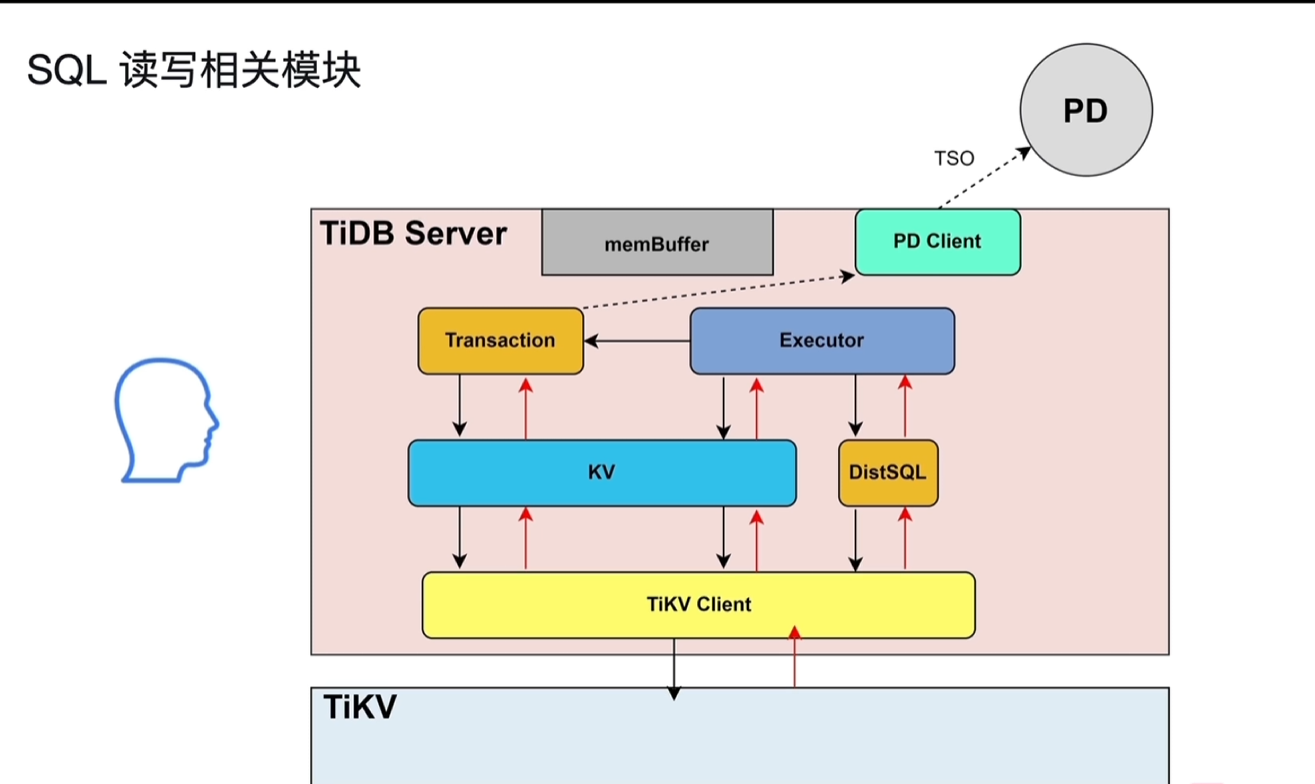
2.2.3 SQL读写相关模块
- 复杂的SQL、嵌套查询等等,Executor会将其交给DistSQL转化成单表的操作组合,再发给TiKV。
- 点查会走KV的模块,如简单的单行请求。
- 存在事务的,会先经过Transaction后再到KV;Transaction会在开始时和提交时从PD中获取TSO时间戳。
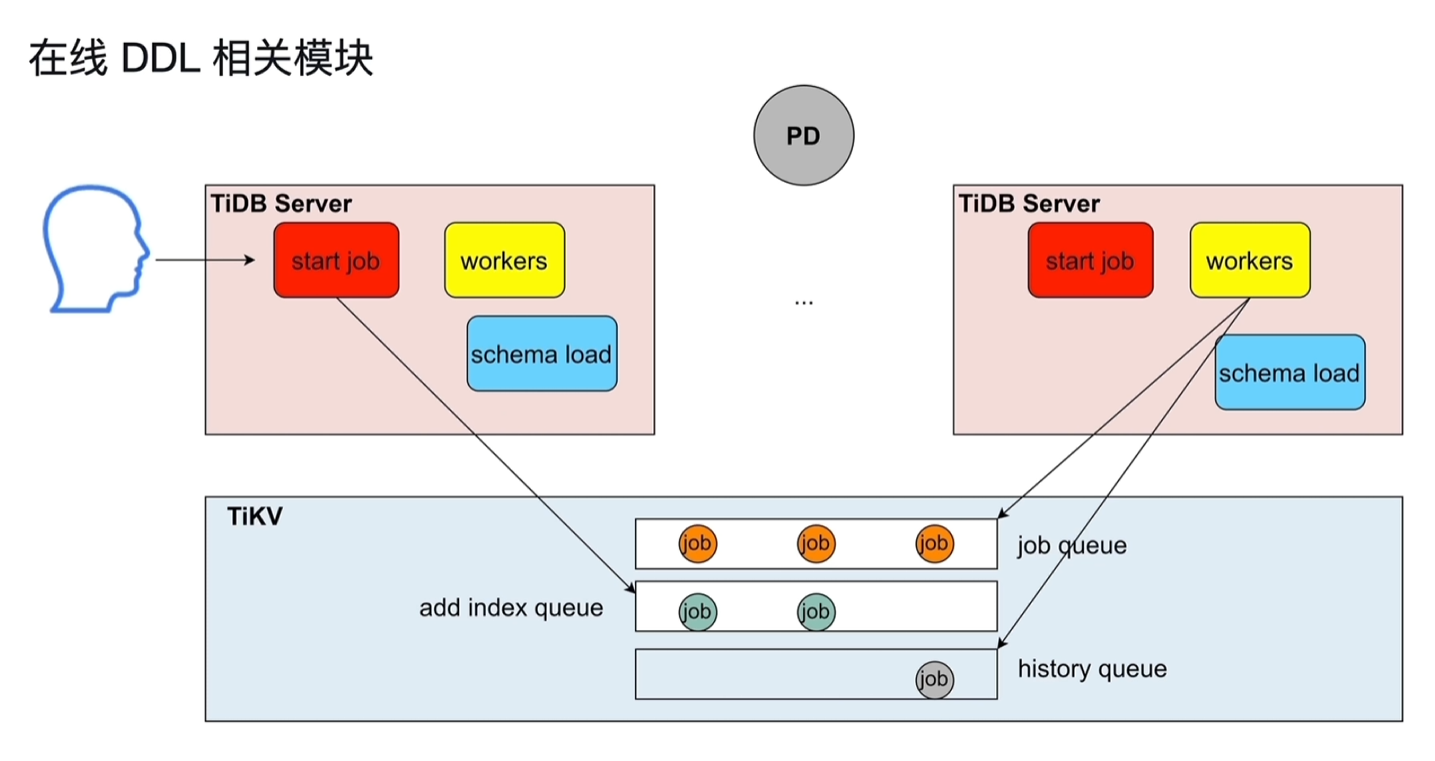
2.2.4 在线DDL相关模块
- 集群中存在多个TiDB Server,都可以接收DDL操作请求,但同一时间只会有1个TiDB Server(Owner)执行DDL操作。
- start job:接收用户发起的DDL操作语句,将其放到TiKV中的job队列中
- worker:负责执行DDL操作,由Owner角色的TiDB Server中的worker去取job queue的第一个job,然后执行;执行结束后放入到history queue中。
- 同一时间只有1个owner,存在一个任期,到达任期后会重新发起选举决定新的owner。
- schema load:成为owner的tidb server,会将最新的表schema的信息同步到其内部的缓存中,好根据这些信息去执行job queue。
- job放在tikv是为了持久化。
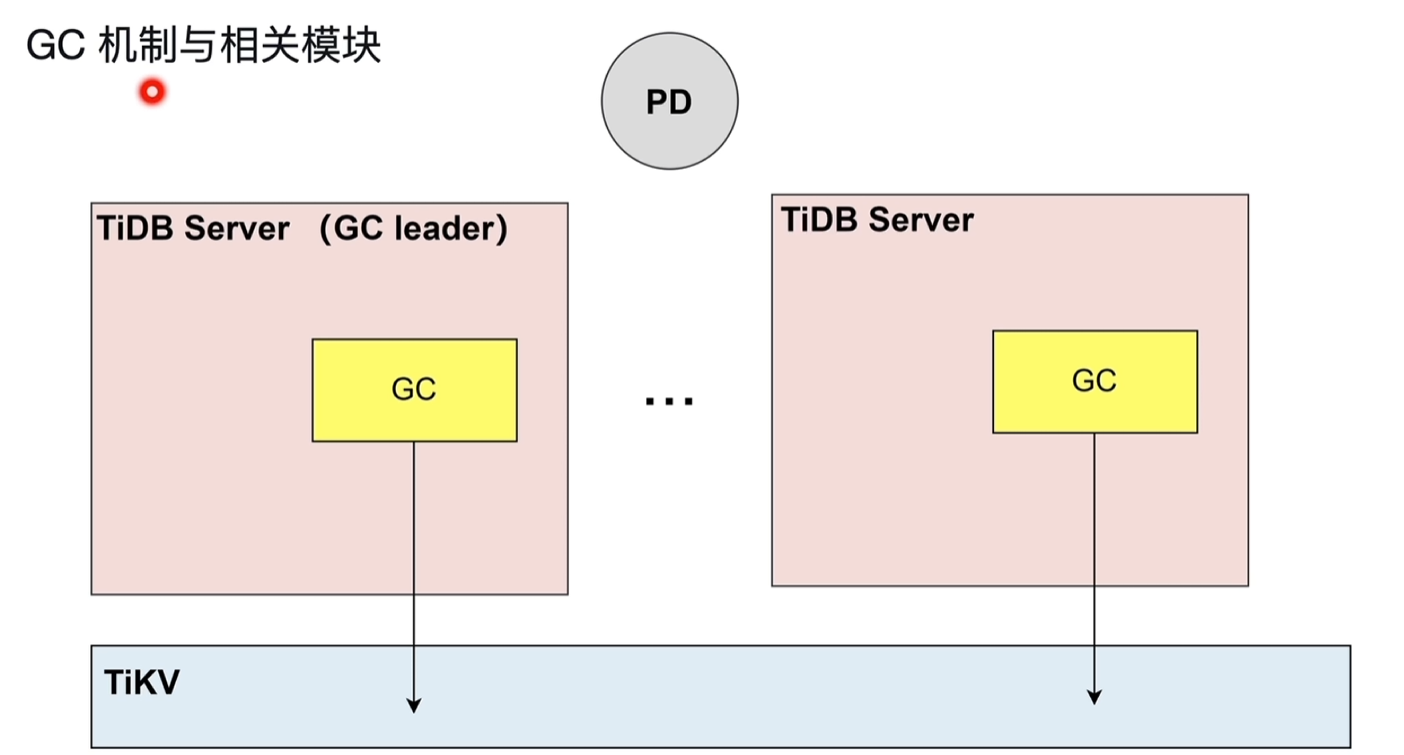
2.2.5 GC机制与相关模块
- TiDB Server的GC是清理历史的版本数据。
- 由GC leader进行清理。
- 基于safe point进行清理:如safe point为10:00am,在这之后的历史版本数据还存在,之前的会被清理。
- GC lift time:默认为10min,即10分钟内的历史版本数据会保留。
2.3 缓存
2.3.1 缓存组成
- SQL结果:数据结果可能分散在多个Tikv节点中,需要有地方来汇聚数据;事务数据的缓存之类的。
- 线程缓存
- 元数据,统计信息
2.3.2 缓存管理
- tidb_mem_quota_query:控制每一个SQL/查询默认使用的缓存存储量
- oom-action:决定缓存超量时,返回error还是记录日志等行为。
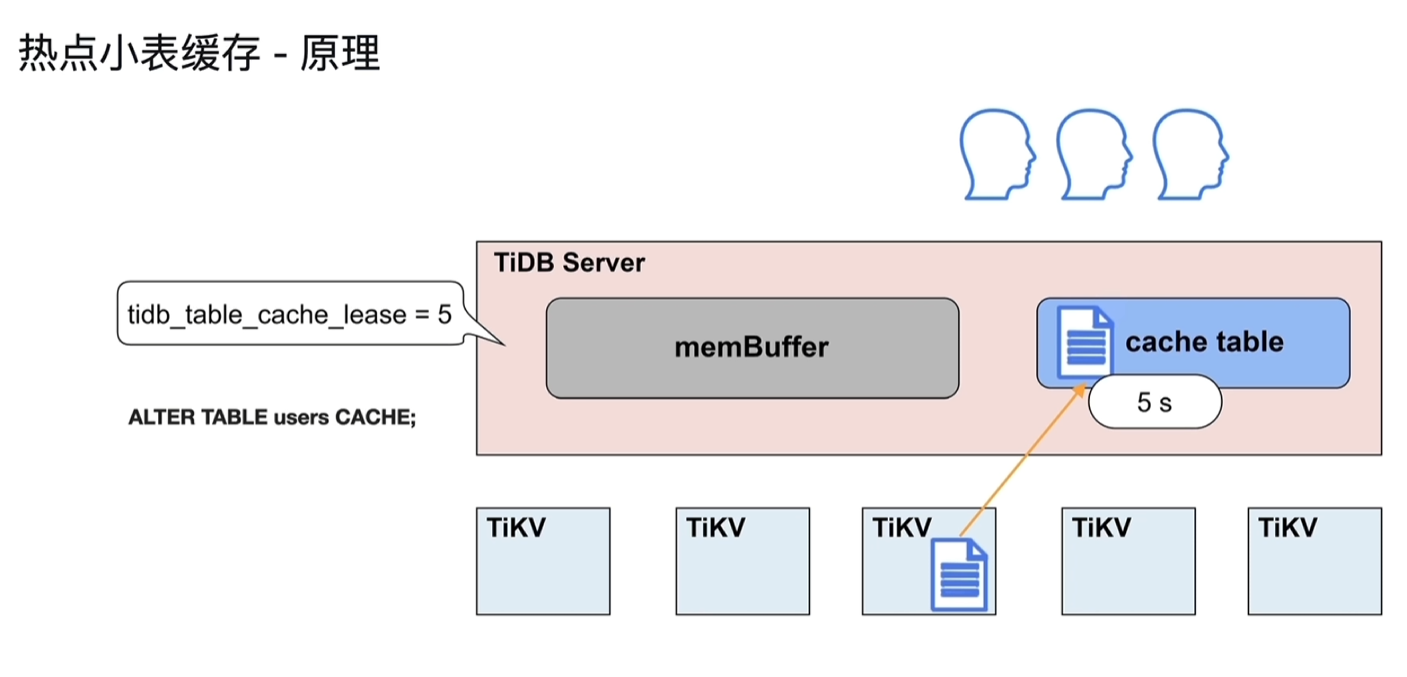
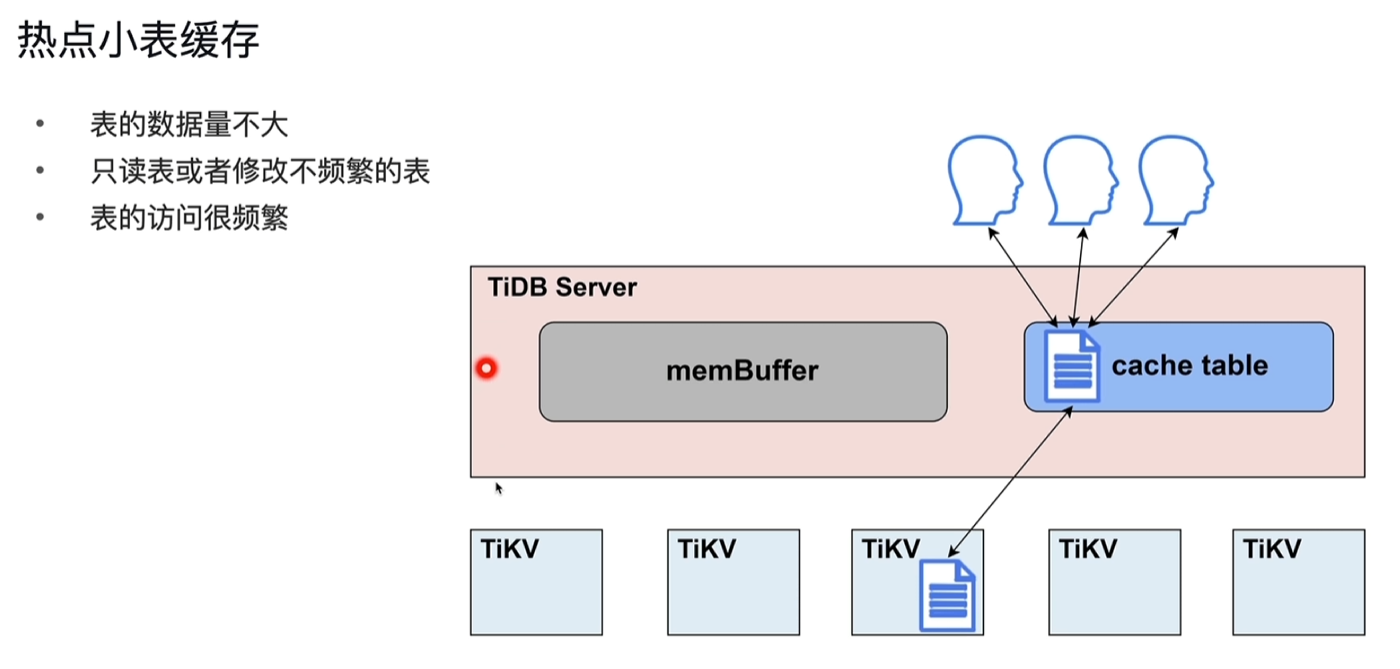
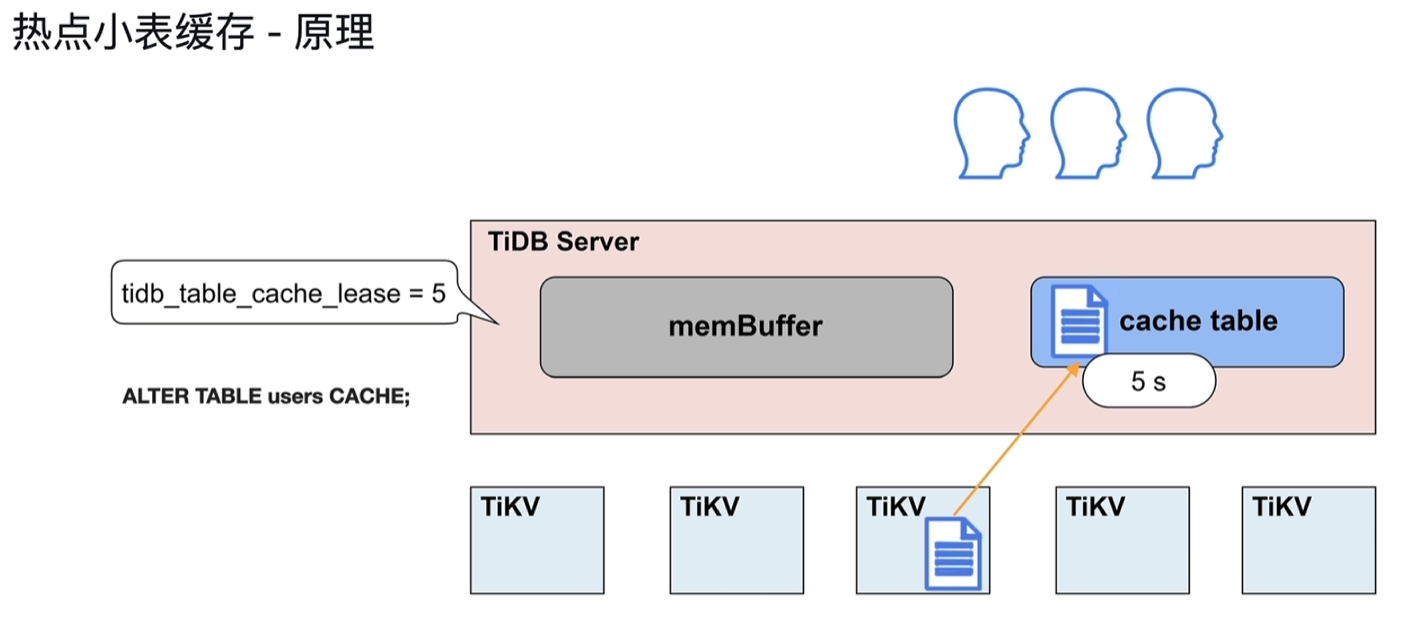
2.3.3 热点小表缓存
- 为了解决频繁从读取tikv小表数据,将数据缓存到tidb server的cache table中
- 表的数据量不大:
- 只读表或者修改不频繁的表
- 表的访问很频繁
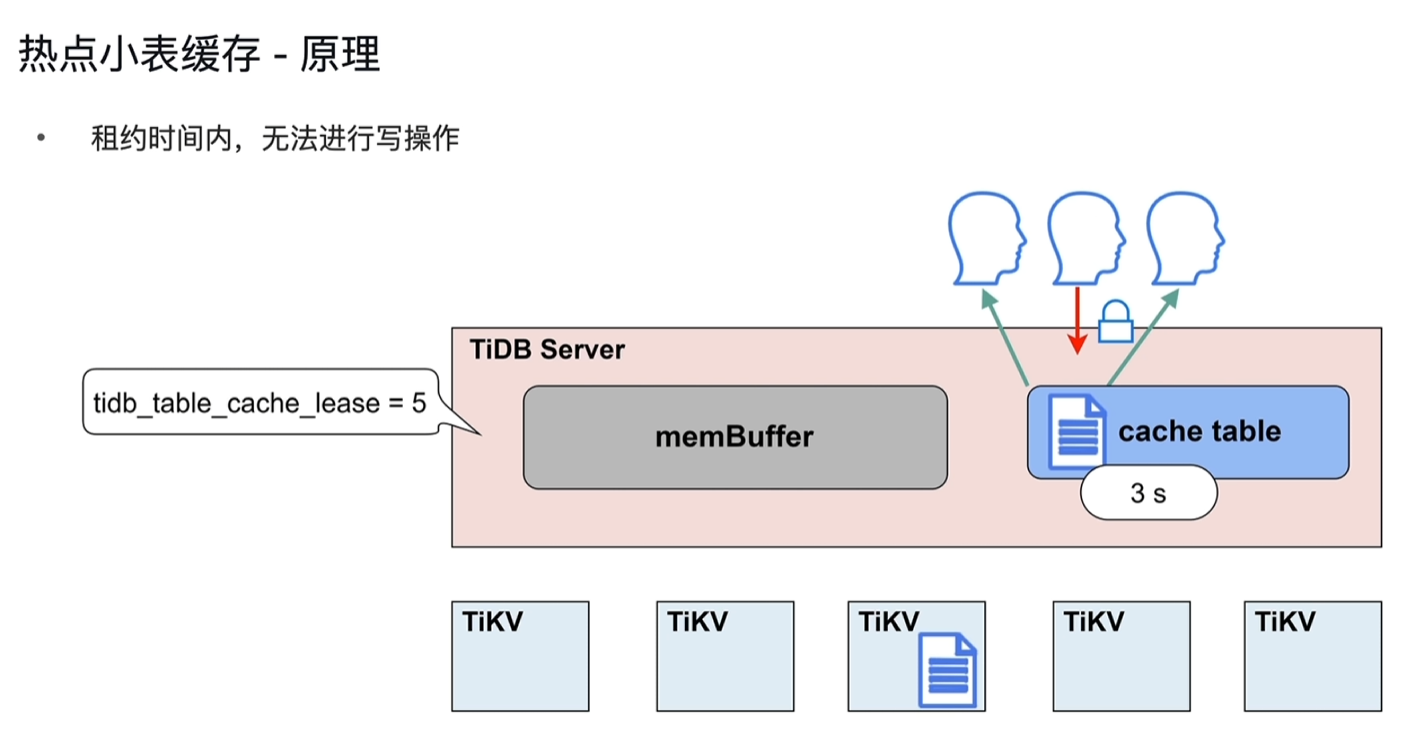
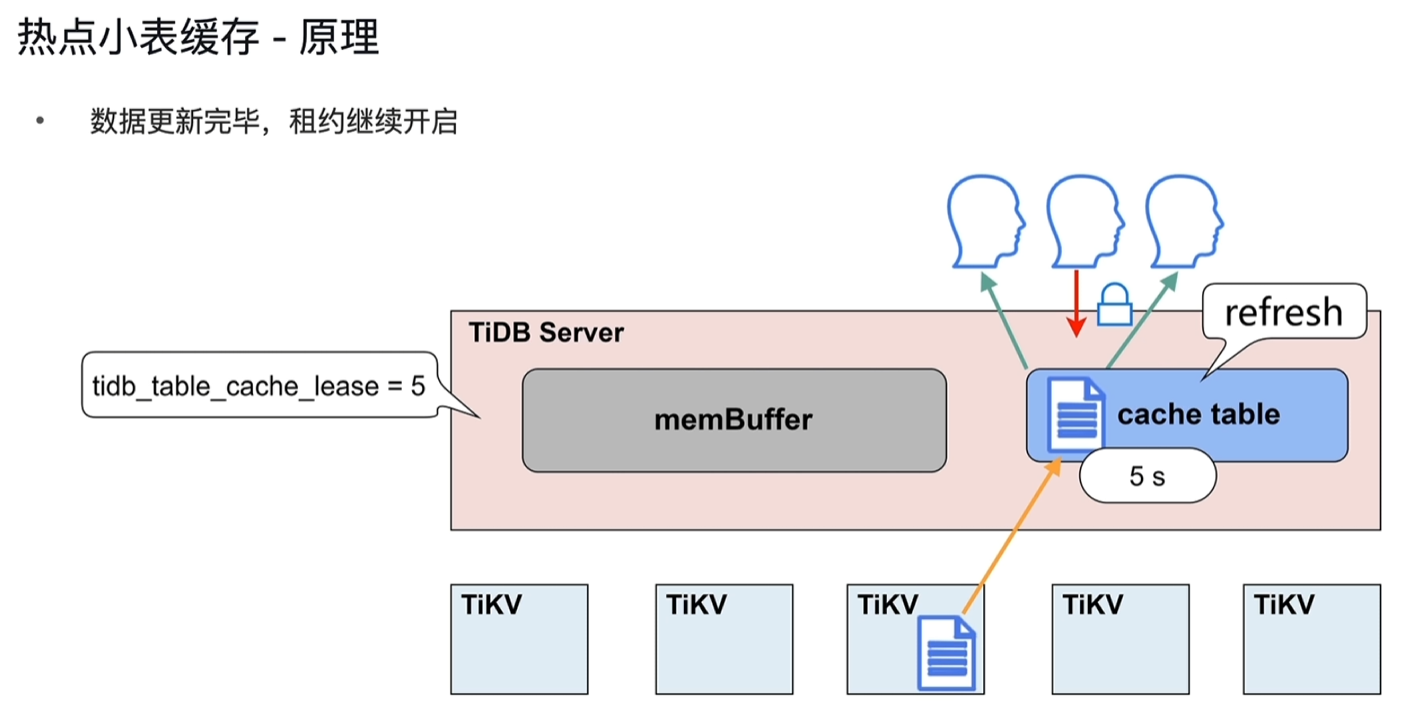
- 设置租约,如5s,租约到期前从cache table中直接读取,到期后再次从tikv中读取并缓存到cache中;如果修改表,租约到期前会阻塞修改操作,待租约到期后再执行修改,读写直接到TIKV节点上执行。
- 设置为热点小表的表不支持DDL,需要先关闭后再进行DDL操作
- 租约到期后的一次读取会比平时慢一点

三、TiKV
架构和作用
- 数据持久化
- 分布式一致性
- MVCC
- 分布式事务
- Coprocessor

3.1 持久化
3.1.1 RocksDB

3.1.2 RocksDB:写入
- 将数据写入磁盘的WAL的日志文件中,保障数据的原子性。
- 会先写到操作系统的缓存中,再批量写入到WAL日志文件中,有丢失概率的风险。
- sync-log:设置为true时,会直接写到WAL日志文件中,会损失一部分性能(大概30%),但更安全有保障,官方推荐是开启。
- 将数据写入到内存中,积累到一定数据后一次性写入到磁盘。
- MemTable:内存的数据,保存落盘前的数据,通过跳跃表、搜索树来保障数据的有序性,追加到一定的数据量(基于write buffer size参数),就将其数据转存到immutable MemTable,然后重新开辟一个MemTable。
- immutable MemTable:不能改的缓存数据,此节点存在的目的是为了防止写入的IO等待,immutable写入磁盘时可能产生IO等待,这样不影响MemTable的写入,防止写阻塞。有1个immutable就会写入到磁盘,如果写入数据太多,可能产生多个,默认达到5个时会触发tidb的流控(基于write stall)。

- Level 0:immutable MemTable的一个复刻,默认达到4个后,就会向下一层压缩排序存储,这个过程叫做compaction。
- Level1以后:文件会切分成一个个的ssd table文件(SST文件),以Key-Value形势按序存储。
- 每一层达到最大容量后,compaction往下一层存储
- 文件查询:文件都是有序的,通过二分查找法查询
- 写入操作:修改、新增都是直接添加对应key进入memtable即可,基于二分查找最终存储到对应Level层级文件的地方即可。写入非常友好。

3.1.3 RocksDB查询
- Block Cache:将最近、最常用的数据缓存在此处。
- 读取顺序:按下图,Block Cache中没有,依次在MemTable中,一直往下查询。
- 单个文件:存在min、max值,基于二分查找法快速定位。
- bloom filter:如果判定某个key在该文件中,它可能在;判定不在,则一定不在。

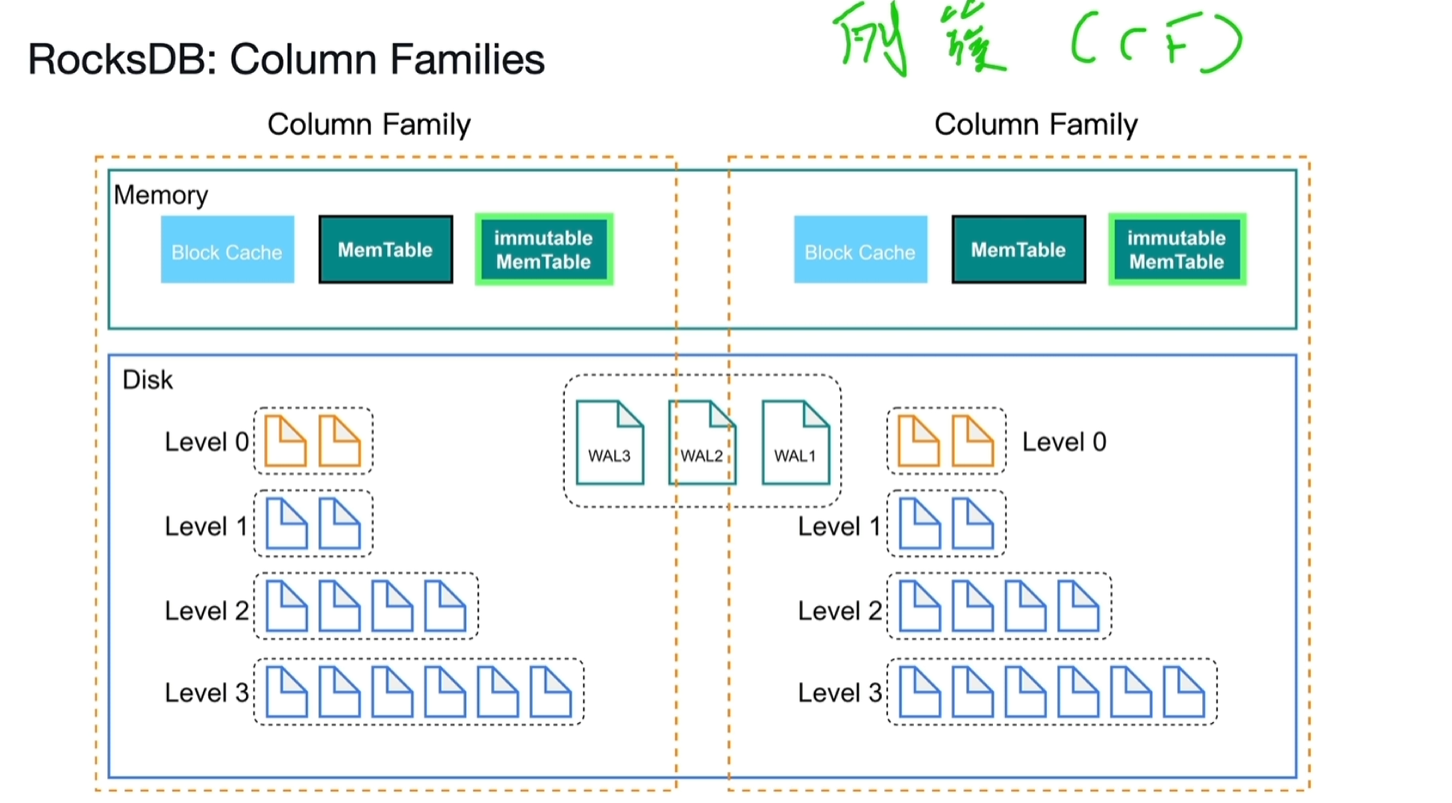
3.1.4 RocksDB:Column Families(列簇)
- 可以分别存取不同表的数据,实现数据分片。
- 示例:Write(cf1,id,name,age,xxx),cf1为指定的列簇,id为key,后面为值。
- 未指定列簇时,有一个默认的列簇default。
- WAL文件是共享的,不存在列簇的区分。
3.2 分布式事务
3.2.1 事务流程
- beigin:start timestamp=100。从PD中获取开始的TSO
- prewrite:修改数据+锁信息。 锁信息如果只写在tikv节点的内存中,其他节点感知不到,只有最后commit时才知道,这叫做乐观事务锁(tidb早期版本是只实现的乐观锁); 锁信息提前写入到tikv节点中,其他节点能感知到,这叫悲观事务锁。 修改数据+锁信息:通过3个列簇存储,Default、Lock、Write; 其中Default中的key包含数据key+TSO; Lock存储锁信息,注意一个事务中操作如果存在多行操作,只会给第一行加一个主锁,其他行均依附于该主锁。下图示例中3代表数据keyID,W代表为写锁,100为事务的开始时间戳
- commit:commit timestamp=110。
从PD中获取事务结束的TSO,在write列簇中写入,如下图所示包含keyid+提交的时间戳,以及对应事务开始的时间戳。
清理锁信息,在Lock中删除对应的锁。注意删除并非直接删除数据,而是新增一个D的锁数据,代表其为删除。
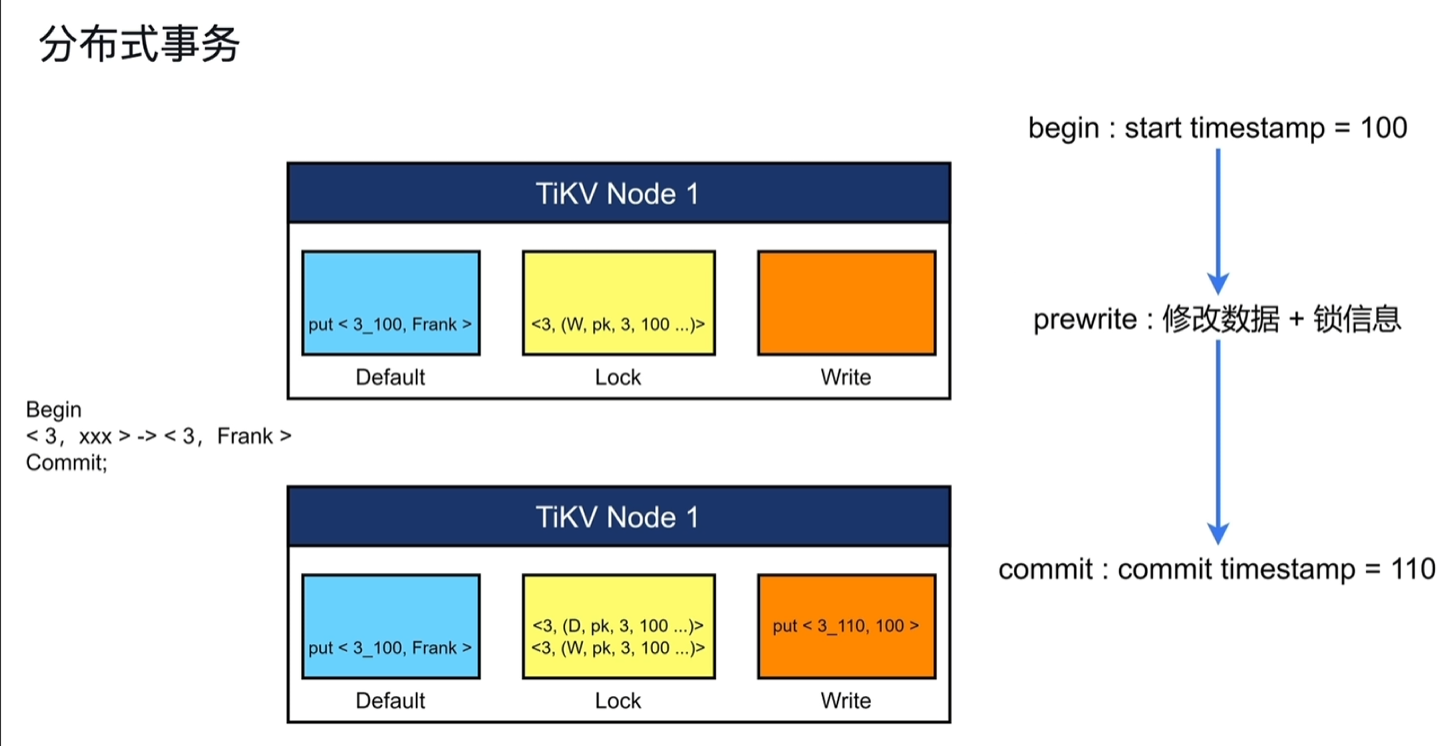 其他人想要读取key为3的值时,先到Write列簇中最近一次修改是什么时间,得知最后一次如上图所示为3+100时间戳,就能在Default中找到3_100的值为Frank;如果在事务提交前读取,在Write中没找到信息,Lock中存在3_100的锁信息,此时不能读取3_100的值。
其他情况
其他人想要读取key为3的值时,先到Write列簇中最近一次修改是什么时间,得知最后一次如上图所示为3+100时间戳,就能在Default中找到3_100的值为Frank;如果在事务提交前读取,在Write中没找到信息,Lock中存在3_100的锁信息,此时不能读取3_100的值。
其他情况
- Write列:当用户写入了一行数据时,如果该行数据长度小于255字节,那么会被存储在write列中,否则的话该行数据会被存入到default列中。
- Default列:用于存储超过255字节长度的数据。
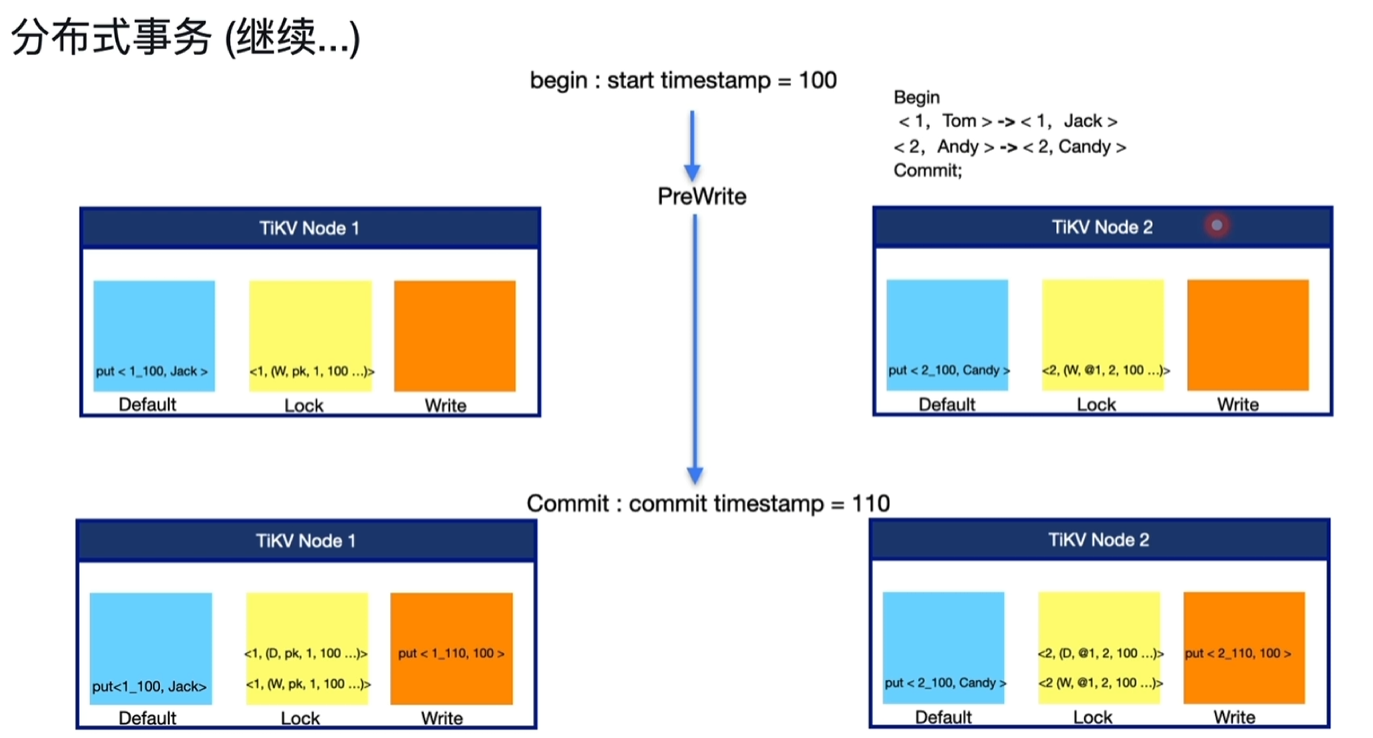
3.2.2 分布式事务
- 基本流程与单节点事务流程一致,下图示例中key1和2分别存在2个节点中。
- 第一行数据1的锁为主锁,标识为pk;第二行数据非主锁,依附于主锁,标识为@1。
- commit时流程一致,分3步先获取提交的TSO,然后在write中写入,再删除锁。
- 由于分布式是多节点,加入commit时,node1节点提交成功,此时note2宕机导致提交失败,这时读取node1的key1数据能正常读取结果;node2恢复后读取2时未在write中找到2_110的提交信息,但通过查锁发现存在W的@1的锁信息,再查node1的队友主锁信息,发现已被删除,这里可以知道之前是因为宕机等原因没提交成功,这时恢复完善write和删除@1锁信息,就可以正常读取。(解决了分布式事务的原子性问题)
3.2.3 MVCC
- 解决事务过程中的读阻塞问题。
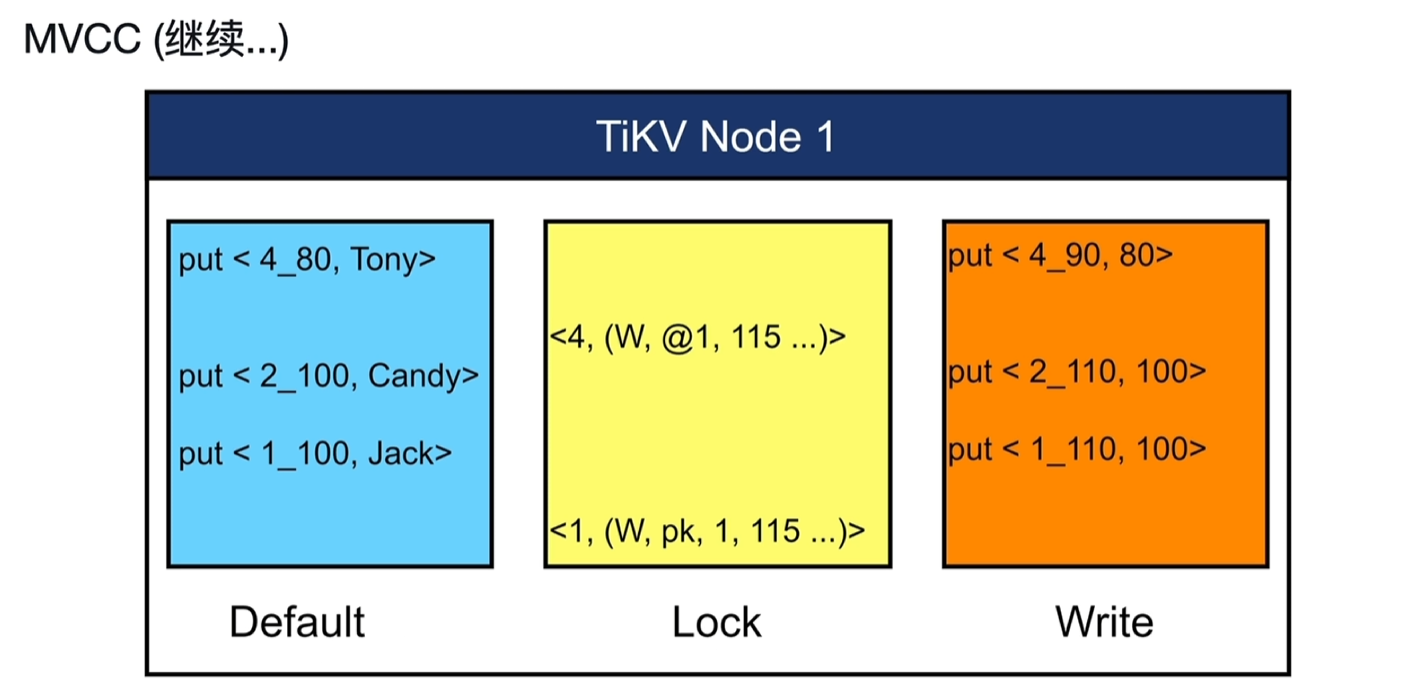
- TiKV不管修改还是删除一个值,都是采取的新增数据的模式。
- 下图中TS0=120时,1的值为Jack,2的值为Candy,4的值为Tony;如果没有MVCC,1、4都不能读取。 ![[Pasted image 20250910075448.png]] TSO=120时操作
- 读取1的值:在Write中找到1的最近一次的提交记录为1_110,拿着1_100读取Default中的值为Jack
- 尝试写1的值:在Write中找到1的最近一次的提交记录为1_110,但在Lock中找到了1时间戳为115的锁,此时阻塞不能修改。
- 尝试写2的值:在Write中找到1的最近一次的提交记录为1_110,在Lock中也没找到2的锁,此时可修改。
- 读取4的值:在Write中找到4的最近一次的提交记录为4_90,拿着4_80读取Default中的值为Tony。
- 尝试写4的值:在Write中找到4的最近一次的提交记录为4_90,但在Lock中找到了4有个依附于@1的主锁,再查主锁发现还锁着,此时阻塞不能修改。
3.3 Raft
3.3.1 部分基本概念
- region:数据存储的逻辑单元,tikv中默认为3副本,不同节点中同一数据的region组成一个raft group。
- region里面的key存储是有序的,一个region的默认大小为96MB,超过144MB时将分裂成2个region
- region是左闭右开的连接组别,例如region1为[1,1000),region2为[1000,1999)
- leader:同一个raft group中只有1个leader,负责读写,并将数据副本以日志的方式传递给follower。
- follower:被管理者,只会对其他的服务作出响应,接收leader的日志。如果长时间没收到leader的反馈,将会变成candidate,投票以选举出新的leader。
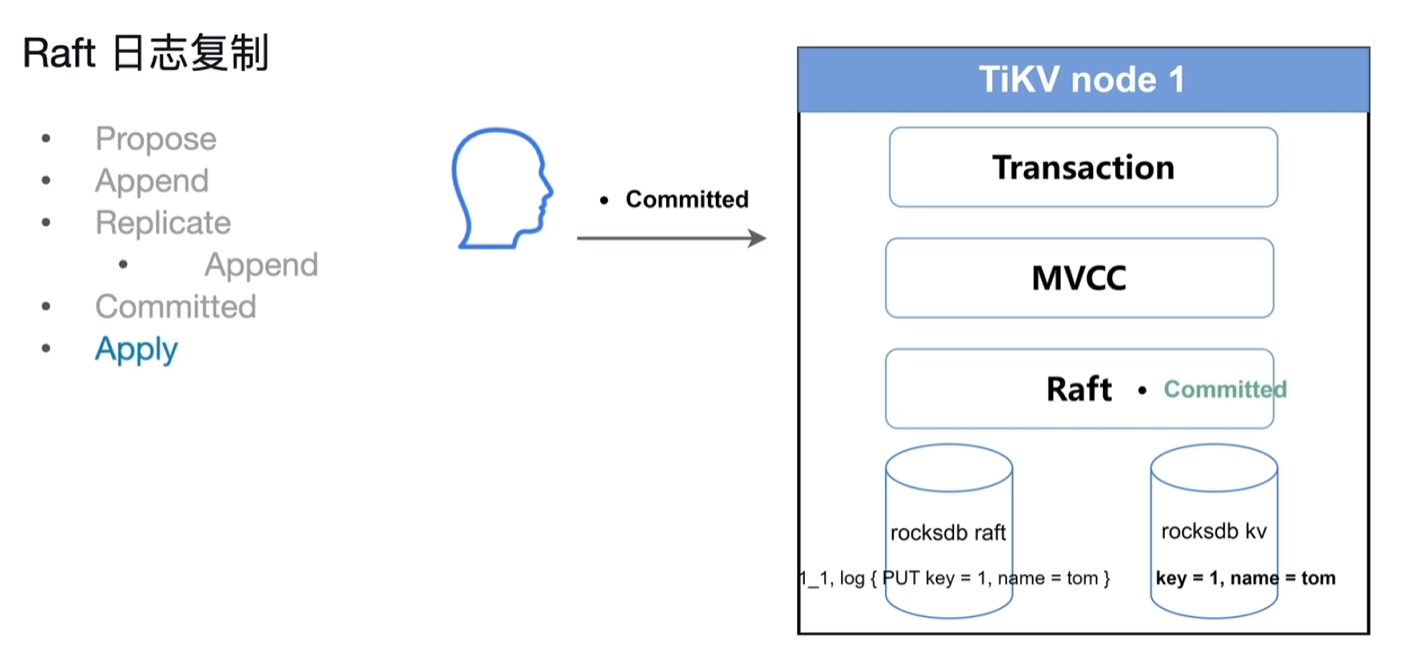
3.3.2 Raft日志复制
步骤
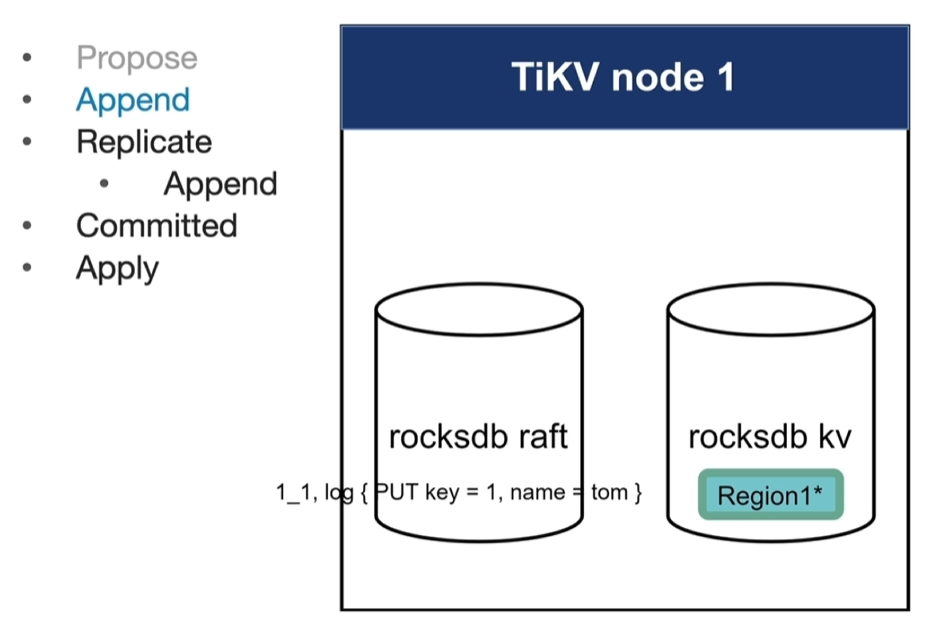
- propose:客户端将写入信息发送给TiKV节点(对应region的leader节点)

- append:leader接收到写入请求,将内容写入到raft日志中 (格式:reaginId_序号,log{PUT key=xx,name=xx},存储在leader当前节点的raftDb中,用来专门存放raft log的Db)
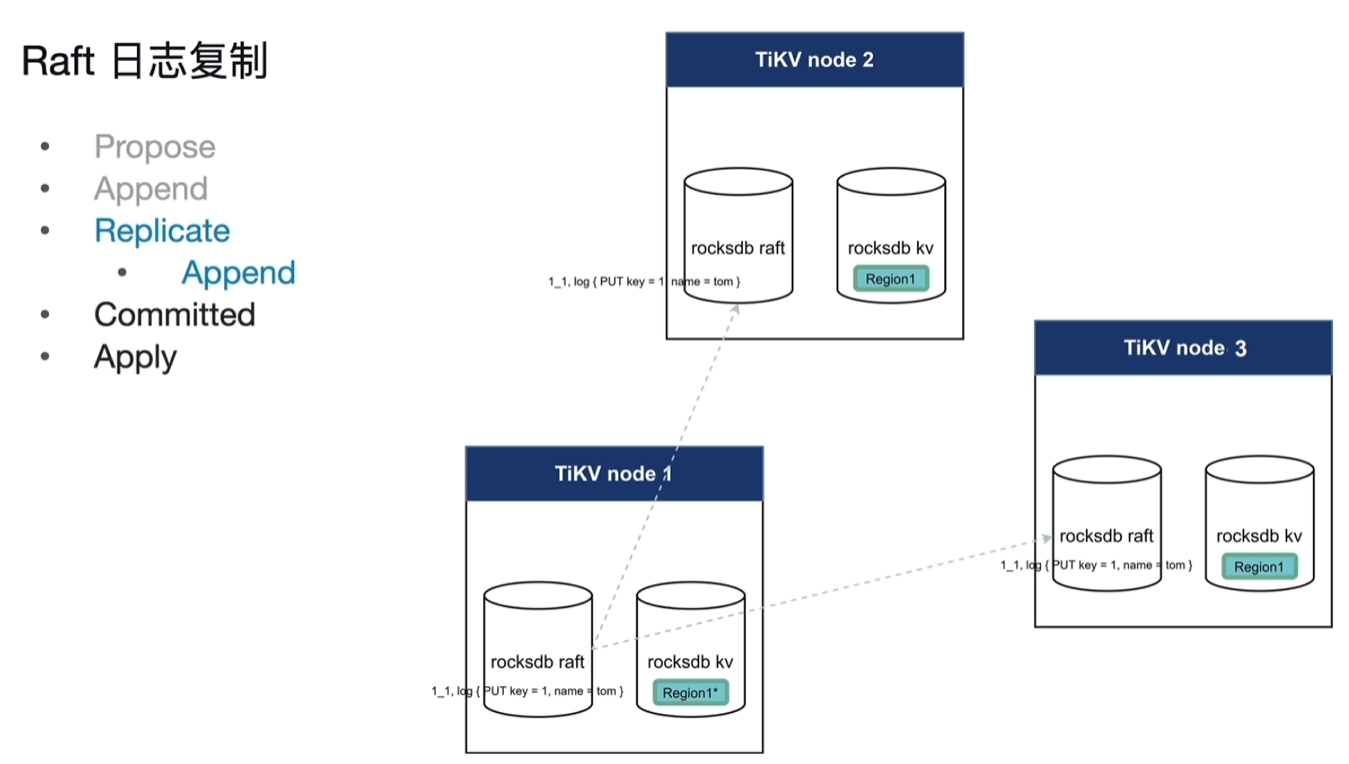
- replicate:将日志内容传递给follower,
append:follower各自进行自己的append将内容写入自己节点的日志中
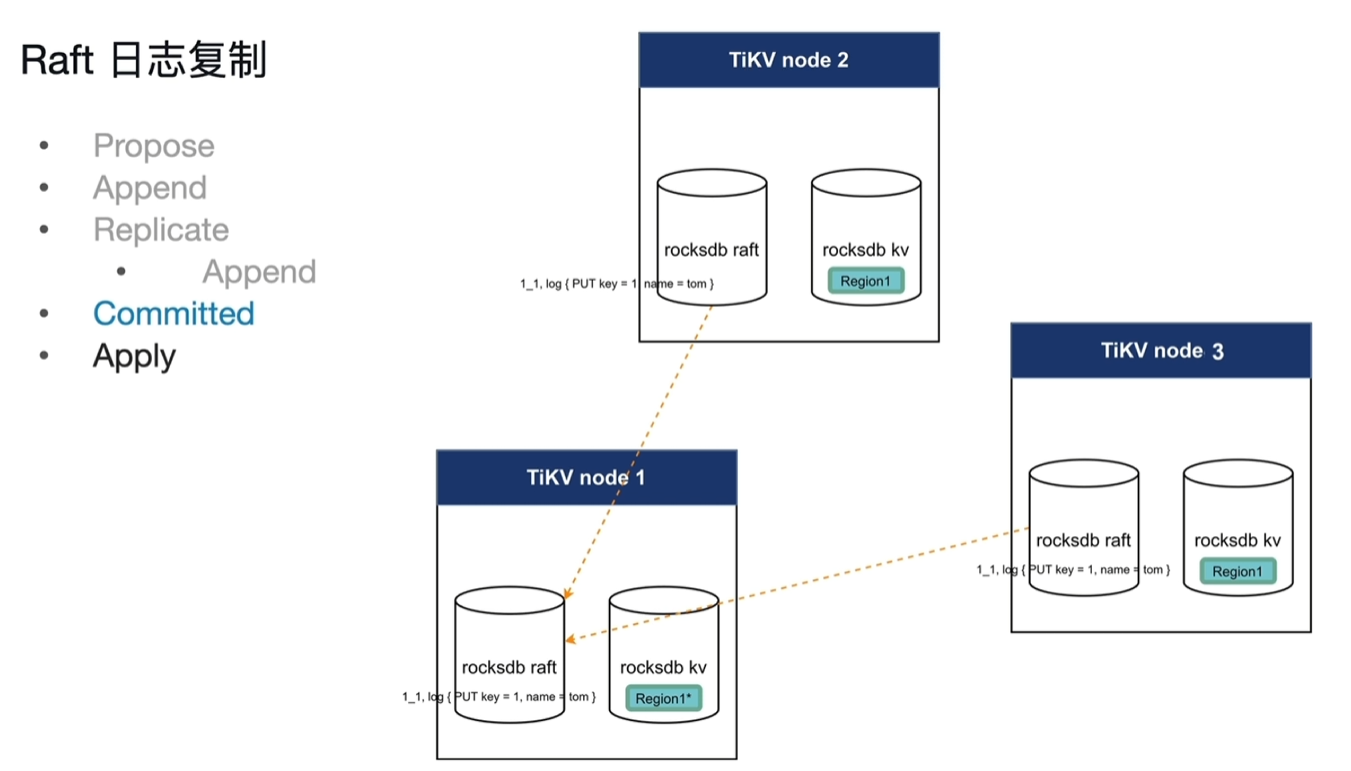
- committed:当多数的节点返回append成功消息后,视为committed成功。(此committed不是指sql应用中的committed,仅仅指raft log的committed)
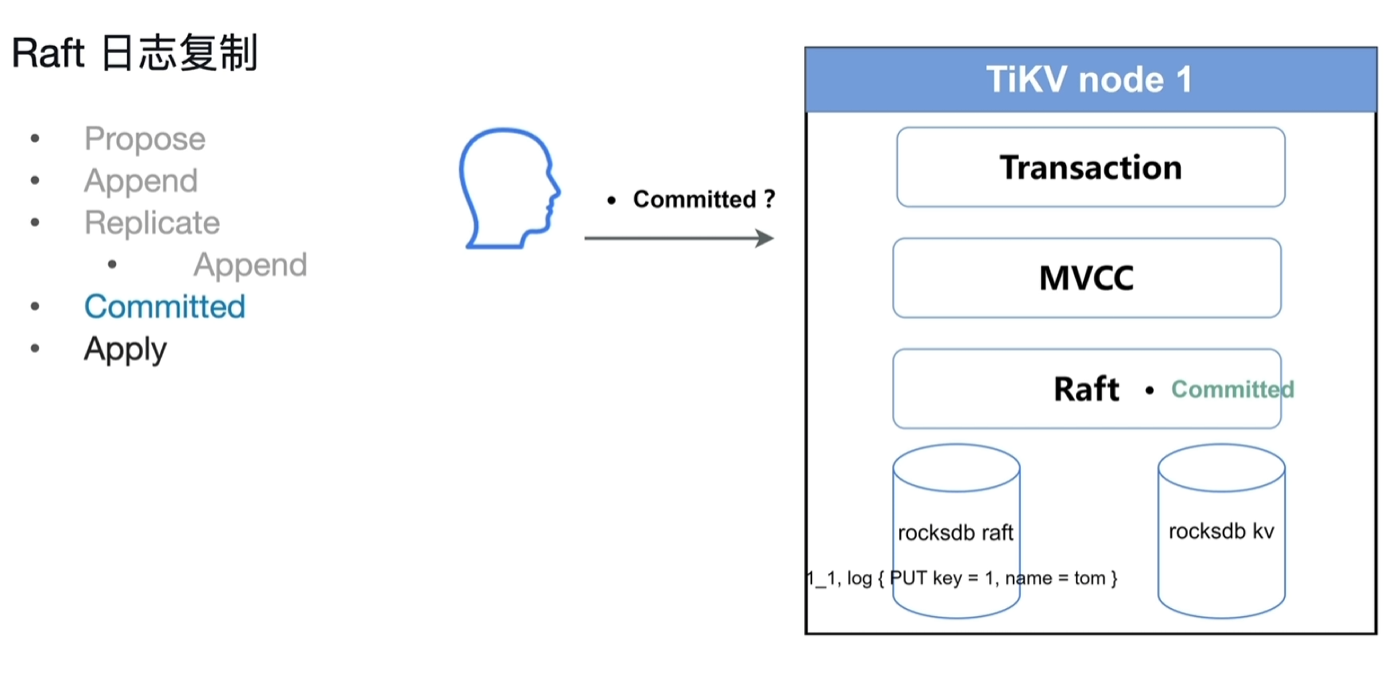
- apply:将raft log写入到rocksdb kv中,此时数据真正存到KV中,可以SQL读取。

3.3.3 Raft Leader选举
- term:一段时期的意思,raft共识协议将时间分成的一小段一小段的单位,代表一段稳定的关系,不是固定的长度。用一个递增的数据来标识。
- election timeout:选举超时周期,校验集群中长时间没有leader将发起投票的超时时间
- heartbeat time interval:心跳周期,接收到leader发送心跳的计时器,假设为10s,正常从0开始计时,经过5秒后变成5后,收到leader发送的心跳,便重新变为0计时。
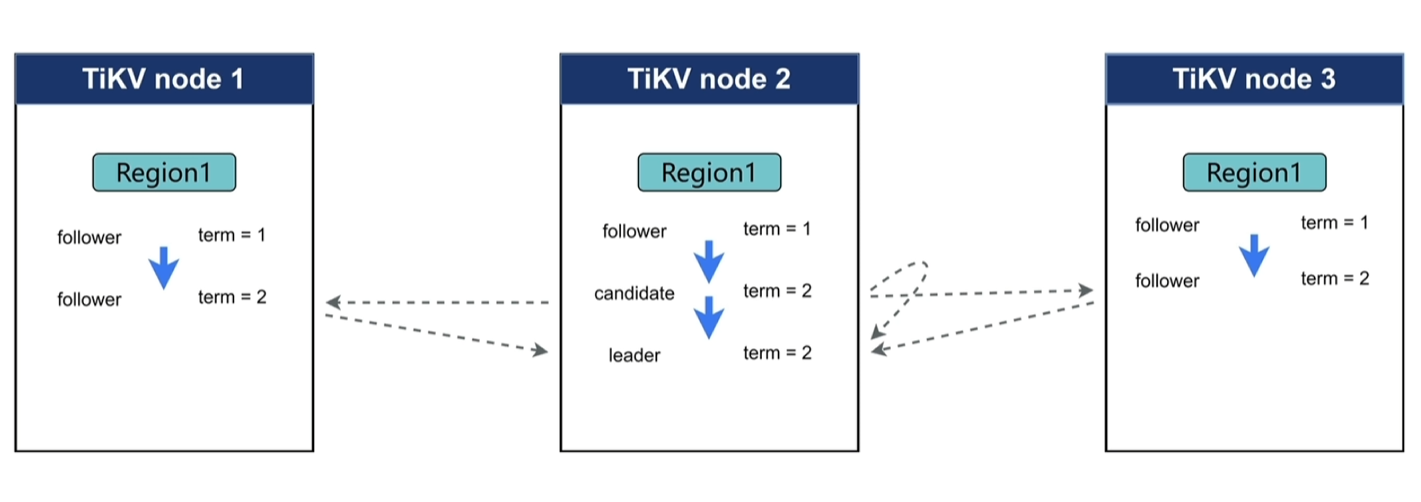
- 初始状态:最初启动时,所有region节点都是follower,此时各自会等待leader的信息,超过election timeout后,会认为集群中没有leader,哪个节点率先超过timeout时间后,该region角色由follower变成candidate(term1变成term2),发起选举并将term2给其他节点,其他节点收到投票请求后对比请求的term2比自己的term1大,同意投票返回给candidate节点,成功转变为leader(超过一半的投票即成功,包括自己的一票)。
- 进行中突然宕机:follower在超过interval时长后未接收到leader心跳消息时,转变为candidate进入下一个term,发起选举流程。
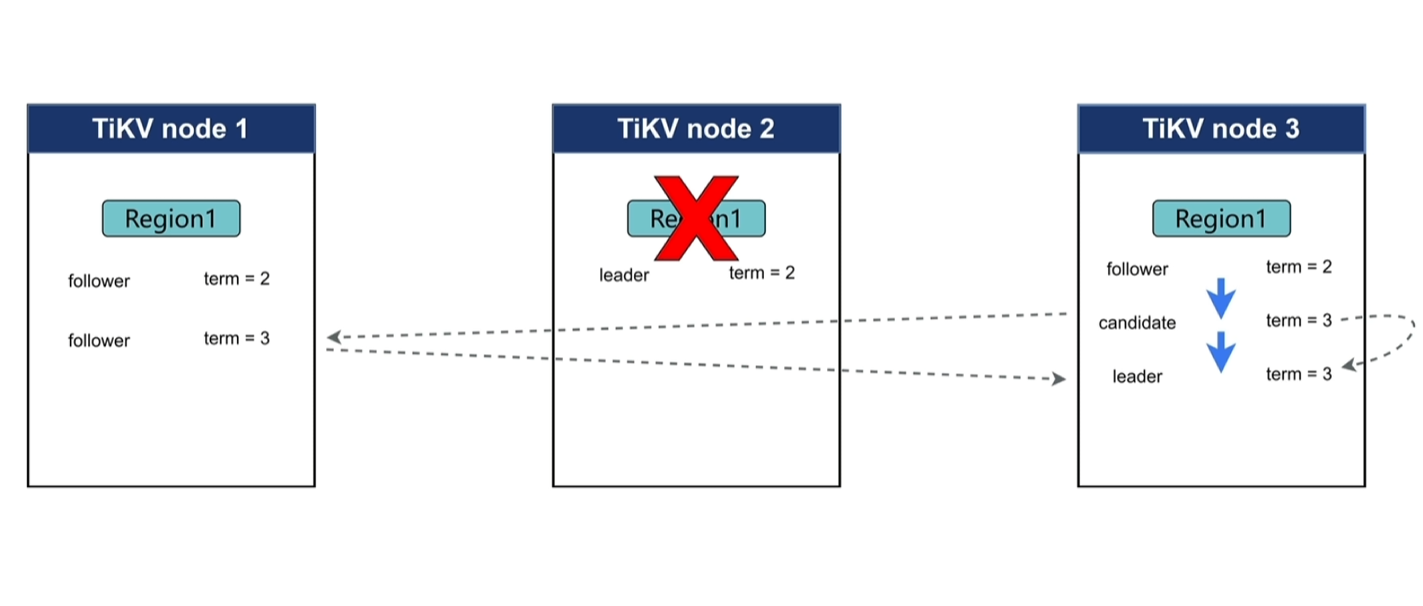
- node2恢复后变成candidate,但会发现其他节点的term更高,将会转成follower。
- 初始阶段特殊情况:初始时若刚好存在2个以上的节点同时timeout并发起选举,这时就会失败,系统会重复发起多次选举,直到选举成功。
- tidb加入了一个random变数解决该问题,即election timeout设置一个区间值,如(100ms-300ms),这样每次会是一个随机timeout值,就能很高概率的避免同时选举的场景出现。
- 一个ticks是一个时间单位,对应一个interval,即1秒。
- raft-election-timeout-ticks不能小于raft-heartbeat-ticks,tikv中默认配置timeout为hertbeat的2倍以上。

3.4 读写与Coprocessor
- 这里的写入暂时忽略MVCC、Transaction的过程,只关注Raft的写入。
3.4.1 数据的写入
- PD:提供时间戳,还有写入的数据在哪一个tikv的那个region上。
- raftstore pool:线程池,收到写请求转换为raft日志,持久化存储,发送日志给其他节点,接收其他节点的成功响应。
- apply pool:线程池,将日志数据写入到kv中。
- 用于能读到的数据都是最终进入KV中后的。

3.4.2 数据的读取
- 读取时需要从PD获取时间戳及key对应的leader在哪个节点
- 读取过程中有耗时,读取时会向其他节点发心跳确保读的节点是leader。

- ReadIndex Read
- 读取线性一致性:在一个时间修改了数据,在之后时间读取到的一定是这个修改后的数据。
- 注意这里是抛开了MVCC机制单独来看的Raft层。
- 10:00时用户修改了如下图所示的1将tom改为jack,对应数据的raft log时间节点为1-95。
- 10:05时用户读取key1的值,当前时间的raft log的commit进度为1-97,这个值记录为ReadIndex。
- 10:08时1-95时key1的值apply成功,存储到了KV中。
- 10:09时用户读取的操作还在等,等到ReadIndex1-97时其对应的数据apply成功,此时能够保障之前的95一定apply成功,这时读取成功,保障了数据一致性。

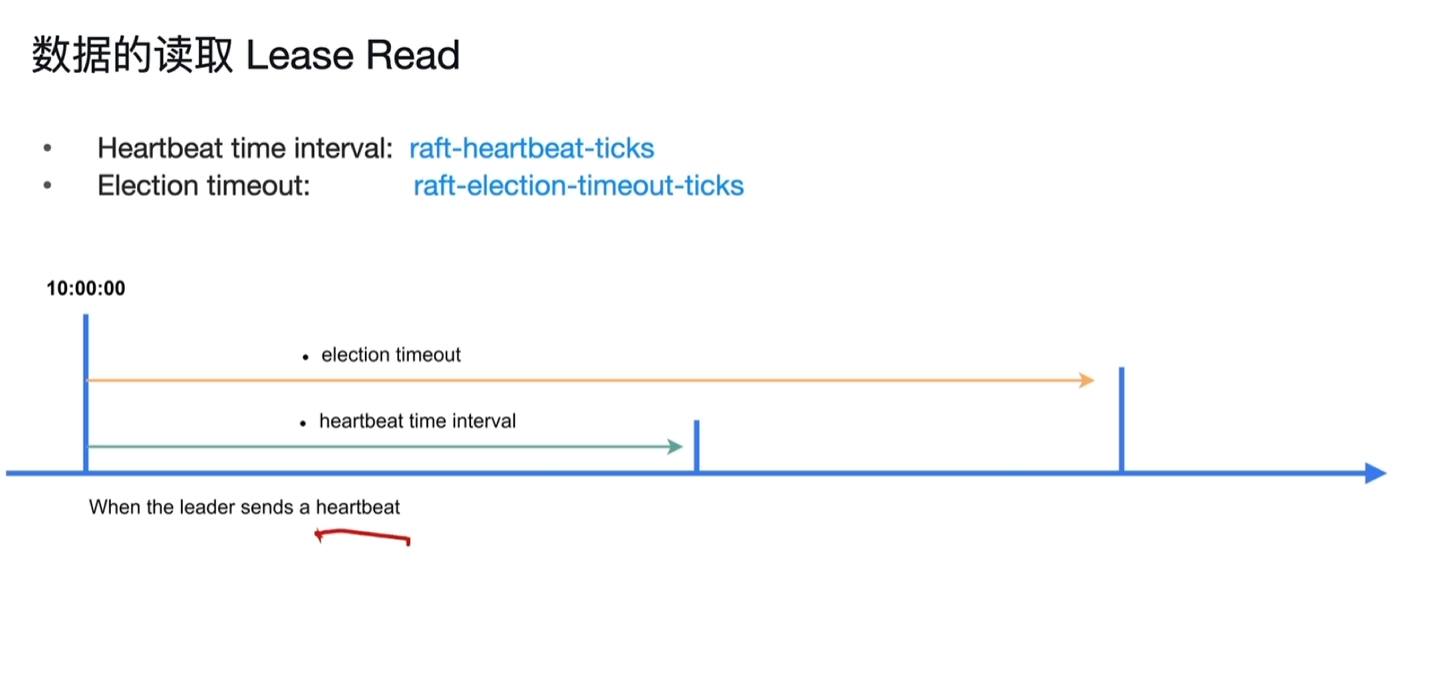
- Lease Read
- 确保当前的节点为leader,会给其他节点发送心跳确认是否为leader,针对这个过程的优化读取就是Lease Read。
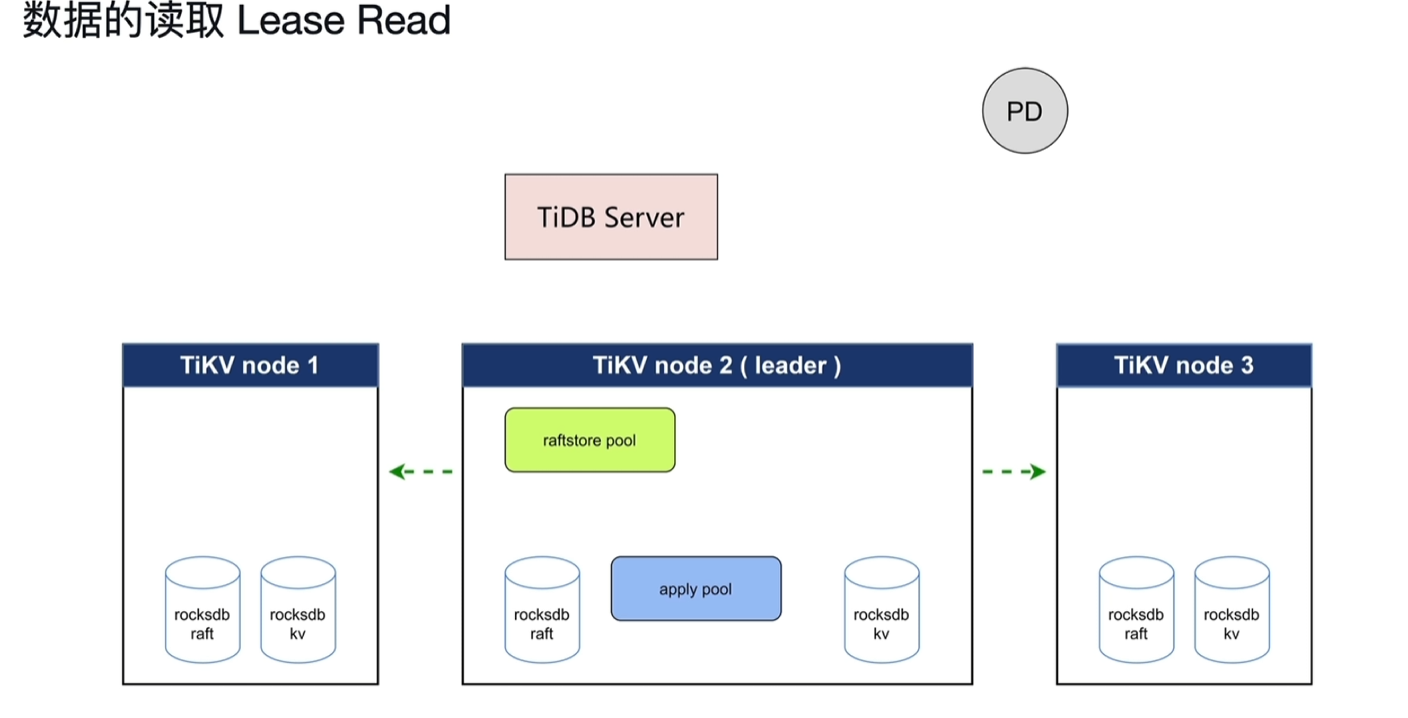
- 10点时leader节点发送心跳成功后,在heartbeat time interval时间范围内,能保障其肯定为leader。
- 10点时到election timeout的时间段,哪怕其他节点没收到心跳,这个时间范围内也来不及重新发起选举,也能保证其还是leader。
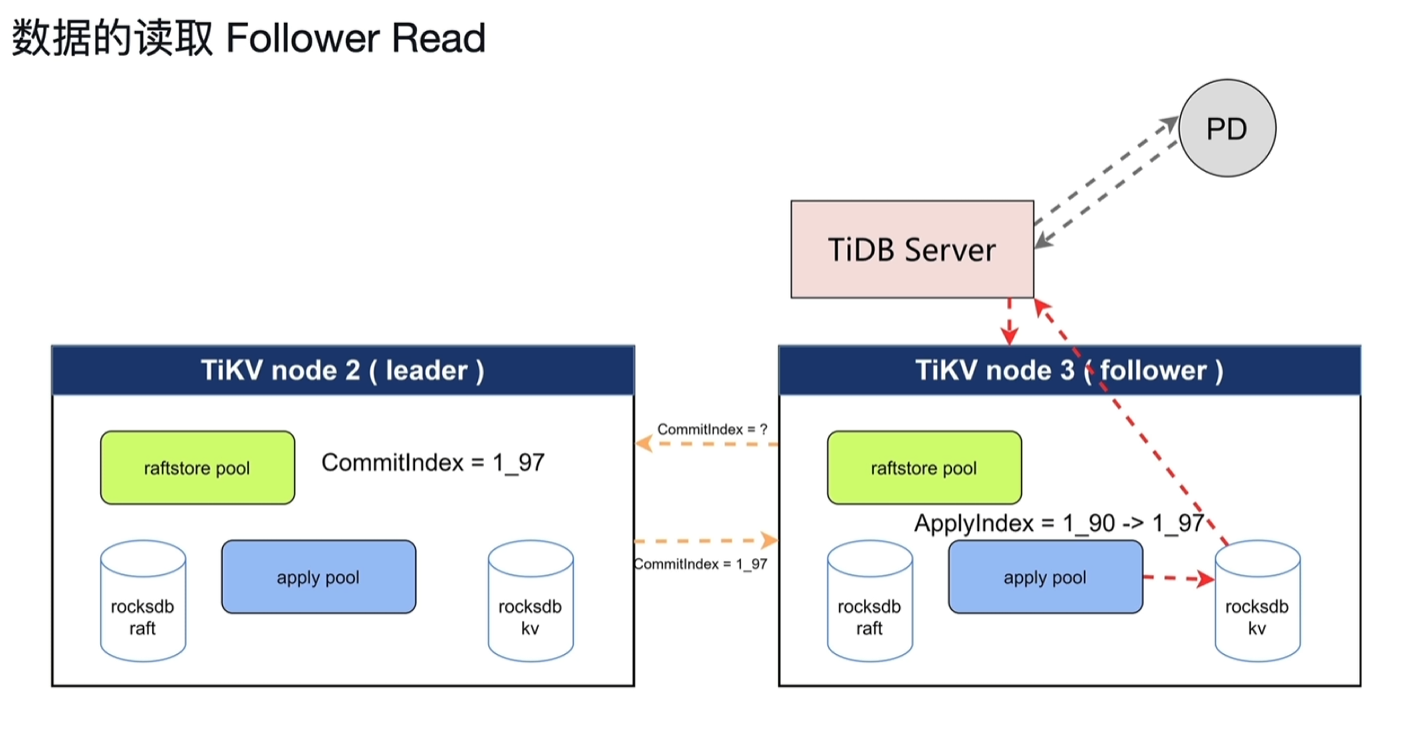
- Follower Read
- 在follower节点中读取数据,以减轻leader节点的读取压力。难点在于怎么保证线性一致性。
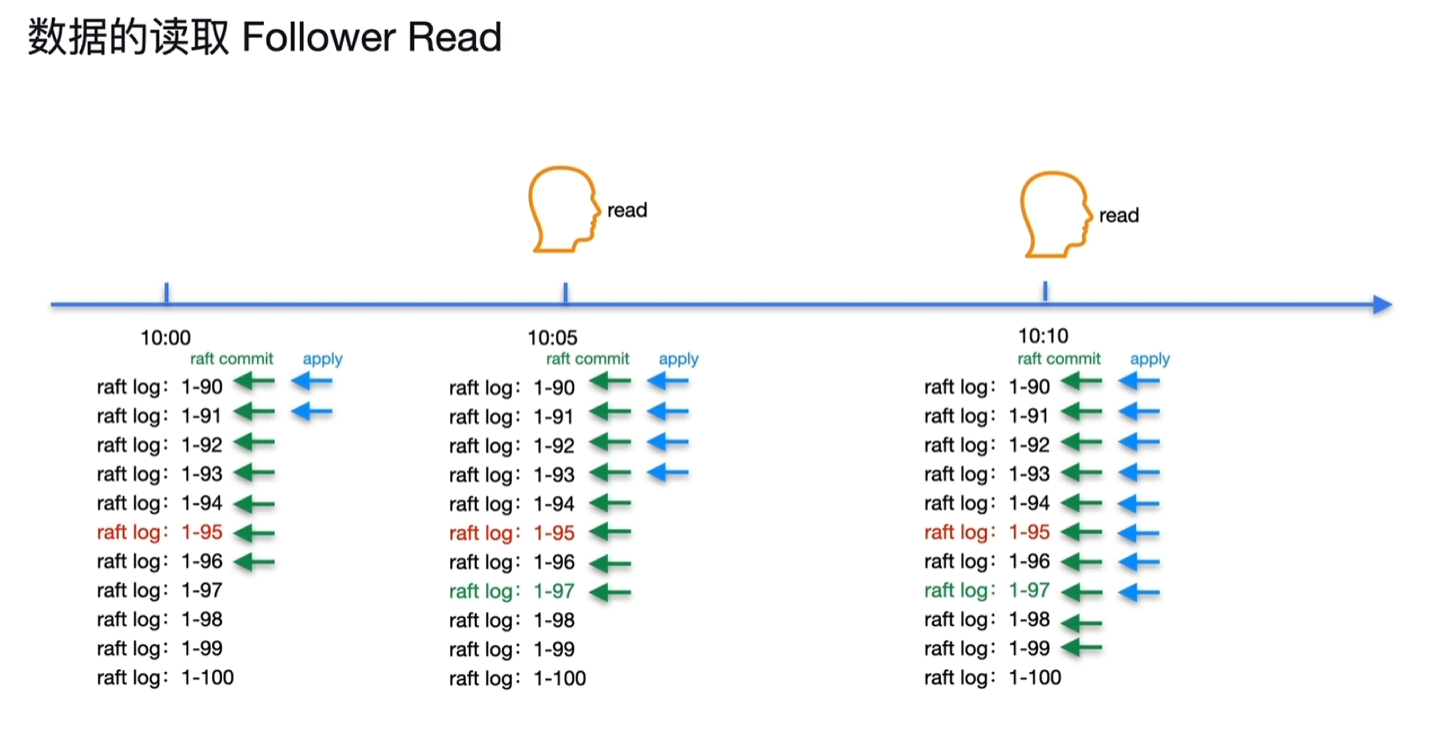
- 下面的2张图分表为leader节点和follower节点的时间轴关系
- 10:00的时候,leader节点写入了一个数据,如图一所示,对应数据的log时间节点为1-95
- 10:00的时候,follower节点如图二,跟leader节点apply进度有所区别。(不同节点也正常)
- 10:05时,用户在follower节点进行了数据读取,此时raft commit的日志为1-97,记录为CommitIndex,这个时间戳apply完成时,之前的时间戳的日志一定就apply完成了。
- 10:08时,leader节点的数据实际写入到KV中
- 10:10时,follower节点的log1-97才被apply,此时读取到key的数据,即能保障1-95的数据能正确读取到。

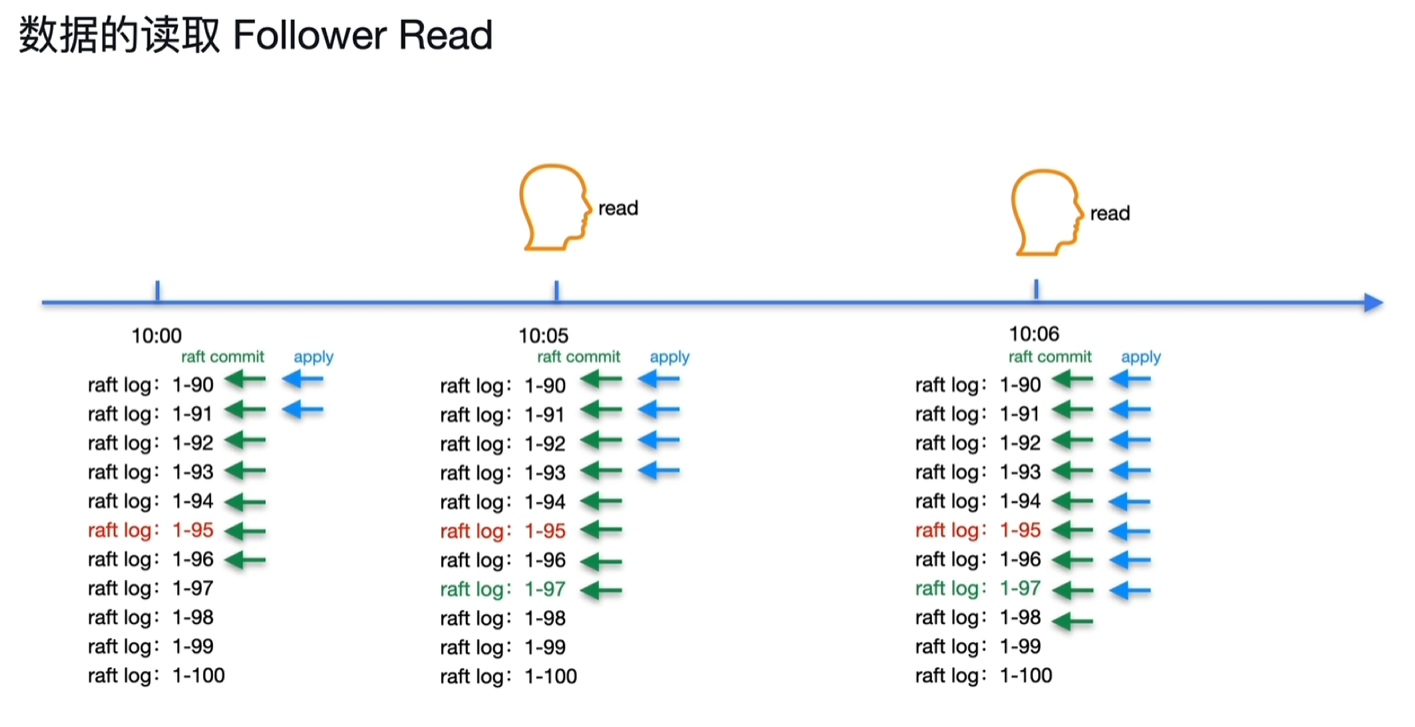
- follower节点有可能性能很快,如下图所示,1-97的apply进度缩短到了10:06,比leader节点时间数据commit的10:08实际存储到位还要早。
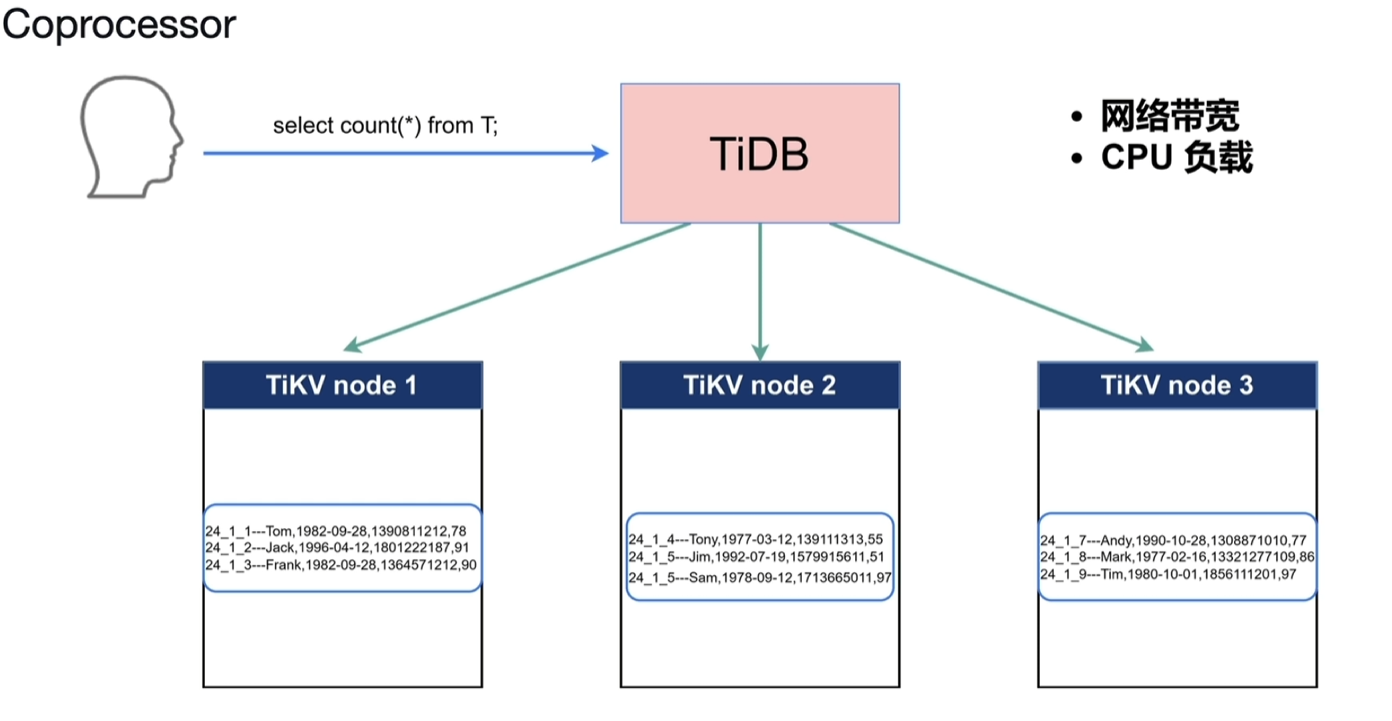
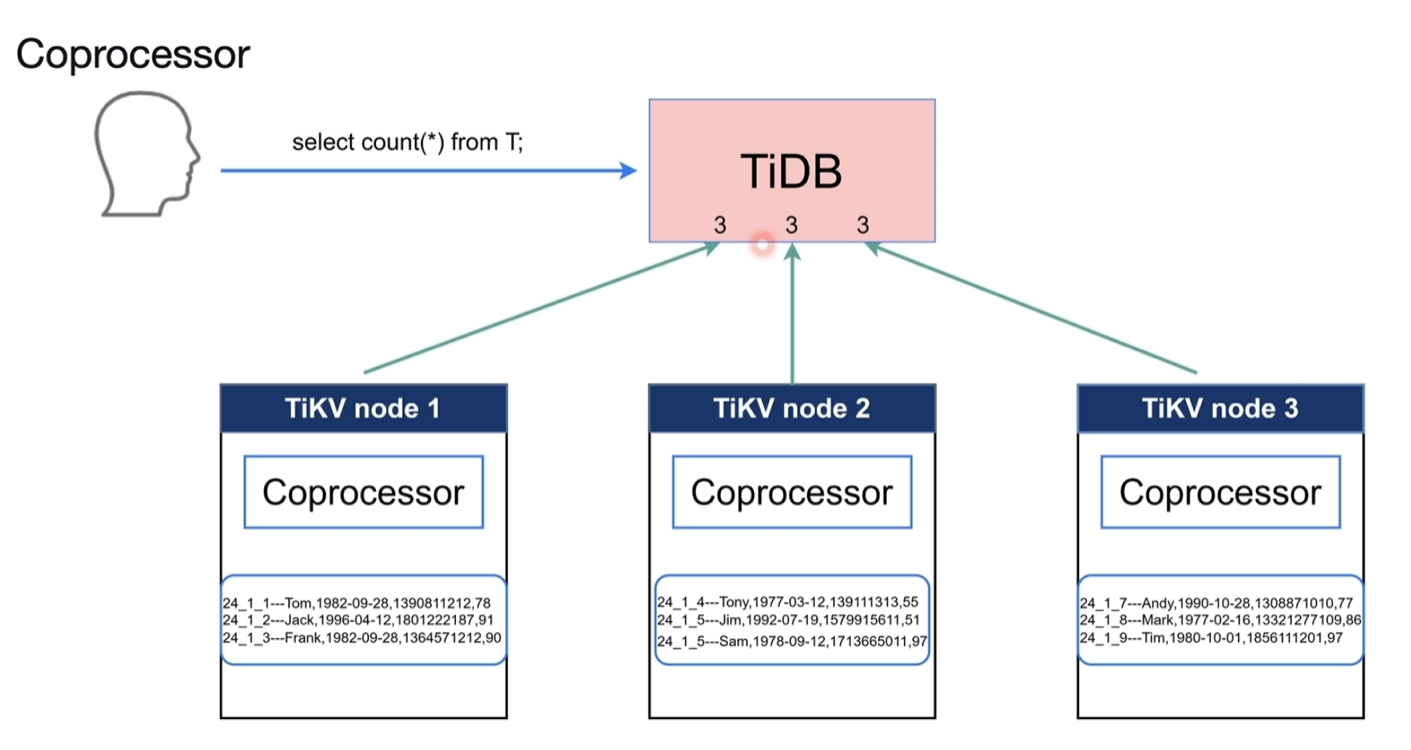
3.4.3 Coprocessor
- 如下图所示计算T的数量,T表的数据又散落在不同的KV节点中,如果将数据全部汇总到TIDB中,网络开销和CPU计算负载都很高。
- 借助TiKV节点进行一些计算和过滤,将结果交给TiDB即为Coprocessor,帮组做算子下推的工作。
- 执行物理算子,为TiDb计算结果,减少网络和CPU开销
- 常见的table scan、index scan等
- 分析数据的统计信息、采样
四、Placement Driver
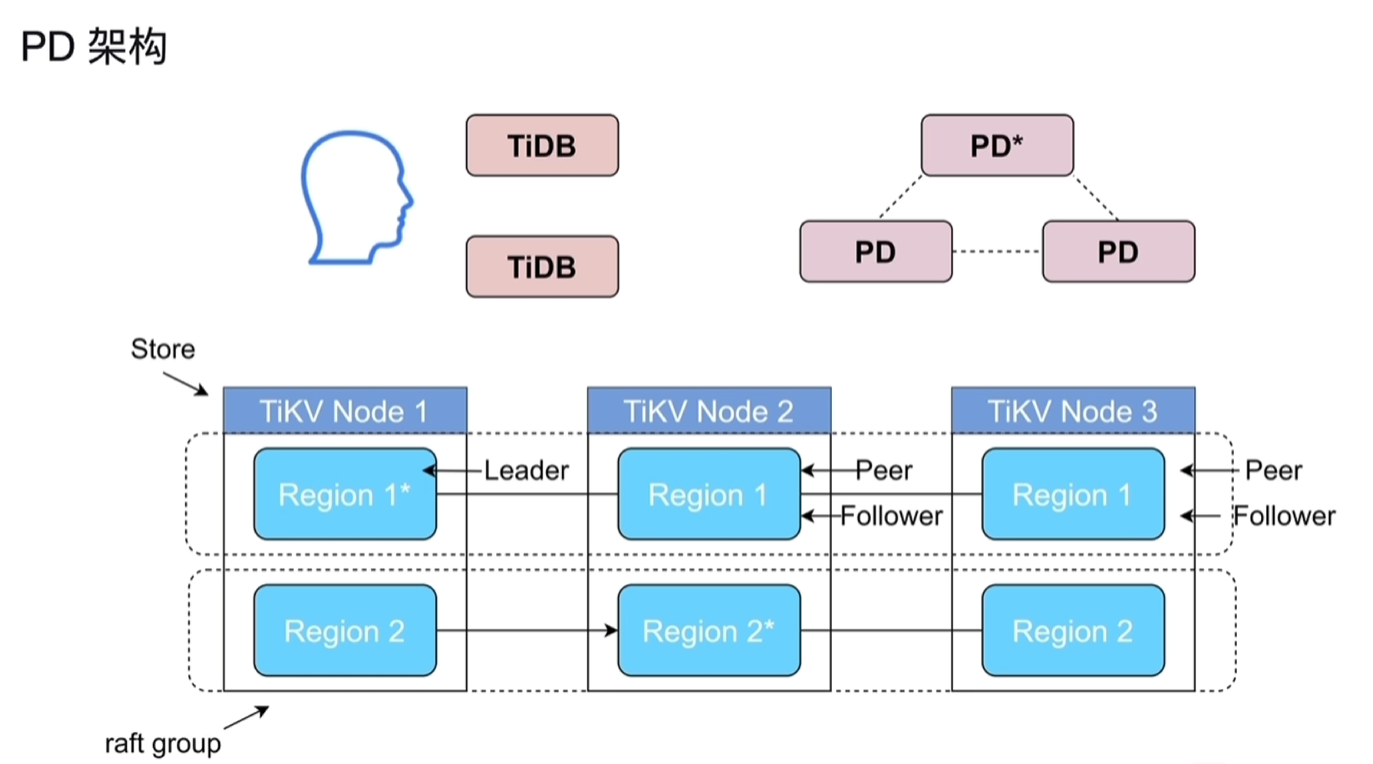
4.1 PD的架构与功能
- PD默认3个节点,其中同时只会有一个leader角色,通过raft协议来保障其高可用性。
- Peer:region的副本又叫Peer。

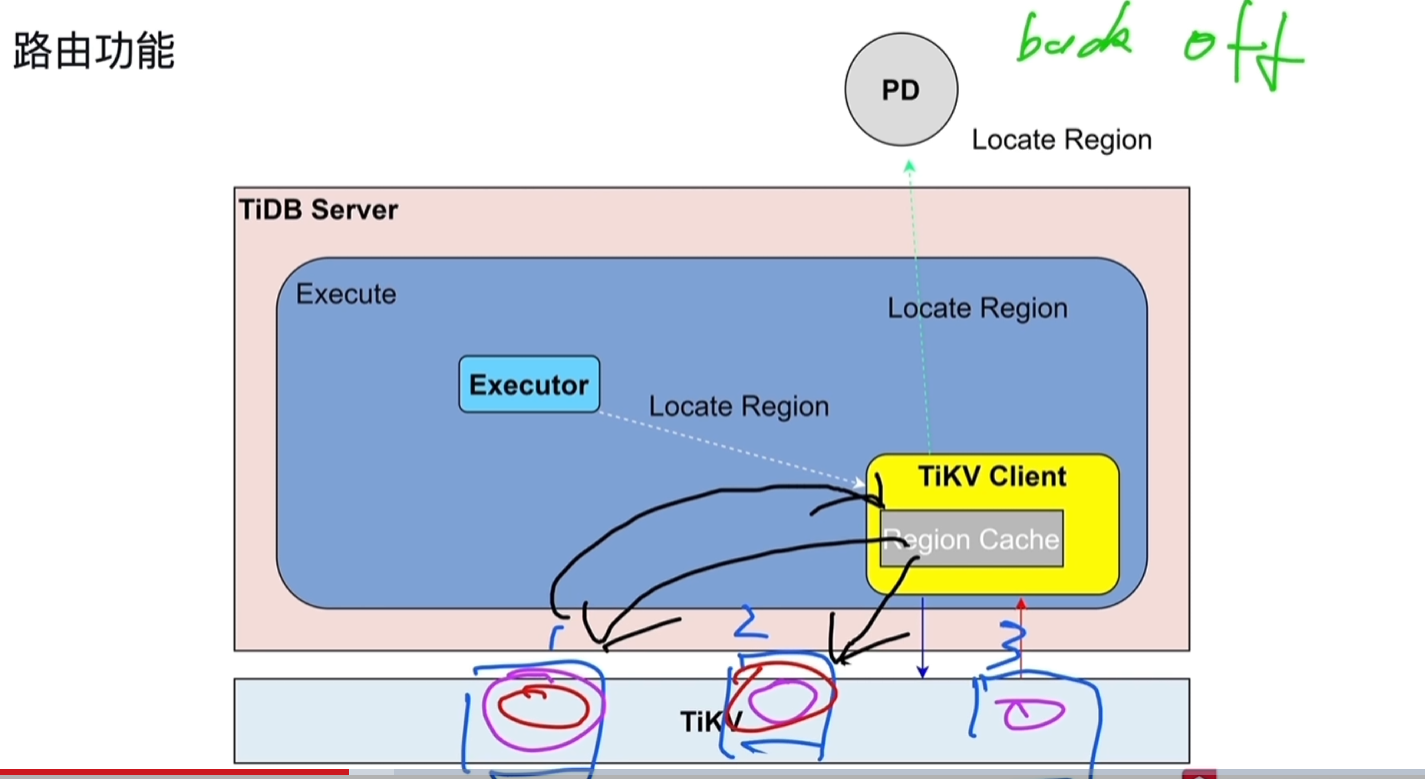
- PD存储了所有region的分布情况,会缓存到TiDB Server中TiKVClient的Region Cache中,减少读取开销。
- back off:region的leader节点变化后会告知tikv client原本的已经失效,需要从PD中从新去载入。
4.2 TSO的分配
- TSO = physical time logical time
- 前面部分为物理意义的时间
- 后面的逻辑时间能将1ms分成262144个TSO
- TSO是一个int64的整型数
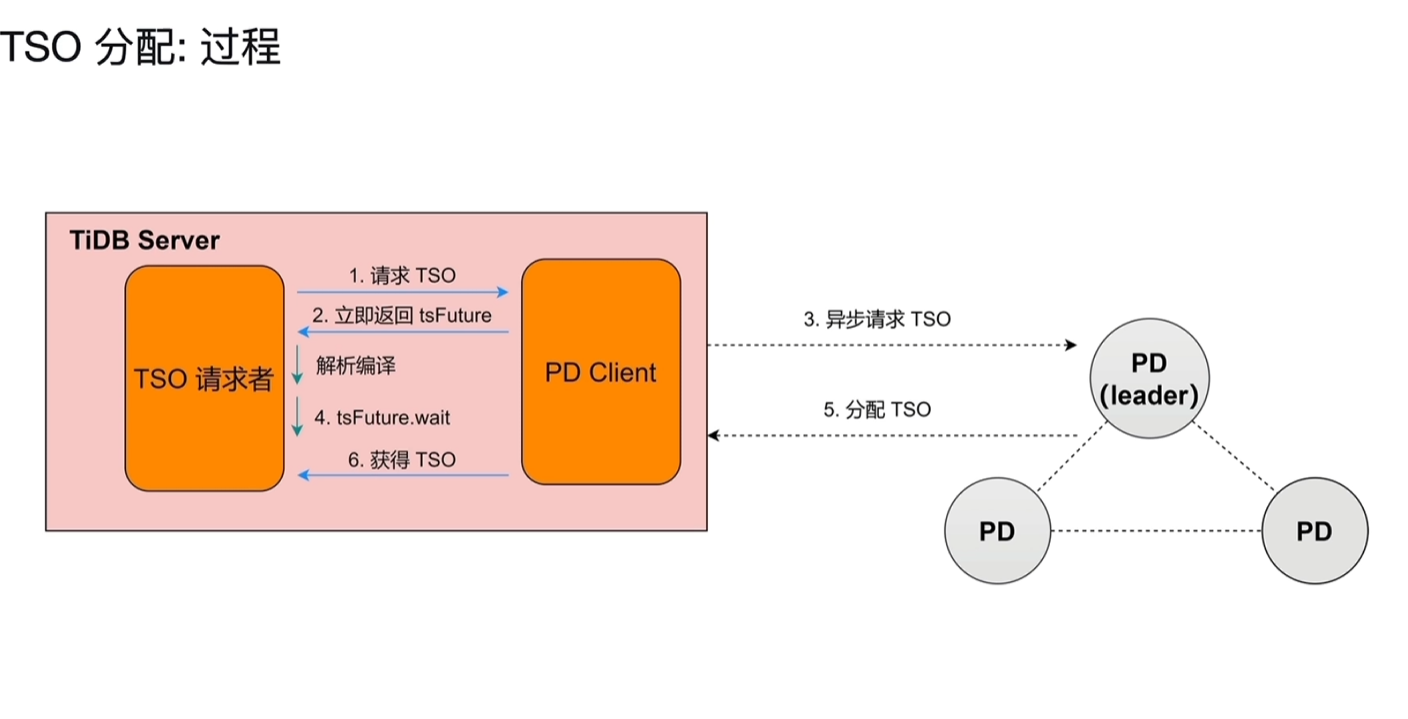
4.2.1 分配过程
- sql在刚开始执行的时候会请求TSO,事务会在开始和结束时候请求TSO。
- 4、5的节点谁先完成,谁就要先等另一方。2、4和3、5是异步分开同时进行的。
- 每个sql都会请求TSO,请求数、并发量会很大,PD Client不会来一个就执行一次3操作,会一次性将一批请求一次发给PD。这个通常是限定一个时间段,比如将5ms的请求一次批量发给PD,如果5ms内只有一个请求,也会发出去。
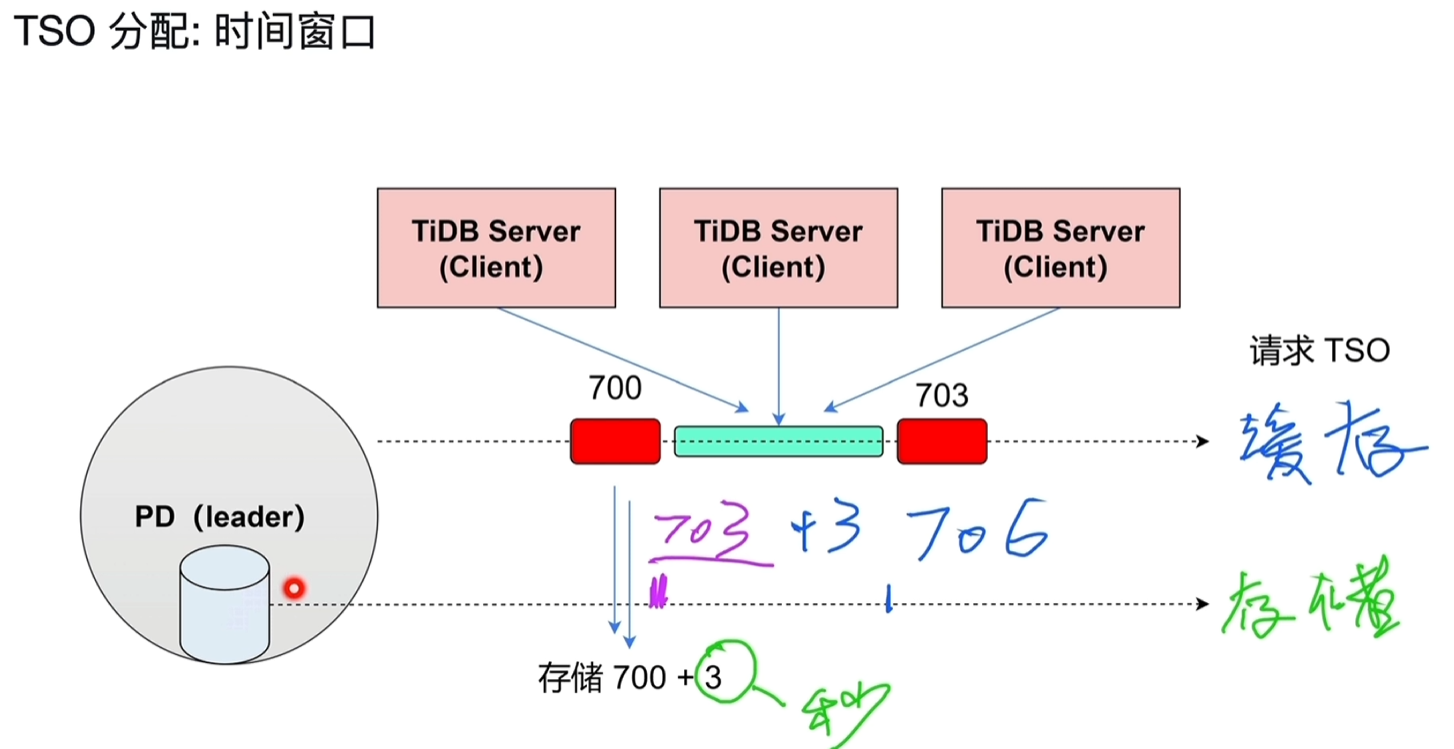
4.2.2 时间窗口
- 解决性能问题,因为tidb server可能会不停的发送TSO请求,这个请求最终落地到PD分配后会存储到PD节点,产生IO。
- 如下图所示,PD一次分配3秒的TSO,放在缓存中供使用,在队列里排队使用。
- 3秒后用完了,再分配至706,这样磁盘的IO是3秒1次。
- 这个过程中leader如果分配了703-706的TSO,其他follower节点的PD也会同步分配703-706。
- 注意这个过程中假设leader节点的TSO在缓存中分配到了704,这时leader宕机了,通过选举出现了一个新的leader节点,这时新的leader节点是无法知道宕机节点缓存中实际分配到704的,只知道之前同步已经最大分配到了706,会重新分配新的TSO:706-709。
- 通过上一条机制实现高可用,保障TSO不会重复,但并不能保障TSO的连续性,如上诉704-705直接会丢失。
4.3 PD的调度原理
- 信息收集
- TiKV节点周期性的向PD发送心跳信息,还有当前节点的存储信息、Region信息。
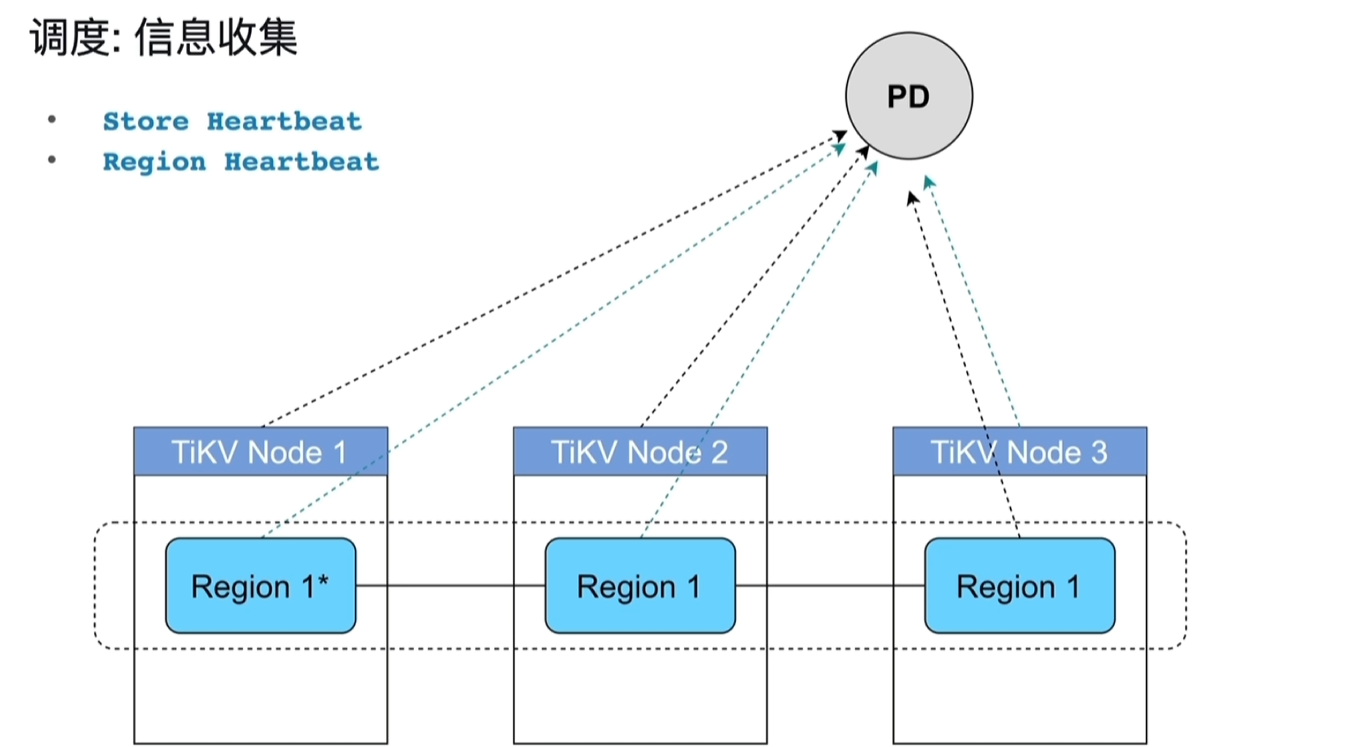
- TiKV节点周期性的向PD发送心跳信息,还有当前节点的存储信息、Region信息。
- 生成调度(Operator)
- Balance:存储的均衡和读写的均衡
- Hot Region:热点region太集中,将其打散放在不同的节点
- Region merge:一些数据、表删了后,将数据少或空的region进行合并

- 执行调度
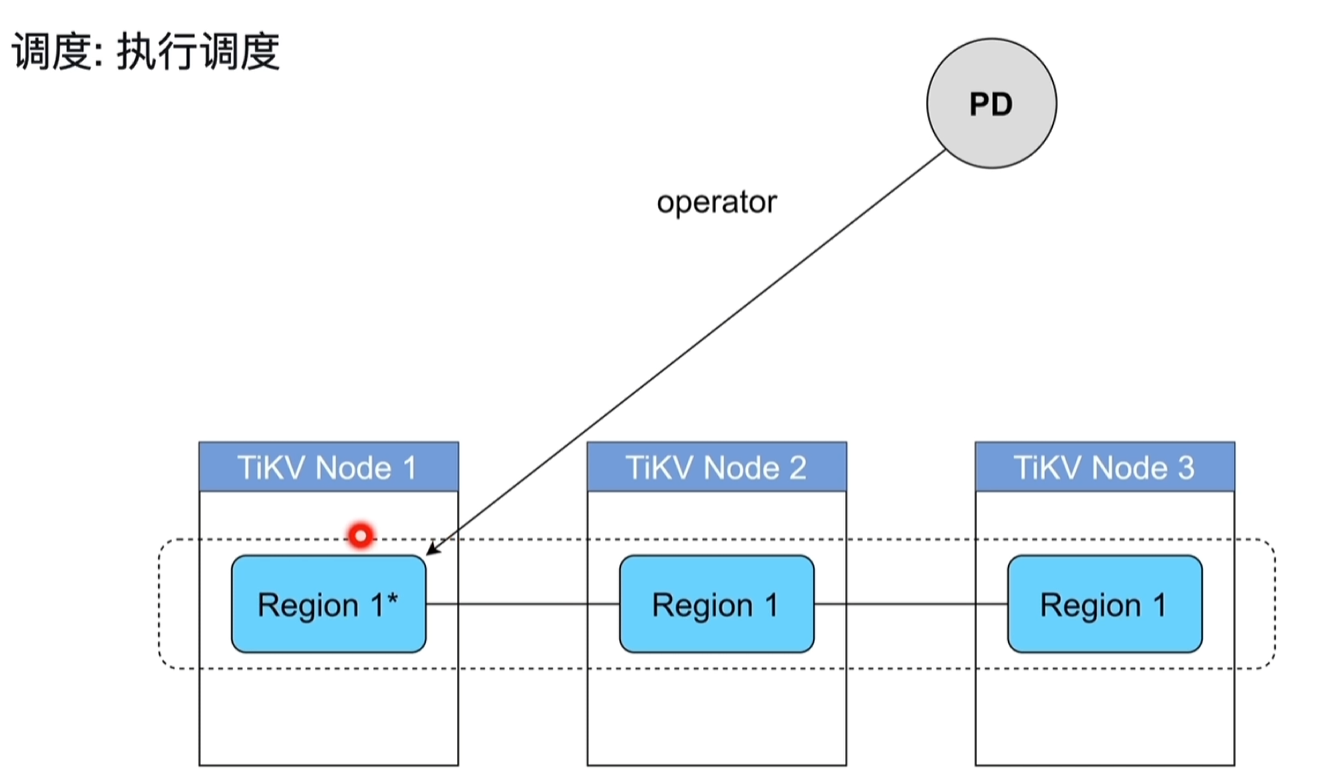
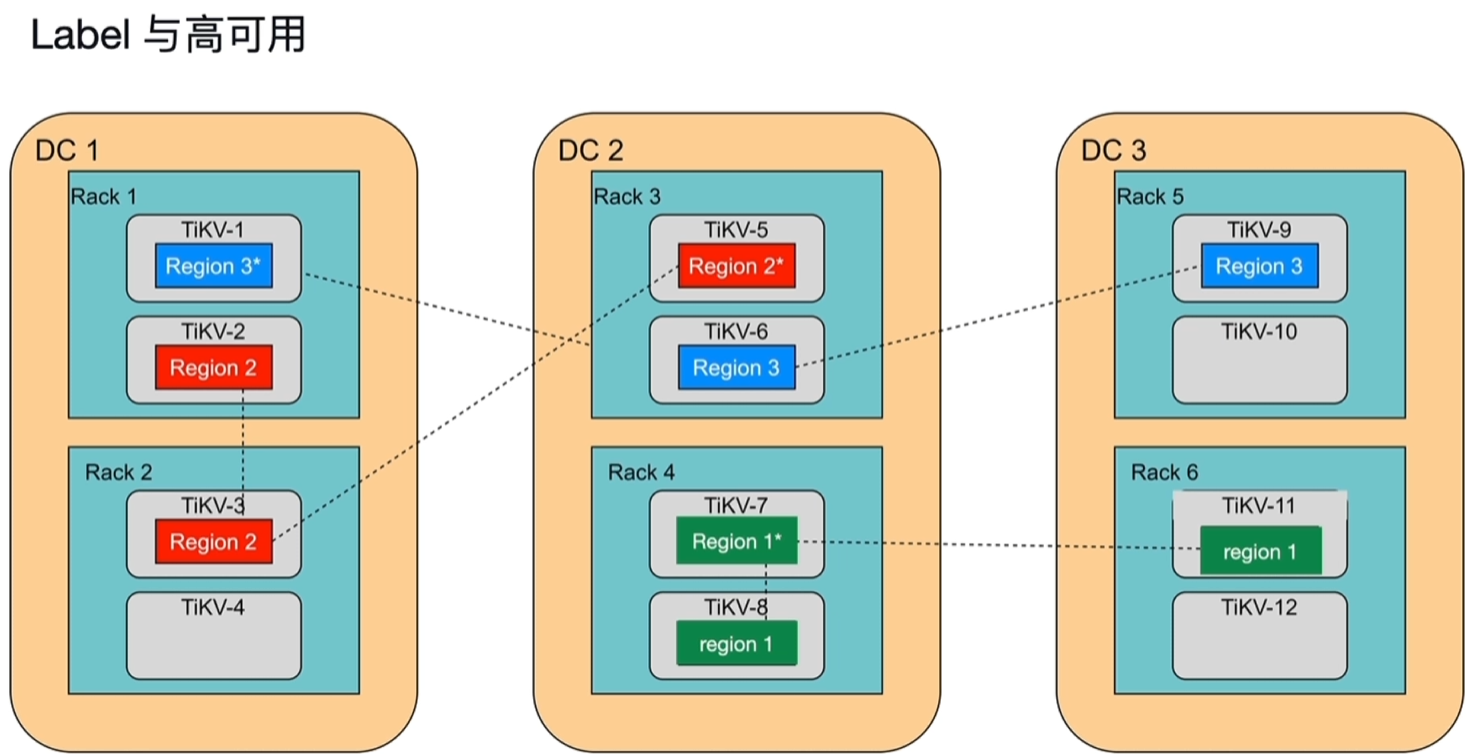
4.4 label的作用
- 下图中DC代表独立的数据中心,RACK代表机柜、TIKV代表主机。
- region1的3副本中2个副本在一个机柜上,rack4机柜或DC2一出问题就不可用了(3副本1个挂掉还能用,2个就不行了)。
- region2一旦DC1出问题就不可用了。
- region3每个region都在独立的DC\RACK\TIKV中,稳定性最高。
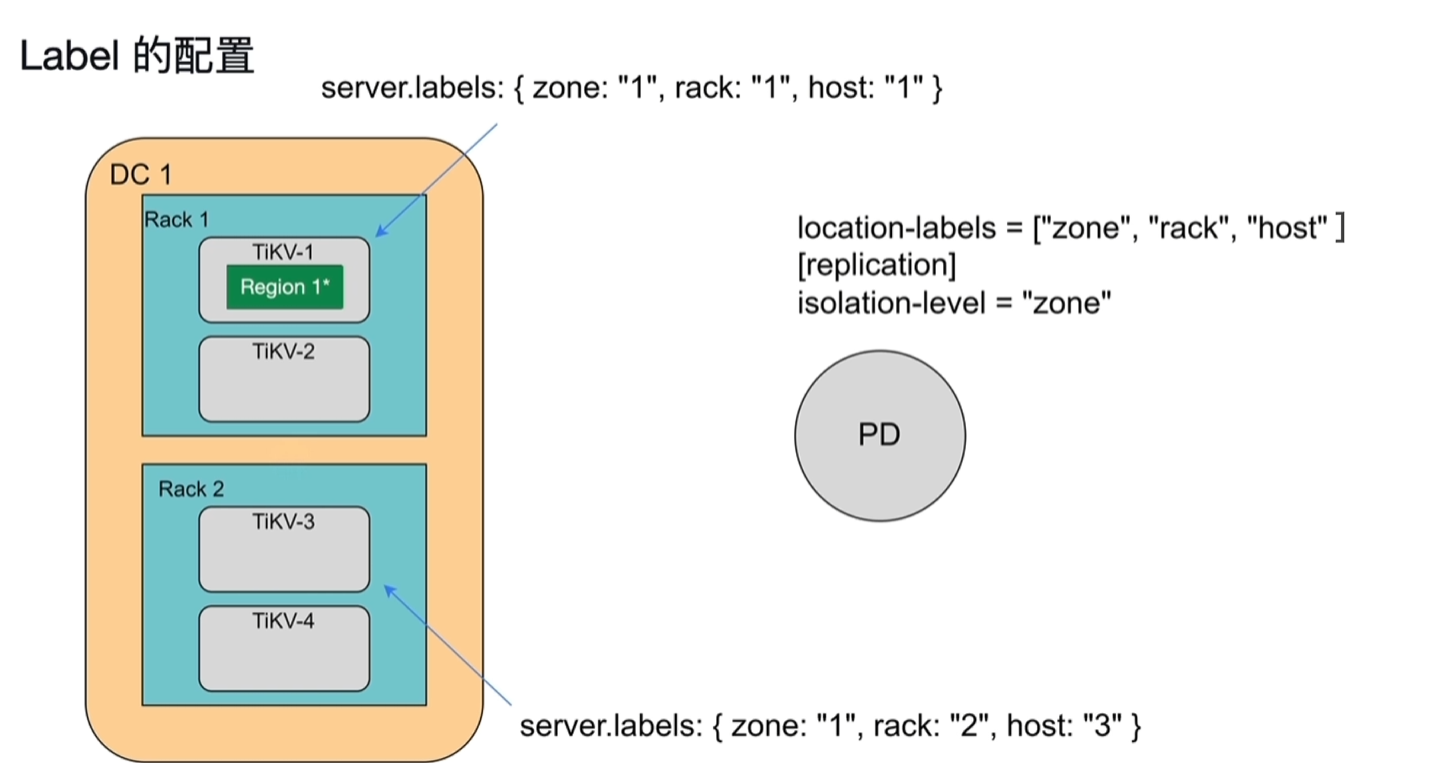
- Label的配置
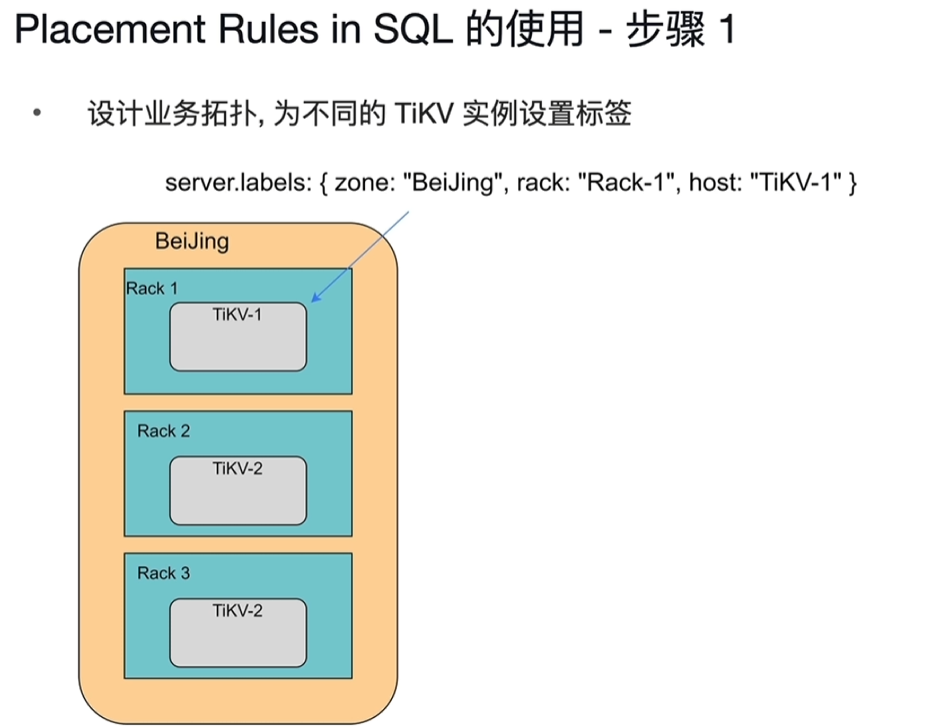
- TikV节点上配置 server.labels:{xxxxxx}
- PD上配置location-labels、isolation-level
五、SQL执行流程
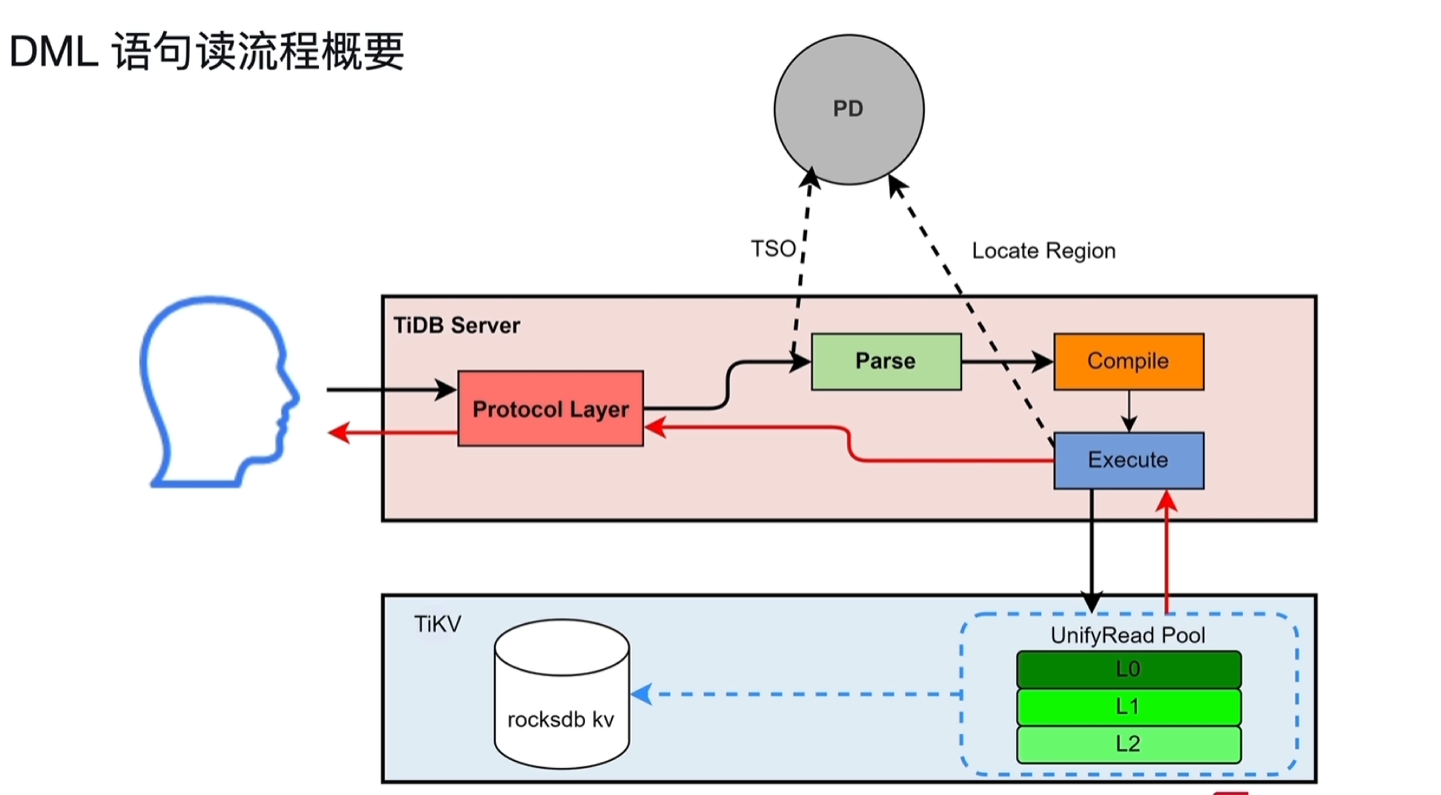
5.1 流程概要
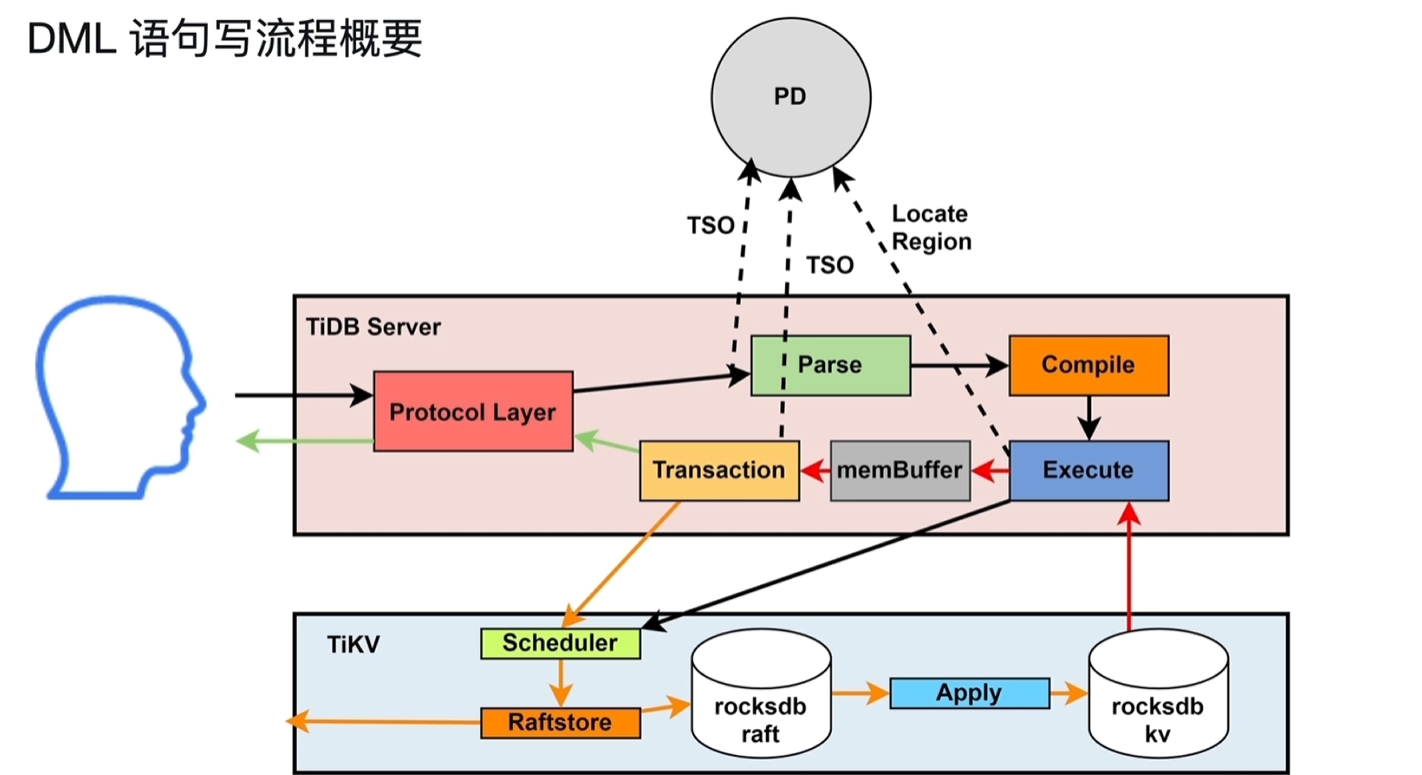
- DML读流程概要
- DML写流程概要
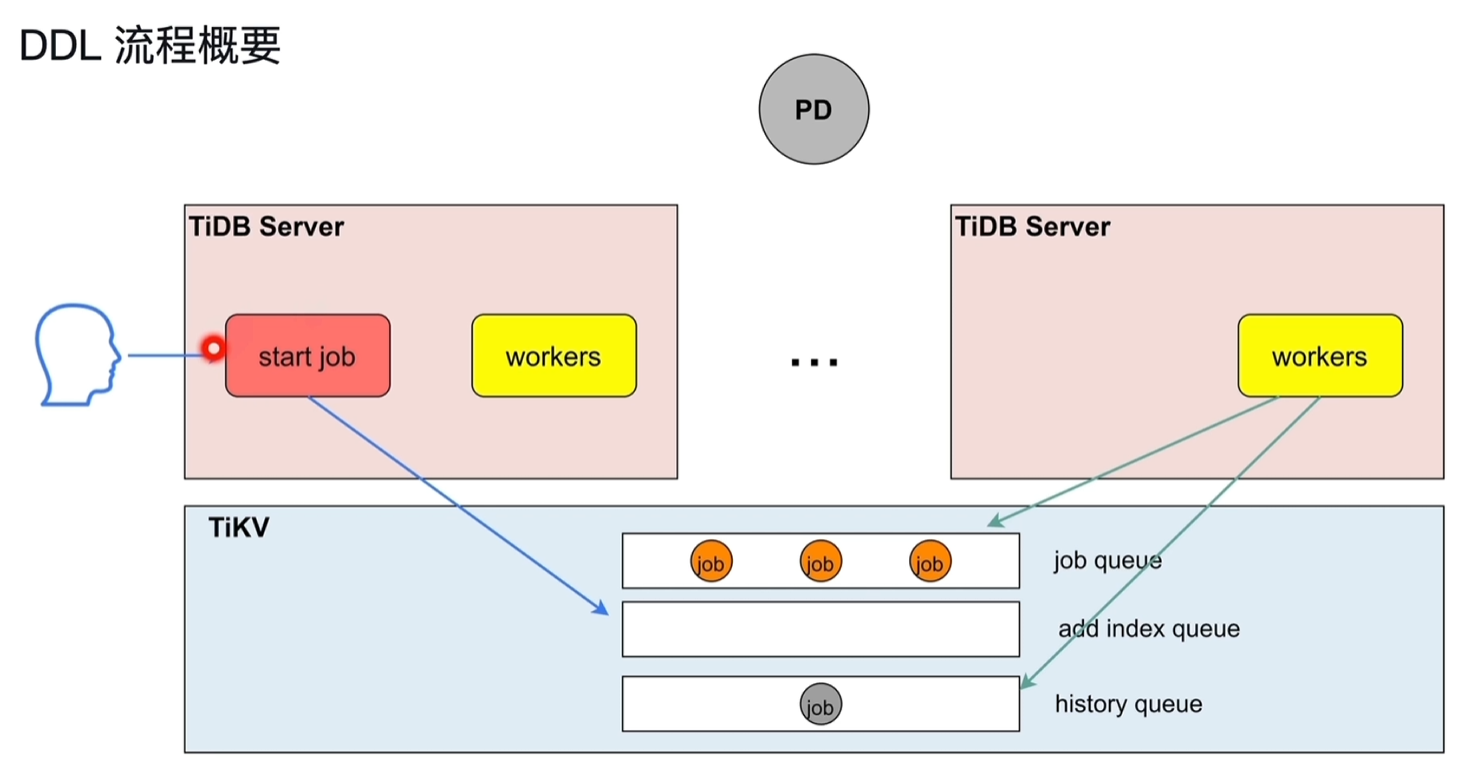
- DDL流程概要
- job queue:除了加索引的DDL操作加入到此队列
- add index queue:加索引的DDL操作加入到此队列
- history queue:执行完的DDL操作加入到此队列
- 每个TiDB Server节点都可以接收DDL请求操作
- 只有owner角色的TiDB Server节点中的workers可以实际执行queue队列中的DDL命令
- owner每隔一个周期会重新发起选举选出新的owner,轮流做owner
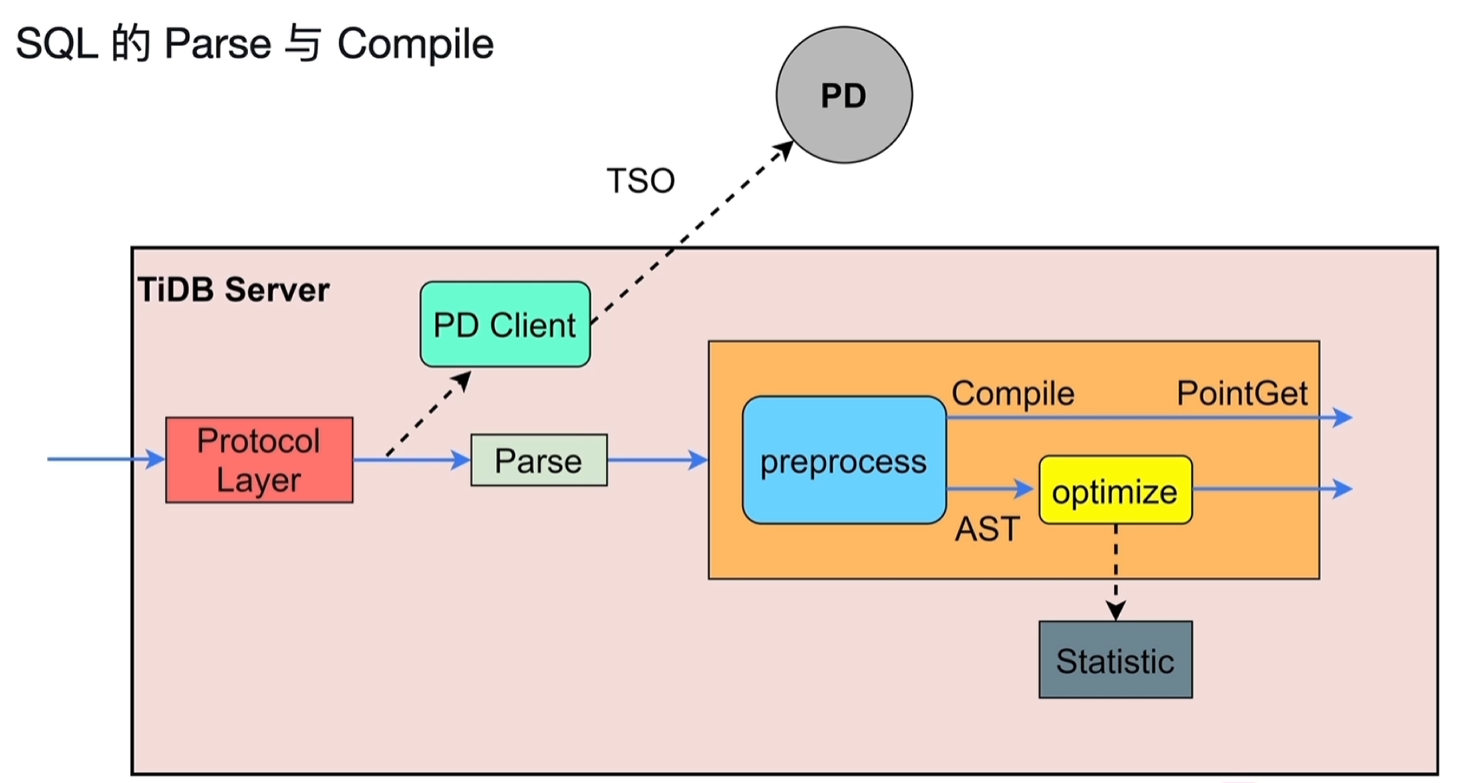
5.2 SQL的Parse与Compile
- Protocol Layer:该协议层监听到客户发送的SQL请求,先从PD中获取TSO
- Parse:经过词法分析和语法分析,将SQL转换为AST语法树
- Compile
- preprocess:预处理阶段,检测sql合法性,判断是否为点查(主键、唯一索引一类的查询)
- PointGet:直接点查
- optimize:优化器进行逻辑优化,物理优化,产生出执行计划给到Executor
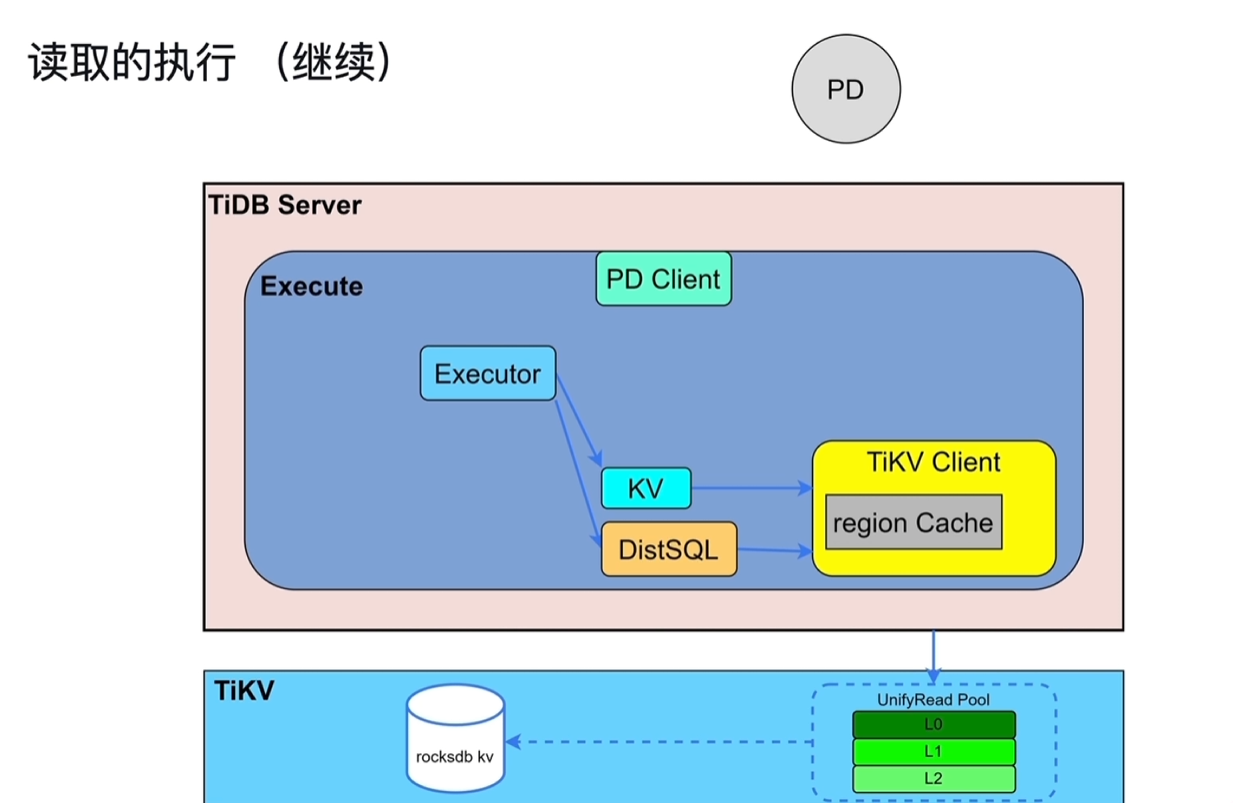
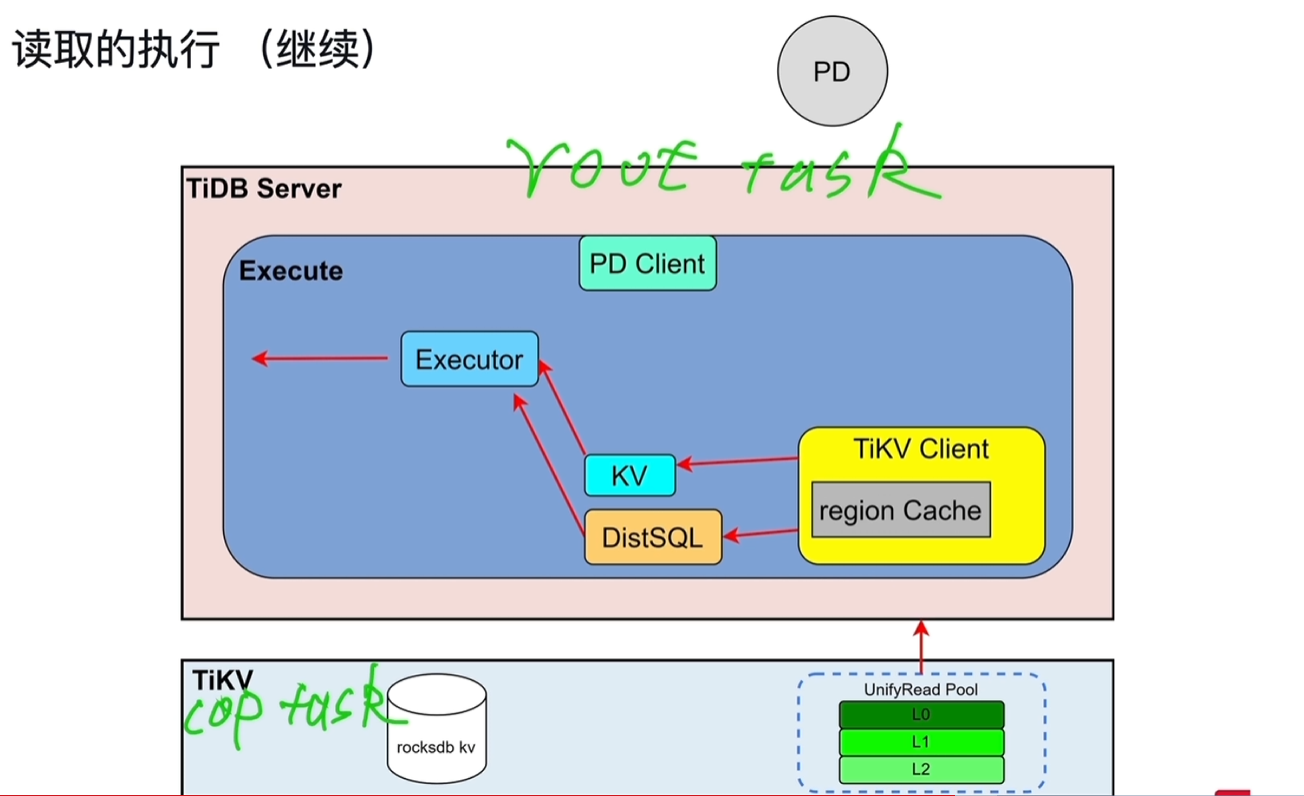
5.3 读取的执行
- Executor先获取表的元数据(表名、列名的一些对应关系),从information schema中的缓存中读取(来源于TiKV中);还要获取需要修改/处理的表对应Key所在的region和region所在的TiKV,从region Cache中读取,来源于PD(缓存中没有就直接从PD中读取)。
- region发生改变时对应的region Cache会过期,这个过程叫做back off,发生后需要重新从PD中读取。

-
KV:执行点查
-
DistSQL:将复杂的SQL转换成对单表的简单查询,再下发给TiKV。
-
snap shot:TiKV收到执行请求后,会先创建一个快照对象,相当于一个时间点,查询看到的数据是这个时间点之前的。
-
查询请求会进入到UnifyRead Pool线程池。
-
cop task:算子下推到TiKV进行计算的任务,如将一些聚合结果进行计算返给TiDB Server
-
root task:无法在TiKV中计算的,如数据分散在不同的tikv节点,需要各自将结果集返回给TiDB的内存中后,在TiDB Server中做表连接。
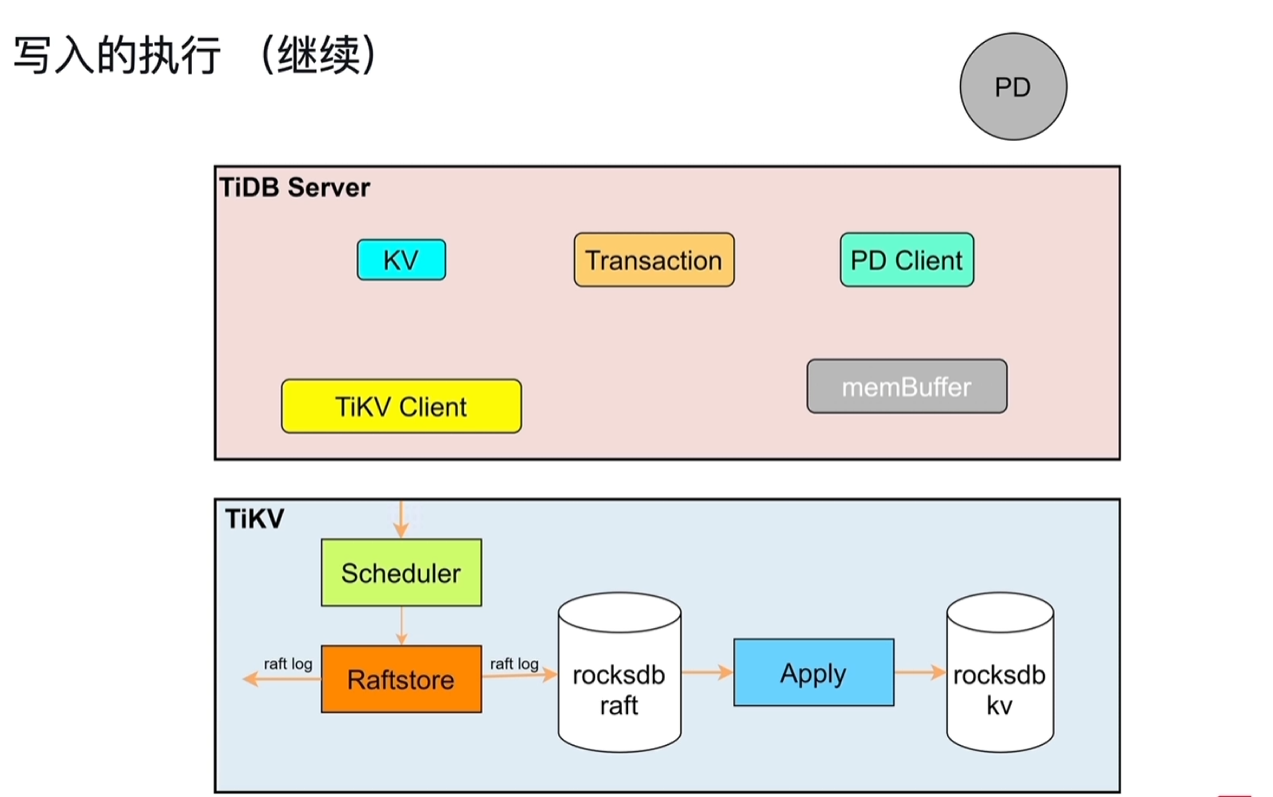
5.4 写入的执行
- Transaction:两阶段提交,prewrite和commit,详情见3.2.1
- KV:操作key值,通过TiKV Client发到TiKV中

- Scheduler:协调事务并发写入的冲突,并将收到的修改操作向下写入。收到冲突的并发请求时(修改同一个Key),用latch来管理冲突,拿到latch的可以向下写入,没拿到的需要等待。
- Raftstore:将写请求转换为raft log,持久化到本地,并向其他副本发送数据。
- Apply:将raft log应用到raocksdb kv中
5.5 DDL的执行
- start job:接收DDL语句
- workers:执行DDL语句,仅owner可以执行。
- schema load:为owner节点提供最新的表的元数据结构信息。
- start job接收到DDL语句时,如果当前节点为owner,直接就给到workers执行;反之给到job queue/add index queue的队列中持久化。
- owner节点的workers会定期的查看TiKV中的job队列,有job就去执行。
- owner由PD节点控制,进行轮询。

六、HTAP
6.1 HTAP概述
6.1.1 基本介绍
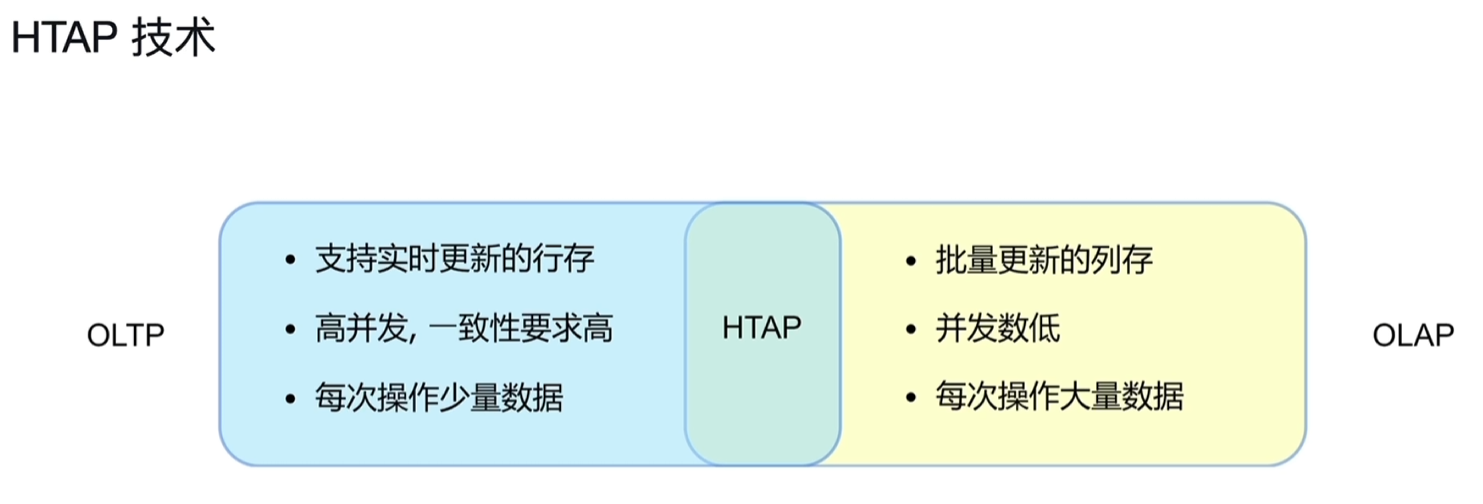
-
通过ETL转换成OLAP,往往存在延迟,如T+1后才能查看结果。
- 事实上目前做的项目来说,很多场景都是按此方式去处理的,业务数据量巨大,产生的报表动态查询结果就会很慢,常用的做法就是进行转换成对应的报表结果,数据非及时。
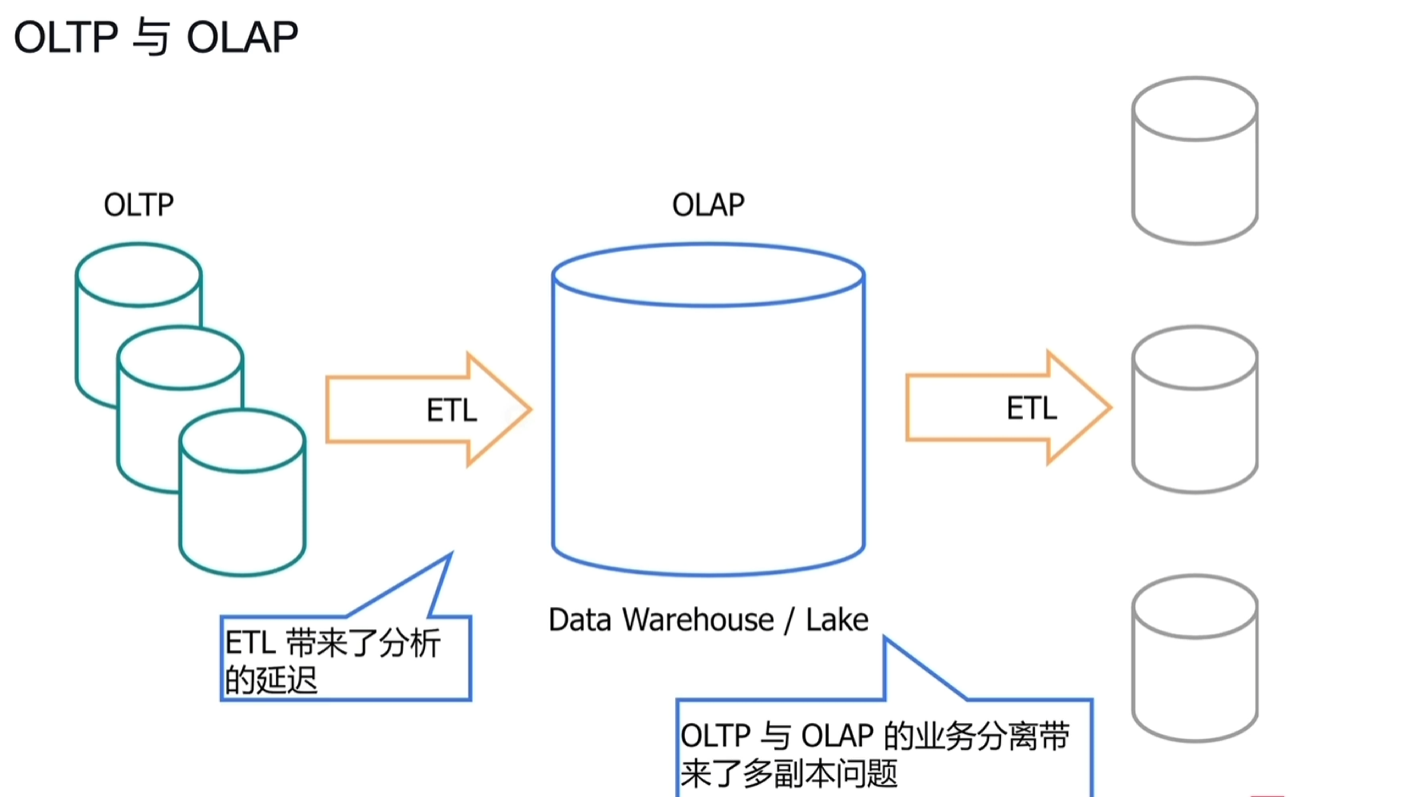

- 事实上目前做的项目来说,很多场景都是按此方式去处理的,业务数据量巨大,产生的报表动态查询结果就会很慢,常用的做法就是进行转换成对应的报表结果,数据非及时。
-
HTAP架构
- TiFlash以第三种角色Learner加入到存储集群中,不参与投票,只是进行异步复制。

- TiDB的HTAP特性
- 行列混合
- 列存(TiFlash)支持基于主键的实时更新
- TiFlash作为列存副本
- OLTP与OLAP业务隔离
- 智能选择(CBO自动或者人工选择)
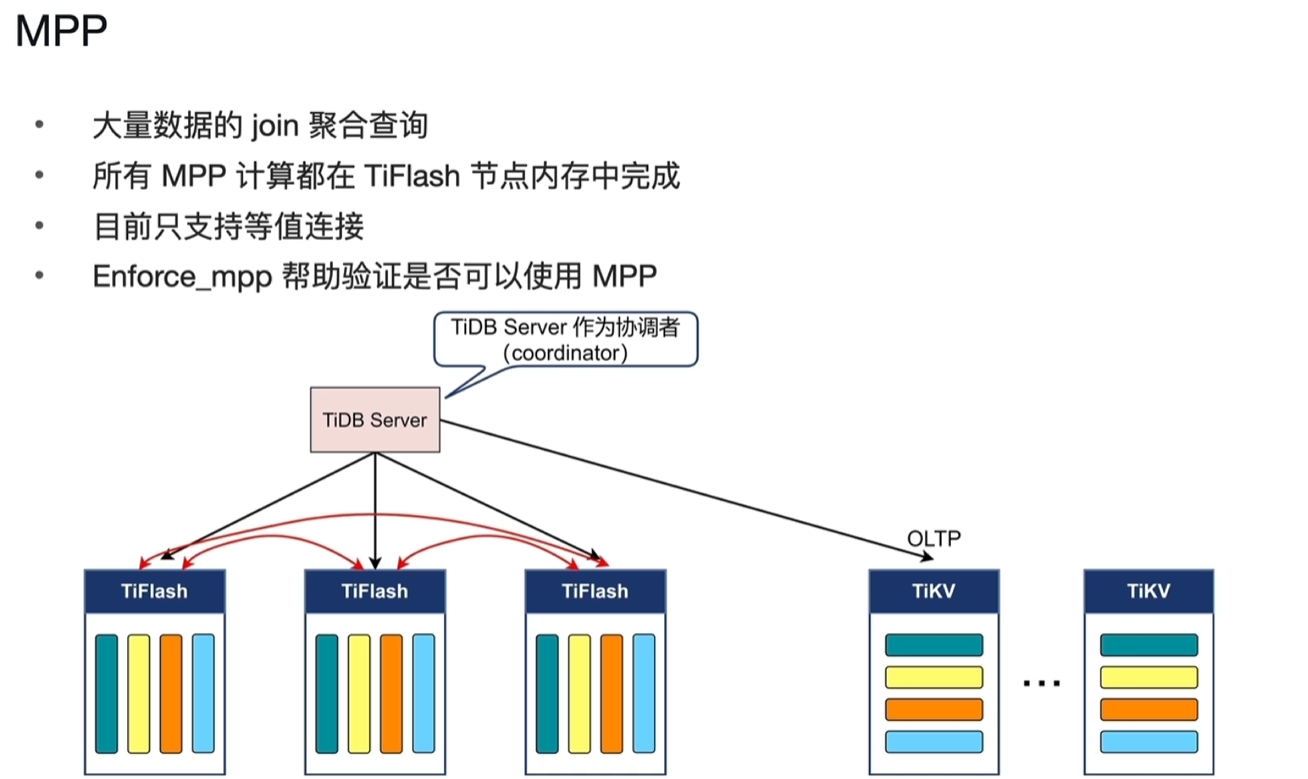
- MPP架构
- 行列混合
6.1.2 MPP架构
- TiDB Server作为协调者,会把每一个TiFlash列存的Region会在TiFlash各个节点中去做交换,让表连接只发生在一个TiFlash中。
- 每一个TiFlash都负责过滤、数据交换、表连接、聚合等等计算的节点,每个TiFlash都是一个MPP Worker,驱动着各个节点并行的做计算。
- 如果某个TiFlash节点宕机,会导致MPP计算终结。
- join只支持等值连接
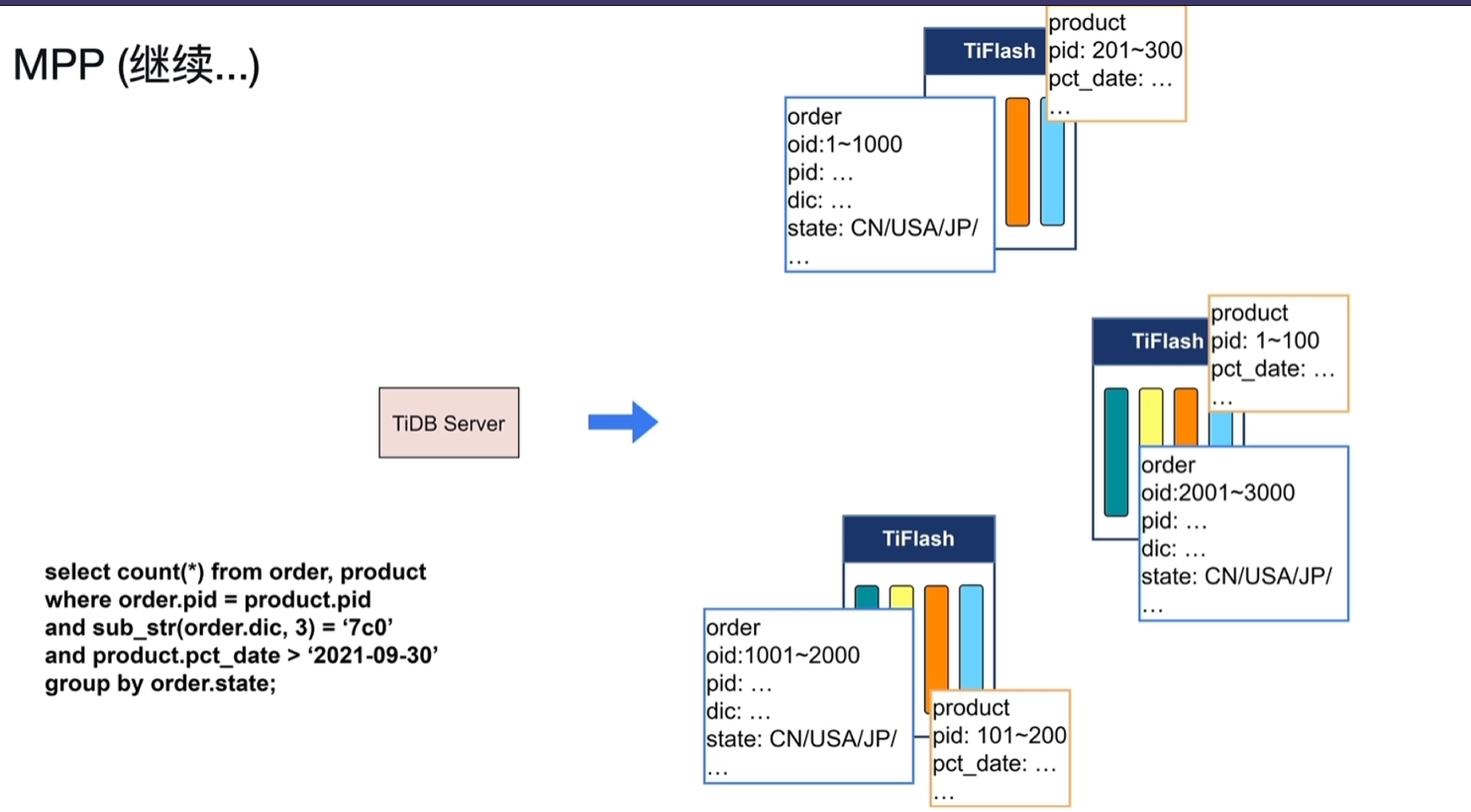
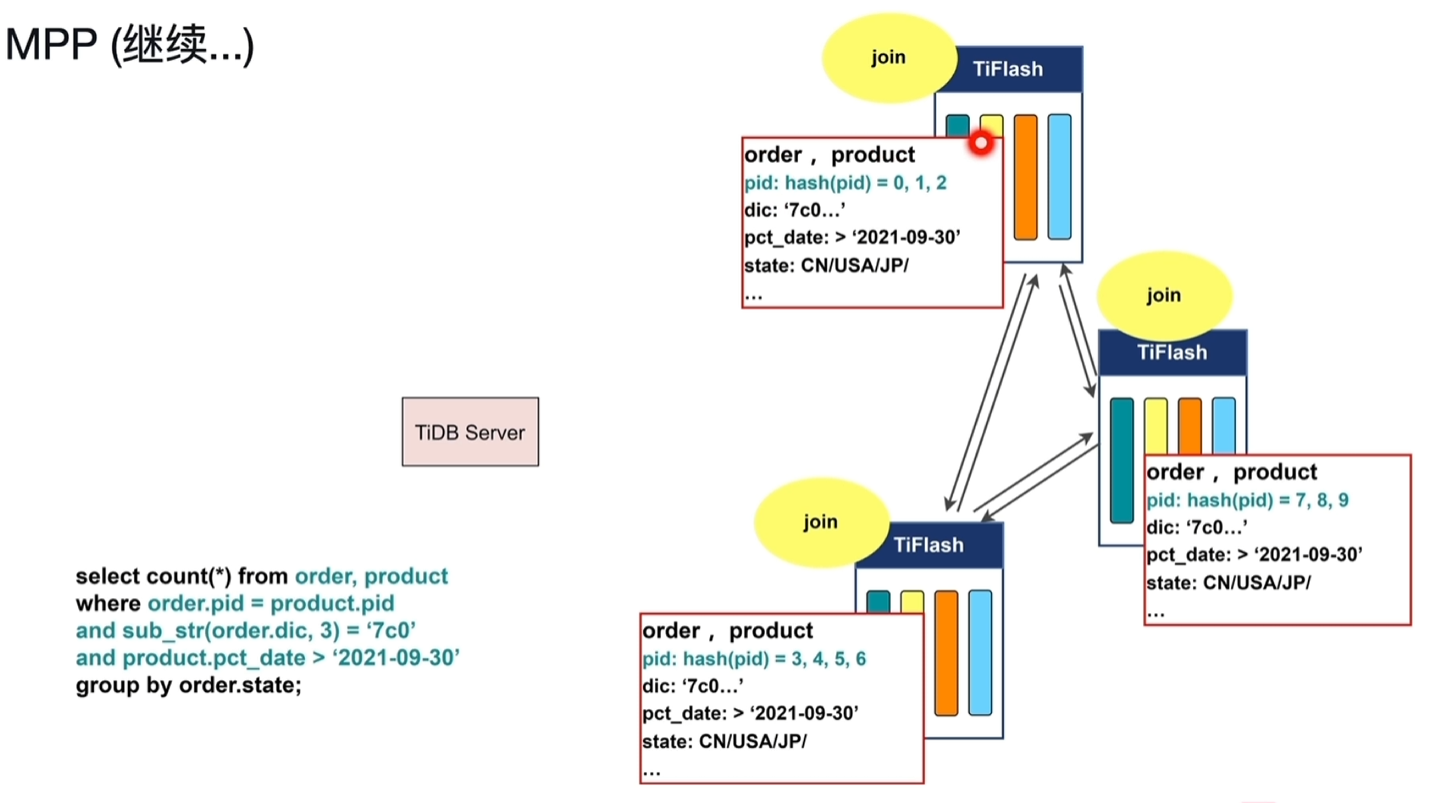
 实例讲解
实例讲解 - 执行了order和product的计数联查
- order、product的表数据分布如下图1所示
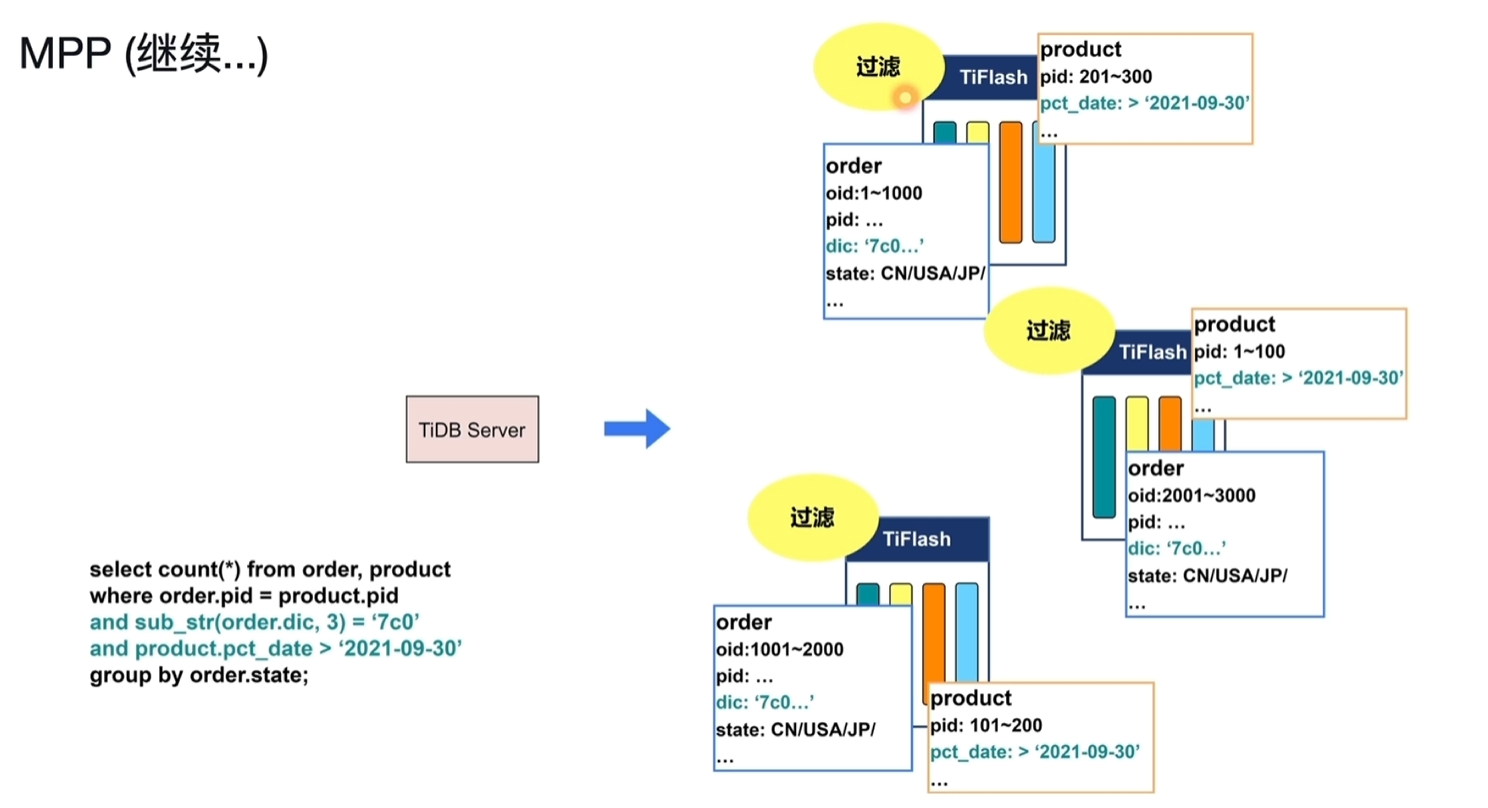
- 过滤:将每个节点的order、product数据按查询条件的范围进行过滤,查询出结果放到内存中。
- 数据交换:通过hash函数将order、product值相等的数据交换到同一个节点中
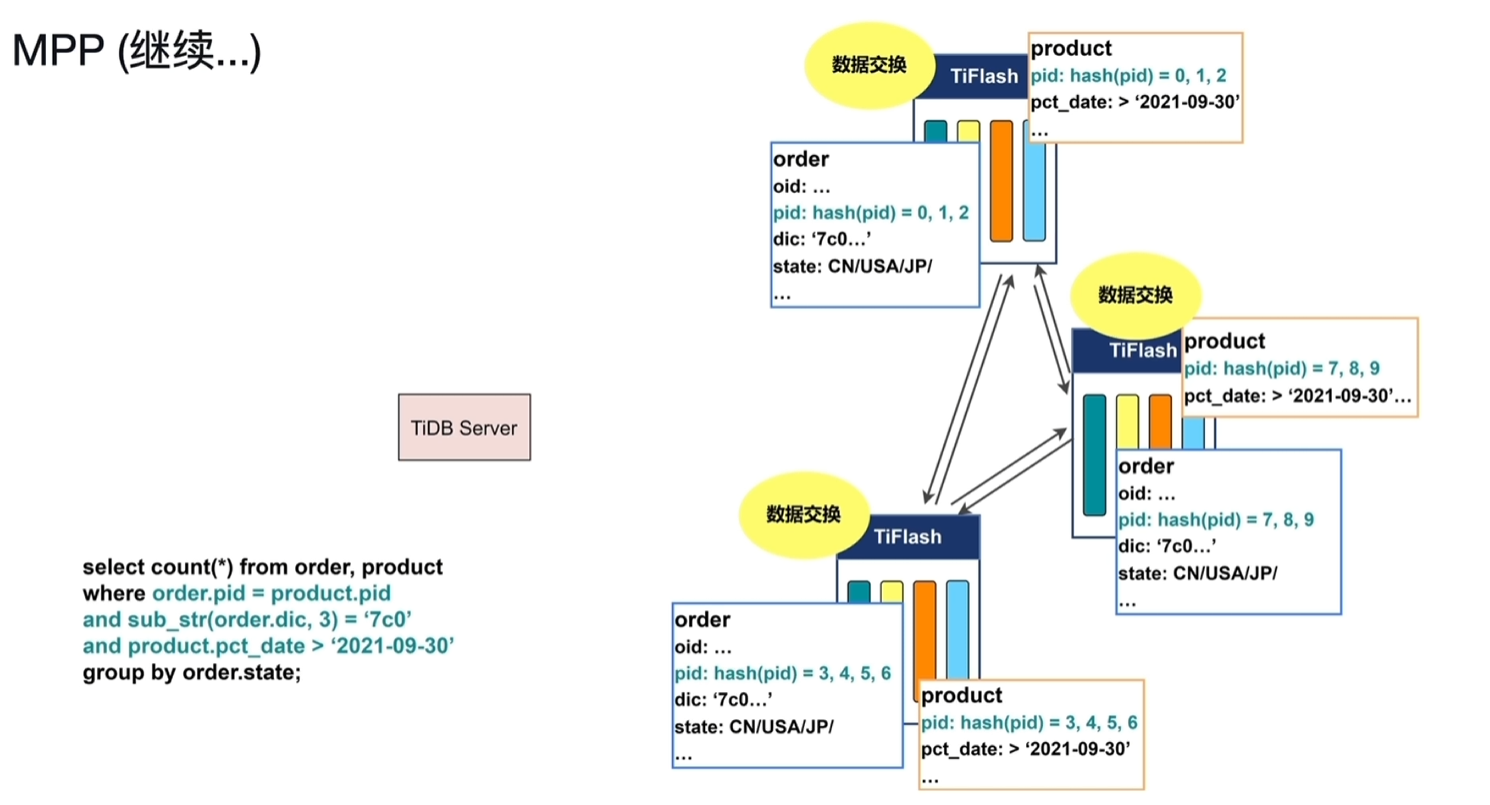
- Join:各个节点并行join查询
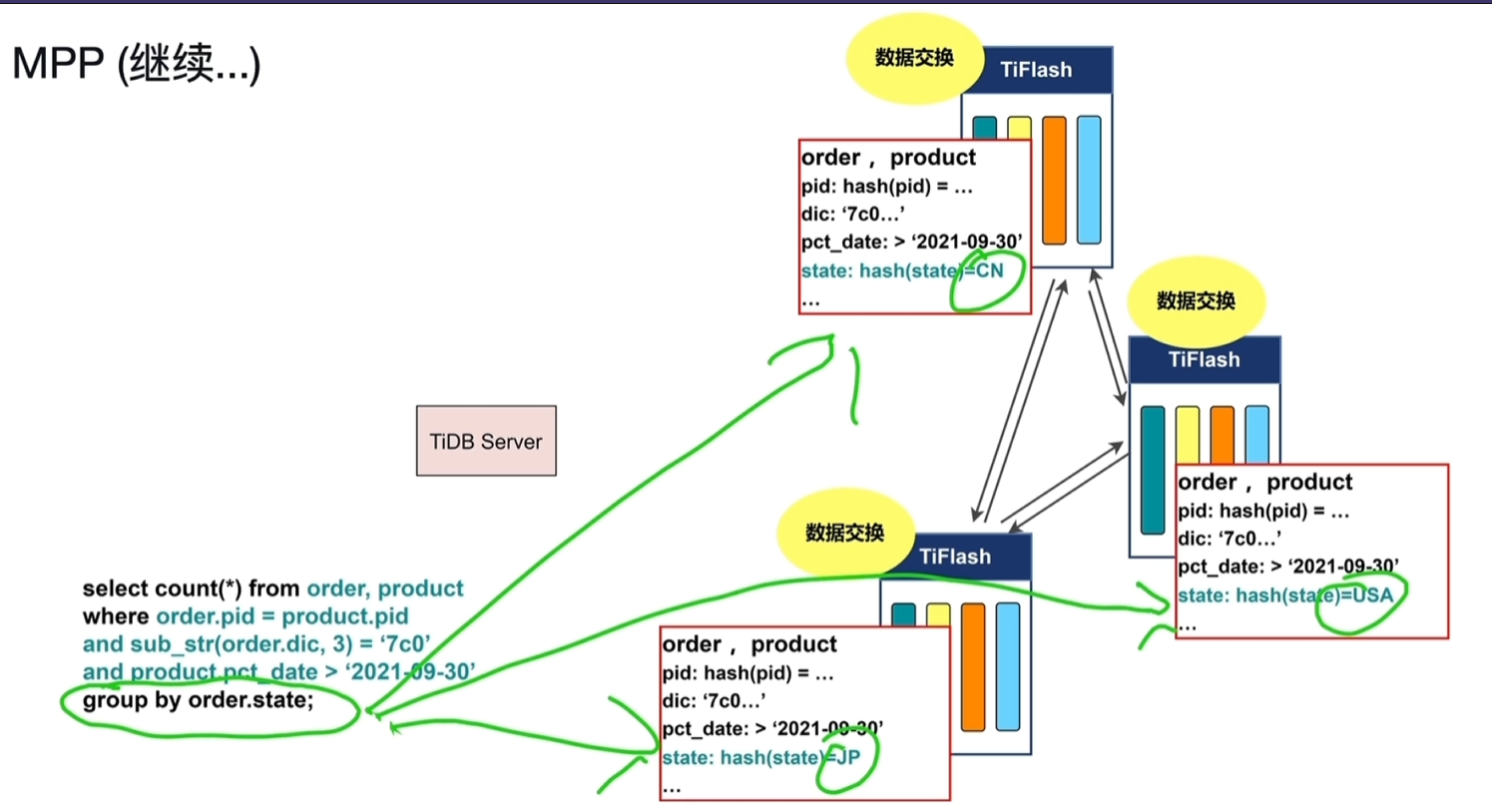
- 数据交换:再基于state取hash函数运算,进行数据交换将相等的数据放置到同一个节点
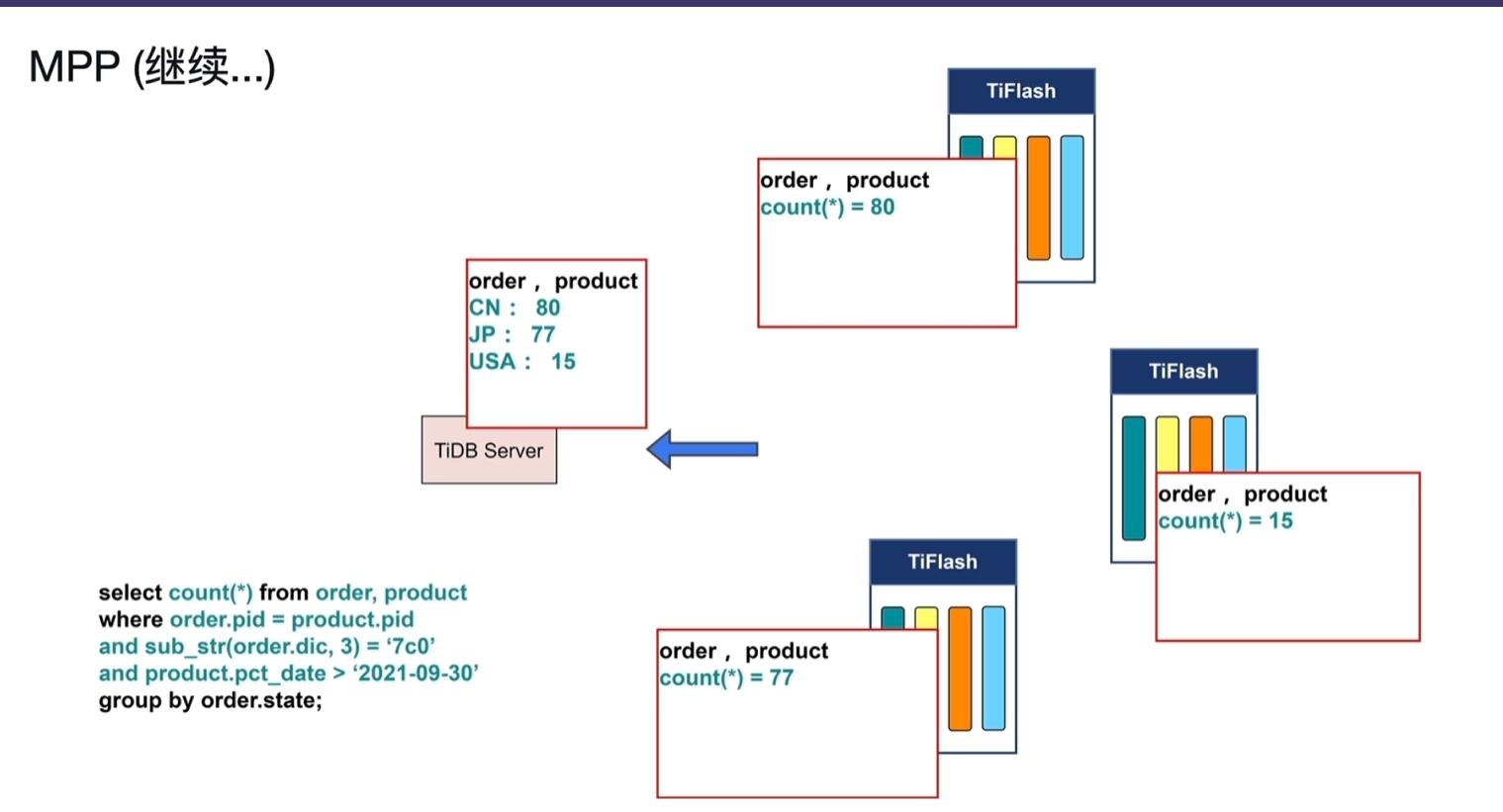
- 聚合:各个节点聚合,得出结果
6.1.3 运用场景

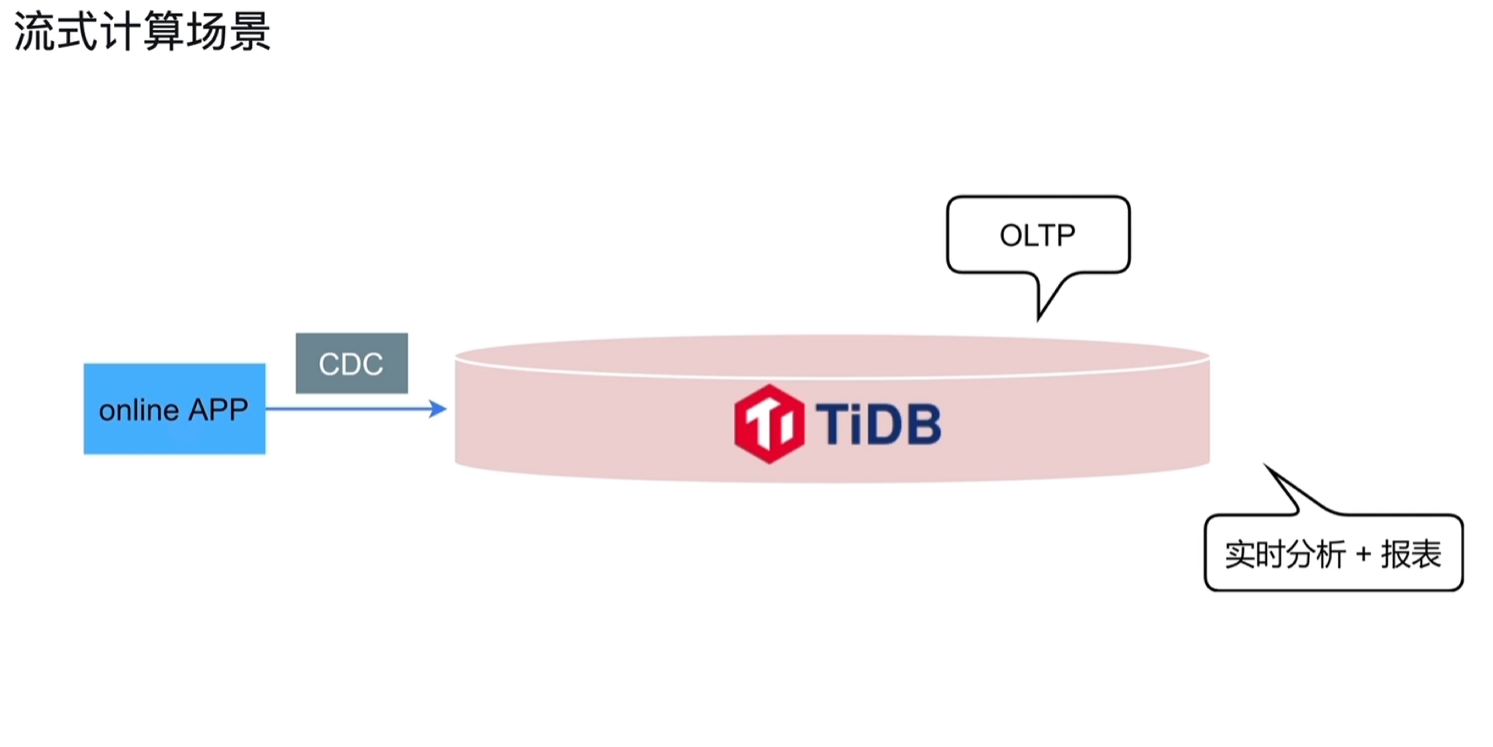
- 传统的流式计算场景:涉及的组件、库众多
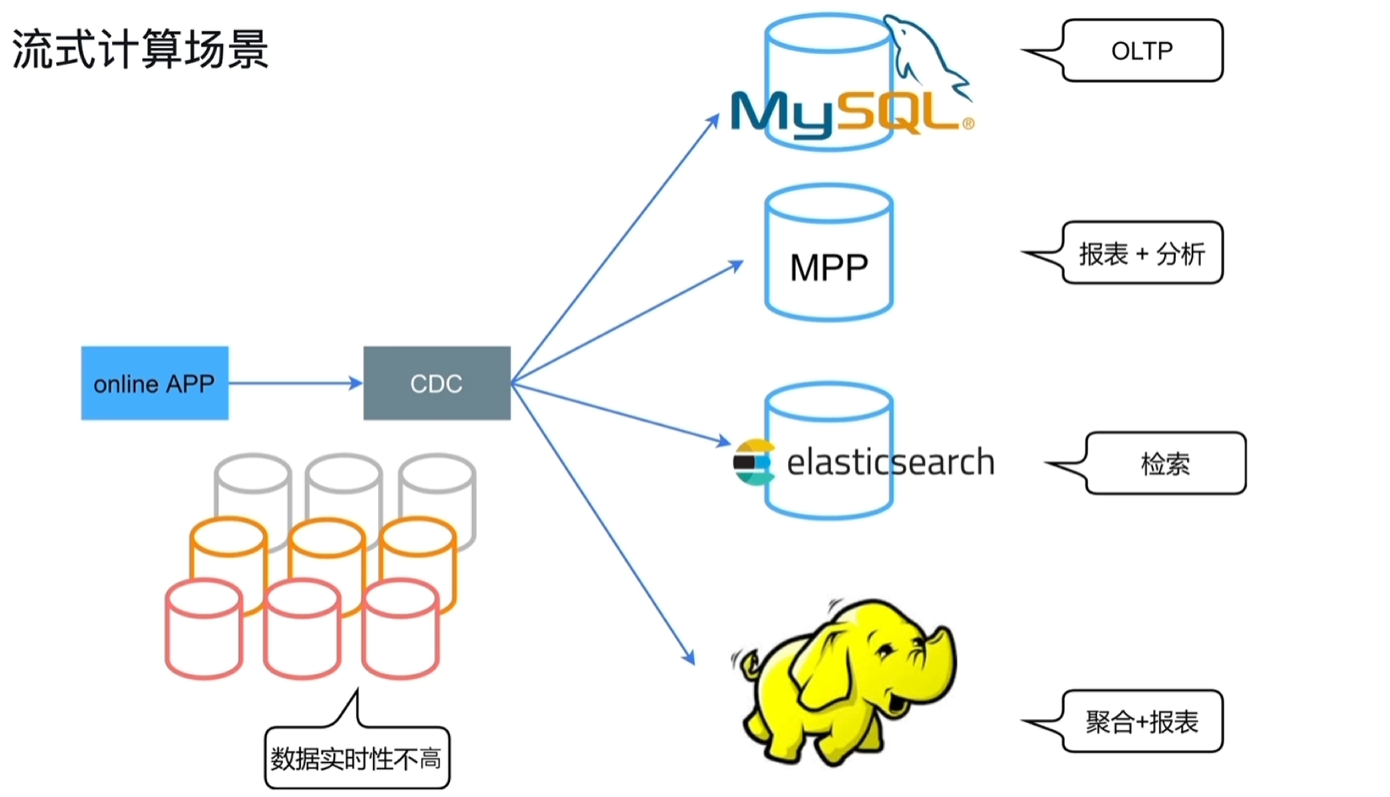
- TiDb的流式计算场景
6.2 TiFlash
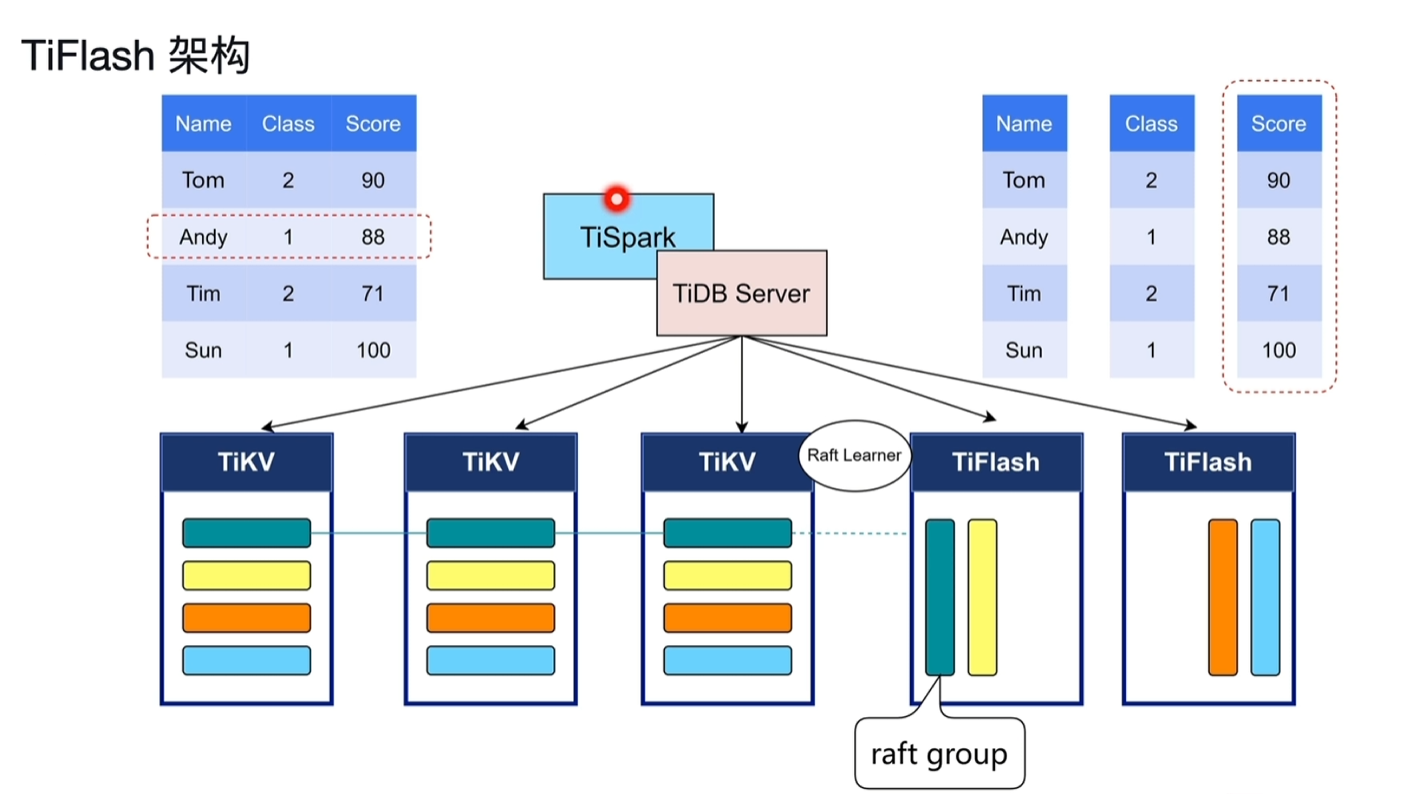
6.2.1 TiFlash架构
- TiFlash只接收TiKV复制的日志,不参与投票,对原本TiKV的性能影响很小。
- 如果宕机重新从TiKV中同步数据副本过滤即可,对线上业务影响很小,具备业务隔离性。
- TiFlash无法直接写数据,都是通过TiKV异步复制数据过来写入的。
- TiFlash读取是一致的,如TiKV中10:00写入的数据,10:00之后从TIFlash能读取到这个写入的数据。
- TIFlash的QPS一般不会很高,小于50。
6.2.2 主要功能
- 异步复制
- 一致性读取
- 引擎智能选择
- 计算加速
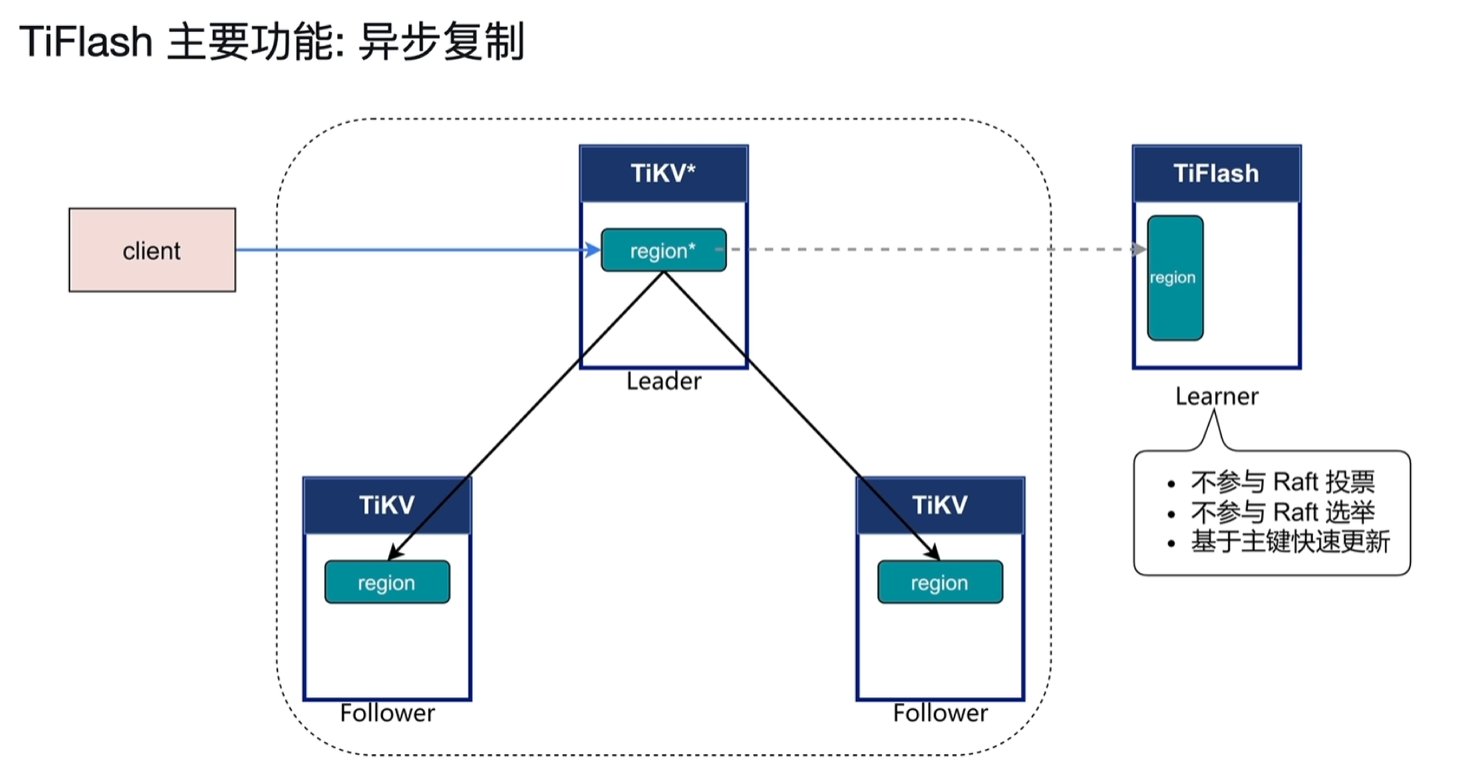
6.2.2.1 异步复制
- 接收从Leader节点来的异步复制的日志数据
- TiFlash是否写入成功不需要参与TiKV Raft复制的commit反馈
6.2.2.2 一致性读取
- T0时刻从客户端写入2行数据,key1=100和key999=7,正好在不同的region中,对应的raft log的idx分别为101、22。
- 此时TiFlash第一个region的idx写入到95,第二个的idx写入到18。因为异步复制,当前没数据也正常。
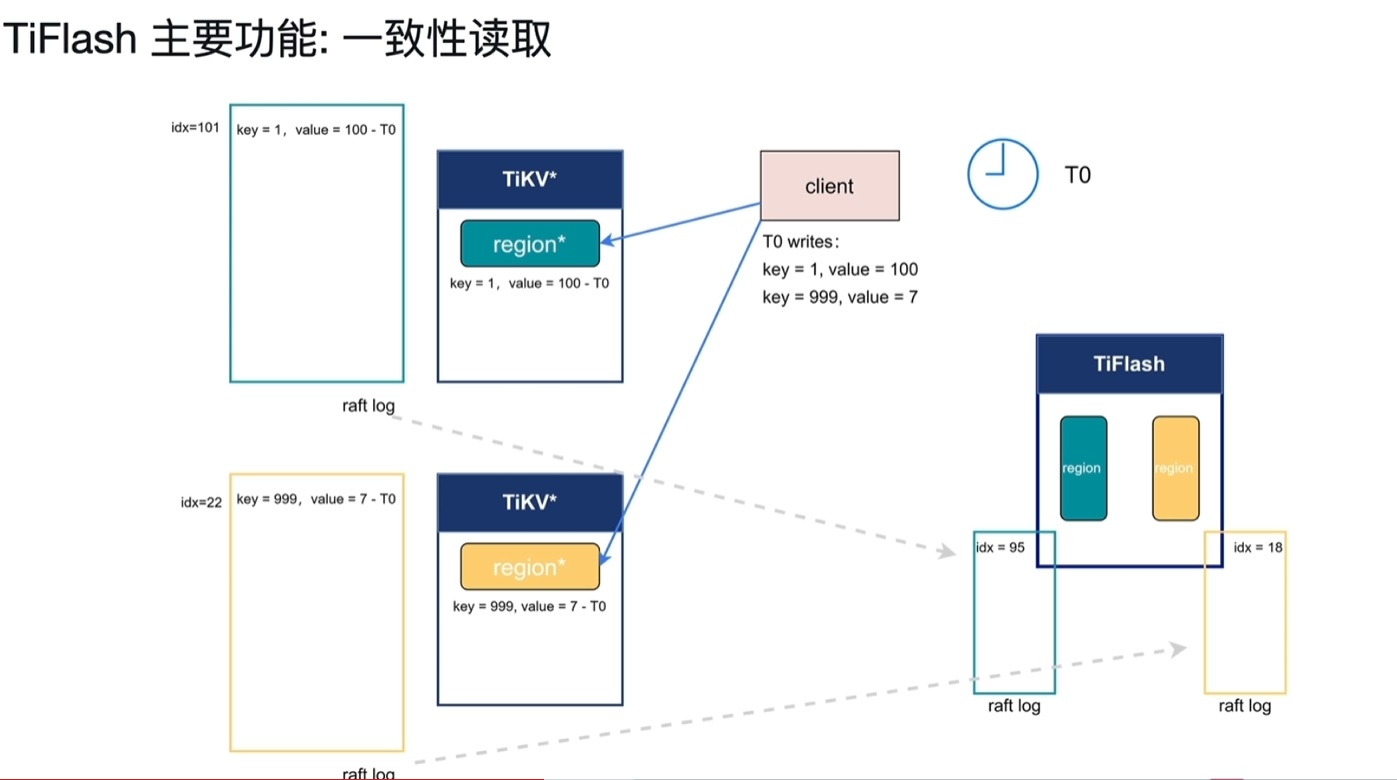
- T1时刻客户端向TiFlash读取key1和key999的值。
- 此时TiFlash的idx分别到了108和20;tikv的idx当前分别为120和29。
- 这时key1的值已经在tiflash中了,key2的值还没有,而且也没发保障当前2个region在tiflash中都存储了之前写入的数据,这时tiFlash需要去询问TiKV当前的idx
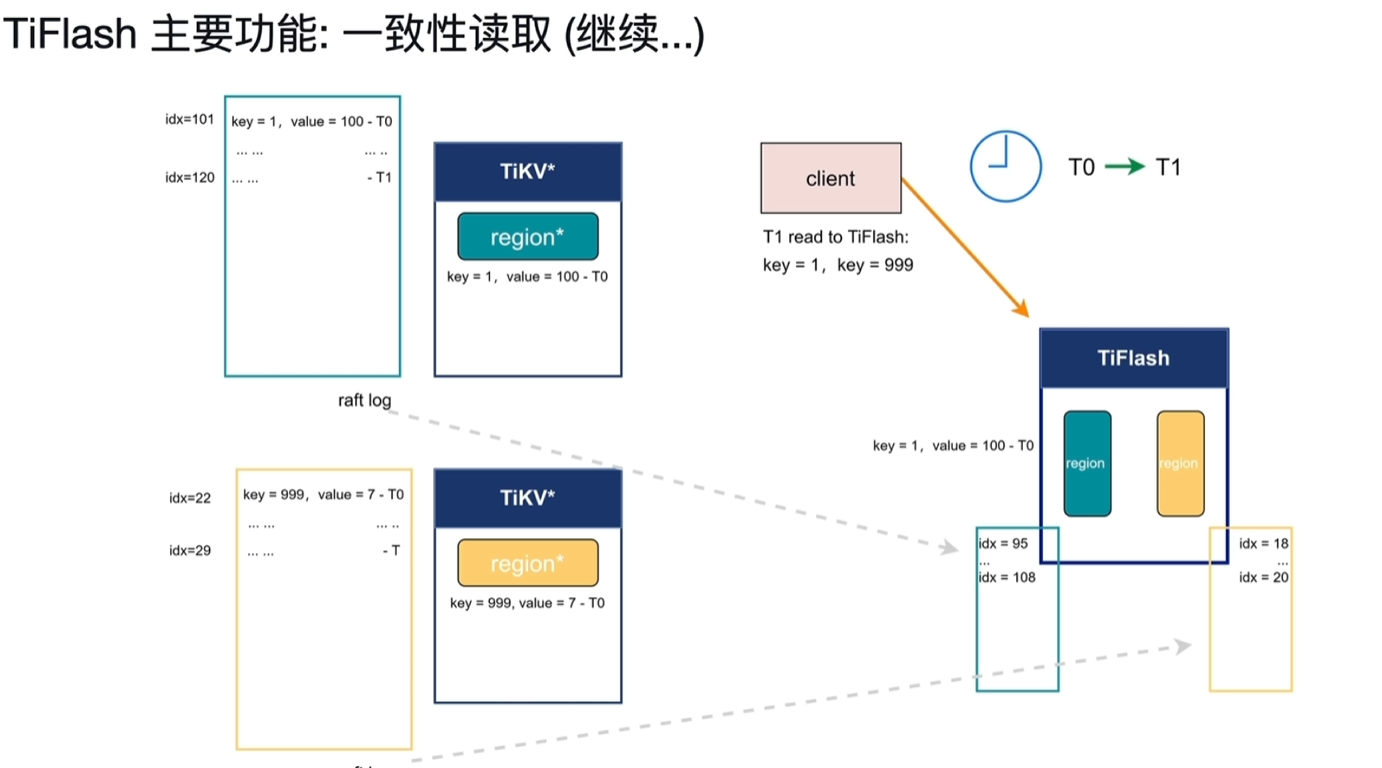
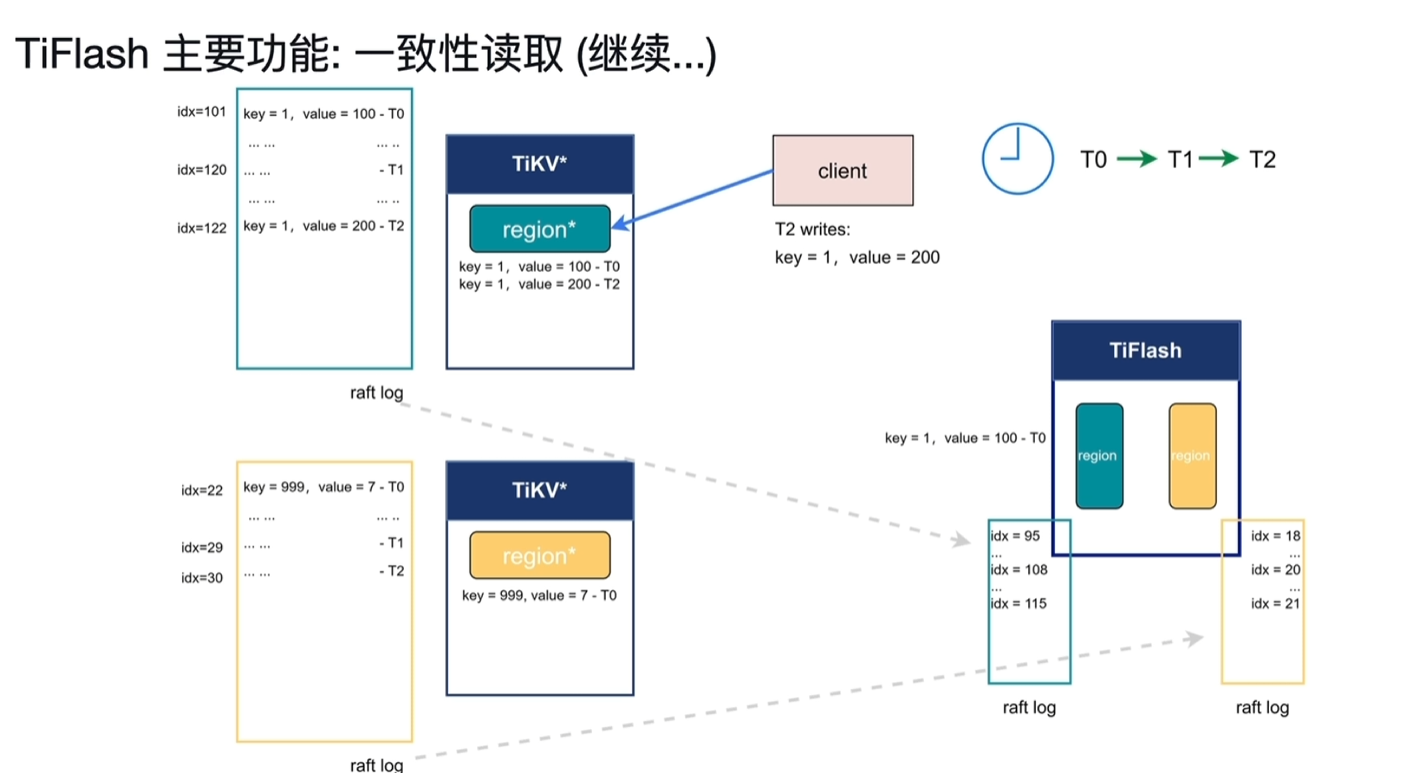
- 在Tiflash询问idx前的,T2时刻这时客户端又将key1的值写入为200,此时当前的TiKV的idx为122
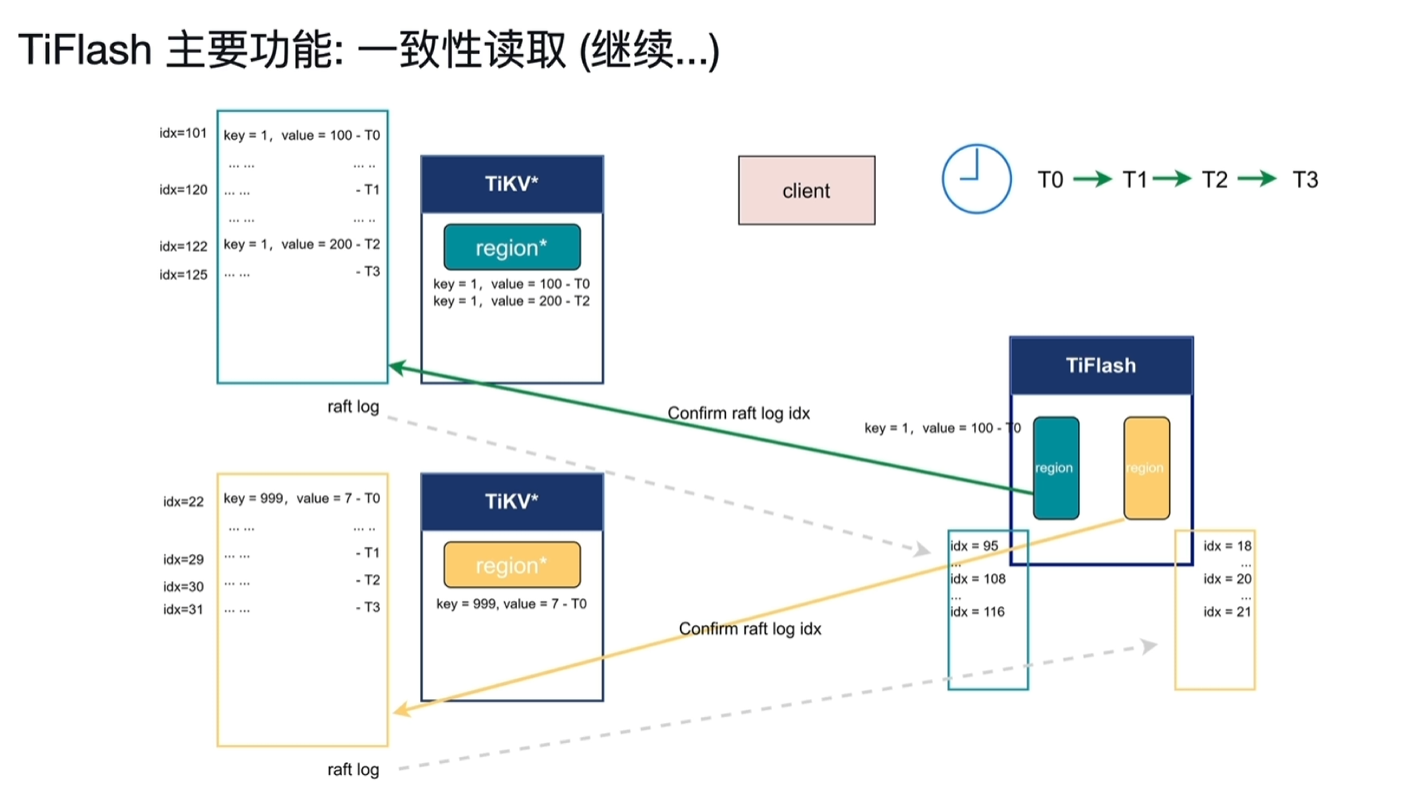
- T3时刻tiflash询问了tikv节点,从tikv中获取了当前tikv的idx,分别为125和31,记录为Wait idx。
- 该请求操作非常轻量。
- 此时TiKV就以这2个Wait idx来等,等到后就能保障之前的写入数据一定能进入到TiFlash中。
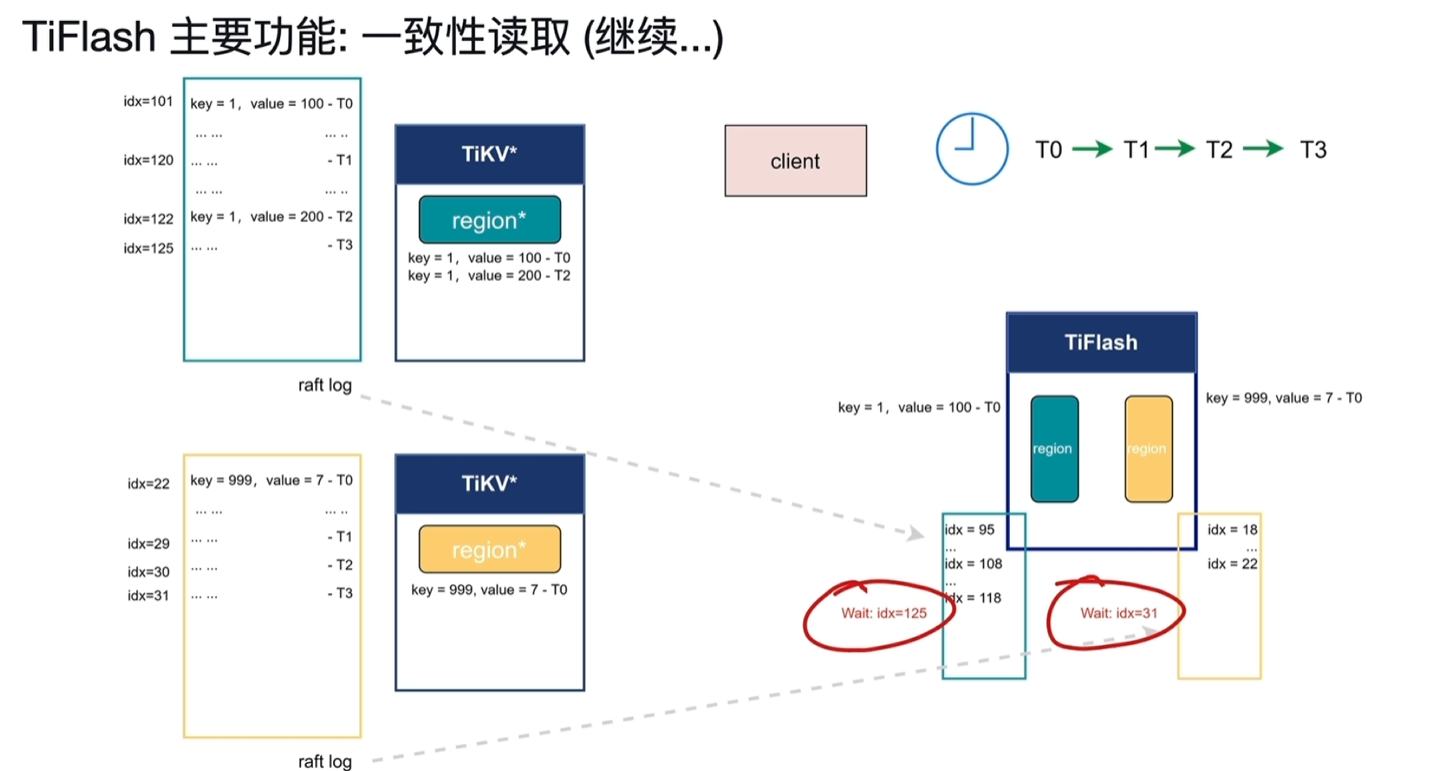
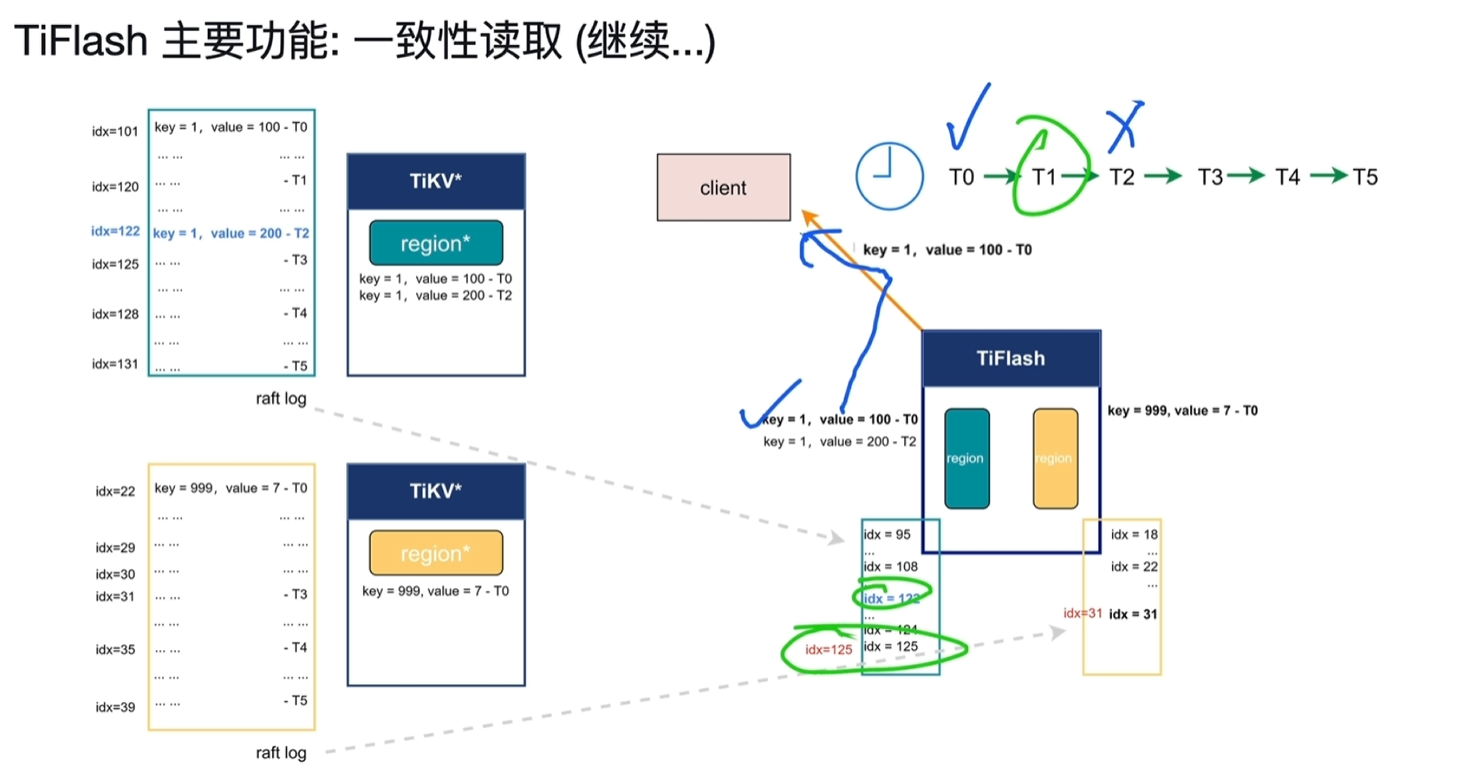
- T4时刻tiflash黄色region等到了31idx写入,此时key999能读取到7了
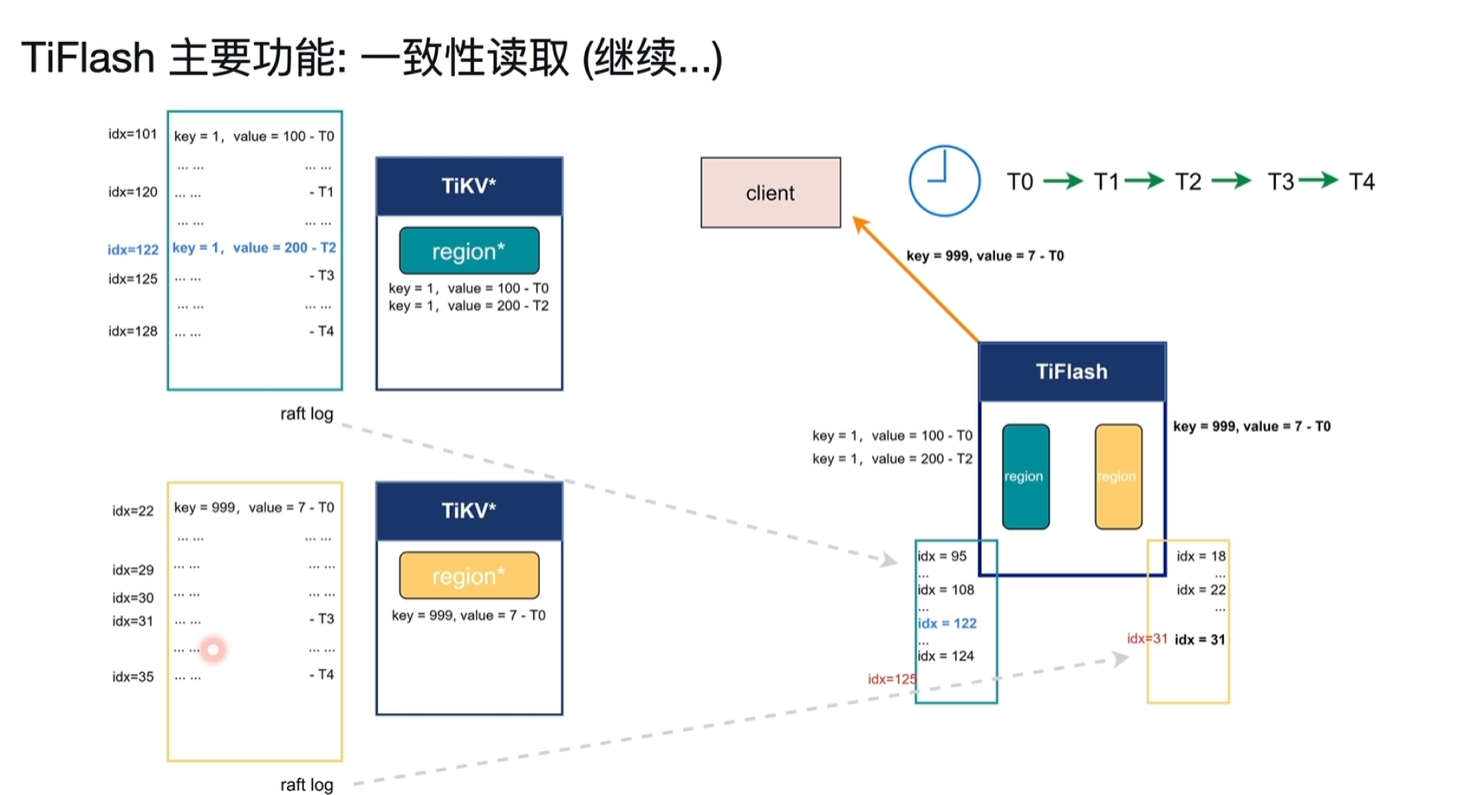
- T5时刻tilflash绿色region等到了125,去读取key1发现有2个版本,分别对应idx101和122
- 由于该读取请求时在T1请求的,按照快照隔离级别只能读取到T1之前写入的数据,此时读到的数据为100
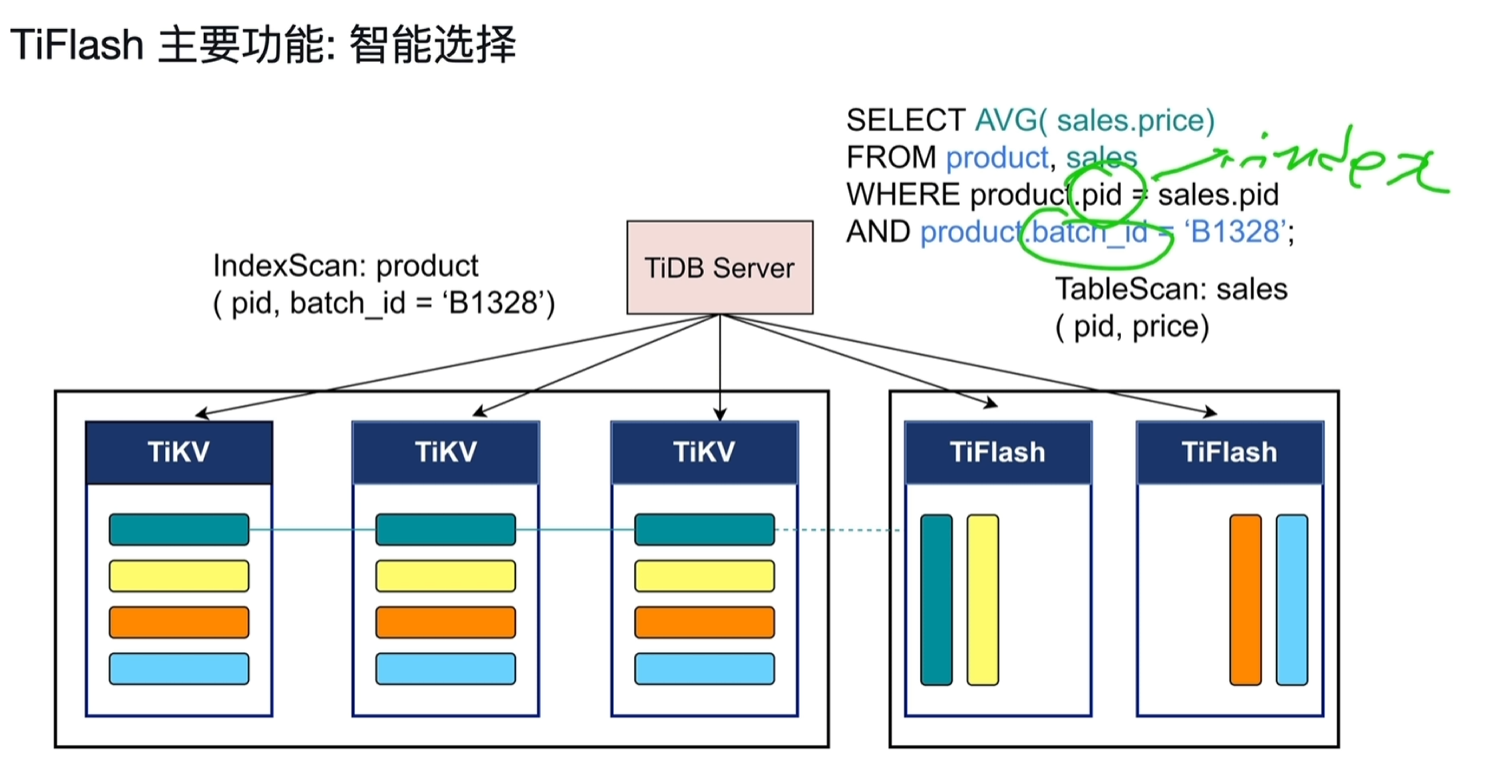
6.2.2.3 智能选择
- 可以同时使用TiKV和TiFlash,
- 下面product的pid和batch_id走TiKV的索引扫,
- sales没任何过滤条件,求的平均值,走TiFlash的表扫
七、TiDB 6.0 新特性
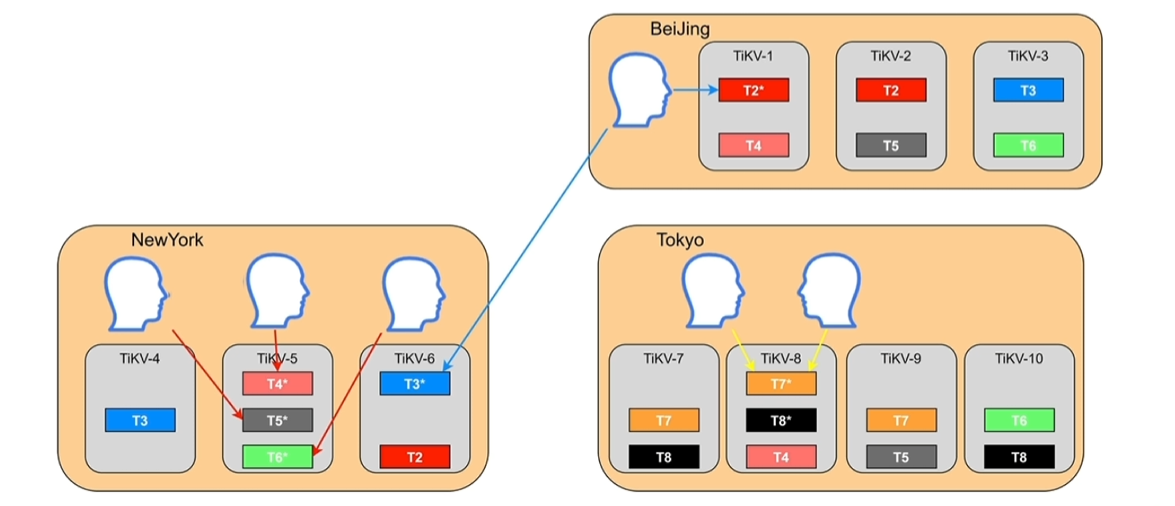
7.1 Placement Rules in SQL
- 之前的痛点
- 跨地域部署的集群,无法本地访问
- 无法根据业务隔离资源
- 难以按照业务等级配置资源和副本数
- 有了之后
- 管地域部署的集群,支持本地访问
- 根据业务隔离资源
- 按照业务等级配置资源和副本数
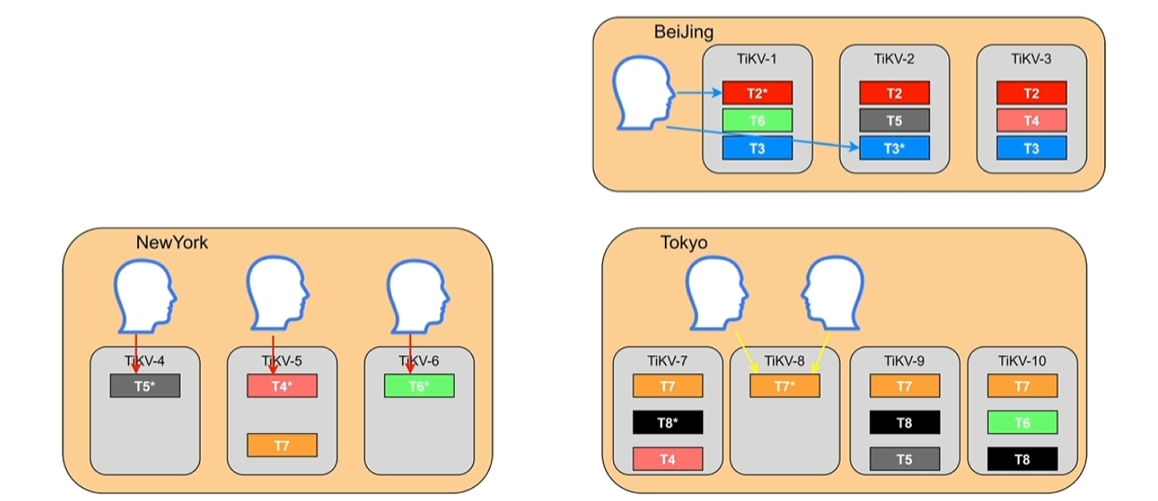
- 使用步骤
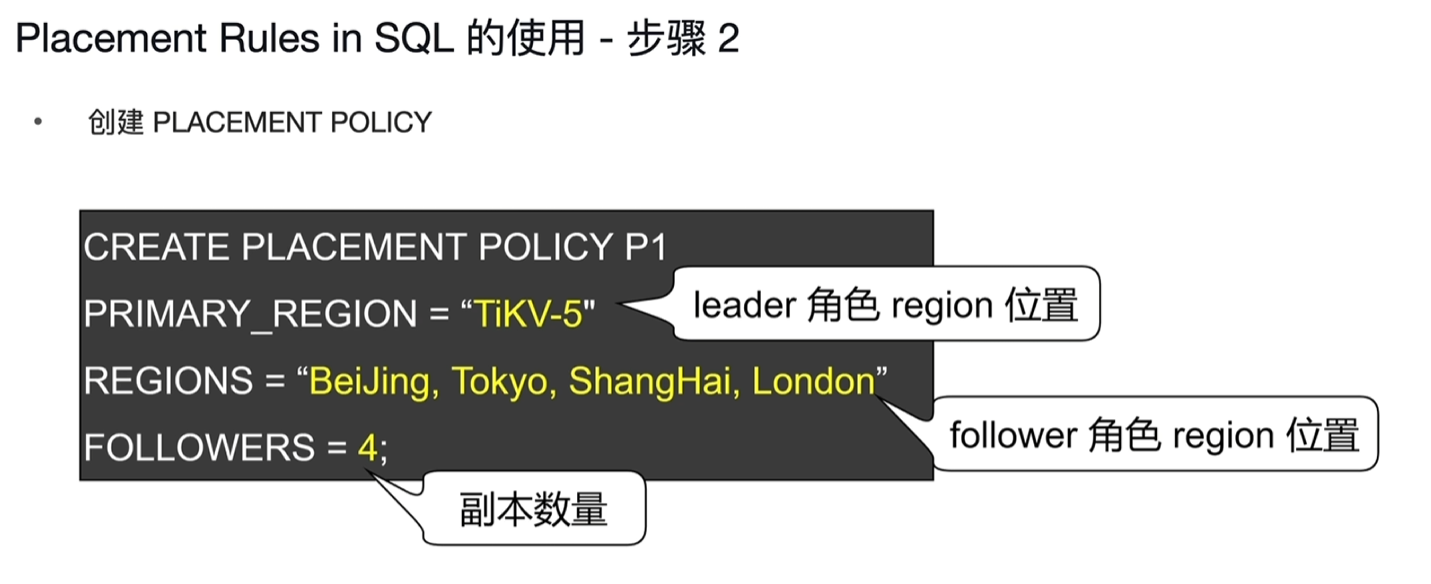

- 应用

7.2 小表缓存
- 减少高频小表的对tikv的IO读取
- sql操作:alter table users cache;


7.3 内存悲观锁
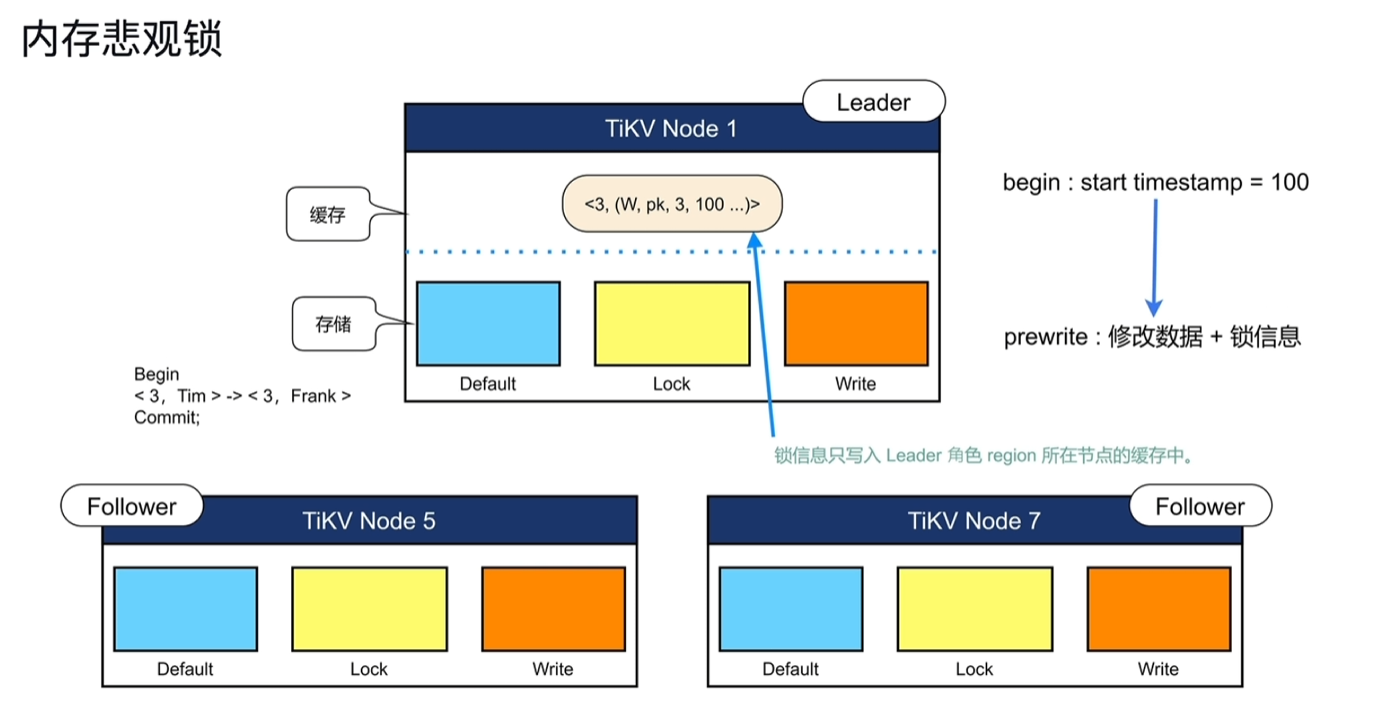
- 之前的内存锁是乐观锁
- 存储在TIKV中持久化的为悲观锁

- 内存悲观锁
- 性能提升
- leader节点在事务过程中宕机,会出现锁丢失的情况,tidb有机制保障其会回滚,也就是事务只是会失败。
- 如果能接受上一条事务发生小概率的失败场景,就可以开启内存悲观锁。



7.4 Top SQL
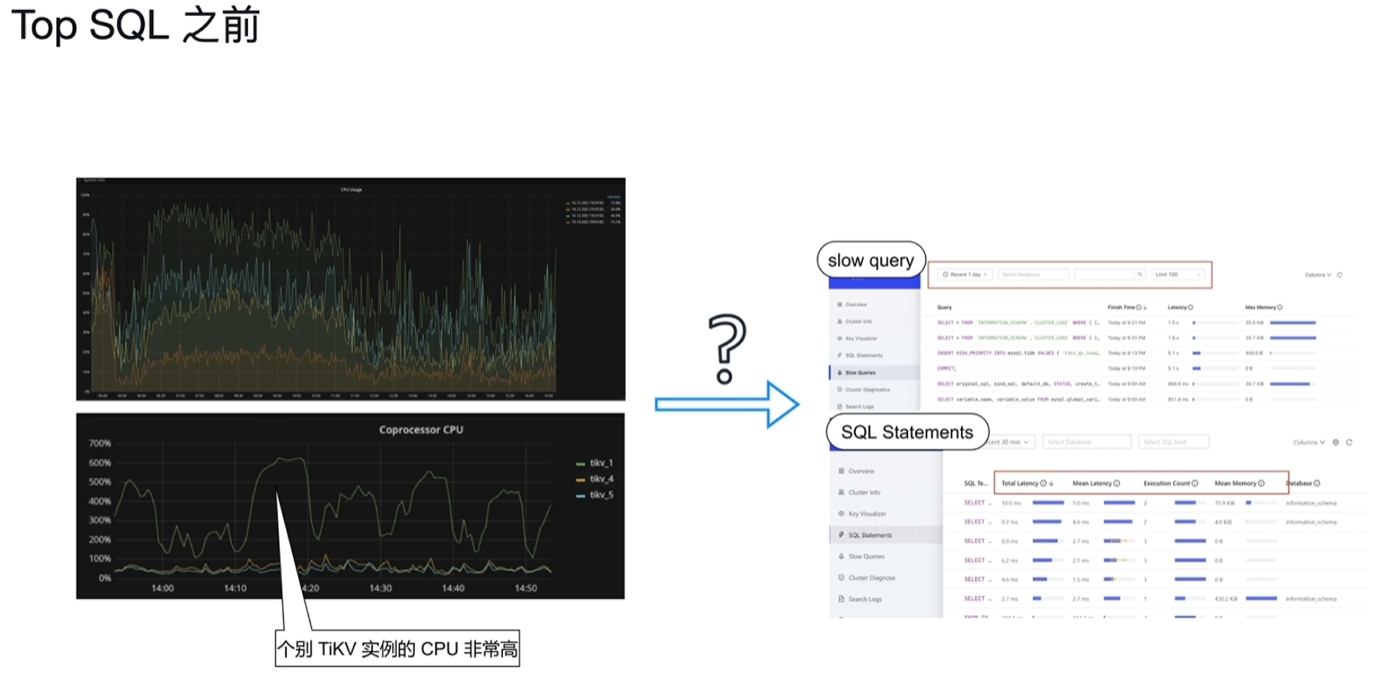
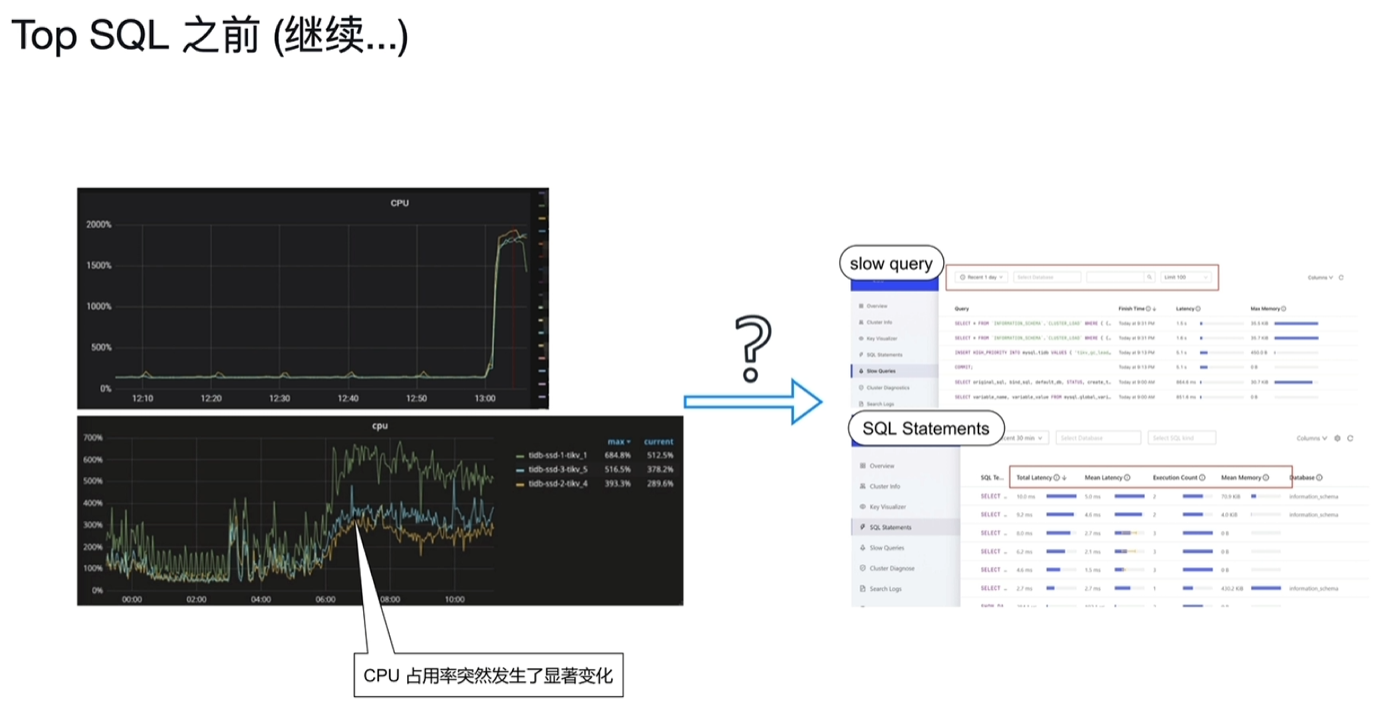
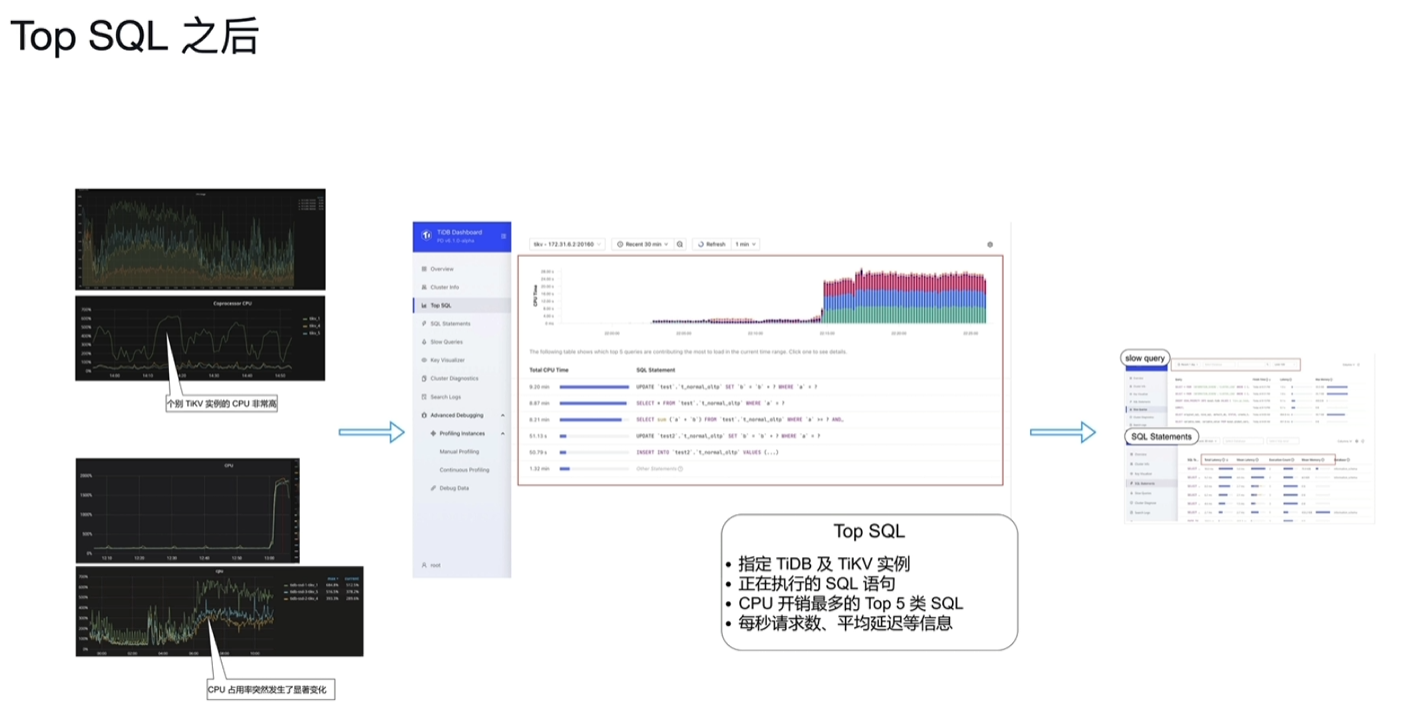

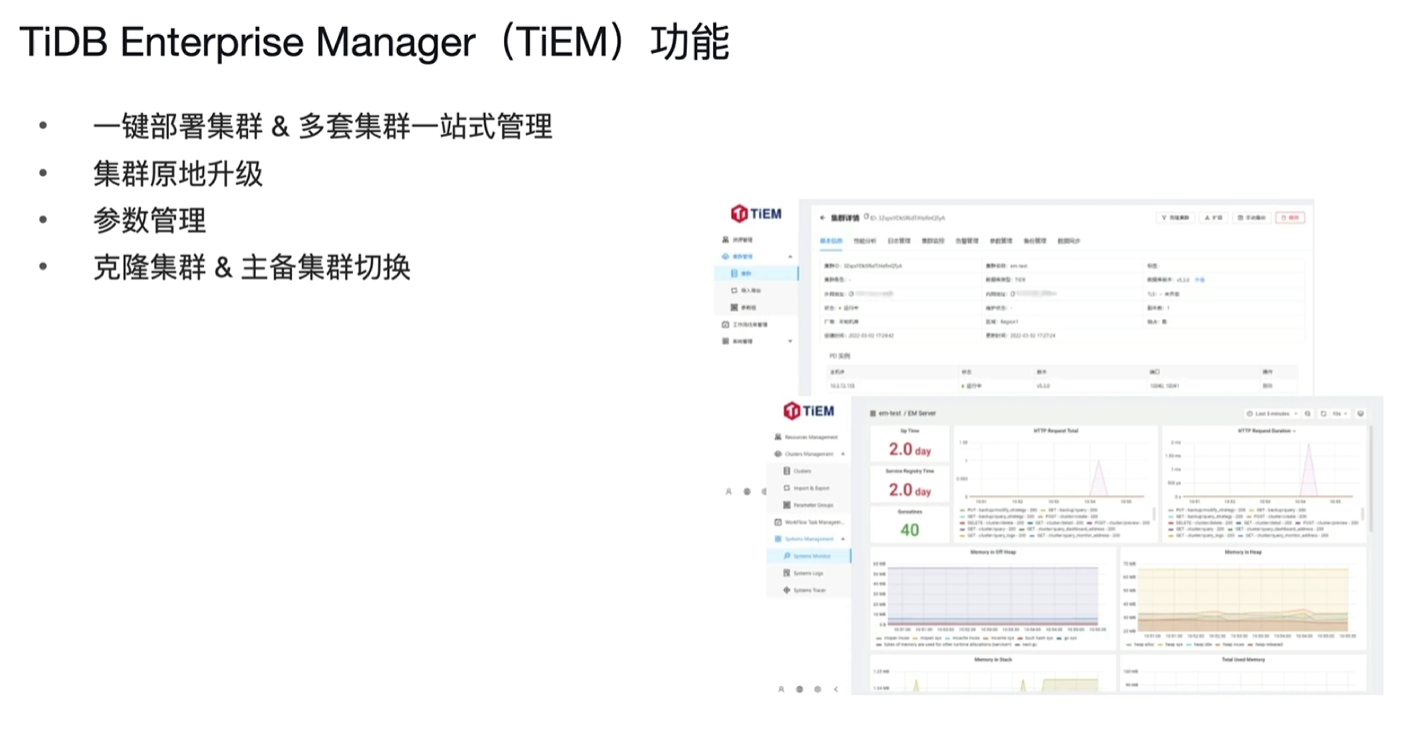
7.5 TiDB Enterprise Manager (TiEM)


八、TiDB Cloud
8.1 为什么选择TiDB
-
作为云原生数据库的好处
- 分布式SQL数据库-多租户
- 混合工作负载-在同一个数据库中(HTAP)
- 事务型:基于行的数据
- 分析性:基于列的数据
- 弹性比例
- 缩小-减少节点
- 横向扩展-添加节点
- 基于Raft的高可用性
- 每个数据段在3个可用区进行复制
-
多租户
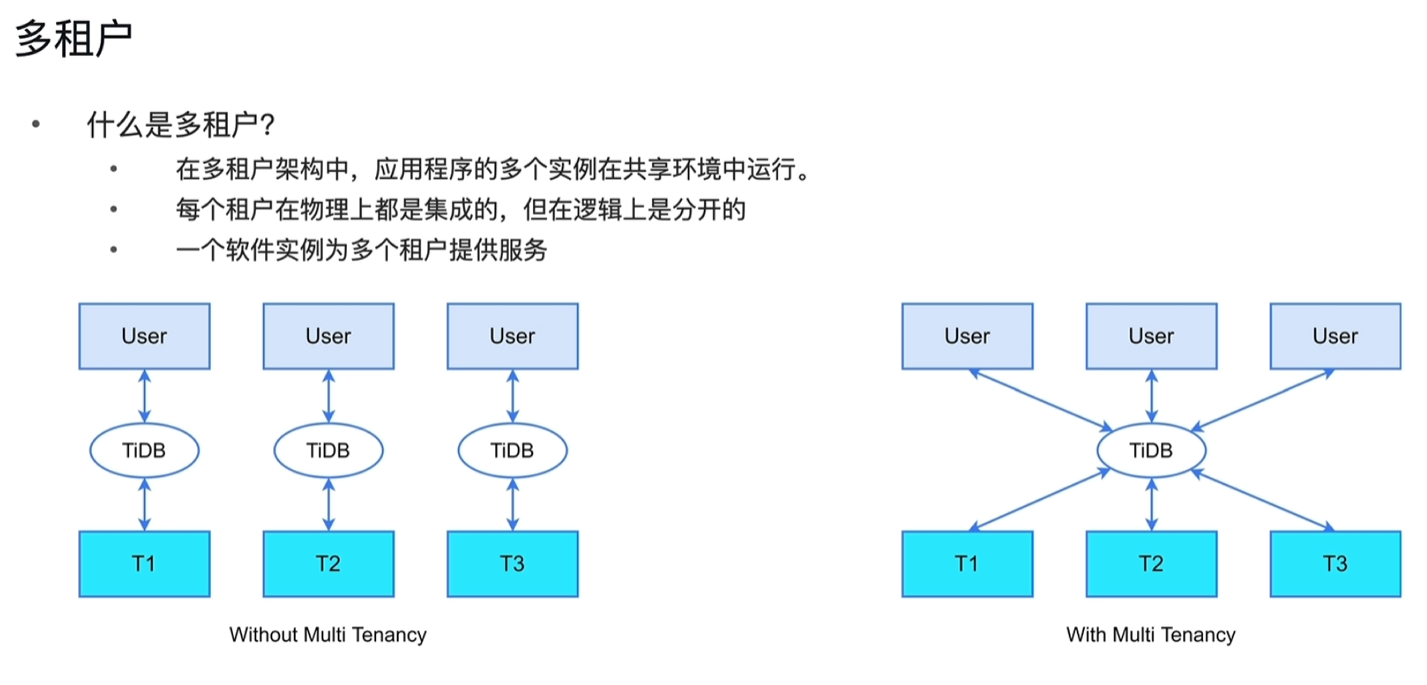
-
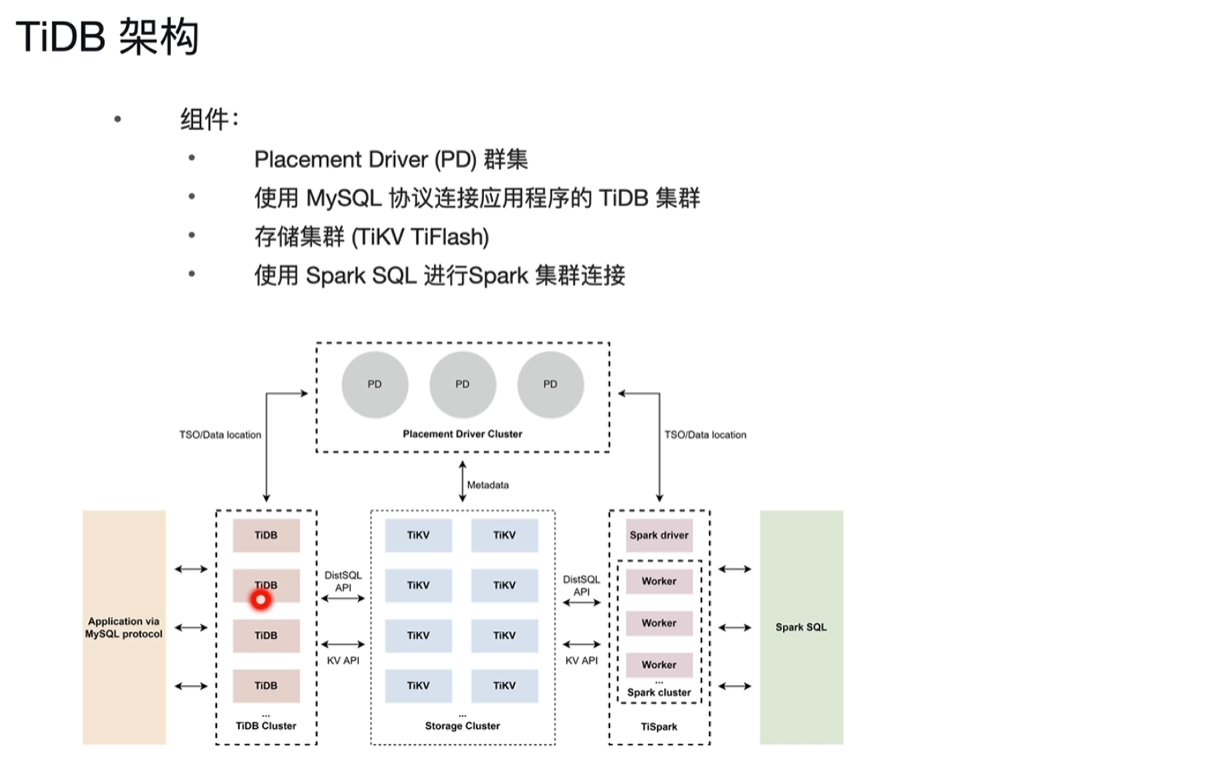
TiDB架构
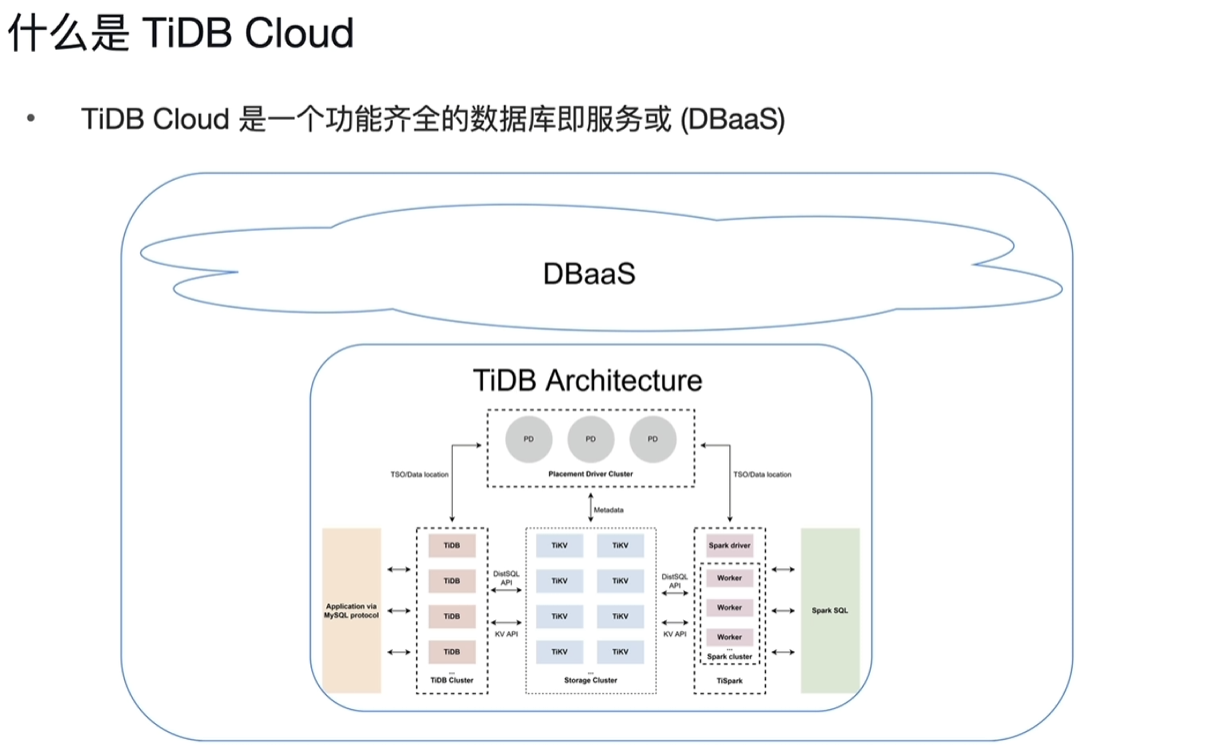
8.2 什么是TiDB Cloud
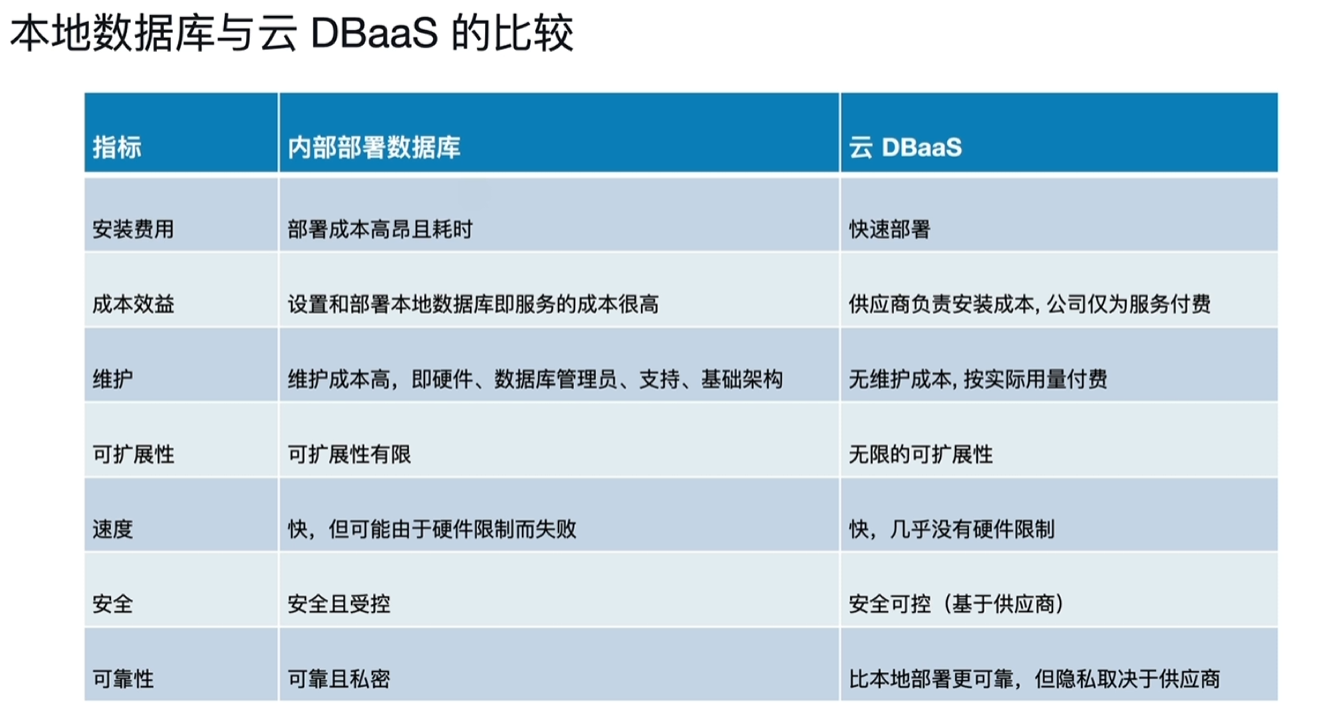
- VPC:虚拟专有网络
- TiDB Cloud Central Service
- 提供计费、报警、元数据存储、Dashboard等功能,对外提供服务
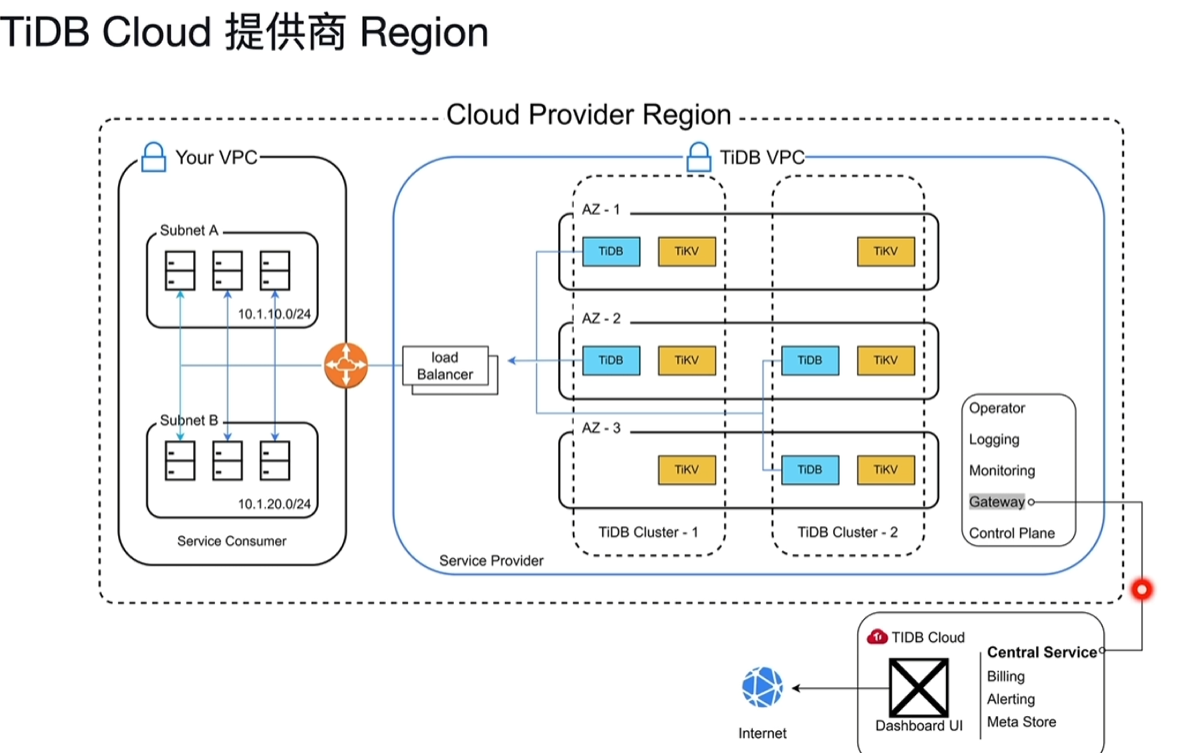
- 提供计费、报警、元数据存储、Dashboard等功能,对外提供服务
- DeveloperTier与Dedicated Tier




