

序
TiDB 作为一款分布式关系型数据库,很多用户在使用时都会很自然地将其与传统关系型数据库在隔离级别、锁机制、事务模型方面作对比。本文将分别对 TiDB 与传统数据库 (以MySQL 为例)进行解读,内容共分为两部分,上篇介绍 MySQL 相关实现原理,下篇介绍 TiDB 相关实现原理及与 MySQL 的对比。
一、隔离级别
(一)ISO 定义的隔离级别
-
隔离级别的目的
- 定义并发事务之间互相影响的程度,两个并发事务之间能看到对方哪些数据。
-
ISO定义的数据库隔离级别
- Read uncommitted(未提交读)
- Read committed(提交读,RC)
- Repeatable read(可重复读,RR)
- Serializable(全串行)
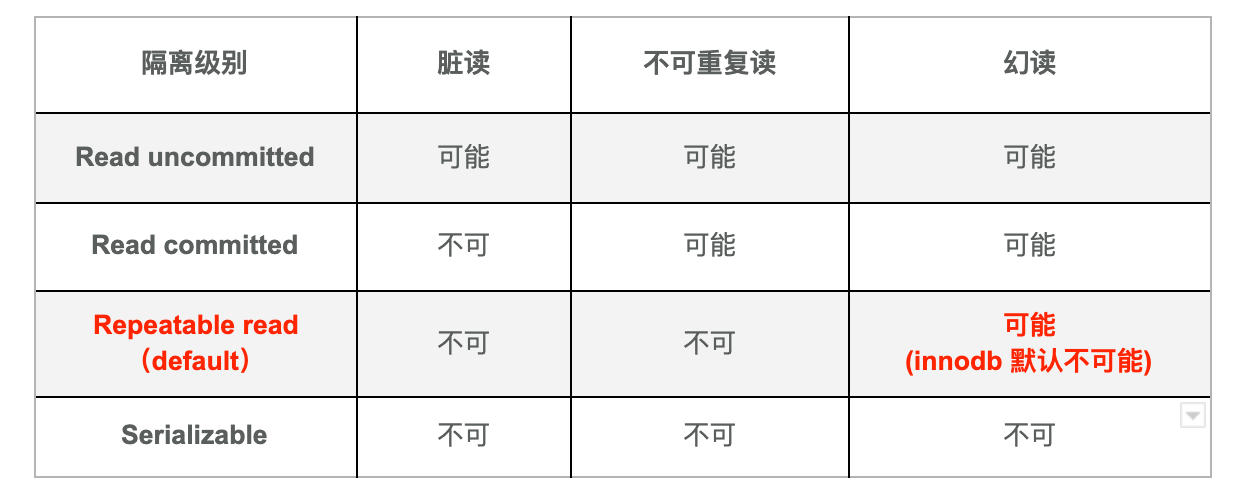
(二)不同隔离级别区分现象(P1-P3)
-
脏读
- 事务 A 修改了 data,但并未提交
- 与此同时事务 B 读到了 data 的修改,称为脏读。
-
不可重复读
- 在事务 A 的两次读 data 之间,事务 B 访问了 data,并修改了 data,并进行了提交。
- 如果事务 A 的前后两次读由于事务 B 的修改,导致的不一致称为不可重复读。
-
幻读
- 与不可重复读的主要差别在于,幻读是涉及插入操作,而不可重复读主要是更新。
- 事务 A 读某一范围数据并进行了修改,与此同时事务 B 在该范围内新增一行 insert_data。
- 事务 A 可重复读,能读到原数据,但提交时发现有之前未查到的数据 insert_data。
(三)隔离级别与现象对应关系
(四)扩展问题
前面把有关隔离级别的一些基本概念进行快速解读后,现在回归到 MySQL,有两个问题:
问题一:为什么在 Innodb 引擎下,默认的隔离级别不是 RC?
- 大家知道 MySQL 是基于计算层产生的 Binlog 进行数据复制,而 MySQL Binlog 有两种主要的格式,其中一种是 statement,为了保证 statement-based binary logging(基于提交去同步主从)数据保持一致。
- 在 RC 隔离级别以及 statement 下,主从同步会导致问题。具体可参考:http://dev.mysql.com/doc/refman/5.7/en/binary-log-setting.html
举例:
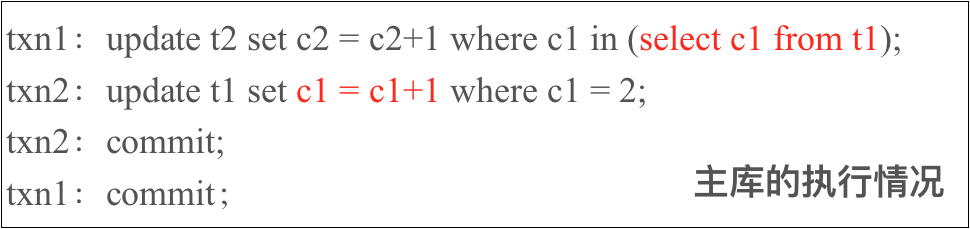

因为 Binlog 回放是和事务提交顺序一致,显然在这种情况下,会导致主从数据不一致。
问题二:为什么 Innodb 引擎的 RR 在默认情况不会有幻读?
- 默认情况下禁用了 locks_unsafe_for_binlog(即 lock_safe_for_binlog)
- Innodb 引入了范围锁,在扫描时使用的 next-key (范围锁的一种) locks 锁住了插入,可以保证避免幻读。
回到上面的例子,txn2 提交的事务会因为 txn1 提交的事务上的 next-key lock 而锁住提交,因此不会发生幻读。从库的执行是 statement-based binlog, 根据提交顺序,也不会有问题。

二、MySQL 锁机制
(一)锁机制知识图

(二)锁和隔离级别的关系
隔离级别的实现主要通过 MVCC + 锁
- 可重复读:事务一致性读(trx consistent read)和记录锁(rec lock)
- 防止幻读:范围锁
(三)MySQL 锁基本属性
-
锁的模式
- LOCK_S(共享锁)
- LOCK_X(排它锁)
-
加锁范围
-
RECORD LOCK(记录锁)
-
RANGE LOCK(区间锁),也是加在记录上,由锁类型区分
- GAP LOCK
- NEXT LOCK,包含RECORD LOCK
- INSERT INTENTION LOCK(插入意向锁)
-
-
范围锁分为 gap lock 和 next-key lock:
- gap lock 为左右开区间
- next-key lock 为下界开,上界闭
-
举例说明:
- 一个索引的行有1,2,3,4
- 可能的 gap lock 有(1,2),(2,3)等
- 可能的 next-key lock 包括(-无穷,1],(1,2],(3,4] 等
(四)MySQL 加锁逻辑
正确理解读操作
-
读操作分 snapshot read 和 current read
-
snapshot read(快照读)
- 最普通的 select 操作(不包括 for update 等)
- 举例:select from table
-
current read(也叫 lock read)
-
删除、更新等必然涉及读,预先读进行检查。
-
举例:
- select from table lock in share mode;
- select rom table for update;
- delete/update table;
- delete/update from in(select from table)等。
-
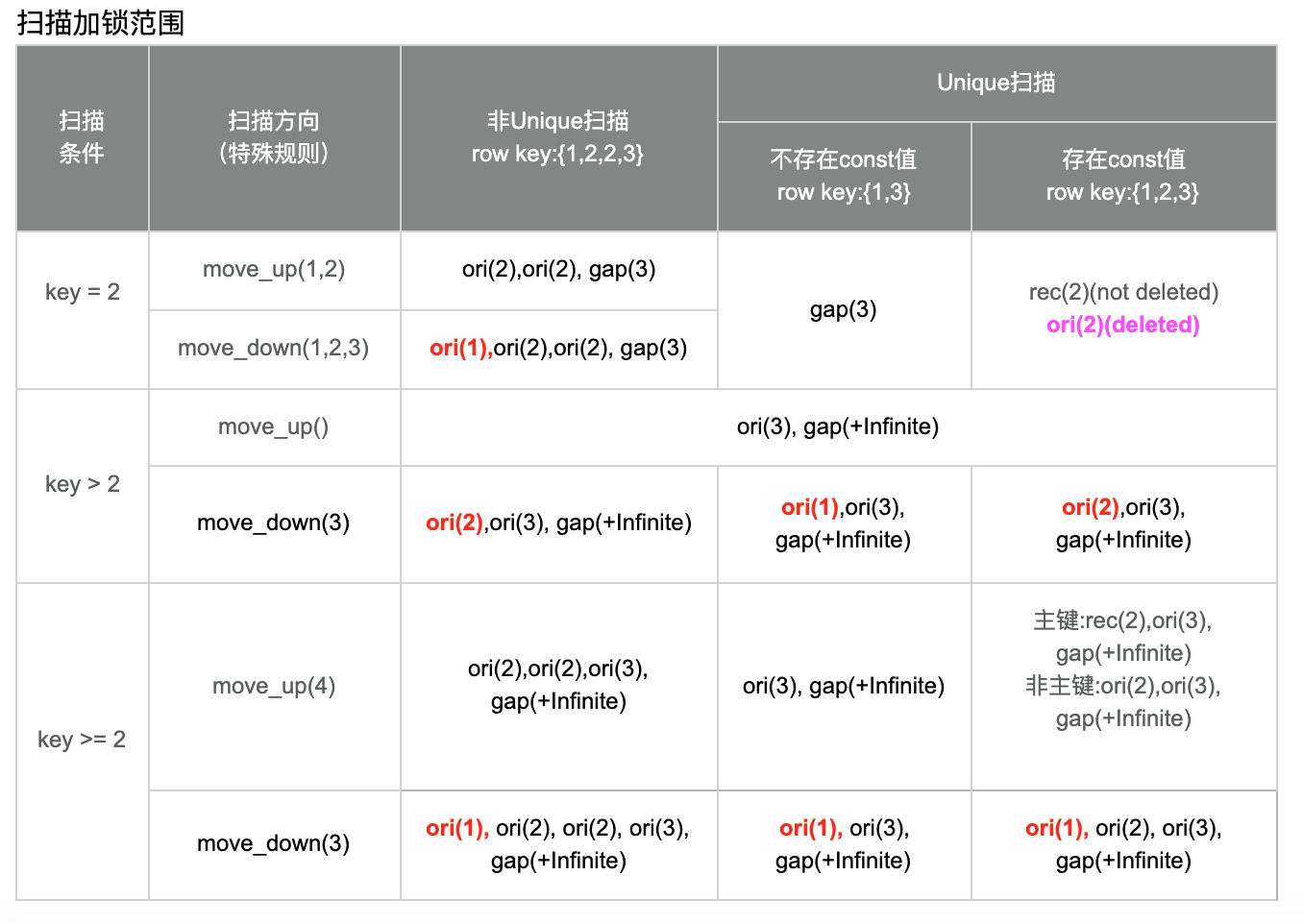
扫描时的加锁类型

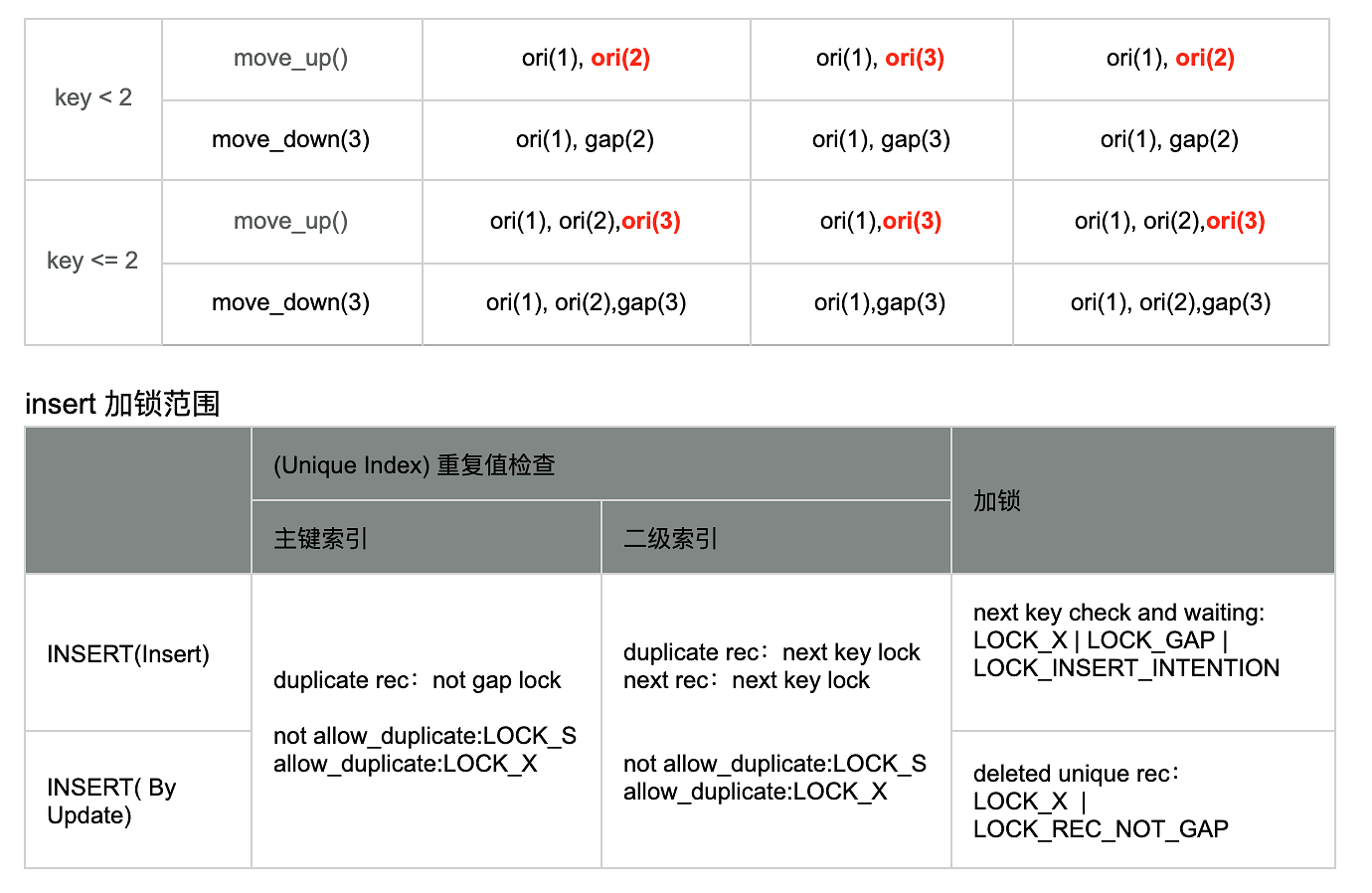
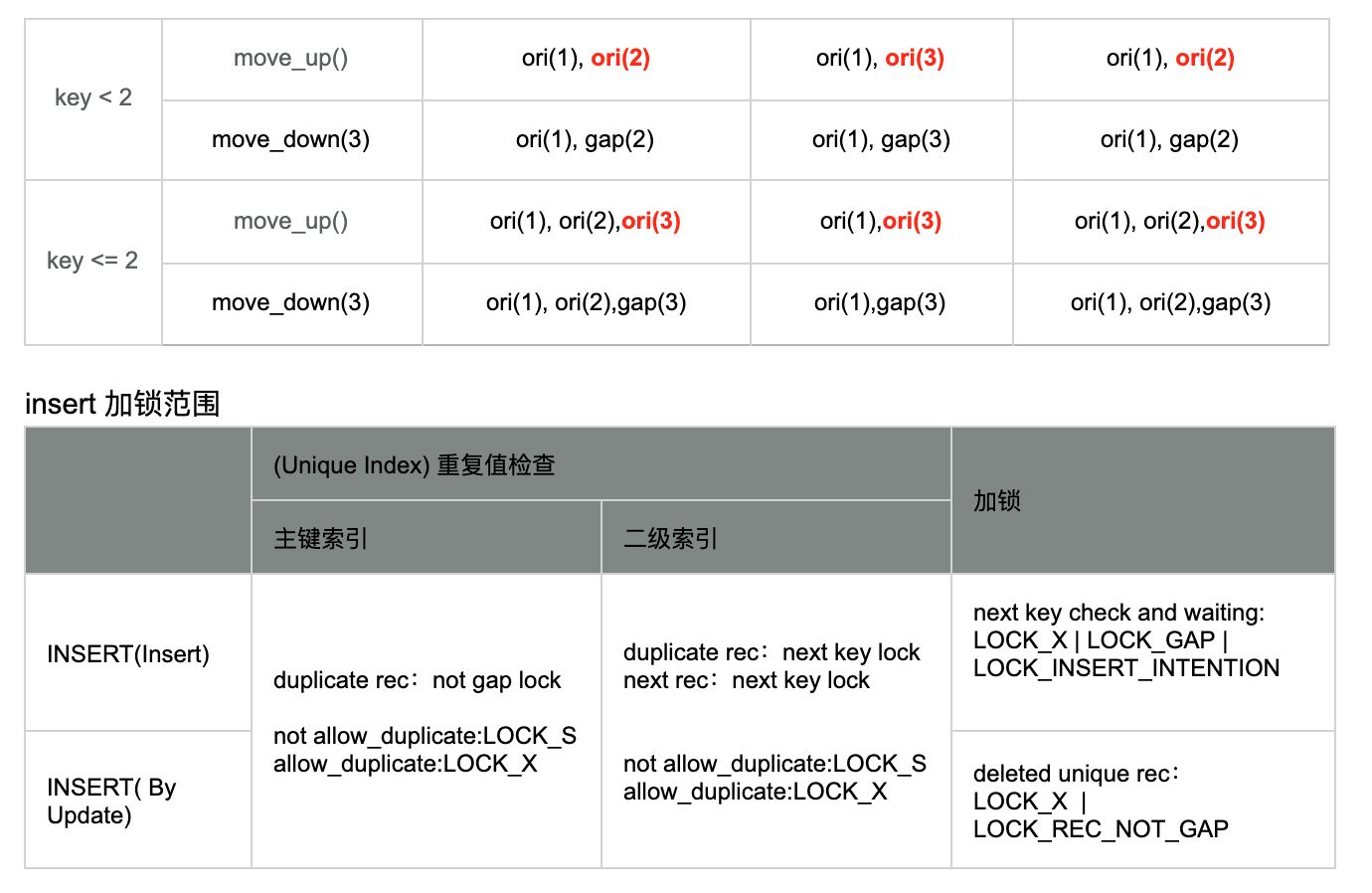
插入加锁类型

扫描加锁范围影响因素
-
索引类型:Clustered Index,Unique Index,普通 Index
-
扫描类型:Unique 扫描和非 Unique 扫描
-
Unique 扫描
- (unique index || primary key)
- && search field number == unique key number
- && (clustered index || search field not contain null)
- Example :unique index(c1, c2):
-
c1 = 2 and c2 =2 ===> unique 扫描
c1=2 ===> 不是 unique 扫描
c1=2 and c2 is null ===> 不是 unique 扫描
- 范围条件:L,LE,EQ,GE,G
- 扫描顺序:前向、后向
扫描加锁范围规则一
-
默认情形:所有满足条件的 rec,都加 next key lock,第一个不满足条件的 rec,也加 next key lock
-
举例
- 对于记录1,2,3,5,7
- 扫描数据2,3
- 则加的锁为(1,2],(2,3],(3,5]
扫描加锁范围规则二
下述规则,可以理解为在默认条件下的优化,提高了next-key lock下的并发性能
-
等值条件扫描
- 规则1:unique 扫描,且满足条件的 rec 不是 deleted,则该满足条件的 rec 加 not gap 锁
- 规则2:非 unique 扫描的第一个不满足条件行加 gap lock
-
规则3:带条件的后向扫描,则第一个满足条件的下一个 rec 加 gap lock
-
规则4:primary key 的前向 GE 条件且第一个满足条件的 rec 等于 search_tuple,则该 rec 加 not gap lock
-
规则5:Supremum record 永远加 gap lock,Infimum record 永远不加锁
锁模式冲突规则
| LOCK_S | LOCK_X | |
|---|---|---|
| LOCK_S | FALSE | TRUE |
| LOCK_X | TRUE | TRUE |
锁范围冲突规则
需要注意的是插入意向锁和其他锁均不冲突

插入意向锁(针对性锁优化)
- 插入时如果检查 INSERT INTENTION LOCK 不冲突时不加锁
- 隐式锁优化:插入、更新、删除行时,如果检查不冲突时也不加锁,必要时在下次扫描或者更新加锁时根据最后更新事务号将隐式锁转化为显式锁
三、总结
- Innodb 通过引入范围锁来解决了幻读的问题。
- 所有的锁信息都体现在 rec 上。
- 引入插入意向锁来对插入进行优化,插入意向锁和其他锁均不冲突。
- gap lock 之间不冲突。
- 扫描加锁范围规则一是默认规则,针对 unique、后向、Supremum 提供了一些特殊规则,可以理解为优化。