

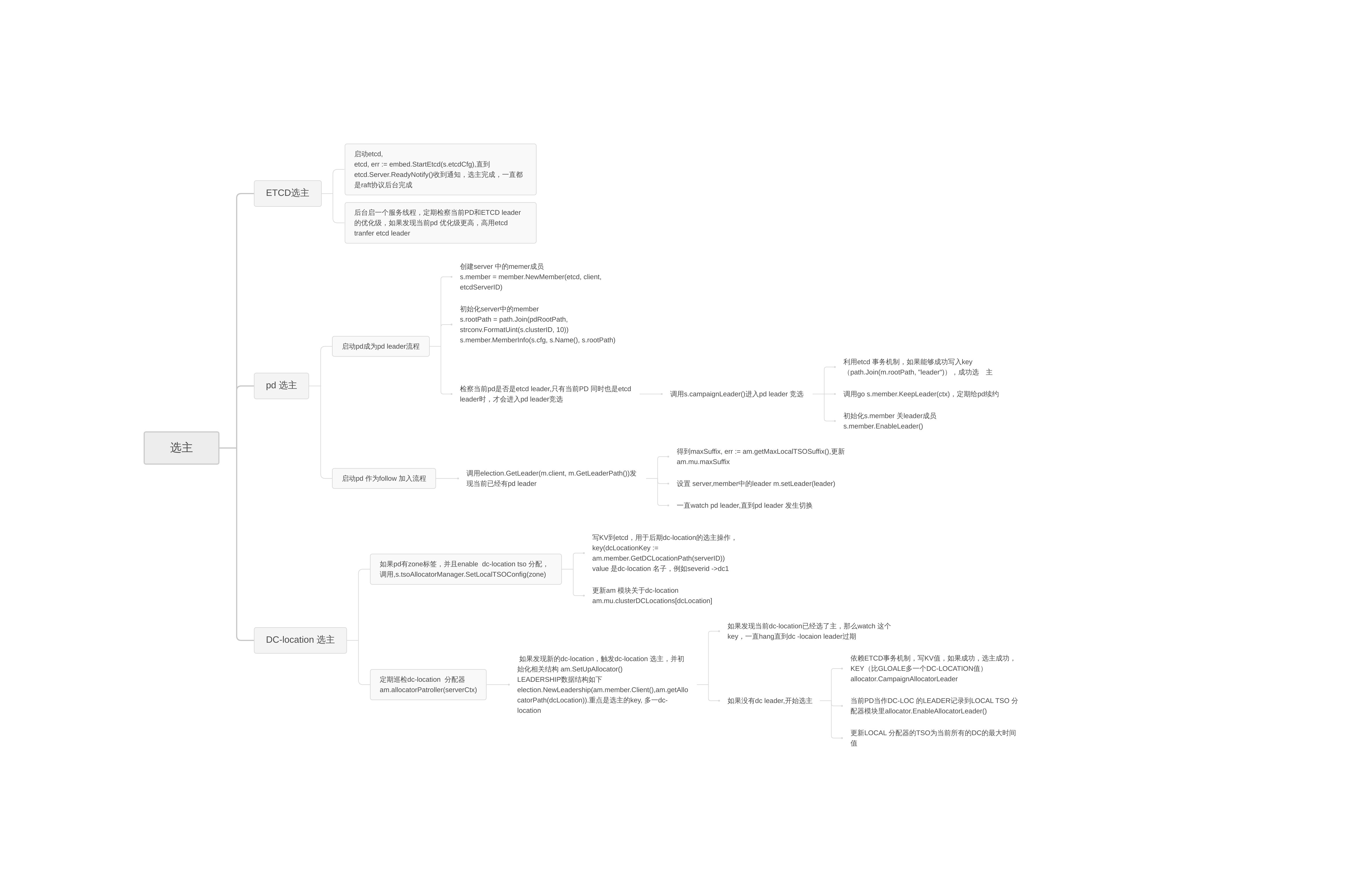
PD涉及三类选主
1.ETCD选主
启动etcd, 调用embed.StartEtcd(s.etcdCfg),
etcd, err := embed.StartEtcd(s.etcdCfg)
等待etcd选主完成,通过等待channel (etcd.Server.ReadyNotify()),这个channel收到通知表明etcd cluster 完成选主,可以对外提供服务
select {
// Wait etcd until it is ready to use
case <-etcd.Server.ReadyNotify():
case <-newCtx.Done():
return errs.ErrCancelStartEtcd.FastGenByArgs()
}
后台启动线程,定期(时间间隔s.cfg.LeaderPriorityCheckInterval)检察当前PD和ETCD leader的优化级,如果发现当前pd 优化级更高,调用etcd tranfer leader,切换etcd leader为当前pd
func (s *Server) etcdLeaderLoop() {
for {
select {
case <-time.After(s.cfg.LeaderPriorityCheckInterval.Duration):
s.member.CheckPriority(ctx)
case <-ctx.Done():
log.Info("server is closed, exit etcd leader loop")
return
}
}
}
// CheckPriority checks whether the etcd leader should be moved according to the priority.
func (m *Member) CheckPriority(ctx context.Context) {
etcdLeader := m.GetEtcdLeader()
myPriority, err := m.GetMemberLeaderPriority(m.ID())
leaderPriority, err := m.GetMemberLeaderPriority(etcdLeader)
if myPriority > leaderPriority {
err := m.MoveEtcdLeader(ctx, etcdLeader, m.ID())
}
}
2.PD leader选主
初始化pd server 中member 成员,这个对象用于pd leader选主
func (s *Server) startServer(ctx context.Context) error {
s.member = member.NewMember(etcd, client, etcdServerID)
}
func (s *Server) startServer(ctx context.Context) error {
s.member.MemberInfo(s.cfg, s.Name(), s.rootPath)
s.member.SetMemberDeployPath(s.member.ID())
s.member.SetMemberBinaryVersion(s.member.ID(), versioninfo.PDReleaseVersion)
s.member.SetMemberGitHash(s.member.ID(), versioninfo.PDGitHash)
}
启动后台服务线程s.leaderLoop(),用于pd 的选主
1.检察当前是否有leader,如果已经存在leader,这个pd 不用参与选主,只要watch 当前的leader,直到leader 过期补删除
2.如果leader过期,或者当前没有pd leader,调用s.campaignLeader()启动选主
2.1 调用s.member.CampaignLeader 开始选主,原理很简单,利用etcd的事务操作,如果能够写入特定的key value,就表示写主成功
2.2 调用后台服务线程,不停的续约PD leader,保证leader一直有效
2.3 因为很多组件依赖pd 的主,所以当PD选主成功以后,会启动很多其它组件的设置工作(tso组件,id 分配组件,重新加载配置参数)
func (s *Server) leaderLoop() {
defer logutil.LogPanic()
defer s.serverLoopWg.Done()
for {
leader, rev, checkAgain := s.member.CheckLeader()
if checkAgain {
continue
}
if leader != nil {
err := s.reloadConfigFromKV()
log.Info("start to watch pd leader", zap.Stringer("pd-leader", leader))
// WatchLeader will keep looping and never return unless the PD leader has changed.
s.member.WatchLeader(s.serverLoopCtx, leader, rev)
syncer.StopSyncWithLeader()
log.Info("pd leader has changed, try to re-campaign a pd leader")
}
// To make sure the etcd leader and PD leader are on the same server.
etcdLeader := s.member.GetEtcdLeader()
if etcdLeader != s.member.ID() {
time.Sleep(200 * time.Millisecond)
continue
}
s.campaignLeader()
}
}
func (s *Server) campaignLeader() {
log.Info(“start to campaign pd leader”, zap.String(“campaign-pd-leader-name”, s.Name()))
if err := s.member.CampaignLeader(s.cfg.LeaderLease); err != nil {
}
// maintain the PD leader
go s.member.KeepLeader(ctx)
log.Info("campaign pd leader ok", zap.String("campaign-pd-leader-name", s.Name()))
alllocator, err := s.tsoAllocatorManager.GetAllocator(tso.GlobalDCLocation)
if err != nil {
log.Error("failed to get the global TSO allocator", errs.ZapError(err))
return
}
log.Info("initializing the global TSO allocator")
if err := alllocator.Initialize(0); err != nil {
log.Error("failed to initialize the global TSO allocator", errs.ZapError(err))
return
}
defer s.tsoAllocatorManager.ResetAllocatorGroup(tso.GlobalDCLocation)
// Check the cluster dc-location after the PD leader is elected
go s.tsoAllocatorManager.ClusterDCLocationChecker()
if err := s.reloadConfigFromKV(); err != nil {
log.Error("failed to reload configuration", errs.ZapError(err))
return
}
// Try to create raft cluster.
if err := s.createRaftCluster(); err != nil {
log.Error("failed to create raft cluster", errs.ZapError(err))
return
}
defer s.stopRaftCluster()
if err := s.persistOptions.LoadTTLFromEtcd(s.ctx, s.client); err != nil {
return
}
if err := s.idAllocator.Rebase(); err != nil {
return
}
s.member.EnableLeader()
}
3.TSO 分配器选主,tso分为两类,
3.1 global tso分配器,
用于保证TSO全局线性增加,它的leader 使用的是pd leader,从下面的代码就能够知道global的leader就是使用的是pd 的leader(s.member.GetLeadership())
s.tsoAllocatorManager.SetUpAllocator(ctx, tso.GlobalDCLocation, s.member.GetLeadership())
3.2 dc tso分配器 ,
用于保证每上DC内的TSO分配线性增加,每个dc内的pd会选出一个主.
启动后台服务线程,定期(时间间隔patrolStep)调am.allocatorPatroller(serverCtx)
allocatorPatroller函数检察是否有新的dc,如果有的话,创建这个DC对应的tso分配器,并创建新的leadership用于dc 内的leader选主。选主调用函数allocatorLeaderLoop,过程和pd选主类似
// Check if we have any new dc-location configured, if yes,
// then set up the corresponding local allocator.
func (am *AllocatorManager) allocatorPatroller(serverCtx context.Context) {
// Collect all dc-locations
dcLocations := am.GetClusterDCLocations()
// Get all Local TSO Allocators
allocatorGroups := am.getAllocatorGroups(FilterDCLocation(GlobalDCLocation))
// Set up the new one
for dcLocation := range dcLocations {
if slice.NoneOf(allocatorGroups, func(i int) bool {
return allocatorGroups[i].dcLocation == dcLocation
}) {
am.SetUpAllocator(serverCtx, dcLocation, election.NewLeadership(
am.member.Client(),
am.getAllocatorPath(dcLocation),
fmt.Sprintf("%s local allocator leader election", dcLocation),
))
}
}
}
allocatorLeaderLoop分析:
1.如果发现当前dc已经有dc tso leader,那么watch这个leader,直到leader 无效
2.如果发现etcd保存有nextleader,表明之前有tranfer leader的请求,如果当前pd不等于nextleader ,那么本次不参与pd选主
3.调用campaignAllocatorLeader进行选主,过程和pd leader选主类似,也是利用etcd的事务机制,写leader key-value,成功表明选主完成
func (am *AllocatorManager) allocatorLeaderLoop(ctx context.Context, allocator *LocalTSOAllocator) {
defer log.Info(“server is closed, return local tso allocator leader loop”,
zap.String(“dc-location”, allocator.GetDCLocation()),
zap.String(“local-tso-allocator-name”, am.member.Member().Name))
for {
select {
case <-ctx.Done():
return
default:
}
// Check whether the Local TSO Allocator has the leader already
allocatorLeader, rev, checkAgain := allocator.CheckAllocatorLeader()
if checkAgain {
continue
}
if allocatorLeader != nil {
log.Info("start to watch allocator leader",
zap.Stringer(fmt.Sprintf("%s-allocator-leader", allocator.GetDCLocation()), allocatorLeader),
zap.String("local-tso-allocator-name", am.member.Member().Name))
// WatchAllocatorLeader will keep looping and never return unless the Local TSO Allocator leader has changed.
allocator.WatchAllocatorLeader(ctx, allocatorLeader, rev)
log.Info("local tso allocator leader has changed, try to re-campaign a local tso allocator leader",
zap.String("dc-location", allocator.GetDCLocation()))
}
// Check the next-leader key
nextLeader, err := am.getNextLeaderID(allocator.GetDCLocation())
if err != nil {
log.Error("get next leader from etcd failed",
zap.String("dc-location", allocator.GetDCLocation()),
errs.ZapError(err))
time.Sleep(200 * time.Millisecond)
continue
}
isNextLeader := false
if nextLeader != 0 {
if nextLeader != am.member.ID() {
log.Info("skip campaigning of the local tso allocator leader and check later",
zap.String("server-name", am.member.Member().Name),
zap.Uint64("server-id", am.member.ID()),
zap.Uint64("next-leader-id", nextLeader))
time.Sleep(200 * time.Millisecond)
continue
}
isNextLeader = true
}
// Make sure the leader is aware of this new dc-location in order to make the
// Global TSO synchronization can cover up this dc-location.
ok, dcLocationInfo, err := am.getDCLocationInfoFromLeader(ctx, allocator.GetDCLocation())
if err != nil {
log.Error("get dc-location info from pd leader failed",
zap.String("dc-location", allocator.GetDCLocation()),
errs.ZapError(err))
// PD leader hasn't been elected out, wait for the campaign
if !longSleep(ctx, time.Second) {
return
}
continue
}
if !ok || dcLocationInfo.Suffix <= 0 {
log.Warn("pd leader is not aware of dc-location during allocatorLeaderLoop, wait next round",
zap.String("dc-location", allocator.GetDCLocation()),
zap.Any("dc-location-info", dcLocationInfo),
zap.String("wait-duration", checkStep.String()))
// Because the checkStep is long, we use select here to check whether the ctx is done
// to prevent the leak of goroutine.
if !longSleep(ctx, checkStep) {
return
}
continue
}
am.campaignAllocatorLeader(ctx, allocator, dcLocationInfo, isNextLeader)
}
}