

TiFlash运维漫谈
2020-10-25 刘春雷
1、前言
自TiDB 4.0版本问世之前,TiFlash就被大家高度关注。TiFlash 是什么?他能做什么?他如何使用?他运维起来麻烦么?他有什么坑?他能真正解决困扰MySQL DBA的 分析型业务无法支持 的问题么?本篇文章更偏向实际使用、运维体验,原理请移步官网~
58这边,自 4.0.0-rc.2 版本就开始调研TiFlash,到目前,大约使用 5个月 左右了, 7套 线上集群在使用TiFlash解决分析型SQL的效率问题。
2、TiFlash简介
TiFlash 是 TiDB HTAP 形态的关键组件,它是 TiKV 的列存扩展,在提供了良好的隔离性的同时,也兼顾了强一致性。列存副本通过 Raft Learner 协议异步复制,但是在读取的时候通过 Raft 校对索引配合 MVCC 的方式获得 Snapshot Isolation 的一致性隔离级别。这个架构很好地解决了 HTAP 场景的隔离性以及列存同步的问题。
整体架构
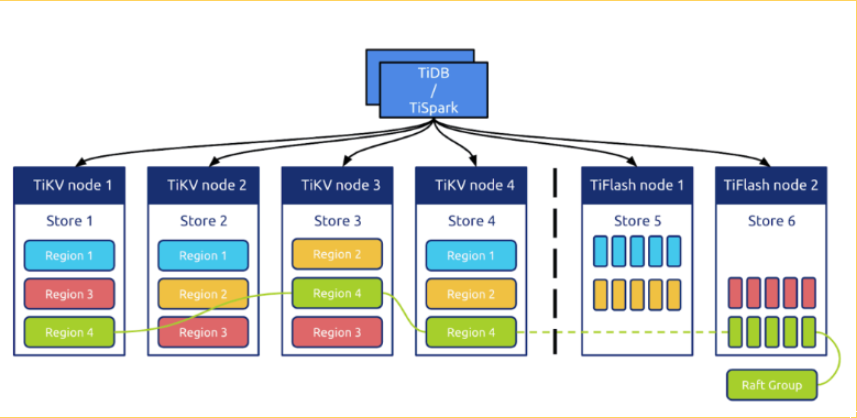
3、部署及使用
推荐:
使用更好性能的磁盘、大内存,多核CPU的机器进行部署,官方:32 VCore 64 GB 2TB (nvme ssd) * 1 ,58这边大致机器为 40核、128G内存、SSD RAID5 或闪存卡机器。
3.1、部署流程
使用tiup工具部署,分为初始化部署、已经存在集群部署TiFlash,区别不大,都是要写好yaml文件即可。
【1、集群配置】:
需要将配置模板中 replication.enable-placement-rules 设置为 true,以开启 PD 的 Placement Rules功能。,或使用pd-ctl,执行 config set enable-placement-rules true 。或者tiup也支持,tiup ctl pd -u
【2、配置文件】:
tiflash_servers:
- host: 10.0.1.11
data_dir: /tidb-data/tiflash-9000
deploy_dir: /tidb-deploy/tiflash-9000
ssh_port: 22
tcp_port: 9000
http_port: 8123
flash_service_port: 3930
flash_proxy_port: 20170
flash_proxy_status_port: 20292
metrics_port: 8234
deploy_dir: /tidb-deploy/tiflash-9000
config:
logger.level: “info”
learner_config:
log-level: “info” - host: 10.0.1.12
- host: 10.0.1.13
【3、执行部署】
新部署集群包括TiFlash节点:
tiup cluster deploy tidb-test v4.0.6 ./topology.yaml
扩容TiFlash节点:
tiup cluster scale-out scale-out.yaml
【4、检查节点状态】
tiup cluster display cluster-name
3.2、使用
【表添加至TiFlash】:
使用上很简单,只需要知道将哪些表同时放到列存TiFlash里面,执行个SQL就行了~
- ALTER TABLE table_name SET TIFLASH REPLICA count
- count 表示副本数,0 表示删除
【查看】:
SELECT * FROM information_schema.tiflash_replica WHERE TABLE_SCHEMA = ‘<db_name>’ and TABLE_NAME = ‘<table_name>’;
- AVAILABLE 字段表示该表的 TiFlash 副本是否可用。1 代表可用,0 代表不可用。副本状态为可用之后就不再改变,如果通过 DDL 命令修改副本数则会重新计算同步进度。
- PROGRESS 字段代表同步进度,在 0.0~1.0 之间,1 代表至少 1 个副本已经完成同步。

【TiDB读取使用】:
TiDB 提供三种读取 TiFlash 副本的方式。如果添加了 TiFlash 副本,而没有做任何 engine 的配置,则默认使用 CBO 方式。 会话级别,即 SESSION 级别

【如何确认使用】:
explain 查看SQL执行计划,看task字段里面是否有tiflash,有 表示该任务会发送至 TiFlash 进行处理 。例如:

【engine隔离】:
适用于某些特殊场景:
- 明确使用其他engine效率比较好,如使用TiKV效率更好
- 或者进行影响隔离,例如某些大批量数据的查询,可以单独走TiFlash,减少对线上读写影响
set session tidb_isolation_read_engines = “逗号分隔的 engine list”;
【支持计算下推】:
TiFlash 支持谓词、聚合下推计算以及表连接,下推的计算可以帮助 TiDB 进行分布式加速。暂不支持的计算类型是 Full Outer Join 和 DISTINCT COUNT,会在后续版本逐步优化
set session tidb_opt_broadcast_join=1
其他下推优化 :
set @@tidb_opt_agg_push_down=1;
set @@tidb_opt_distinct_agg_push_down=1;
4、使用经验
4.1、元信息部分
因TiDB多端口的特性,混合部署的话,推荐集群间端口间隔的多一些,例如间隔50个端口,这样会减少端口冲突的情况。且TiFlash 想比较其他角色,端口比较多,6个左右。这样就需要单独一张角色表,记录TiFlash的基本信息,与TiDB其他实例表相关联。
4.2、有哪些坑
-
问题1 : 对资源消耗很大,比tikv节点大, 某集群部署tiflash后,添加写入特别频繁的表至TiFlash,且几乎没有读TiFlash的情况,TiFlash 节点的CPU使用率100%,推荐大家 使用多核CPU的机器 。
-
问题2:无法限制内存 , 这个写入特别频繁的表的tiflash异常重启多次,排查为内存吃满oom了,此机器的内存128G,直接使用完oom…启动占用大内存的问题,已经提给官方,官方在修复 。
【排查系统日志如下】
ep 28 16:35:42 10.0.0.1 kernel: [34135946.096974] Out of memory: Kill process 506925 (tiflash) score 896 or sacrifice child
【监控情况如下】
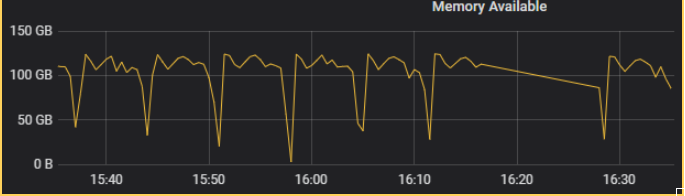
【内存使用情况如下】

【tiup状态】
因重启检查超时,TiUP cluster display结果显示变成Down,或者Disconnected

-
问题3 : 修改pd节点 ,切换后,TiFlash的 PD信息不同步 …不同步…需要手动修改TiFlash的配置tiflash.toml
日志报错如下:
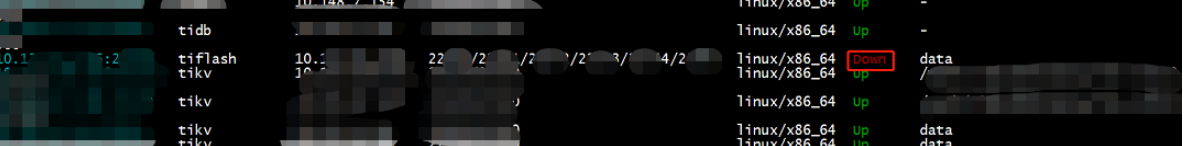
需要改tiflash.toml里面pd信息,改成新的
[raft]
pd_addr = “10.0.0.1:100,10.0.0.2:100,10.0.0.3:100”
- 问题4: 不能正常开启TiFlash 的话,也不能正常的scal-in下线,需要手动清除同步规则,及强制从 pd 删除这个节点信息,参考wiki:


使用 TiUP 扩容缩容 TiDB 集群
PingCAP Docs
使用 TiUP 扩容缩容 TiDB 集群
PingCAP Docs
5、对比ClickHouse
面对如火如荼的ClickHouse,TiFlash又性能如何呢?我们进行了如下测试。
5.1、性能对比
【机器信息】
内存: 192G
CPU: 20*2 Intel® Xeon® Silver 4114 CPU @ 2.20GHz
磁盘 :3*1.8T SSD RAID5
部署 :单机单实例部署
版本: ClickHouse版本 20.3.8.53 ,TiFlash: 4.0.0-rc
【 ClickHouse查询如下 】:
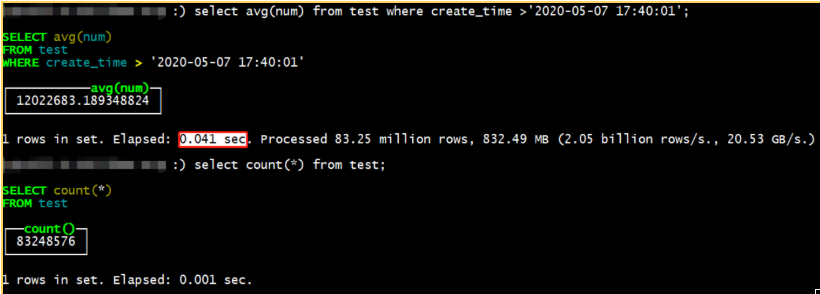
【汇总对比如下】:

【差异原因】:
tiflash 因为需要支持 update,所以需要额外读取三列:handle (int64), version(uint64), del_mark(uint8)
clickHouse 只需要 scan,但是 tiflash 需要把数据做一次全局排序 + mvcc 过滤,这些是固定成本。
5.2、场景对比
clickhouse目前大致的使用场景为:
- 作为MySQL的从库使用,这样受限于MySQL的集群大小及读写效率的考虑,表可能不大,百G左右
- 独立部署集群,大小不限制,专注于高效分析
TiDB 目前在58主要为解决MySQL的痛点问题:例如单表超100G,推荐迁移至TiDB。或者新业务,体量大,流量高的场景。
TiFlash可以依托TiDB使用,使用方便,与TiKV一起,可以支持更多的场景,所以使用的就更广泛。
大致场景对比如下:

6、TiFlash的日常使用心得
对于58的50多套集群,到底哪套集群?哪些表?哪些SQL需要使用TiFlash来优化呢?这是一个很大的难题!真的很大~
- 首先需要DBA了解所有集群的业务,了解所有集群的常见慢SQL、高频SQL情况,想想50套集群、想想每天大致50多亿次访问的TiDB业务,这对于DBA就要求很高了。
- 因为磁盘的限制,不能所有的表都添加至TiFlash里面,只能找在查询上可以使用TiFlash优化的表,这点很难!需要逐个测试,逐个…
- 58的集群里面,有数仓业务,有报表业务,有信安的实时写入与分析业务。这几种是大致可以确定使用TiFlash优化的,然后我们需要详细分析测试…
- 然后我们要查看这几套集群的慢SQL、高频SQL,然后将表添加至TiFlash里面,逐条explain 来查看执行计划,然后确定哪些是可以走TiFlash的,这个同步过程也很漫长,表越大越长,有同步1周多的…这个测试的周期就被拉的很长~很长~
- 然鹅现实有时候很骨感,很多SQL,explain查看执行计划是不能被TiFlash优化的,有些联合索引添加的很好,查询完全匹配的时候,就直接走TiKV的索引扫描了,只有很少部分的SQL可以通过TiFlash优化…
- 监控上,查看TiFlash-Summary的Request QPS监控图,也是不尽人意,很少的SQL。
- 目前上的几套集群里面,TiFlash优化好的SQL有一些,例如原SQL 19.9s,优化后0.48s,业务非常开心~
- 当然线上还是有很多的SQL可以通过TiFlash优化的,只是这个需要DBA耗费很大的人力去测试、确定
总之:
-
TiFlash能很好的优化一些分析型的SQL
-
TiFlash能很好的使用,需要DBA付出很大的精力,较长的时间~
-
TiFlash还存在很多可以优化的地方,例如
- 添加内存限制
- 解决TiFlash重启慢的问题
- TiFlash机器资源使用过高的问题
- 支持更多的查询情况优化
- SQL能否给出智能的建议:使用TiFlash优化~,这样来减少DBA的工作量
- 性能上的提升
希望TiFlash 使用的越来越简单,问题越来越少,效率越来越高~