

目的:
随着tidb使用场景的越来越多,接入的业务越来越重要,不由得想试验下tidb组件的高可用性以及故障或者灾难如何恢复,恢复主要涉及的是pd组件和tikv组件,本文主要涉及pd组件。
tikv恢复请看TiKV多副本丢失以及修复实践
基础情况
tidb版本:5.2.1
部署方式:tiup
部署拓扑
$ cat tidb-test.yaml
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb/tidb-deploy"
data_dir: "/data/tidb/tidb-data"
pd_servers:
- host: 10.12.16.225
- host: 10.12.16.226
- host: 10.12.16.227
tidb_servers:
- host: 10.12.16.225
- host: 10.12.16.226
- host: 10.12.16.227
tikv_servers:
- host: 10.12.16.225
- host: 10.12.16.226
- host: 10.12.16.227
monitoring_servers:
- host: 10.12.16.228
grafana_servers:
- host: 10.12.16.228
alertmanager_servers:
- host: 10.12.16.228
部署结果查看:
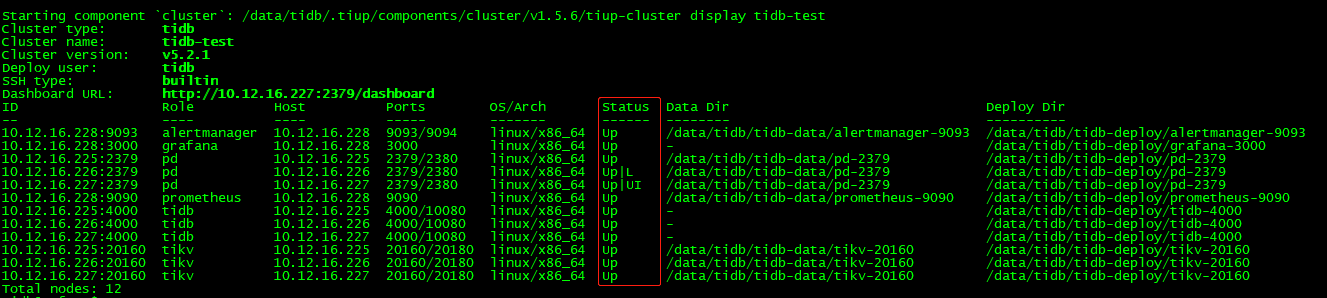
$ tiup cluster display tidb-test
Found cluster newer version:
The latest version: v1.6.0
Local installed version: v1.5.6
Update current component: tiup update cluster
Update all components: tiup update --all
Starting component `cluster`: /data/tidb/.tiup/components/cluster/v1.5.6/tiup-cluster display tidb-test
Cluster type: tidb
Cluster name: tidb-test
Cluster version: v5.2.1
Deploy user: tidb
SSH type: builtin
Dashboard URL: http://10.12.16.227:2379/dashboard
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
-- ---- ---- ----- ------- ------ -------- ----------
10.12.16.228:9093 alertmanager 10.12.16.228 9093/9094 linux/x86_64 Up /data/tidb/tidb-data/alertmanager-9093 /data/tidb/tidb-deploy/alertmanager-9093
10.12.16.228:3000 grafana 10.12.16.228 3000 linux/x86_64 Up - /data/tidb/tidb-deploy/grafana-3000
10.12.16.225:2379 pd 10.12.16.225 2379/2380 linux/x86_64 Up /data/tidb/tidb-data/pd-2379 /data/tidb/tidb-deploy/pd-2379
10.12.16.226:2379 pd 10.12.16.226 2379/2380 linux/x86_64 Up|L /data/tidb/tidb-data/pd-2379 /data/tidb/tidb-deploy/pd-2379
10.12.16.227:2379 pd 10.12.16.227 2379/2380 linux/x86_64 Up|UI /data/tidb/tidb-data/pd-2379 /data/tidb/tidb-deploy/pd-2379
10.12.16.228:9090 prometheus 10.12.16.228 9090 linux/x86_64 Up /data/tidb/tidb-data/prometheus-9090 /data/tidb/tidb-deploy/prometheus-9090
10.12.16.225:4000 tidb 10.12.16.225 4000/10080 linux/x86_64 Up - /data/tidb/tidb-deploy/tidb-4000
10.12.16.226:4000 tidb 10.12.16.226 4000/10080 linux/x86_64 Up - /data/tidb/tidb-deploy/tidb-4000
10.12.16.227:4000 tidb 10.12.16.227 4000/10080 linux/x86_64 Up - /data/tidb/tidb-deploy/tidb-4000
10.12.16.225:20160 tikv 10.12.16.225 20160/20180 linux/x86_64 Up /data/tidb/tidb-data/tikv-20160 /data/tidb/tidb-deploy/tikv-20160
10.12.16.226:20160 tikv 10.12.16.226 20160/20180 linux/x86_64 Up /data/tidb/tidb-data/tikv-20160 /data/tidb/tidb-deploy/tikv-20160
10.12.16.227:20160 tikv 10.12.16.227 20160/20180 linux/x86_64 Up /data/tidb/tidb-data/tikv-20160 /data/tidb/tidb-deploy/tikv-20160
提示:
防止tiup部署后,在破坏掉pd实例后,pd-server被自动拉起来,影响试验效果,需要做如下修改
1、在/etc/systemd/system/pd-2379.service中去掉 Restart=always或者改Restart=no,
2、执行systemctl daemon-reload 重新加载
模拟PD集群损坏:
1、在10.12.16.227上删除掉pd-server进程的数据目录
$ cd /data/tidb/tidb-data
$ ls
monitor-9100 tikv-20160 pd-2379
$rm -rf pd-2379
查看10.12.16.227:2379进程状态:

此时 tikv和tidb组件是up状态,还能正常提供服务
2、在10.12.16.226上删除掉pd-server进程的数据目录
$ cd /data/tidb/tidb-data
$ ls
monitor-9100 tikv-20160 pd-2379
$rm -rf pd-2379
查看10.12.16.226:2379进程状态:

此时发现pd集群全部是down状态(原因大家应该很清楚,大多数原则无法满足,pd无法选举出leader),并且tikv是N/A状态,整个集群无法对外提供服务,此时集群不可用
3、在10.12.16.225上删除掉pd-server进程的数据目录
$ cd /data/tidb/tidb-data
$ ls
monitor-9100 tikv-20160 pd-2379
$ rm -rf pd-2379
查看10.12.16.225:2379进程状态:
此时跟步骤2的结果一样,整个集群在步骤2已经对外不可用
到目前为止,整个PD集群已经完全被破坏掉,所有pd-server进程对应的数据目录全部被删除掉
修复PD集群:
1、找出已经损坏的PD集群ID,即cluster-id和alloc-id
cluster-id查找方法:
方法1:
通过pd日志查找
$ cat /data/tidb/tidb-deploy/pd-2379/log/pd.log | grep "init cluster id"
输出:
[2021/10/09 16:02:09.878 +08:00] [INFO] [server.go:351] ["init cluster id"] [cluster-id=7016973815389845033]
方法2:
通过tidb-server日志查找
$ cat /data/tidb/tidb-deploy/tidb-4000/log/tidb.log | grep "init cluster id"
输出:
[2021/10/09 16:02:11.722 +08:00] [INFO] [base_client.go:126] ["[pd] init cluster id"] [cluster-id=7016973815389845033]
方法3:
通过tikv日志查找
$ cat /data/tidb/tidb-deploy/tikv-20160/log/tikv.log | grep "connect to PD cluster"
输出:
[2021/10/09 16:02:10.165 +08:00] [INFO] [server.rs:344] ["connect to PD cluster"] [cluster_id=7016973815389845033]
alloc-id只能通过pd日志查找:
$ cat /data/tidb/tidb-deploy/pd-2379/log/pd.log | grep "idAllocator allocates a new id" | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r | head -n 1
输出:
4000
2、通过强制缩容剔除226和227上的pd-server节点
$ tiup cluster scale-in tidb-test -N 10.12.16.226:2379 --force
......
failed to delete pd: Get "http://10.12.16.225:2379/pd/api/v1/members": dial tcp 10.12.16.225:2379: connect: connection refused
Stopping component pd
Stopping instance 10.12.16.226
Stop pd 10.12.16.226:2379 success
Destroying component pd
Destroying instance 10.12.16.226
Destroy 10.12.16.226 success
- Destroy pd paths: [/data/tidb/tidb-deploy/pd-2379 /etc/systemd/system/pd-2379.service /data/tidb/tidb-data/pd-2379 /data/tidb/tidb-deploy/pd-2379/log]
+ [ Serial ] - UpdateMeta: cluster=tidb-test, deleted=`'10.12.16.226:2379'`
+ [ Serial ] - UpdateTopology: cluster=tidb-test
{"level":"warn","ts":"2021-10-09T16:31:42.706+0800","logger":"etcd-client","caller":"v3@v3.5.0/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc0001528c0/#initially=[10.12.16.225:2379]","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: last connection error: connection error: desc = \""transport: Error while dialing dial tcp 10.12.16.225:2379: connect: connection refused\"""}
Error: context deadline exceeded
Verbose debug logs has been written to /data/tidb/.tiup/logs/tiup-cluster-debug-2021-10-09-16-31-42.log.
Error: run `/data/tidb/.tiup/components/cluster/v1.5.6/tiup-cluster` (wd:/data/tidb/.tiup/data/SlKXEx0) failed: exit status 1
虽然有报错,但是还是强制删除两个节点
$ tiup cluster display tidb-test
输出:

3、启动仅存的10.12.16.225:2379节点
$ tiup cluster start tidb-test -N 10.12.16.225:2379
......
Start 10.12.16.225 success
+ [ Serial ] - UpdateTopology: cluster=tidb-test
{"level":"warn","ts":"2021-10-09T16:35:22.598+0800","logger":"etcd-client","caller":"v3@v3.5.0/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc0001b6700/#initially=[10.12.16.225:2379]","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = context deadline exceeded"}
Error: context deadline exceeded
Verbose debug logs has been written to /data/tidb/.tiup/logs/tiup-cluster-debug-2021-10-09-16-35-22.log.
Error: run `/data/tidb/.tiup/components/cluster/v1.5.6/tiup-cluster` (wd:/data/tidb/.tiup/data/SlKYAsl) failed: exit status 1
$tiup cluster display tidb-test
输出:
实际上也是没有启动成功
$ pidof pd-server
43663
说明pd-server进程是存在的,但是不能对外提供服务
查看日志:
[2021/10/09 16:39:02.211 +08:00] [WARN] [probing_status.go:70] ["prober detected unhealthy status"] [round-tripper-name=ROUND_TRIPPER_RAFT_MESSAGE] [remote-peer-id=d13032871d13be7f] [rtt=0s] [error="dial tcp 10.12.16.226:2380: connect: connection refused"]
[2021/10/09 16:39:02.211 +08:00] [WARN] [probing_status.go:70] ["prober detected unhealthy status"] [round-tripper-name=ROUND_TRIPPER_SNAPSHOT] [remote-peer-id=d13032871d13be7f] [rtt=0s] [error="dial tcp 10.12.16.226:2380: connect: connection refused"]
[2021/10/09 16:39:02.211 +08:00] [WARN] [probing_status.go:70] ["prober detected unhealthy status"] [round-tripper-name=ROUND_TRIPPER_SNAPSHOT] [remote-peer-id=32a1a8544e3c1c6f] [rtt=0s] [error="dial tcp 10.12.16.227:2380: connect: connection refused"]
[2021/10/09 16:39:02.211 +08:00] [WARN] [probing_status.go:70] ["prober detected unhealthy status"] [round-tripper-name=ROUND_TRIPPER_RAFT_MESSAGE] [remote-peer-id=32a1a8544e3c1c6f] [rtt=0s] [error="dial tcp 10.12.16.227:2380: connect: connection refused"]
提示有remote-peer-id,单实例集群启动不应该有remote-peer-id才对,查看启动脚本
$ cat /etc/systemd/system/pd-2379.service
[Unit]
Description=pd service
After=syslog.target network.target remote-fs.target nss-lookup.target
[Service]
LimitNOFILE=1000000
LimitSTACK=10485760
User=tidb
ExecStart=/data/tidb/tidb-deploy/pd-2379/scripts/run_pd.sh
Restart=no
RestartSec=15s
[Install]
WantedBy=multi-user.target
在10.12.16.225上
$ rm -rf pd-2379 #原因:刚才启动时initial-cluster指定了三个节点,集群信息已经初始化到数据目录
$ tiup cluster start tidb-test -N 10.12.16.225:2379
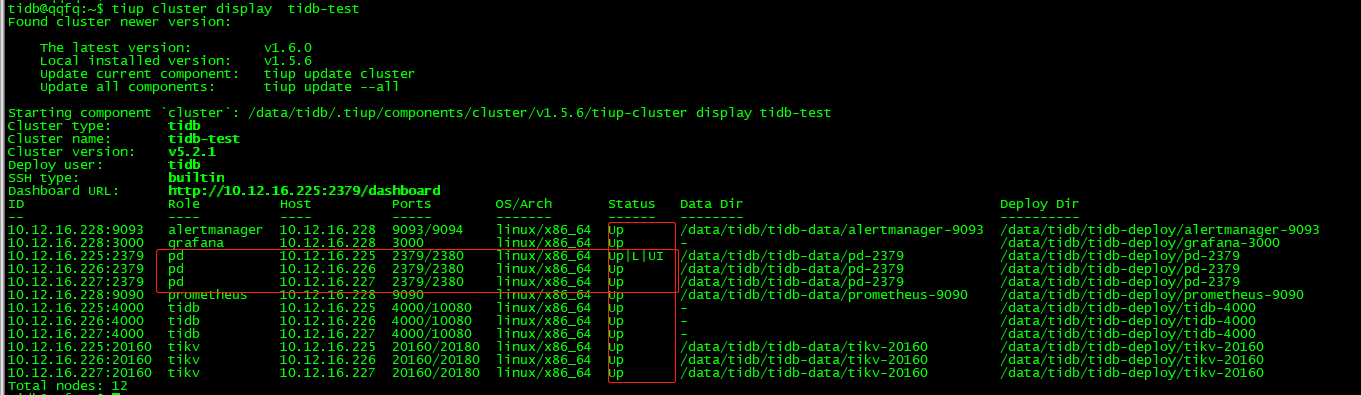
$ tiup cluster display tidb-test

发现集群pd已经是up状态
4、修改新pd集群的cluster-id和alloc-id
$ tiup pd-recover -endpoints http://125.94.237.5:2379 -cluster-id 7016973815389845033 -alloc-id 6000
输出:
Starting component `pd-recover`: /data/tidb/.tiup/components/pd-recover/v5.2.1/pd-recover -endpoints http://10.12.16.225:2379 -cluster-id 7016973815389845033 -alloc-id 6000
recover success! please restart the PD cluster
5、重启pd集群
$ tiup cluster restart tidb-test -N 10.12.16.225:2379
$ tiup cluster display tidb-test

此时整个集群正常,可以对外提供服务
6、扩容pd集群
7、重启整个集群
略
总结:
1、pd集群只是存储元数据信息,并且是通过tikv心跳上报,故pd集群的所有数据丢失后,整个tidb集群可以通过重建pd集群修复;
2、如果用到了TiCDC,那么changefeed的配置需要备份,否则pd数据全部丢失后,无法恢复changefeed任务;
3、重建pd集群需要知道pd老集群的cluster-id和alloc-id,日常备份这两个值即可。
4、一些动态修改的调度策略调整,修复后就会变成默认值,这个需要修复后及时调整到之前的。