

一、 背景
目前有个apk的大表原先在tidb 中跑,期间出现update 语句时快时慢问题(存在写写冲突,业务逻辑一时半会无法解决),暂时迁移到了mysql,但是还是同步到下游Tidb,最近业务有一个聚合查询分析的场景在mysql中运行返回结果比较慢,比较头疼了,又想起了Tidb,想尝试一下,结果一运行,直接报Out Of Memory Quota😅,Tidb 默认限制sql 查询内存不能超过1GB,可见着条sql 确实是个重sql,机会来了,想起了Tidb tiflash 针对这种聚合查询分析场景应该会非常有效,于是开始了tiflash尝鲜
二、Tiflash 架构
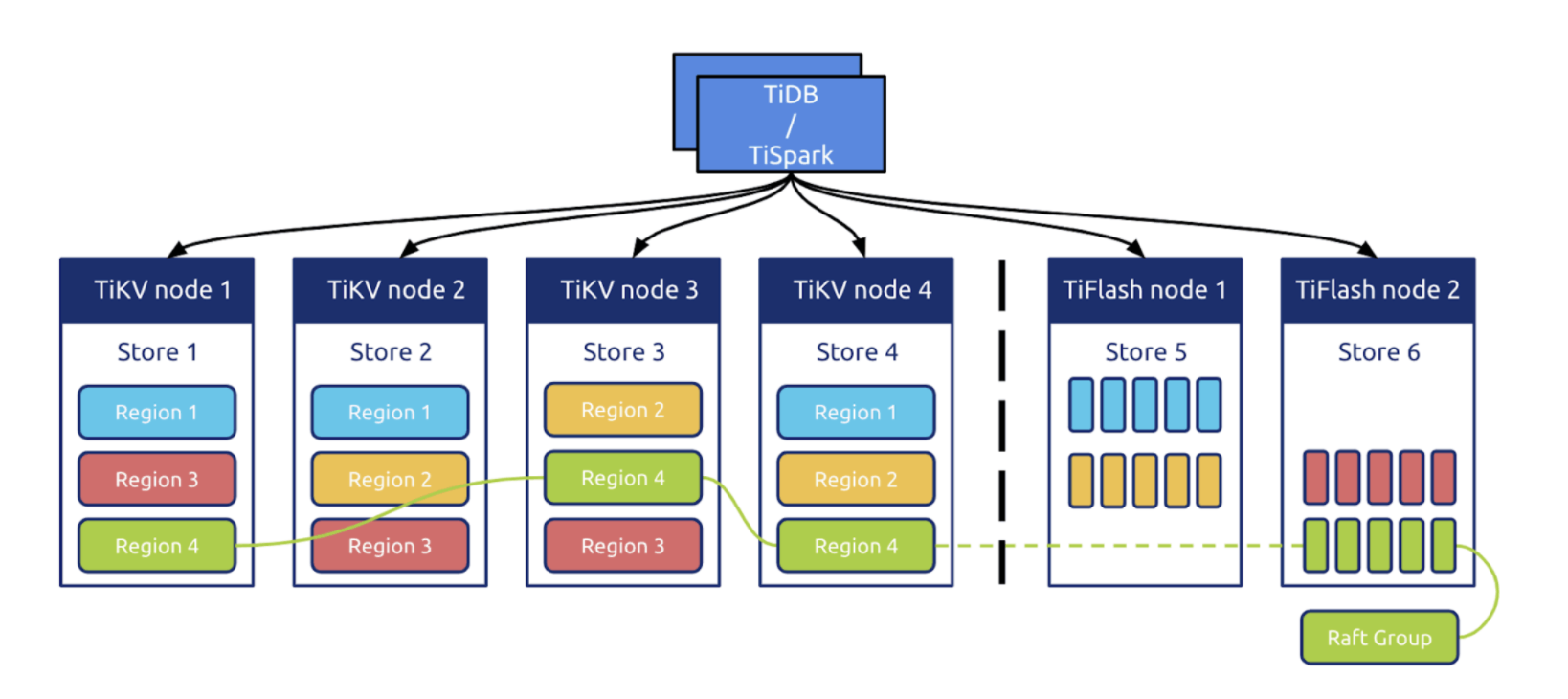
TiFlash 是 TiDB HTAP 形态的关键组件,它是 TiKV 的列存扩展,在提供了良好的隔离性的同时,也兼顾了强一致性。列存副本通过 Raft Learner 协议异步复制,但是在读取的时候通过 Raft 校对索引配合 MVCC 的方式获得 Snapshot Isolation 的一致性隔离级别。这个架构很好地解决了 HTAP 场景的隔离性以及列存同步的问题
三、扩容Tiflash 节点
假设要添加的节点ip 是1.1.1.1,2.2.2.2
(1)编辑scale-out.yaml 文件
tiflash_servers:
- host: 1.1.1.1
- host: 2.2.2.2
(2)执行tilash扩容
tiup cluster scale-out cluster_name scale-out.yaml
(3) 对表创建副本
ALTER TABLE table_name SET TIFLASH REPLICA count
四、使用Tiflash
数据库版本:5.7.25-TiDB-v5.0.3
表大小:10GB
select apk_md5, check_time, apk_icon_md5, apk_state, count(apk_md5) as ct from apk group by apk_icond5, apk_state limit 100;
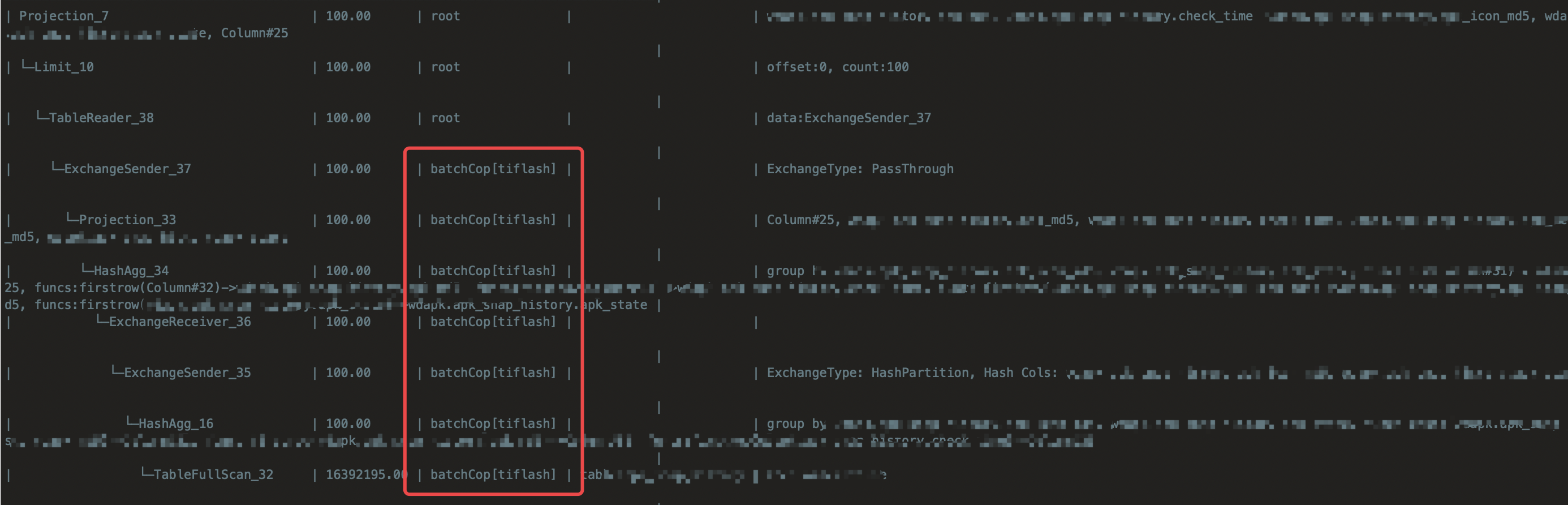
explain analyze sql 耗时大约1s左右,而mysql 直接卡死,半天没返回数据,开发重燃使用TIDB的信心,准备再次使用Tidb了😃

五、未来展望
随着Tidb 5.x HTAP 越来越完善,我会积极跟业务沟通,寻找合适的场景来使用这些新特性,让更多的业务认识使用TIDB,希望Tidb 发展越来越好