本文整理自 TUG 大使、360 金融数据小组负责人黄龙在 8 月 25 日 TUG 华南区首次线下活动的分享。
TiDB 整体概况

TiDB 在 360 金融主要用来存一些实时数据。历史数据或者数据量很大的数据是存在 Hive 里面。
TiDB 数据主要来源:
- 通过 DM 从 MySQL 同步过来的数据,可以进行实时的数据监控,和一些即席的数据查询。
- Kafka 队列里的用户事件数据,总体大概是3 亿条/天,不过我们会做定时清理,确保数据量在2天范围内。
- 我们自己放到 RocketMQ 里面的一些数据。这个数据是我们有一个 RocketMQ 的MySQL 插件,也是把 MySQL 的一些 binlog 实时进行处理,经转化为 json 放到 RocketMQ 里面,然后我们再去消费这个数据。
整体数据量:6T,接近 90w region
承载业务:
- 报表:渠道报表,产品报表,电商业务报表。
- 实时监控:之前使用 MySQL 做监控,现在通过 DM 同步过来 MySQL 的数据,放在 TiDB 上做实时监控。
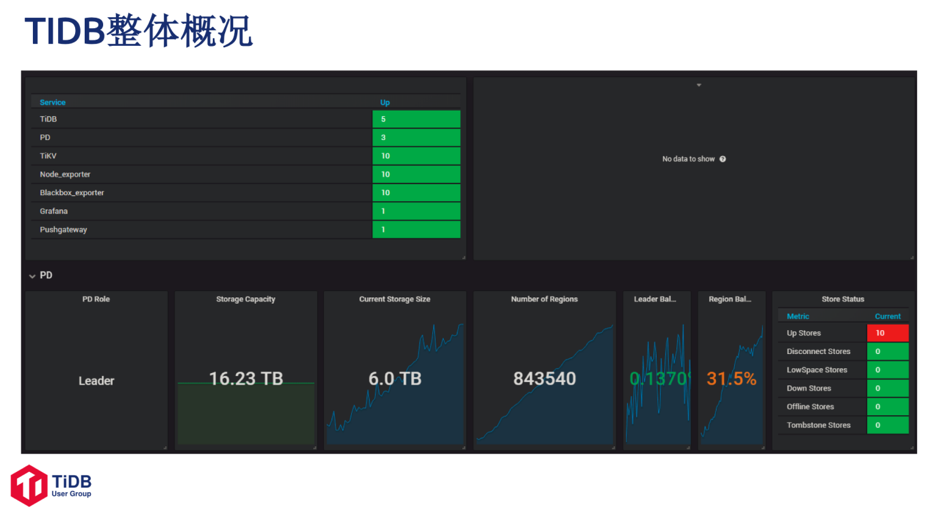
目前部署了 5 个 TiDB 节点,10 个 TiKV 节点,运行了大概半年。
渠道实时转化业务
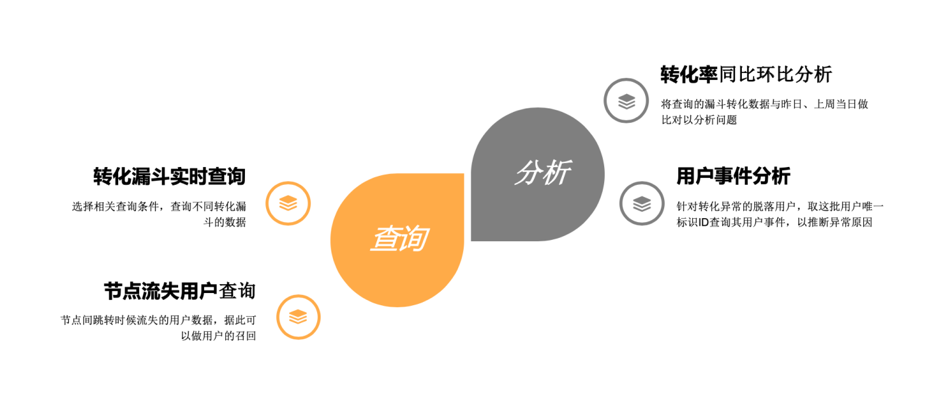
在渠道实时转化业务的设计中主要有四个方面的考虑:
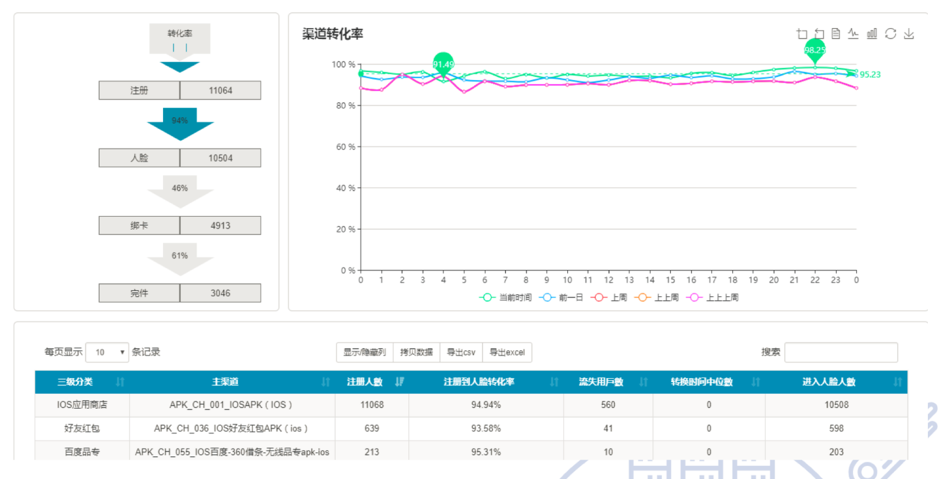
- 转化漏斗实时查询:之前把渠道转化数据拉出来通过邮件发给大家,比较慢。现在可以做指标对比,同比分析,选择相关查询条件查询不同转化漏斗的数据。
- 节点流失用户查询:节点间跳转时候流失的用户,查看这些用户的信息,并据此做用户召回。
- 转化率同比环比分析:将查询的漏斗转化数据与昨日、上周当日做对比,分析问题。
- 用户事件分析:针对转化一场的流失用户,取这批用户的唯一标识 ID 查询其用户事件,推断异常原因。
数据处理

数据结构设计
当时的设计原则必须要让查询简单,我当时想法是必须要做单表查询。如果把事件分散到不同的表里,然后去查转化率,做表的 Join,性能肯定是非常低的。我们当时设计关键的三个转化率:H5 渠道注册转化,APP 渠道注册转化,渠道完件转化。
- 渠道完件转化从登录开始算,同一用户每一个环节节点都会写入对应用户记录的节点时间字段,以确保查询过程中不出现表 Join 操作,提高查询效率。
- 表字段有两种类型:维度字段,包括 H5 指纹,请求 IP 等设备信息;事件发生时间字段,包括看广告的时间,发送短信验证码的时间等。
- 查询逻辑:依据选择转化业务、渠道和时间范围条件,查询这些条件下的相应事件以用户标示去重的数量即可。

数据处理逻辑
- 实时消费指定埋点数据写入/更新至 TiDB:根据转化事件基础配置,消费 Kafka 中指定的用户事件,并写入 TiDB 的指定转化表,对于满足时间窗口范围要求的后续事件,一般是更新相应表数据的事件时间字段。
- 实时消费指定 binlog 数据写入/更新至 TiDB:根据转化事件基础配置,消费 RocketMQ 的 binlog 事件,将其依照配置的规范转化为相应事件,并根据转化事件的时间窗口配置更新相应表数据的事件字段。
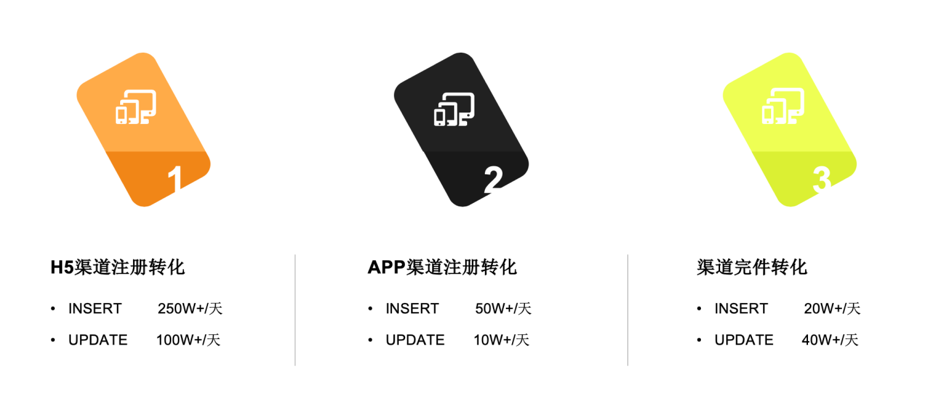
如何阐述我们转化率表现的一些数据:
- H5 渠道注册转化:insert 250w+/天,update 100w+/天
- APP 渠道注册转化:insert 50w+/天,update 10w+/天
- 渠道完件转化:insert 20w+/天,update 40w+/天
查询界面展示如下,查询条件略掉: