

1 月 22 日的新品分享会上,平凯数据库发布了“新一代存算分离2.0内核”。
新一代内核有什么亮点?什么时候能用上?等问题受到大家的关注。
本期平凯数据库(TiDB 企业版)新品分享会核心问答,通过九问九答,为您解读内核是如何思考设计的。
Q1:为什么要推出新一代内核?核心考虑是什么?
为了构建面向未来的“确定性”数据底座。
业务负载日益复杂,AI Agent 带来的极端不确定性(如突发脉冲流量、多模态数据需求)也只是一个开始。而传统的数据库架构通常基于负载可预测的假设,难以应对这种动态变化。推出新一代内核,旨在将数据库的稳定性和灵活性提升到更高维度,确保无论未来负载如何波动,数据底座始终“稳”且“快”。

Q2:新内核如何实现“极致的稳定与灵活”?核心设计是什么?
通过“深度解耦”与“统一抽象”,实现动态负载的彻底隔离。
极致稳定(深度解耦): 将在线交易、后台任务(如整理、备份)、AI 引擎等彻底拆解。这意味着后台任务与核心业务在 CPU 和 IO 层面彻底物理隔离,即便负载动态变化,也能确保核心业务 P99 延迟“零抖动” 。
极致灵活(统一抽象): 构建了 “统一存储抽象层” 。它屏蔽了底层存储的差异,让上层不同的计算引擎可以根据实时业务需求,独立地进行弹性伸缩和调度 。

Q3:如何理解“存算分离 2.0”?它与 1.0 有什么区别?
更彻底的解耦和隔离,实现了算算分离、存存分离。
存算分离 2.0 深入到了进程内部,将在线任务、离线任务和 AI 引擎进行了彻底解耦。它们不仅资源隔离,还能独立扩缩容。这意味着可以在同一个集群内运行多种负载,而互不干扰。

Q4:新一代内核在性能上有哪些实质提升?
新内核更稳定、更快速、更高效。读写性能提升 50%。
前面讲到深度解耦带来极致稳定,确保核心业务 P99 延迟“零抖动” 。此外,我们在工程层面也进行了大量优化,包括减少日志写入量、降低并发冲突等。这使得新内核不仅更灵活,在基础的吞吐能力上也更加强悍。

Q5:新一代内核对 AI 的支持有哪些改进?
在内核层面实现“原生多模,All in One”
原生引擎支持向量(内置 Embedding)与全文检索。这意味着你可以在一套系统内实现 SQL + Vector + Full-Text 的实时混合检索,既保证了极致性能,又无需维护复杂的异构技术栈。
但这远不止于此。我们将它定义为“AI 就绪”且“Agent 友好”的统一数据底座。
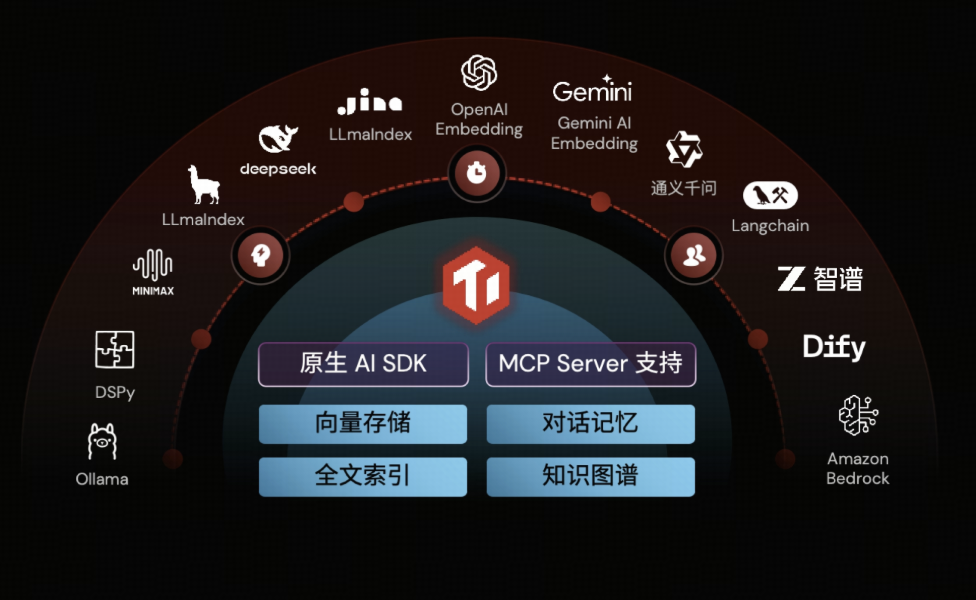
- 工具层,提供了TiDB AI SDK 和独立部署的 MCP Server。
- 生态层:支持各种主流开发框架。无论是 RAG 流程编排还是 Agent 开发,都能以极低门槛直接复用现有生态。
Q6:新一代内核在“云服务”和“私有化部署”的价值点有何异同?
都是存算分离 2.0 内核,均享有确定性的稳定。在此基础上,根据基础设施的差异,释放出不同维度的价值:
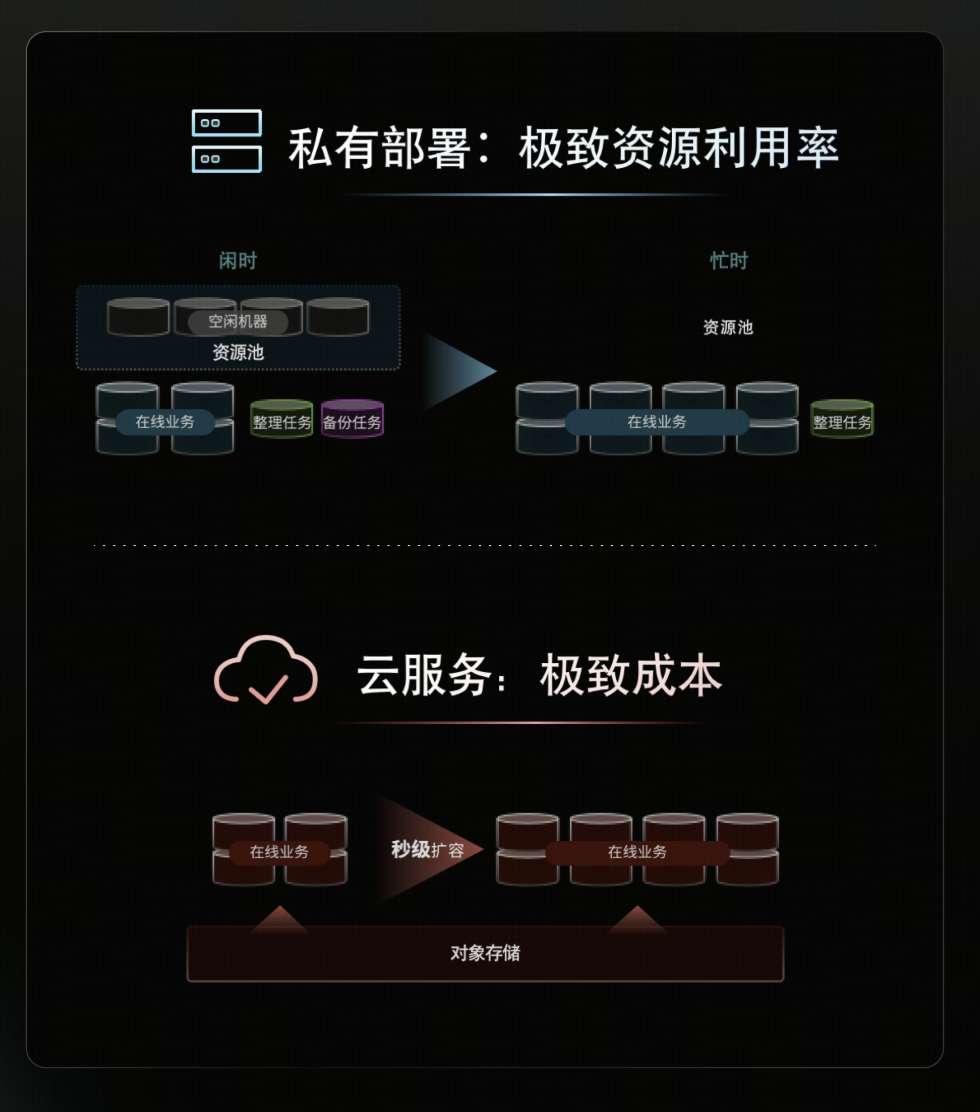
- 全托管云服务(即将到来):极致的弹性与成本。充分利用云端对象存储的特性,将弹性从“分钟级”推向了“秒级”。新节点启动即服务,无需预留资源、等待数据搬迁。这不仅能从容应对突发流量,更实现了真正的按用量付费。
- 私有化部署:极致的资源灵活性。受限于物理硬件难以做到秒级扩容,但得益于“存存分离、算算分离”,可以获得极致的资源隔离与分配灵活性——能够更细粒度地规划在线与离线资源,将硬件资源的利用率与分配灵活性推向极致。
Q7:这是一个全新的内核,稳定性如何值得信赖?
新一代内核的能力已在极端场景中经过了实战打磨。
在 Manus和 Dify 等头部 AI 客户的生产环境中,借助新一代内核的能力,经受住了海量 Agent 带来的脉冲流量冲击。
当数据库能够应对最复杂的变化,其在更常规业务场景中的适用性与稳定性更可放心。

Q8:新一代内核会替代现有的内核吗?
它是平凯数据库下一代演进版本。
新一代内核的技术成果(如更细粒度的资源隔离、存算分离 2.0)将逐步融入平凯数据库的整体产品体系中,为所有业务场景提供更高上限的底层架构支撑。
Q9:什么时候可以用上新一代内核?
2026 年上半年。
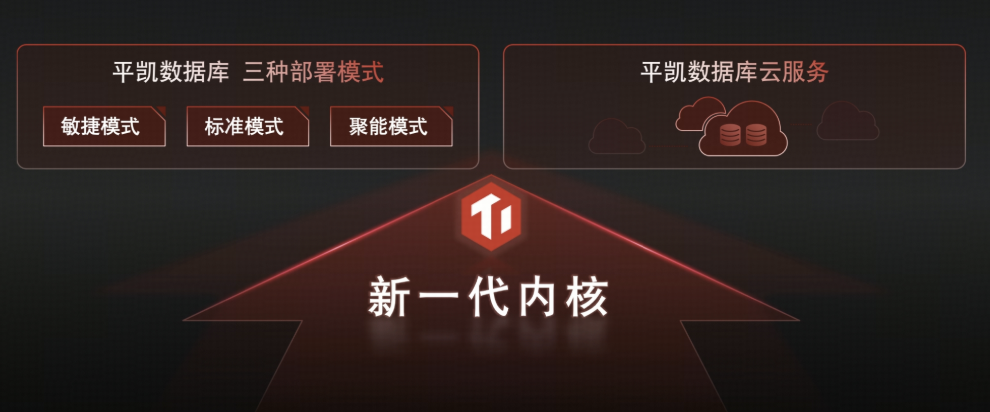
基于新一代内核的平凯数据库云服务将在今年上半年正式推出,届时您可以直接在云端体验到全托管、免运维的新一代数据底座。
在私有化部署,基于新一代内核的平凯数据库敏捷模式、标准模式和聚能模式也将推出。
