

【是否原创】是
【首发渠道】TiDB 社区
【首发渠道链接】
【目录】
【正文】
这是一篇关于程序员对SQL认知的文章,如果你只是好奇SQL和CRUD是啥,可以直接滑到文末,顺便点个赞 :slight_smile:
不知道你是不是注意到这么一个现象,在逛各大论坛的时候,大家问的最多的问题是怎么读取数据,怎么存储数据,也就是大家常说的CRUD操作,这里打个比方,假如一个数据库比作一个冰箱,把食物放进冰箱,这种操作可以认为是CRUD操作中的插入操作;打开冰箱看看有什么食物是查询操作;原材料加工成菜肴再放回冰箱是更新操作;菜肴吃完不再把空盘子放回冰箱是删除操作。程序员如果跟数据库打交道,是不是大部分工作都是在对数据进行拿进拿出的操作?但是SQL的初衷真的只是CRUD操作嘛?
1986年,一个叫ANSI的标准化组织发表了一些列针对SQL的ISO标准文档,2019年最新一版SQL:2019已经对SQL内容增加到了15个部分,这么多内容都讲的啥?对我的工作有啥帮助?是不是每一部分都要看懂才能用数据库?
这里先放一下这些问题,我们先讲一下为啥会突发奇想去看SQL标准,重新理解SQL内部设计。
故事要从2017年讲起,当初由于内部项目对分布式数据的需求,我们开始尝试改造开源分布式数据库TiDB,这就给了我们一个机会,从数据库内部理解数据存储和数据获取的运行逻辑。这个改造不光只是修改几行代码,我们需要从TiDB支持的MySQL协议和查询关键字,改变成PostgreSQL协议和查询关键字,具体的经过可以查看下面这篇文章。
TiDB for PostgreSQL—牛刀小试 - 知乎 (zhihu.com)
修改SQL语句关键字时,就要涉及修改SQL Parser模块,这些模块处在接受SQL语句之后的流程中,也就是下图绿色方块部分。
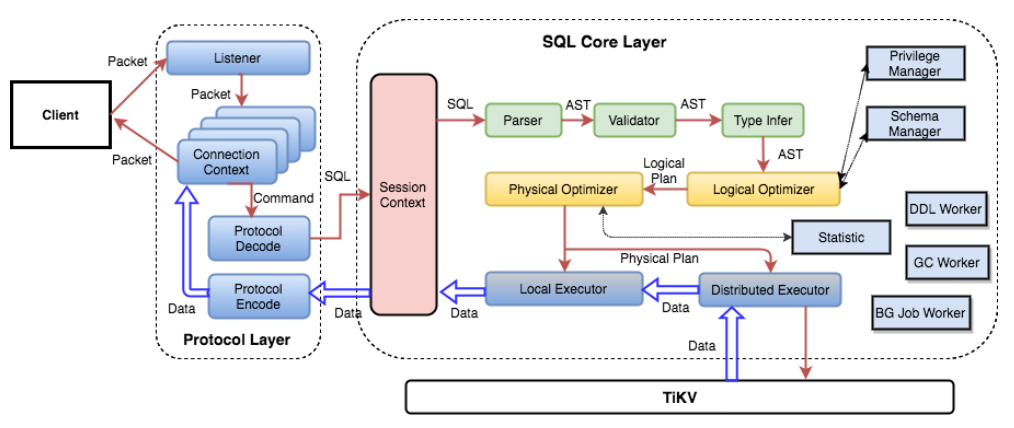
这部分代码其实是一个独立的代码库
pingcap/parser: A MySQL Compatible SQL Parser (github.com)
我们在这个库的基础上,重新加入PostgreSQL语句和关键词的解析,代码地址和说明可以参考下面的链接。
DigitalChinaOpenSource/DCParser (github.com)
TiDB源码学习笔记:Parser模块 - 知乎 (zhihu.com)
但这里又出现了一个新的问题,pingcap下的parser是MySQL兼容的解析器,如果基于这个项目修改的解析器一定多多少少包含MySQL语法的影子,那我们是不是能完全摆脱MySQL,做出一个纯粹的pg语法parser呢?
我们打开parser.y的yacc文件,可以在文件开头注释中看到这样的说明。
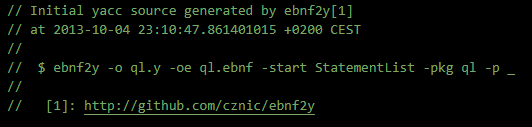
另外结合,pingcap源码阅读系列文章,TiDB 源码阅读系列文章(五)TiDB SQL Parser 的实现 | PingCAP
最初的parser.y是从BNF文件转化生成的。可以这么理解,由于SQL语句解析过于庞大,如果全部手工编写会非常耗时,所以通过工具,先把标准的SQL BNF文件转换成Yacc文件,再修改这个文件实现MySQL适用的解析器,等于找了个事半功倍的工具。
BNF是Backus-Naur Form的首字母缩写,Backus代表John Backus,Naur代表Peter Naur,这两个人于上世纪50年代分别使用数学符号的方式来描述特定语言,最后形成统一的规范,我们就称这种规范为BNF。这里举一个简单的例子:
<table_expression> ::= <from_clause>[ <where_clause> ][ <group_by_clause> ][ <having_clause> ]
这个表达式的意思是,在SQL语句中的table表达式部分, 必须有from语句,可以有where语句,也可以有group by语句,还有可以有having语句,所以我们可以得知,这里的中括号代表不是强制需要的语句部分,而这些对应的语句部分需要去看相应的语句定义部分。
所以我们知道找到对应的SQL BNF文件,就能生成yacc文件,就是tidb parser最初的样子,也就是SQL标准所定义的样子。BNF可以从Ron的代码库中找到
ronsavage/SQL: BNF Grammars for SQL-92, SQL-99 and SQL-2003 (github.com)
至此,我们其实已经可以从SQL标准BNF开始搭建PG语法兼容的Parser了,不过为了搞清楚每一个SQL标准更新到底有哪些不同,应不应该从最新的标准开始我们的工作,我们需要进一步查找SQL标准相关资料。其实也就回到了文章最初的问题,这些标准都讲了啥?对我的工作而言有没有必要了解?
我们从维基百科上找到了这么一张表格,表格内标注了每一个SQL标准发布年份和主要更新内容。
| Year | Name | Alias | Comments |
|---|---|---|---|
| 1986 | SQL-86 | SQL-87 | First formalized by ANSI |
| 1989 | SQL-89 | FIPS 127-1 | Minor revision that added integrity constraints, adopted as FIPS 127-1 |
| 1992 | SQL-92 | SQL2, FIPS 127-2 | Major revision (ISO 9075), Entry Level SQL-92 adopted as FIPS 127-2 |
| 1999 | SQL:1999 | SQL3 | Added regular expression matching, recursive queries (e.g. transitive closure), triggers, support for procedural and control-of-flow statements, nonscalar types (arrays), and some object-oriented features (e.g. structured types), support for embedding SQL in Java (SQL/OLB) and vice versa (SQL/JRT) |
| 2003 | SQL:2003 | Introduced XML-related features (SQL/XML), window functions, standardized sequences, and columns with autogenerated values (including identity columns) | |
| 2006 | SQL:2006 | ISO/IEC 9075-14:2006 defines ways that SQL can be used with XML. It defines ways of importing and storing XML data in an SQL database, manipulating it within the database, and publishing both XML and conventional SQL-data in XML form. In addition, it lets applications integrate queries into their SQL code with XQuery, the XML Query Language published by the World Wide Web Consortium (W3C), to concurrently access ordinary SQL-data and XML documents.[33] | |
| 2008 | SQL:2008 | Legalizes ORDER BY outside cursor definitions. Adds INSTEAD OF triggers, TRUNCATE statement,[34] FETCH clause | |
| 2011 | SQL:2011 | Adds temporal data (PERIOD FOR)[35] (more information at: Temporal database#History). Enhancements for window functions and FETCH clause.[36] | |
| 2016 | SQL:2016 | Adds row pattern matching, polymorphic table functions, JSON | |
| 2019 | SQL:2019 | Adds Part 15, multidimensional arrays (MDarray type and operators) |
SQL-92是最重要的版本,这个版本里定义了大家最常用的数据功能,包括:
- DATE,TIME,NVARCHAR…等类型
- 对字符串,时间进行运算
- 定义了UNION,JOIN等操作
- 创建临时表
- 事务隔离等级
同时开始出现”数据关系“这个概念,这些功能代表着,从SQL-92开始,数据库不再只是简单的数据存储和索引系统,而是可以通过大家熟悉的第一范式、第二范式、第三范式减少数据冗余和建立数据关系,能够对数据库内部数据按照业务需求进行数据转换呈现。
SQL-1999之后,SQL开始添加更多超出关系范畴的功能,例如正则表达式,循环查询,数组类型,自定义类型等等,我们举一些简单的例子。
- 数组类型
- 嵌套表
- 复合类型
- 递归查询
数组类型:
我们在系统设计时经常会碰到一些数组类型的对象属性,这些属性如果按照关系型设计,通常会设计成下图,属性表没有主键,查询还需要join多张表,是不是觉得很累赘。
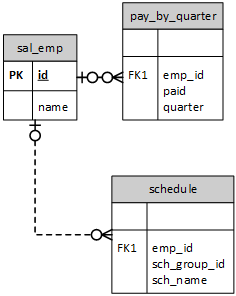
如果抛弃外键关系,利用数组类型,可以变成一种非常简单的设计:
| Schema | Insert | Select | Update in a slice |
|---|---|---|---|
| CREATE TABLE sal_emp ( name text, pay_by_quarter integer[], schedule text[][]); | INSERT INTO sal_emp VALUES (‘Bill’, ‘{10000, 10000, 10000, 10000}’, ‘{{“meeting”, “lunch”}, {“training”, “presentation”}}’); | SELECT * FROM sal_emp WHERE 10000 = ANY (pay_by_quarter); | UPDATE sal_emp SET pay_by_quarter[1:2] = ‘{27000,27000}’ WHERE name = ‘Carol’; |
From https://www.postgresql.org/docs/9.1/arrays.html
嵌套表:
如果希望对这些数组属性进行表的聚合与筛选操作,就可以利用嵌套表实现,表结构如下:
ALTER TABLE customers_demo
ADD (cust_address_ntab cust_address_tab_typ,
cust_address2_ntab cust_address_tab_typ)
NESTED TABLE cust_address_ntab STORE AS cust_address_ntab_store
NESTED TABLE cust_address2_ntab STORE AS cust_address2_ntab_store;
可以通过MULTISET INTERSECT DISTINCT对两张嵌套表数据进行筛选,选出相同的数据:
SELECT customer_id, cust_address_ntab
MULTISET INTERSECT DISTINCT cust_address2_ntab multiset_intersect
FROM customers_demo
ORDER BY customer_id;
CUSTOMER_ID MULTISET_INTERSECT(STREET_ADDRESS, POSTAL_CODE, CITY, STATE_PROVINCE, COUNTRY_ID
----------- -----------------------------------------------------------------------------------
101 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('514 W Superior St', '46901', 'Kokomo', 'IN', 'US'))
102 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('2515 Bloyd Ave', '46218', 'Indianapolis', 'IN', 'US'))
103 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('8768 N State Rd 37', '47404', 'Bloomington', 'IN', 'US'))
104 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('6445 Bay Harbor Ln', '46254', 'Indianapolis', 'IN', 'US'))
105 CUST_ADDRESS_TAB_TYP(CUST_ADDRESS_TYP('4019 W 3Rd St', '47404', 'Bloomington', 'IN', 'US'))
From https://docs.oracle.com/cd/B28359_01/server.111/b28286/operators006.htm#SQLRF51164
复合类型:
如果我们希望数据关系更紧密,我们可以考虑利用复合类型来构建数据间的关系:
CREATE TYPE inventory_item AS (
name text,
supplier_id integer,
price numeric
);
CREATE TABLE on_hand (
item inventory_item,
count integer
);
INSERT INTO on_hand VALUES (ROW('fuzzy dice', 42, 1.99), 1000);
From https://www.postgresql.org/docs/current/rowtypes.html
递归查询:
我们在处理有自我关系的数据表时,经常需要处理层级问题,例如下面这个情况,业务希望查找第四层人员中有没有一个叫Anna的人,
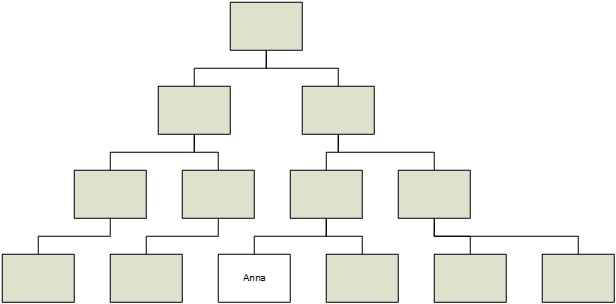
CRUD boy通常会有两种做法,
方法一,一次性获取所有数据,在内存中处理,减少数据库链接成本:
all_data = get_all_data_from_database()
level_data = get_root_node(all_data)
for depth = 2 to 4
level_data = get_next_level_data(all_data, level_data)
If has_person(level_data, "Anna")
// found
方法二,一次获取一层数据,减少一次性加载的数据量:
level_data = get_data_from_database(null) // select * from graph where parent_id = null
for depth = 2 to 4
parent_ids = get_ids(level_data)
level_data = get_data_from_database(parent_ids) // select * from graph where parent_id in parent_ids
If has_person(level_data, "Anna")
// found
这两种方式都是传统CRUD处理的办法,都有优缺点,数据量少可以用第一种方法,数据量多就只能靠每次读数据库处理了。
但是如果利用SQL-1999提供的递归查询功能,可以非常简单的处理这类问题,代码示例如下,
WITH RECURSIVE search_graph(id, parent_id, data, depth) AS (
SELECT g.id, g.parent_id, g.data, 1
FROM graph g
UNION ALL
SELECT g.id, g.parent_id, g.data, sg.depth + 1
FROM graph g, search_graph sg
WHERE g.id = sg.parent_id
)
SELECT * FROM search_graph where depth = 4 and data = 'anna';
From https://www.postgresql.org/docs/9.1/queries-with.html
之后SQL版本又增加了XML,JSON,Window函数,Fetch语句的支持。可以说SQL数据之间的关系早已超越了数据库设计范式的定义,甚至开始针对XML/JSON等非强关系数据结构进行处理操作,所以对数据表设计要求越来越高,如果数据表设计合理可以减少冗余,提高数据查询效率;反之会带来数据灾难,尤其是在复杂业务数据场景下。
文章结束前打个广告,tidb for pg项目正在招募志同道合的小伙伴一起推进tidb pg生态,有兴趣的小伙伴可以联系我们:dc.opensource@yungoal.com
项目地址:
- https://github.com/DigitalChinaOpenSource/TiDB-for-PostgreSQL
- https://github.com/DigitalChinaOpenSource/DCParser/
名词解释:
-SQL:Structured Query Language的缩写,简单来说,通过接近自然语言的方式操作数据的编程语言。比如看看保险箱(safe)里有多少(sum)钱(money),就能用这样SQL语句,SELECT SUM(money) FROM safe;
-CRUD:Create, Read, Update, Delete四种操作的首字母缩写,也是程序员对数据库应用最多的操作