

摘要
在TiDB生态中,Placement Driver (后续以 PD 简称) 作为调度模块,负责整个集群的调度以及保存整个集群的元数据信息。这篇文章将从PD 的启动作为入手点,简单剖析 PD 节点启动的步骤,了解 PD 启动的流程,学习PD读取配置、启动日志和监控、设置并启动 PD 节点服务等知识点。
PD 简介
PD 是 TiDB 架构全局中心总控节点,它负责整个集群的调度,负责全局 ID 的生成,以及全局时间戳 TSO 的生成等。PD 还保存着整个集群 TiKV 的元信息,负责给 client 提供路由功能。
在架构上面,PD 所有的数据都是通过 TiKV 主动上报获知的。同时,PD 对整个 TiKV 集群的调度等操作,也只会在 TiKV 发送 heartbeat 命令的结果里面返回相关的命令,让 TiKV 自行去处理,而不是主动去给 TiKV 发命令。这样设计上面就非常简单,我们完全可以认为 PD 是一个无状态的服务(当然,PD 仍然会将一些信息持久化到 etcd),所有的操作都是被动触发,即使 PD 挂掉,新选出的 PD leader 也能立刻对外服务,无需考虑任何之前的中间状态。
Why PD?
当集群中只有一个 TiKV 时,调度没有意义,因为所有数据都在同一台机器上。所有的客户端请求经过 TiDB server 的解析都将分发到该TiKV。在分布式存储领域下,这种情况无法一致维持下去,因为数据增量终有一日将会达到这台机器的存储极限。到时候必须将部分数据迁移到其他机器上去。
在 TiDB 集群系统中,最初只有一个 Region。当数据量不断增大而超过设置的 Region 容量阈值时,Region 就会分裂,生成两个新的 Region。 Region 是 PD 调度 TiKV 的基本单位。当集群中新增 TiKV 节点时,PD 就会将原来 TiKV 中的一些 Region 迁移到新的 TiKV 中去。这样就能够保证数据尽量均衡地分布在整个 TiKV 集群上。其实除了要考虑数据分布上的均衡,同时也要考虑计算的均衡。这样才能保证整个 TiKV 集群更快更好地对外提供服务。因为 TiKV 使用的是 Raft 一致性算法。Raft 有一个强约束就是为了保证线性一致性。所有的读写都必须通过 Leader发起。假设现在有三个 TiKV,如果几乎所有的 Leader 都集中在某一个 TiKV 上,那么会造成这个 TiKV 成为性能瓶颈,最好的做法是 Leader 也能够均衡地分布在不同的 TiKV 上,这样整个系统都能对外提供服务。
总的来说,在分布式存储 TiKV 中,调度任务及其重要。这关乎系统向外提供服务的质量。必须同时考虑存储 Storage 和计算 Leader 等资源。所以我们得出一个观点,分布式存储系统是必须要有一个调度模块的。针对调度模块,不同的系统做出了不同的解决方案。比如Apache Doris 就将调度,sql解析,查询请求下发到 BE 节点等功能合并在一起作为为 FE 节点。这样做的好处就是集群中只有FE,BE两种节点。其搭建起集群的架构是相对简单明白的。但是这样也有缺点,调度与处理请求二者耦合在一起,每当因为查询请求压力过大时而增加 FE 节点时,同时增加了调度和处理请求的模块。这将造成一定的资源浪费,因为往往调度节点不需要和处理查询请求的节点一样多。因此,TiDB 将 PD 单独作为一个项目拿出来,使其可以单独部署,保证 PD 的灵活性,功能单一性。使得 TiDB 架构设计有了更多选择。
PD 本地编译运行
PD 源码开源,可以从 github 获取:https://github.com/tikv/pd
源码阅读需要在本地编译运行 PD 源码。首先需要准备 PD 所需环境。我本地运行的是 Win10 系统,安装了如下依赖:go 1.14.7 + cmake3 + mingw64,使用 Goland 本地编译运行。
这里需要注意的是,我一开始安装的 go 版本为1.15。结果每次本地编译都会报内存泄漏的问题。解决方法是降低 go 的版本。我降到1.14 版本后即可正常编译运行 PD server。
PD 源码阅读
今天将解读 PD 源码的开始部分:启动一个 PD server。
阅读从根目录下的cmd/pd-server/main.go开始,由此展开。
一、读取配置
PD 的配置信息有三个来源。分别是 Config 对象默认配置,外部配置文件和命令行参数。它们的优先级分别是命令行参数 > 外部配置文件 > 默认。
下面第一块代码就是读取配置的两行代码。config.NewConfig() 获取到系统的默认配置。系统默认配置文件在 /conf/config.toml 里。在Config 的结构体中,可以利用第三方包 BurntSushi/toml 直接读取 toml 格式的配置文件中的值。下面的第二段代码就是 config 结构体中使用 toml 工具包读取 toml 格式的配置文件中的值来设置属性的默认值的部分代码。通过 toml:"配置文件中属性名"的形式获取到配置的值。从而设置为该属性的默认值。Parse 方法读取命令行参数并将参数设置到 config 对象中去。
cfg := config.NewConfig()
//读取命令行参数
err := cfg.Parse(os.Args[1:])
type Config struct {
flagSet *flag.FlagSet
Version bool `json:"-"`
ConfigCheck bool `json:"-"`
ClientUrls string `toml:"client-urls" json:"client-urls"`
PeerUrls string `toml:"peer-urls" json:"peer-urls"`
AdvertiseClientUrls string `toml:"advertise-client-urls" json:"advertise-client-urls"`
AdvertisePeerUrls string `toml:"advertise-peer-urls" json:"advertise-peer-urls"`
}
创建默认配置对象 cfg 时,NewConfig 方法内部还将利用 flagSet 对象对 cfg 各个属性做属性说明。对于 bool 类型的属性将调用 flagSet的 BoolVar方法对其进行说明。具体过程会声明该变量的简称,值以及用处。同理 StringVar 就是对 string 类型的变量做说明的。
下面的示例代码就展示了 BoolVar 和 StringVar 的内部逻辑以及使用这些方法对 config 对象的属性做说明的过程。我们可以看到使用 StringVar 对属性 configFile 做了说明。其简称为 config 。它的值默认为 “” 。它的用处就是作为配置文件。同理,BoolVar 也对 bool 类型的属性 ConfigCheck 做了说明。说明它是检查配置文件的合规性的。
cfg := &Config{}
cfg.flagSet = flag.NewFlagSet("pd", flag.ContinueOnError)
fs := cfg.flagSet
fs.StringVar(&cfg.configFile, "config", "", "config file")
fs.BoolVar(&cfg.ConfigCheck, "config-check", false, "check config file validity and exit")
func (f *FlagSet) BoolVar(p *bool, name string, value bool, usage string) {
f.Var(newBoolValue(value, p), name, usage)
}
func (f *FlagSet) StringVar(p *string, name string, value string, usage string) {
f.Var(newStringValue(value, p), name, usage)
}
以上是默认配置的一些处理操作。接下来讲讲获取外部配置文件和命令行中的配置信息。
PD 在启动时可以携带外部的配置文件对 PD 的属性做配置。具体操作是用命令行启动 PD 时,使用命令行参数 --config 指明外部配置文件的位置。例如 --config “/usr/local/config.toml” 将指定 PD 启动时读取本机文件目录 /usr/local/config.toml 的配置文件。
接着在代码层面看一下这个过程:
首先在 main 方法中获取命令行参数信息。这一步骤是通过 go 的 os 包支持的。通过 os.Args 获取命令行参数数组。然后传入到 config 对象的 Parse 方法中。
接着在 Parse 方法中,调用 flagSet 的 Parse 方法将命令行参数都设置到 config 对象对应的属性上。在随后的代码中将判断 config 对象中 configFile 属性是否非空。因为这个属性默认是空字符串,只有设置了值,才能进行下一步读取指定路径的配置文件。当它的值非空时将调用 configFromFile 方法读取指定目录的配置文件,读取的结果放到 toml.MetaData 对象中。然后将这个对象传入到 config 对象的Adjust 方法中用于调整 config 的各个属性值。
PD 的配置文件描述全面的资料可以参考:https://docs.pingcap.com/zh/tidb/stable/pd-configuration-file
命令行参数描述可以参考:https://docs.pingcap.com/zh/tidb/stable/command-line-flags-for-pd-configuration
读取完配置后,Parse 方法将返回 err 对象以帮助判断 Parse 过程是否成功。err 如果是 nil,则说明 Parse 是没有问题的。如果是ErrHelp,则说明输入命令行的是 -h 或者是 -help。输入这个命令说明我只是想查看 PD 启动时可以携带哪些配置参数而不是直接启动PD。所以在这个 case 下将调用 exit 方法退出启动程序。除此之外,其他情况就是 parse 过程错误,输出错误提示信息。
switch errors.Cause(err) {
case nil:
case flag.ErrHelp:
exit(0)
default:
log.Fatal("parse cmd flags error", errs.ZapError(errs.ErrParseFlags))
}
二、启动 logger 服务并打印 PD Server 的信息和警告信息
PD 使用 zap Logger 替代 go 原生的 log 组件以此来提高整体运行的性能。go 原生的 logger 使用起来十分简单。通过设置任何 io.writer 作为日志记录输出并向其发送要写入的日志就行。但是简单归简单,原生 logger 也有很多不足的地方。例如:仅限基本日志级别、只有一个 Print 选项、Fatal 日志通过调用os.Exit(1)来结束程序、Panic 日志在写入日志消息之后抛出一个 panic、不提供日志切割的能力、缺乏日志格式化能力等。综合这些原因,PD 使用 uber 开源的日志框架 zap logger 来替换原生的 logger。zap logger 有两个优点。其一是提供了结构化日志记录和 printf 风格的日志记录。其二是它非常的快。关于 zap logger 高性能的设计思路可以参考它家 github 地址:https://github.com/uber-go/zap#performance。
下面代码就是 PD 创建 zap logger 作为自己的 logger 的过程:
首先调用 cfg 对象的 SetupLogger 方法设置 cfg 的 logger 和 logProps 属性。在 SetupLogger 方法内部,使用 PingCAP 自家的 log 包里的初始化方法 InitLogger 获得 zap.logger 和 ZapProperties 对象并将二者分别赋给 cfg 的 logger 和 logProps 属性。接着使用 ReplaceGlobals 替换全局的 logger。然后刷新缓存,最后使用 InitLogger 初始化 zap logger。
logger 组件设置启动好之后,打印 PD 信息和过程中出现的警告。
err = cfg.SetupLogger()
if err == nil {
log.ReplaceGlobals(cfg.GetZapLogger(), cfg.GetZapLogProperties())
} else {
log.Fatal("initialize logger error", errs.ZapError(err))
}
// Flushing any buffered log entries
defer log.Sync()
// The old logger
err = logutil.InitLogger(&cfg.Log)
if err != nil {
log.Fatal("initialize logger error", errs.ZapError(err))
}
server.LogPDInfo()
for _, msg := range cfg.WarningMsgs {
log.Warn(msg)
}
三、Prometheus 监控
在 main 方法中调用 EnableHandlingTimeHistogram 。在 PD 启动时,会初始化一个默认的 ServerMetrics 对象来记录 PD server服务运行的指标。默认不开启 Histogram metrics 这个指标监控。因为这个指标监控耗费性能较高。在源码的注释中也说明:开启 Histogram metrics 监控可能会耗费较大性能。如果机器性能有限,那么可以选择不开启。
接着就会调用 Push 方法将指标发送到 Prometheus 的推送网关上。具体推送方法是 prometheusPushClinet。在该方法内首先构造推送者对象 pusher。pusher 的构造使用了建造者模式。首先使用推送的地址和任务初始化 pusher,添加了为其添加了收集器以及分组标签。
grpcprometheus.EnableHandlingTimeHistogram()
metricutil.Push(&cfg.Metric)
func prometheusPushClient(job, addr string, interval time.Duration) {
pusher := push.New(addr, job).
Gatherer(prometheus.DefaultGatherer).
Grouping("instance", instanceName())
for {
err := pusher.Push()
if err != nil {
log.Error("could not push metrics to Prometheus Pushgateway", errs.ZapError(errs.ErrPrometheusPushMetrics, err))
}
time.Sleep(interval)
}
}
四、动态添加节点
PD 使用 PrepareJoinCluster 方法将当前节点 join 指定的集群当中去并且在 join 成功后持久化 join 配置,当 PD 节点宕机后重启时,读取本地配置就能快速重新加入集群。
下面简单聊聊从 PD 节点首次加入到一个集群以及 PD 停机再次加入集群的情况。
当 PD 节点首次 join 某集群时,我们进入 PrepareJoinCluster 方法,携带的参数是 cfg,也就是 PD 配置对象。当我们想 join 某个集群时,首先保证目标集群能够正常工作。在启动 PD 节点时。命令行携带参数 --join=“target-urls”,target-urls 就是目标集群里任意 PD 的advertise-clinet-url。PD 启动时通过 os.Args 读取这些额外参数并设置到 cfg 对象中去。首先要做基本的差错检测,排除 join 信息错误的情况。然后尝试读取本地保存的 join 信息。我们是第一次 join 到一个陌生的集群,这些信息以及目录还没有创建。接下来将创建一个etcd 的 client,创建时传入 Join 信息、TLS凭证配置、超时限制等信息。下一步,ListEtcdMember 方法列出目标集群所有的 etcd 成员。随后判断当前 PD 节点是否与集群中的节点重名。重名则无法加入集群,直接退出。如果满足条件名字不冲突。随后使用 AddEtcdMenber方法尝试加入集群。结果将返回到类型为 *clientv3.MenberAddResponse 的对象中。随后再次调用 ListEtcdMenber 获取最新的 etcd 集群成员信息并对集群情况进行验证,并将最新的集群信息更新到 cfg 对象中。最后将节点配置信息保存到本地。
当 PD 停机再次重启时,直接读取本地文件获取集群信息并加入到集群中去。
err = join.PrepareJoinCluster(cfg)
if err != nil {
log.Fatal("join meet error", errs.ZapError(err))
}
五、创建并运行 PD Server
这一步骤主要做两件事情。第一个就是创建 PD Server 并运行。第二就是监听退出信号。
首先使用 CreateServer 方法创建 server 对象并且传入所需要的参数:上下文对象 ctx、配置 cfg、服务数组 servcieBuilders。接着调用server 的 Run 方法启动 server。在 Run 方法内,首先会通过协程开启监控。随后开启 etcd 和 Server 服务。最后通过 server 的startServerLoop 方法使得服务处于不断运行的状态而不退出。
另外一个部分就是监听退出信号。通过监听四种信号来判断是否要中止服务。这四种信号及含义如下表所示。监听程序通过协程的方式监听退出信号,一旦监听到退出信号,调用 cancle 方法即会向 ctx 对象的 Done 通道发送消息。Done 通道一旦接收到消息运行 server 的线程就会退出。接着就会打印退出信息返回退出码。
| 信号 | 值 | 动作 | 说明 |
|---|---|---|---|
| SIGHUP | 1 | Term | 终端控制进程结束(终端连接断开) |
| SIGINT | 2 | Term | 用户发送INTR字符(Ctrl+C)触发 |
| SIGINT | 3 | Term | 用户发送QUIT字符(Ctrl+/)触 |
| SIGINT | 15 | Term | 结束程序(可以被捕获、阻塞或忽略) |
ctx, cancel := context.WithCancel(context.Background())
serviceBuilders := []server.HandlerBuilder{api.NewHandler, swaggerserver.NewHandler, autoscaling.NewHandler}
serviceBuilders = append(serviceBuilders, dashboard.GetServiceBuilders()...)
svr, err := server.CreateServer(ctx, cfg, serviceBuilders...)
if err != nil {
log.Fatal("create server failed", errs.ZapError(err))
}
总结
总的来说,PD 节点的启动会经历读取配置、设置logger、启动 prometheus 监控、join 集群、启动 server、监听退出命令后退出等步骤。其启动过程相对与 TiDB Server 的要简单不少。使用到的技术也是比较常见的,比如 etcd、Raft、TOML、Prometheus、Zap Logger。
整个 PD 的启动流程用下面流程图表示:
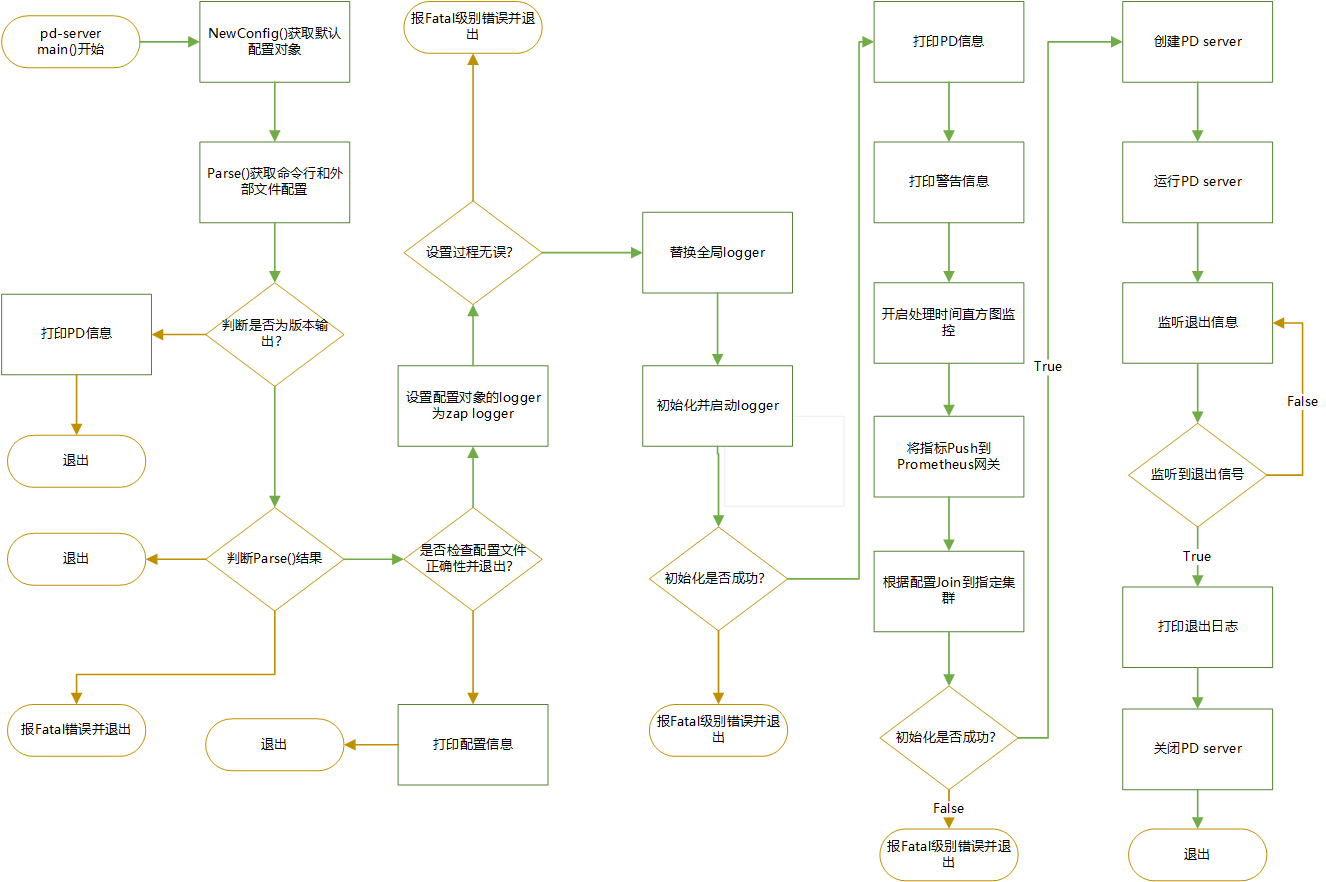
本篇文章只是对 PD 节点启动做的一个粗略的解读,有些地方可能存在不妥的地方,希望有真知灼见的大神能不吝赐教,指出文章的问题,多多交流。