

1、前言
分布式数据库的备份,实现本身就存在很多难点:
-
每个分布式存储节点独立备份?or 整体逻辑备份?
-
如何备份?
-
备份存放地点
-
备份恢复如何做?
-
集群过大如何处理?
-
集群压力过大如何处理?
面对如此多的难点,TiDB本身提供了几个参考方案:
-
-
mydumper/dumping 逻辑备份工具
-
BR: 分布式备份恢复的命令行工具
2、信息
2.1、集群大小信息
大于3T的集群还是挺多的
| TiDB集群大小 | <3T | >3T | >10T |
|---|---|---|---|
| 数量 | 70套+ | 20套 | 10套左右 |
2.2、某集群的表信息
例如某集群的表信息
只少部分的表比较大,导致整个集群备份时间过长,无法备份

2.3、备份举例
备份日志信息:1.3T集群备份时间12小时+,即小于3T的集群也存在备份时间特别长的
【命令】:
dumpling -u xxx -p xxx -h xxx-P xxx–status-addr xxx -F 64MiB -c gzip -t 6 -o xxx
【日志】:
[2021/06/18 02:00:02.021 +08:00] [INFO] [versions.go:55] [“Welcome to dumpling”]
[2021/06/18 14:24:02.623 +08:00] [INFO] [status.go:38] [progress] [tables=“6/7 (85.7%)”] [“finished rows”=1925417242]
[“estimate total rows”=1894156590] [“finished size”= 1.34TB ] [“average speed(MiB/s)”=30.258647971246944] [2021/06/18 14:25:26.909 +08:00] [INFO] [collector.go:212] [“backup Success summary: total backup ranges: 18, total success: 18,
total failed: 0, total take(backup time): 12h25m24 .287105754s, total take(real time): 12h25m24.287132149s,
total size(MB): 1280405.48 ,avg speed(MB/s):28.63,total rows:1929008578”]
3、备份实现
3.1、实现方式
BR备份工具我们还在内测中,目前NFS的性能、稳定性均有一定问题,后续测试好后再进行分享。当前还是逻辑备份
表重要性:
- 越大的表,重要性相对越低,例如日志流水表等
- 越小的表,重要性相对越高,例如配置表等
- 暂时无法备份的表,后期我们再考虑下如何备份
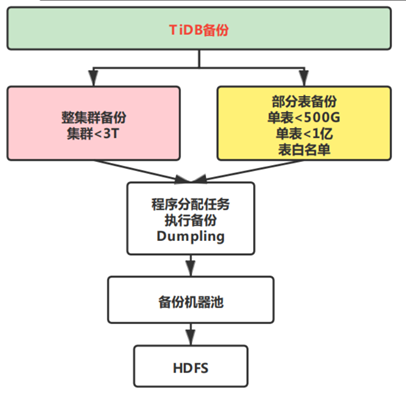
整集群备份:
- 小于3T的集群
- 如果小于3T也备份失败,则改成部分表备份
部分表备份:
- 单表<500G
- 单表小于1亿
- 白名单
备份工具:
- Dumpling备份
- BR持续调研与关注
3.2、当前备份情况
集群备份:60套左右
单表备份的集群:25套
单表备份的表:1500张左右