

1、背景
TEM(TiDB Enterprise Manager)是平凯数据库(基于 TiDB 的企业版)提供的一款企业级运维管理平台,面向分布式数据库全生命周期运维场景,帮助企业简化复杂的运维流程,提高运维效率与规范性。
TEM 的核心能力包括:
全生命周期运维管理:从集群部署、配置管理、扩缩容、升级,到运维巡检、备份恢复、故障恢复等一体化支持
可视化监控与智能诊断:集成监控大盘,可视化展示主机与数据库资源、SQL 负载、慢查询等指标,并支持告警与性能诊断。
企业级安全与治理:支持访问控制、全流程审计、TLS 加密、集群防火墙等企业级安全能力。
统一纳管与自动化编排:支持跨集群、跨数据中心统一纳管资源,自动化执行运维任务,无需切换多个传统工具。
集成运维生态:融合常用运维组件(如 Prometheus、Grafana),避免运维工具碎片化。
总而言之,TEM 不只是一个图形界面,而是将 TiDB 的运维能力整合成一套企业级、可统一管理的平台,让日常运维更可控、更规范、更高效。
熟悉TiDB数据库的伙伴都了解使用resource control来实现资源隔离,资源隔离的最小单位为RU,这个换算成CPU、MEM、Disk相对抽象。相比 TiDB 原生只用 RU 抽象值来做资源隔离,TEM 提供了更直观、更物理资源导向的隔离能力,便于企业用户理解、管理和规划资源。
TEM 的资源管理不仅展示资源,还可以根据物理资源(如 CPU、MEM、Disk)来划分集群资源,尤其在多租户或资源池化场景中更加直观。这意味着你可以直接基于物理资源指标来定义隔离策略,而不是通过抽象的 RU 值换算。
参考文档:
https://pingkai.cn/docs/tidb/dev/tidb-resource-control-ru-groups/#%E4%BD%BF%E7%94%A8%E8%B5%84%E6%BA%90%E7%AE%A1%E6%8E%A7-resource-control-%E5%AE%9E%E7%8E%B0%E8%B5%84%E6%BA%90%E7%BB%84%E9%99%90%E5%88%B6%E5%92%8C%E6%B5%81%E6%8E%A7
https://pingkai.cn/docs/tem/stable/tem-cluster-management-create-tidb/
2、环境准备
准备9台物理机,使用TEM纳管,并创建6套云化集群
集群信息如下:
集群名 |
部署模式 |
资源分配 |
节点 |
版本 |
|---|---|---|---|---|
tpcc1 |
共享 |
60c/200G |
2个tidb(8C 32G)、3个pd(4C 8G)、3个tikv(8C 32G) |
v8.5.3 |
tpcc2 |
共享 |
60c/200G |
2个tidb(8C 32G)、3个pd(4C 8G)、3个tikv(8C 32G) |
v8.5.3 |
tpcc3 |
共享 |
60c/200G |
2个tidb(8C 32G)、3个pd(4C 8G)、3个tikv(8C 32G) |
v8.5.3 |
tpcc4 |
共享 |
60c/200G |
2个tidb(8C 32G)、3个pd(4C 8G)、3个tikv(8C 32G) |
v8.5.3 |
tpcc5 |
共享 |
60c/200G |
2个tidb(8C 32G)、3个pd(4C 8G)、3个tikv(8C 32G) |
v8.5.3 |
tpcc6 |
共享 |
60c/200G |
2个tidb(8C 32G)、3个pd(4C 8G)、3个tikv(8C 32G) |
v8.5.3 |
主机信息如下:
ip地址 |
主机名 |
规格 |
关联集群 |
类型 |
|---|---|---|---|---|
ip1 |
host1 |
64C 512G |
tpcc1、tpcc2、tpcc3、tpcc4、tpcc5、tpcc6 |
物理机 |
ip2 |
host2 |
64C 512G |
tpcc1、tpcc2、tpcc3、tpcc4、tpcc5、tpcc6 |
物理机 |
ip3 |
host3 |
64C 512G |
tpcc1、tpcc2、tpcc3、tpcc4、tpcc5、tpcc6 |
物理机 |
ip4 |
host4 |
64C 512G |
tpcc1、tpcc2、tpcc3、tpcc4、tpcc5、tpcc6 |
物理机 |
ip5 |
host5 |
64C 512G |
tpcc1、tpcc2、tpcc3、tpcc4、tpcc5、tpcc6 |
物理机 |
ip6 |
host6 |
64C 512G |
tpcc1、tpcc2、tpcc3、tpcc4、tpcc5、tpcc6 |
物理机 |
ip7 |
host7 |
64C 512G |
tpcc1、tpcc2、tpcc3、tpcc4、tpcc5、tpcc6 |
物理机 |
ip8 |
host8 |
64C 512G |
tpcc1、tpcc2、tpcc3、tpcc4、tpcc5、tpcc6 |
物理机 |
ip9 |
host9 |
64C 512G |
tpcc1、tpcc2、tpcc3、tpcc4、tpcc5、tpcc6 |
物理机 |
ip10 |
host10 |
64C 512G |
tiup中控 |
物理机 |
集群拓扑如下:
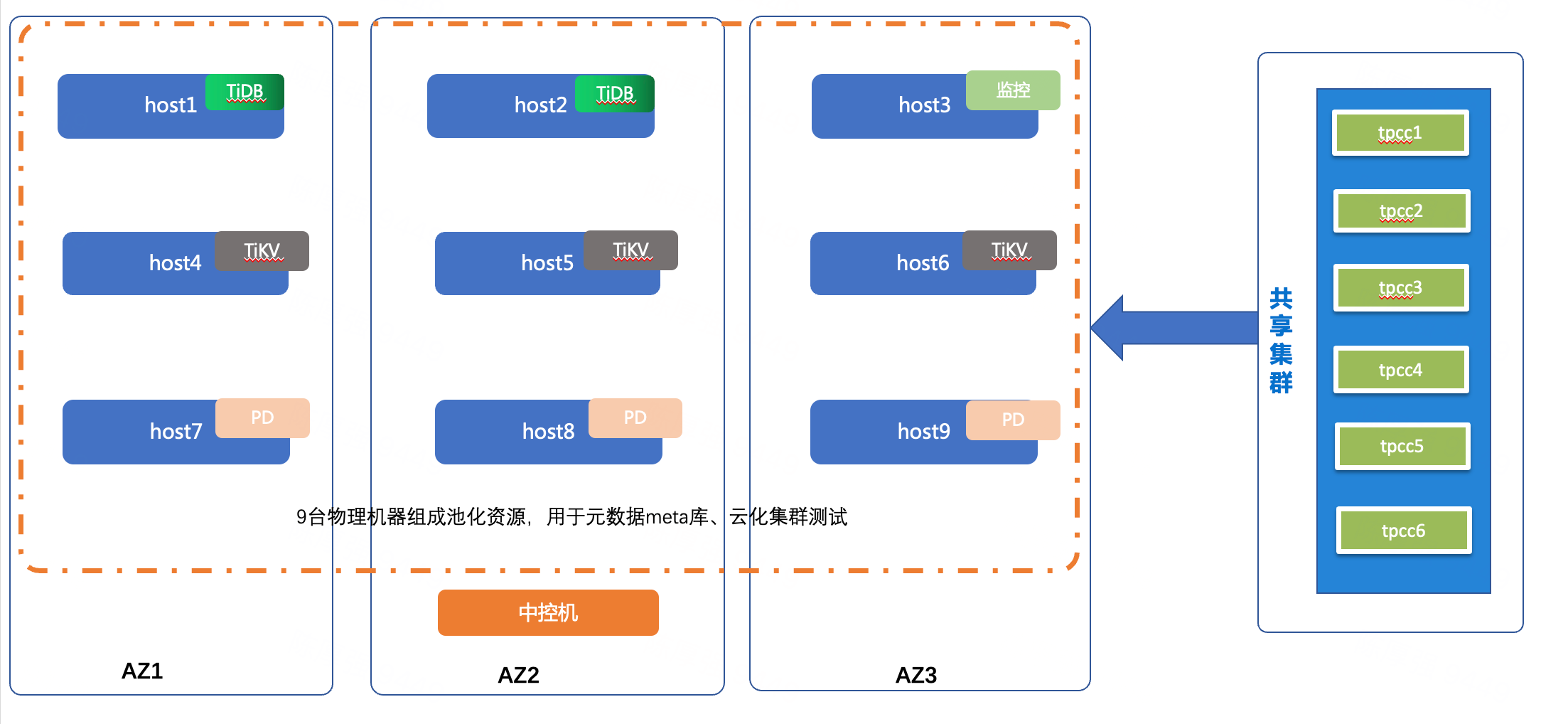
准备10台物理机,TEM纳管为共享主机,每台主机划分的角色如上图所示,每套集群有2个tidb(8C 32G)、3个pd(4C 8G)、3个tikv(8C 32G)、1个监控组件(4C 8G);创建6套共享集群,每套集群的拓扑和物理机资源均相同,只是端口号不同,使用tpcc导入测试数据,进行tpcc测试。
为了验证云化资源的隔离特性,6套集群除了端口号不一样,其他条件均保持一致。
3、测试TEM云化功能之资源隔离
使用tpcc来模拟测试,tpcc的参数均保持一致,6套集群的配置及所在主机均保持一致。
准备tpcc数据,使用如下命令,向6套集群注入基础数据
tiup bench tpcc -H ip -P4000 -D tpcc -Uroot -p --warehouse 200 --ignore-error --threads 200 prepare
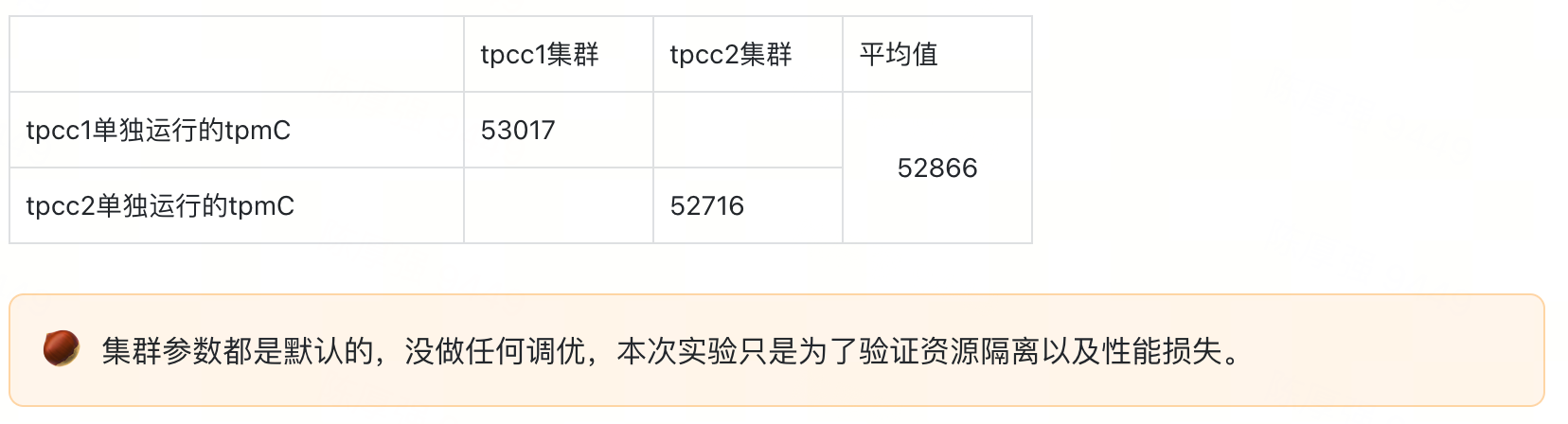
3.1、单个集群tpcc测试
6套集群正常运行,但只有一套集群运行tpcc,为了保证数据准确性,测试2次。
使用tpcc来压测,时间为10min,选择2套集群,分别单独运行。
tiup bench tpcc -H ip -P4000 -D tpcc -Uroot -p --warehouse 200 --ignore-error --threads 200 --time 10m run
3.2、两个集群同时tpcc测试
6套集群正常运行,2套集群同时运行tpcc,为了保证数据准确性,测试2次。
tiup bench tpcc -H ip -P4000 -D tpcc -Uroot -p --warehouse 200 --ignore-error --threads 200 --time 10m run

3.3、四个集群同时tpcc测试
6套集群正常运行,4套集群同时运行tpcc,为了保证数据准确性,测试2次。
tiup bench tpcc -H ip -P4000 -D tpcc -Uroot -p --warehouse 200 --ignore-error --threads 200 --time 10m run

3.4、六个集群同时tpcc测试
6套集群正常运行,6套集群同时运行tpcc,为了保证数据准确性,测试2次。
tiup bench tpcc -H ip -P4000 -D tpcc -Uroot -p --warehouse 200 --ignore-error --threads 200 --time 10m run

4、测试中资源使用情况
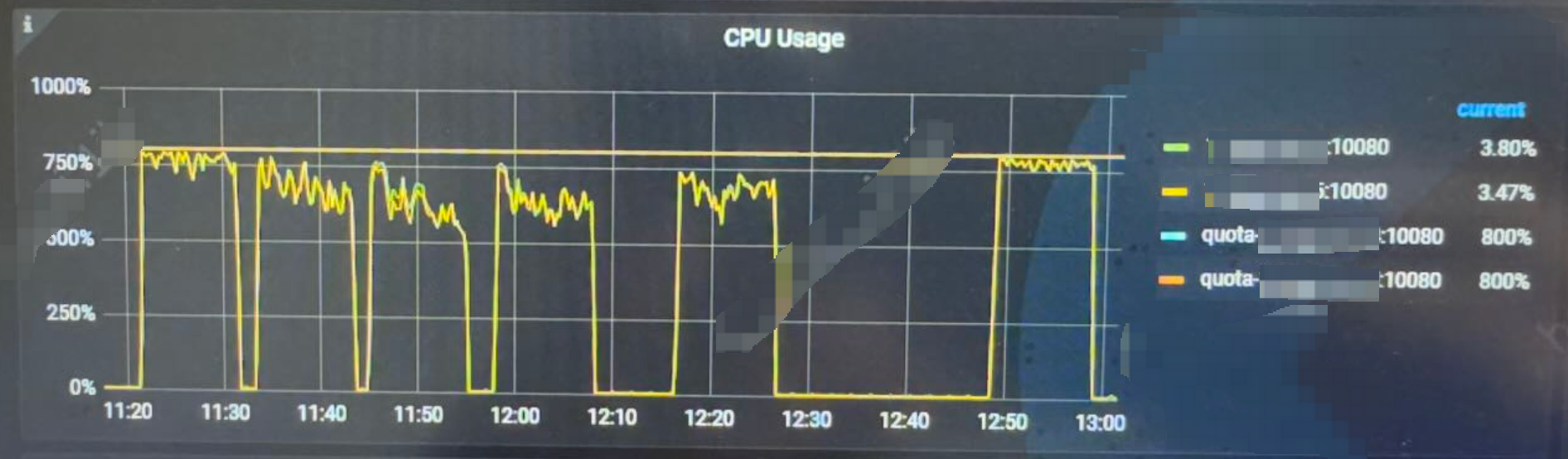
TiDB 的CPU使用情况
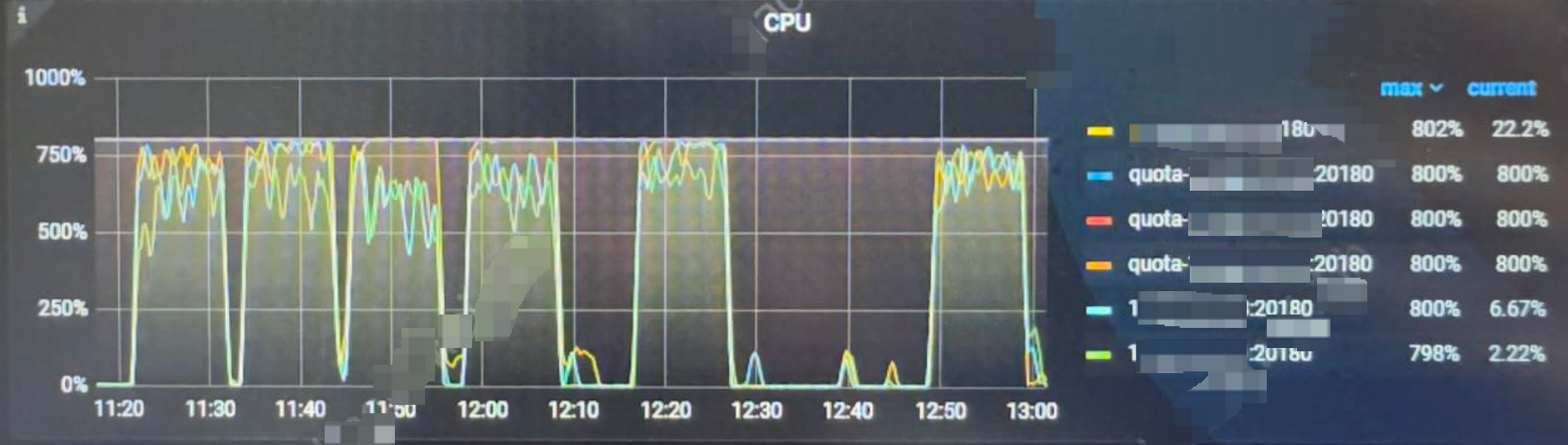
TiKV 的CPU使用情况
PD 的CPU使用情况
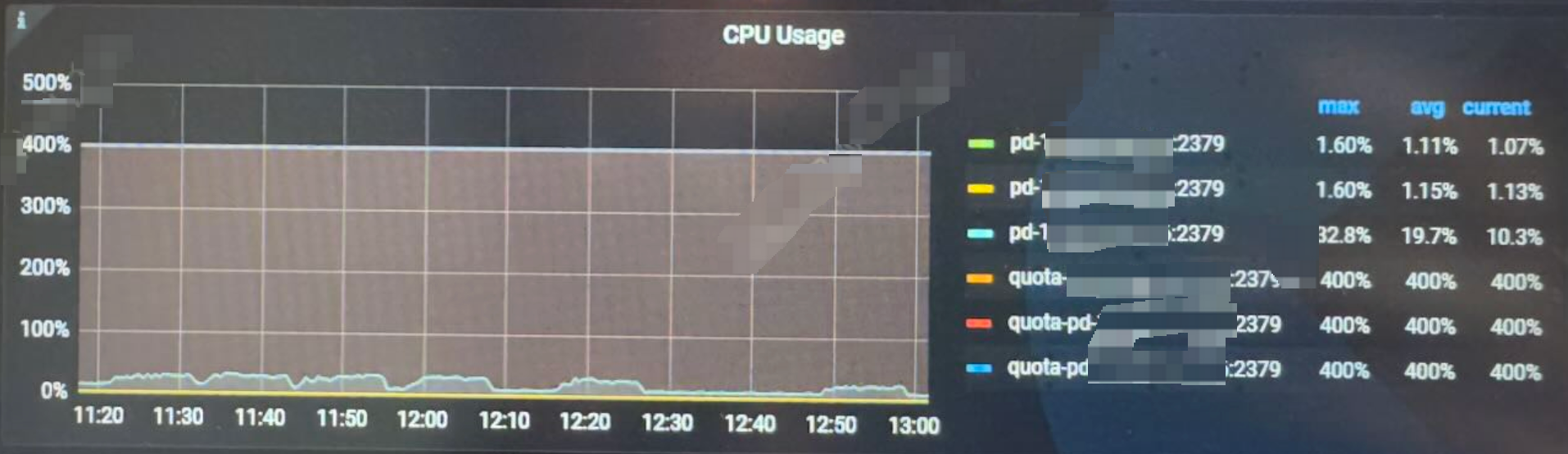
每套集群的资源使用率类似,都是没有超过规定的限制。
5、测试结果
通过上述4项测试内容,每项测试内容取平均值,作为测试项的实际值;对前2项测试结果取平均值,作为tpcc的基准值,来对比其余两项的性能影响。测试结果如下图所示:
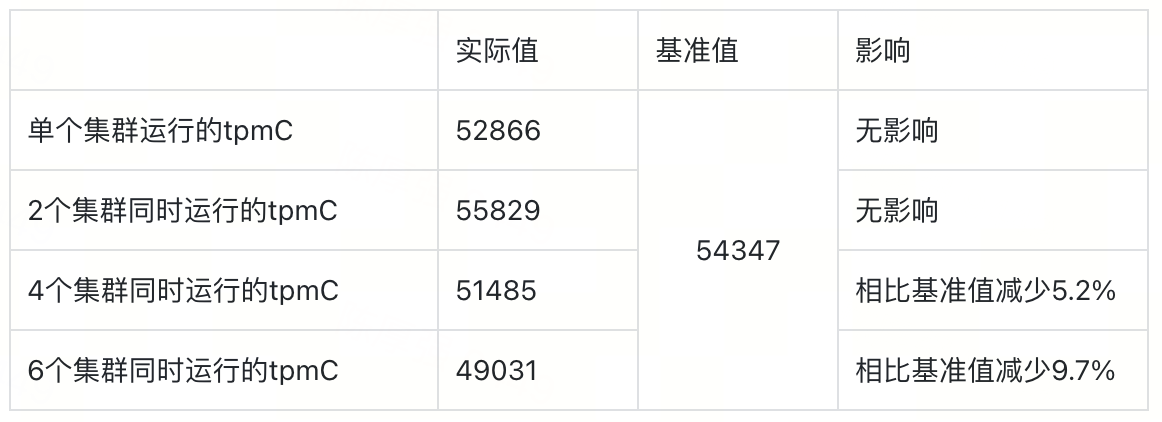
结果显示,在单集群和双集群场景下,系统 tpmC 与基准值基本一致,无明显性能变化;当运行四个集群时,tpmC 相较基准值降低约 5.2%;当运行六个集群时,性能下降约 9.7%,反映出随着并发集群增多,系统整体吞吐能力有所下降。
6、总结
1、基准值定义
基准值取自单个与两个集群同时运行的平均 tpmC,用来表示系统在无明显干扰条件下的正常吞吐能力。
2、性能影响趋势
单集群和双集群运行时性能基本一致,tpmC 与基准值偏离较小,说明在这些条件下系统吞吐能力整体稳定。
当并发集群数量增多到四个时,系统的 tpmC 出现约 5.2% 的下降。
当并发集群达到 六个 时,tpmC 下降约 9.7%,表明随着并发数量增加,系统整体负载加剧导致资源竞争加剧,从而影响性能。
3、性能影响
这些结果表明,在基础环境下 TPCC 吞吐性能(tpmC)相对稳定,但当多个集群同时运行时,硬件资源(如 CPU/IO)或系统内部调度瓶颈可能逐渐显现,从而产生一定程度的性能递减,在容忍范围之内。
综上所述,使用TEM的云化功能可以直接基于物理资源指标来定义隔离策略,提供更直观、更物理资源导向的隔离能力。