

本文根据 PingCAP DevCon 2021 上来自小米的数据库研发工程师刘子东的分享整理而成,介绍了 TiDB 在小米的落地以及小米在云原生领域的探索。
视频回顾: https://www.bilibili.com/video/BV1eq4y1p7HL
讲义下载:小米-刘子东-TiDB 在小米的落地及云原生探索.pdf (768.1 KB)
现状
小米从创立到今天已经过去了 10 年,2020 年 8 月 16 日雷总在线上直播,宣布小米正式开启新十年的创业者计划。第二个月,云平台部门的数据库与存储团队启动了 TiDB 项目,作为团队在小米新十年中的第一个三年规划。2021 年 1 月,TiDB 产品正式在小米的内部私有云上线,落地各项业务。
先介绍一下小米与 TiDB 的现状。经过近一年的发展,TiDB 在小米已经部署了 20 多个集群,TiKV 节点也达到了三位数,覆盖的业务场景包括电商、供应链、大数据等等。右边这个米字 logo 的词云是由我们的一部分业务线组成的,包括了零售中台、小米有品、智能制造、代工厂、还有门店等。

小米经过十年的发展,在传统数据库上的使用中,确实遇到了相当多的痛点。因为时间有限,这只列举其中四个。
第一,容量瓶颈。我们内部的单机只有 2.6 T,经过十年的发展,很多业务线单机的存储都已经达到了 2 T 以上,甚至只有几百 G 的空间剩余,马上就要满了。为了解决容量问题,之前一般采用传统的分库分表解决方案,如果你对业务逻辑没有很深的了解,是成本非常高的事情,然而业务线的建设时间往往已经过去很久,以至于代码都不知道从何下手去重构。通过引入 TiDB 就能够比较轻松地解决这个问题。
第二,高可用。MySQL 的主从架构下,我们尝试使用很多方法来做高可用实现,比如通过 LB + Orchestrator + 中间件的方案来解决。但是,如果半夜主库挂了,可能仍然睡不好觉。
第三,高写入。TiDB 作为一个分布式数据库,很好地解决了多点写入的问题。传统的 MySQL 主从架构,只能写到主库上,很容易达到瓶颈,达到瓶颈之后就会带来非常强的主从延迟。主从延迟就会带来一致性问题,一致性问题对很多业务来说是一个灾难。
最后,我们还有一些历史包袱。小米十年发展以来,我们内部有各种各样的解决方案去适应业务规模的增长,但都各有优劣。小米曾开源过一个叫 Gaea 的中间件,也是支持分库分表的,我们内部还有其他的中间件,方案非常多,而且都分散在各个业务线。一旦相关人员有一些变动,就会变得非常难以维护。但是 TiDB 实现了这些方案的打包,我不再需要考虑是用这个中间件还是那个中间件,他们分别适应什么样的场景。
发展
我们发展的非常快,从我们刚刚了解 TiDB,到去年 9 月份接入了第一个业务,然后我们开始正式立项,建立团队。在今年 1 月份,我们就完成了包括部署、监控、告警、工单等基础能力的建设,开始类似于一个 DBaaS 平台,去对业务提供服务。
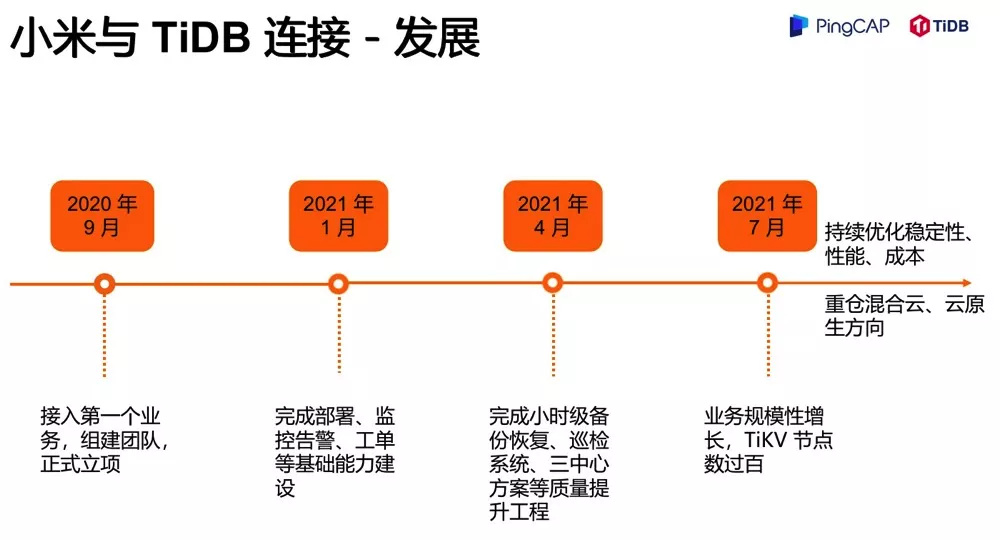
到今年 4 月,我们开始做质量提升工程,完成了小时级的备份恢复,还有巡检系统、两地三中心等方案的落地,大大提升了业务质量。到今年 7 月份,业务规模开始快速增长,TiKV 节点很快就过百了。我们现在看到的节点数过百,完成业务规模翻倍,其实仅仅就两三个月的时间。因为很多业务确实看到了 TiDB 很大的一个可扩展性,在遇到存储瓶颈时,他们也很愿意去做这个迁移接入。后面,我们也会持续的去做 TiDB、TiKV 的稳定性、性能还有成本等方面的工作,并且会重仓云原生的方向。
我们正式成立 TiDB 团队投入到 TiDB 产品的落地中还不到一年,和很多厂商相比算是后辈,我们也充分利用了后发优势,直接引入了大量生态产品如 BR、TiCDC、TiUP、DM 等等这些生态产品极大地减小了我们的运维成本,方便我们构建 TiDB 服务平台,促进了产品的快速发展。
挑战
其实接入 TiDB 也不是那么一帆风顺。
第一是从分库分表到 TiDB 的迁移过程。历史问题造成的上游数据质量堪忧(如业务自行分库分表的设计,主键ID重复,甚至触发器、存储过程等),需要业务端做改造,从而导致迁移周期漫长。
第二是复杂的业务 SQL 导致查询计划不准。我们的老业务迁到 TiDB 之后,某一个 SQL 突然比以前执行时间大大增长。SPM 无法完全解决,一是 SQL 变化多、数量大。二是根据 cost,执行计划也会变化。而很多老业务的复杂 SQL 非常多,我们需要一一去调整查询计划,去帮业务做调优。
第三是部分内部工具对接,比如为了对接内部消息队列,我们建了一个 TiCDC 的内部分支版本、Drainer 的内部分支版本,当然后续比较根源的解决办法是内部工具去迎合外部开源工具,支持相应开源工具的接口。
最后,硬件、软件多方面的性能调试。比如一些反直觉的情况:我们之前使用的一款NVMe 硬盘表面上磁盘性能比 SSD 要高,但实测 sysbench 的 workload 和业务的 workload 都有不小性能差距,有的情况下甚至 NVMe 的并发性能比 SSD 还要差一倍。硬件的适配和兼容也是后期我们调优的一个方向。
点赞
第一个是 社区支持非常友好,文档非常完善,因此我们的接入非常快速 。我之前也讲了,其实仅仅一个季度的时间,我们就把整个以前看来各种高大上的平台做好,可以对业务提供服务了。
第二个是 完善的数据库周边生态,降低了运维的成本 。我们知道一个数据库产品的落地需要有自动化部署、监控告警、运维管理平台等一系列基建,得益于 TiDB 社区良好的可观测性和丰富的生态组件如 TiUP / BR / Dashboard 等等,我们很轻松的完成了相关建设,极大降低了运维成本,减轻了运维压力。
第三个, 跨机房,多机房容灾,异地多活这个话题也是一个很深的话题 。我们真正实践起来发现 TiDB 在跨机房上表现得非常优秀,很容易落地三中心的计划。对于一些需要异地容灾的业务来说,TiDB是一个很好的选择。
第四个, 加密存储及传输的功能 。透明数据加密 (Transparent Data Encryption),简称 TDE,是 TiDB 推出的一个新特性,应用在风控隐私集群上,极大简化了业务逻辑。

最后是说下 HTAP 的内容。我们内部也有一些 HTAP 的实践,右边这个指标是我们的一个核心业务做的 HTAP 的实践,我们之前通过 TiSpark 打在 TiKV 上的任务时间是在左边,我们换了 TiFlash 之后,我们可以看到,无论是从任务执行时间,还是 P99 延时、负载上,我们都提高了不只三倍。如果我们自己去优化这三倍的性能,需要投入的精力有多少,大家做过性能优化的应该都知道。TiFlash 的引入大大简化了我们的工作。
连接
前面我们提到,TiDB 丰富的生态,极大降低了我们的运维成本。 取之社区,回馈社区 。包括 TiDB 产品在内,很多生态产品我们都有提 patch。现在,小米团队是多个产品的 contributor,包括 dumpling、br、ticdc、tiup 等,TiDB 产品目前是 active contributor。
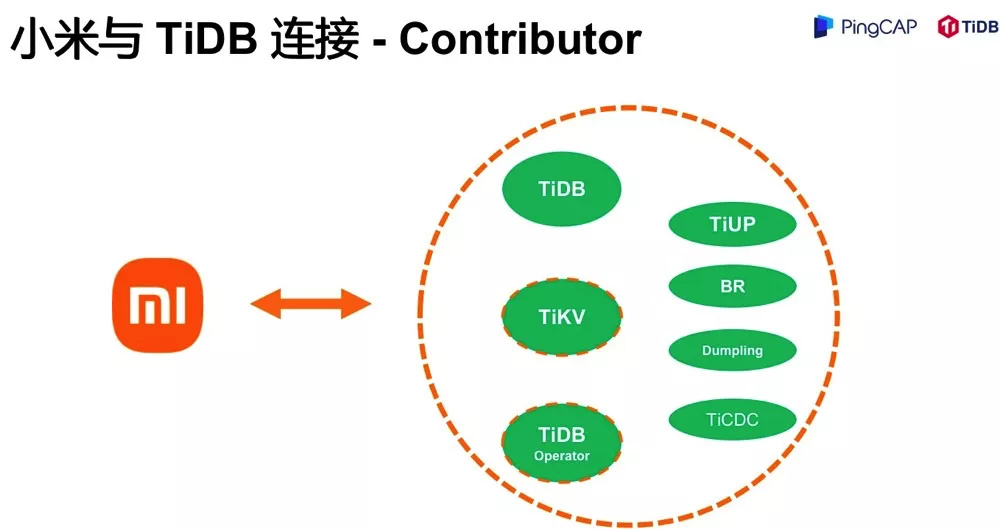
画虚线的产品 TiKV、TiDB Operator,虽然目前还不是 contributor,但是我们和 PingCAP 已经达成合作,后续将持续贡献 TiDB、TiKV、TiDB Operator 产品,同时也是符合我们持续性优化稳定性、性能及成本目标。
我们不仅仅是 DBA,还是研发工程师,都有代码层面了解产品的执拗,当然对生态产品的代码了解也有助于我们落地到业务中,同时反哺社区,帮助完善生态,也是开源社区所倡导的良性循环。
探索
玩过云的,大家可能都知道,云发展历程中经历过很多基础设施的不同潮流,包括选择私有云还是公有云,以及底层的一些框架如何使用。
因为小米的国际化业务现在越来越发达,我们对海外的公有云的需求也会越来越大。所以我们制订了一个全球混合多云的战略。我们同时使用 IDC 机房和多种公有云,并且对外封装,把他变成一个屏蔽细节的、全球化的混合多云。

这个混合多云的具体有哪些好处呢?
首先是 安全性 。在国际化业务中,我们可以根据需求把数据存储在不同的位置。这个是可以通过我们的存储来做,业务无需关心。第二个 灵活性 。我们可以对业务屏蔽掉底层这个复杂的多云环境,从而提供一个通用的环境。这样我们在切换供应商,或者是做一些底层操作的时候,业务就不会有感知。第三个 成本 。云原生的好处之一,就是优化调度,资源共享。第四个 质量 。 云的另一个好处就是高弹, 我们可以快速完成扩缩容。而我们如何在混合云下做高弹,又是一个非常大的挑战。
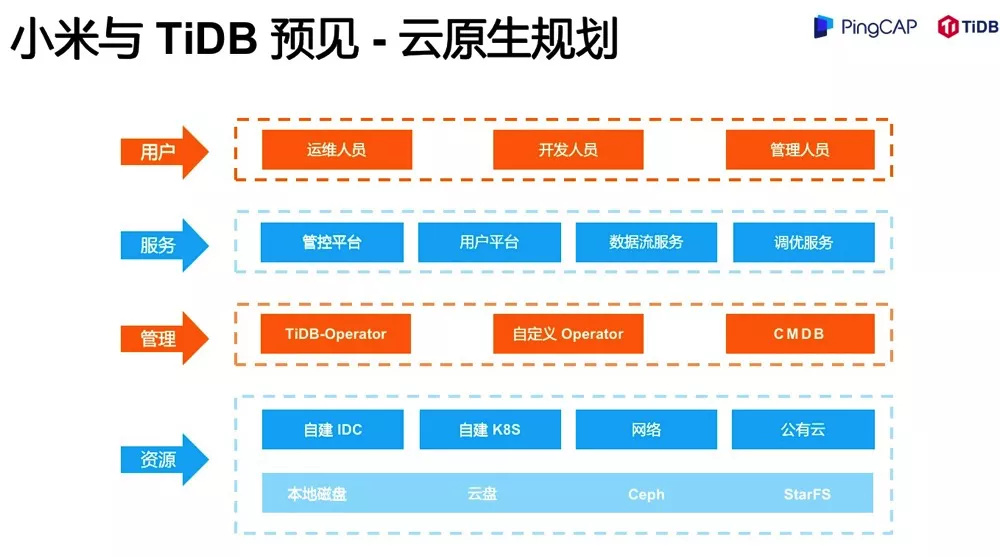
我这里画了一个非常粗粒度的规划。
用户层我们不展开讲。服务是我们给用户提供的服务,包括运维管控、用户平台、数据流以及一些调优服务。然后是管理:由于 TiDB Operator 部署在单个 K8s 集群中,控制范围仅能在单个 K8s 集群,而我们的需求可能包含跨机房,跨云,甚至 IDC 和 K8s 混合(比如 TiCDC 部署在云中,而 TiDB 集群在 IDC 物理机上),所以我们需要在 TiDB Operator 上另外增加一些自定义调度。所以我们可以看到除了 TiDB Operator、传统的 CMDB,我们增加了一个自定义的 Operator。
底层的资源刚刚已经介绍了大部分,需要提的一项是底层的存储资源。从本地磁盘到云盘到 Ceph,再到其他分布式存储。开发者嘉年华的吐槽大会环节,美团的黄潇老师对 TiDB 对演进方向有一个灵魂拷问:我们未来 TiKV 到底是继续提高调度呢,还是说去往 PolarDB 这边靠,做一些共享存储的方案?东旭的回答是:我们为什么不都做呢?
其实我们也在研究这个问题。在支持本地磁盘和云盘的过程中,我们也在调研云原生的分布存储。StarFS 是我们数据库与存储团队目前正在自研的分布式云原生文件系统,与普通分布式存储如 HDFS、Ceph 等有区别,主打高性能、低延迟。分布式存储有一个天然弱势就是 latency 不稳定,所以很难作为线上数据库的存储后端,目前没有能满足数据库需求的开源分布式存储。StarFS计划采用基于高性能存储介质 SSD、NVMe,采用 SPDK、RDMA 等技术实现适合数据库的分布式存储后端。
当然,这只是初步规划,并在有条不紊推进过程中,也期待引进越来越多的新技术,来迭代优化混合云的架构设计。

云原生探索踩过一些小坑,这里技术细节比较多了。可以简单介绍一下,假如 PD-pod 假死,Operator 的控制逻辑就会失效。表面上是在 Running 的状态,但其实这个 pod 已经无法提供服务了,这个坑也很难受。还有一些分布式存储的调度问题、故障切换问题造成服务不可用的问题等。另外 Controller 的串行化设计也需要注意。我们知道 Controller 是把你的集群控制在一个期望的状态,但是这个串行化的控制逻辑会让你在扩容 TiDB 的时候,假如 TiDB 扩容不成功,TiKV 也无法扩容成功,这样的话就导致阻塞,导致你整个运维操作的失败。
预见
最后表达一下期望,我们已经和 TiDB 社区建立了深度的合作,我们会共同推进混合多云战略,推进核心业务的 MySQL 迁移,以及做一些 Committer 的培养。在内部也会继续推进 TiDB 落地到小米金融、小米 AI、小米 IoT 等多个业务场景。