

背景
在 v6.0.0 版本,针对悲观事务引入了内存悲观锁的优化(In-memory lock),从压测数据来看,带来的性能提升非常明显(Sysbench 工具压测 oltp_write_only 脚本)。
- Tps 提升 30% 左右
- 减少 Latency 在 15% 左右
TiDB 事务模型从最初的乐观事务到悲观事务;在悲观事务上,又针对悲观锁进行的 ”Pipelined 写入“ 和 ”In-memory lock“ 优化,从功能特性上可以看出演进过程(参考TiDB 事务概览)。
乐观事务
乐观事务在提交时,可能因为并发写造成写写冲突,不同设置会出现以下两种不同的现象:
- 关闭乐观事务重试,事务提交失败:也就是执行 DML 成功(不会被阻塞),但是在执行 commit 时候失败,表现出与 MySQL 等数据库不兼容的行为。
| T1 | T2 | 说明 |
|---|---|---|
| mysql> set session tidb_disable_txn_auto_retry = 1(或者 set session tidb_retry_limit=0;);Query OK, 0 rows affected (0.00 sec) | 关闭重试 | |
| mysql> begin;Query OK, 0 rows affected (0.00 sec) | mysql> begin optimistic;Query OK, 0 rows affected (0.00 sec) | T2开启乐观事务 |
| mysql> delete from t where id = 1;Query OK, 1 row affected (0.00 sec) | ||
| mysql> delete from t where id = 1;Query OK, 1 row affected (0.00 sec) | 语句执行成功,没有被 T1 阻塞,跟 MySQL 行为不兼容 | |
| mysql> commit;Query OK, 0 rows affected (0.00 sec) | T1 提交成功 | |
| mysql> commit;ERROR 9007 (HY000): ...... | T2 提交失败 |
T2 事务提交失败,具体的报错信息如下:
mysql> commit;
ERROR 9007 (HY000): Write conflict, txnStartTS=433599424403603460, conflictStartTS=433599425871872005, conflictCommitTS=433599429279744001, key={tableID=5623, handle=1} primary={tableID=5623, handle=1} [try again later]
- 开启乐观事务重试,自动重试后返回成功,但是因为重试 DML 使用的事务 id(start_ts) 是重新获取的,不是事务开始的事务 id(start_ts),也就是说实际执行结果相当于同一个事务中读和写是使用不同的事务 id(start_ts),执行结果可能跟预期不一致。
| T1 | T2 | 说明 |
|---|---|---|
| mysql> set session tidb_disable_txn_auto_retry = 0;Query OK, 0 rows affected (0.00 sec) | 开启重试 | |
| mysql> set session tidb_retry_limit = 10;Query OK, 0 rows affected (0.00 sec) | 设置最大重试次数 | |
| mysql> begin;Query OK, 0 rows affected (0.00 sec) | mysql> begin optimistic;Query OK, 0 rows affected (0.00 sec) | T2开启乐观事务 |
| mysql> delete from t where id = 1;Query OK, 1 row affected (0.01 sec) | T1 删除 id = 1的记录 | |
| mysql> delete from t where id in (1, 2, 3); Query OK, 1 row affected (0.00 sec) | T2 没有被 T1 阻塞,同样删除了 id = 1 的记录,affected rows 显示为 1. | |
| mysql> insert into t (name, age) values("lihua", 9), ("humei", 8); Query OK, 2 rows affected (0.00 sec)Records: 2 Duplicates: 0 Warnings: 0 | T1 插入两条记录,由于自增 id,两条新纪录的 id 分别为 2 和 3. | |
| mysql> commit;Query OK, 0 rows affected (0.00 sec) | T1 提交,表 t 中只有 id 为 2 和 3 的记录 | |
| mysql> commit;Query OK, 0 rows affected (0.01 sec) | T2 提交成功 | |
| mysql> select id, name, age from t;Empty set (0.01 sec) | mysql> select id, name, age from t;Empty set (0.01 sec) | 表 t 中, id 为 2 和 3 的记录也被删除。 |
这里事务 T2 就涉及到乐观事务重试情况下的两个局限性:
- T2 提示 affected rows 显示为 1 行,删除的是仅有的 id = 1 的记录,但是实际提交时候,删除的是 id 为 2 和 3 的两条记录,实际的 affected rows 是 2 行,参考博客TiDB 新特性漫谈:悲观事务。
- 破坏可重复读的隔离级别,参考下重试的局限性的说明,在使用重试时,要判断好是否会影响业务的正确性。
悲观事务
针对乐观事务存在的问题,悲观事务通过在执行 DML 过程中加悲观锁,来达到与传统数据库的行为:
- 并发执行 DML,对同一行数据进行更改,先执行者会加悲观锁,后执行者被锁阻塞
- 让写冲突按顺序执行,这样可以避免乐观事务在 commit 时遇到冲突后多次重试的问题,使得 commit 顺利完成
悲观事务写入悲观锁,相对乐观事务带来以下开销:
- 悲观锁写入 TiKV,增加了 RPC 调用流程并同步等待悲观锁写入成功,导致 DML 时延增加
- 悲观锁信息会通过 raft 写入多个副本,给 TiKV raftstore、磁盘等带来处理压力
pipelined
针对悲观锁带来的时延增加问题,在 TiKV 层增加了 pipelined 加锁流程优化,优化前后逻辑对比:
- 优化前:满足加锁条件,等待 lock 信息通过 raft 写入多副本成功,通知 TiDB 加锁成功
- pipelined :满足加锁条件,通知 TiDB 加锁成功、异步 lock 信息 raft 写入多副本(两者并发执行)
异步 lock 信息 raft 写入流程后,从用户角度看,悲观锁流程的时延降低了;但是从 TiKV 负载的角度,并没有节省开销。
in-memory
pipelined 优化只是减少了 DML 时延,lock 信息跟优化前一样需要经过 raft 写入多个 region 副本,这个过程会给 raftstore、磁盘带来负载压力。
内存悲观锁针对 lock 信息 raft 写入多副本,做了更进一步优化,总结如下:
- lock 信息只保存在内存中,不用写入磁盘
- lock 信息不用通过 raft 写入多个副本,只要存在于 region leader
- lock 信息写内存,延迟相对于通过 raft 写多副本,延迟极小
从优化逻辑上看,带来的性能提升会有以下几点:
- 减小 DML 时延
- 降低磁盘的使用带宽
- 降低 raftstore CPU 消耗
实现原理
引用下内存悲观锁 RFC In-memory Pessimistic Locks 的介绍:
Here is the general idea:
- Pessimistic locks are written into a region-level lock table.
- Pessimistic locks are sent to other peers before a voluntary leader transfer.
- Pessimistic locks in the source region are sent to the target region before a region merge.
- On splitting a region, pessimistic locks are moved to the corresponding new regions.
- Each region has limited space for in-memory pessimistic locks.
简单理解就是为每个 region 单独维护(只在 leader peer 维护)一个内存 lock table,当出现 region 变动时候例如 Leader transfer、Region merge 会先将 lock table 中的悲观锁通过 raft 同步到其他节点,这个 lock table 有大小限制。
in-memory lock 跟非优化前相比,不会破坏数据一致性,具体的实现细节挺复杂,但是可以简单理解下:
- in-memory 悲观锁正常存在 region leader lock table 情况下
- 对于读写 leader,跟普通悲观锁读写一致
- 对于 follow read,基于 snapshot 读,只有 prewrite lock 会影响读取结果,而 prewrite 的数据是会同步到 follower 的,所以仍然没问题
- in-memory 悲观锁丢失
- 对于 write 操作,事务提交 prewrite 阶段会检查版本冲突,有冲突会因为冲突提交失败,没冲突正常提交
- 对于 read 操作,同上面 follower read,悲观锁不会影响读
锁丢失
in-memory 悲观锁的设计初衷是在收益与付出之间做的权衡:
- 相对于乐观事务,悲观事务加锁,让写冲突按顺序执行,冲突场景下事务提交成功率更高。
- 相对于同步持久化的悲观锁,减少了 TiKV 负载的开销,但是同时会有锁丢失。
锁丢失的原因:in-memory 悲观锁只在 region leader 上维护,这里的锁丢失是指新的 region leader 没有获取到变更前 region 上的悲观锁信息。原因主要是 TiKV 网络隔离或者节点宕机,毕竟对于 region 变更,正常会先通过 raft 将当前 region 的悲观锁同步给其他 region peer。感觉 in-memory 悲观锁比 pipelined 加锁,宕机后锁丢失会更多。
锁丢失的影响(参考Pipelined 加锁流程):
- 事务在 region leader 变更前上的锁,无法阻塞修改相同数据的其他事务。如果业务逻辑依赖加锁或等锁机制,业务逻辑的正确性将受到影响。
- 有较低概率导致事务提交失败,但不会影响事务正确性。
在 pipelined 加锁流程,同样会有悲观锁失效的现象,因为异步写入可能失败,悲观锁没有写成功,但是却通知了上锁成功。
| T1 | T2 | OS CLi |
|---|---|---|
| mysql> begin;Query OK, 0 rows affected (0.00 sec) | mysql> begin;Query OK, 0 rows affected (0.00 sec) | |
| mysql> delete from t where id=1;Query OK, 1 row affected (0.00 sec) | ||
| mysql> delete from t where id=1; | ||
| ...... | kill -9 tikv | |
| Query OK, 1 row affected (19.20 sec) | ||
| mysql> commit;Query OK, 0 rows affected (0.00 sec) | ||
| mysql> commit;ERROR 1105 (HY000) |
事务 T1 提交失败,详细报错信息如下:
mysql> commit;
ERROR 1105 (HY000): tikv aborts txn: Error(Txn(Error(Mvcc(Error(PessimisticLockNotFound { start_ts: TimeStamp(433149465930498050), key: [116, 128, 0, 0, 0, 0, 0, 1, 202, 95, 114, 128, 0, 0, 0, 0, 0, 0, 1] })))))
这里事务 T1 先加锁成功,事务 T2 被阻塞,kill tikv 导致 leader transfer,新的 leader 没有事务 T1 的悲观锁信息,然后事务 T2 被解除阻塞,并提交成功。事务 T1 提交失败,但不会影响数据的一致性。
所以如果业务中依赖这种加锁机制,可能导致业务正确性受影响。如下使用场景:
mysql> begin;
mysql> insert into tb values(...) 或者 select 1 from tb where id=1 for update;
...加锁成功...
...业务依赖以上加锁成功做业务选择...
...在锁丢失场景可能多个事务都能加锁成功导致出现不符合业务预期的行为...
mysql> commit;
如果对于成功率和事务过程中执行返回结果有强需求或者依赖的业务,可选择关闭内存锁(以及 pipelined 写入)模式。
开启 in-memory
TiKV 配置文件:
[pessimistic-txn]
pipelined = true
in-memory = true
只有 pipelined 和 in-memory 同时打开才能开启内存悲观锁。
可以在线动态开启、关闭:
> set config tikv pessimistic-txn.pipelined='true';
> set config tikv pessimistic-txn.in-memory='true';
Grafana 查看 in-memory lock 的写入情况,在 {clusterName}-TiKV-Details->Pessimistic Locking 标签下:
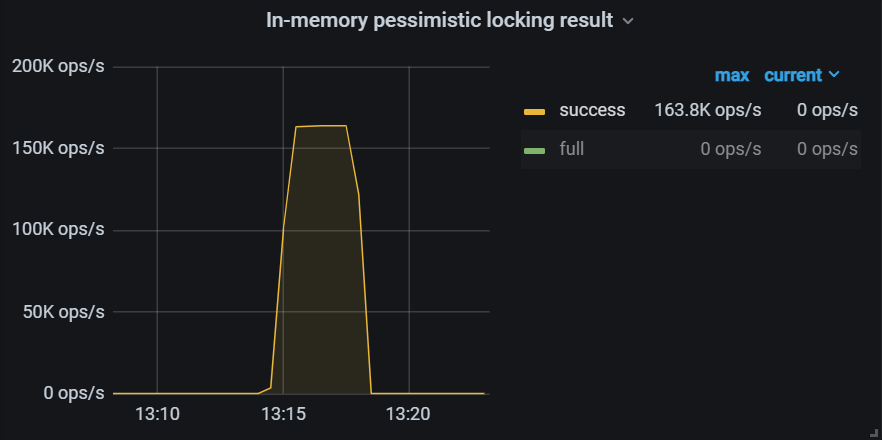
内存限制
每个 region 的 in-memory 锁内存固定限制为 512 KiB,如果当前 region 悲观锁内存达到限制,新的悲观锁写入将回退到 pipelined 加锁流程(在典型 TP 场景下,很少会超过这个限制)。
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update sbtest1 set k=k+1 limit 10000000;
Query OK, 10000000 rows affected (3.26 sec)
Rows matched: 10000000 Changed: 10000000 Warnings: 0

由于大量悲观锁写入,悲观锁内存达到限制值,监控中 full 值大量出现。
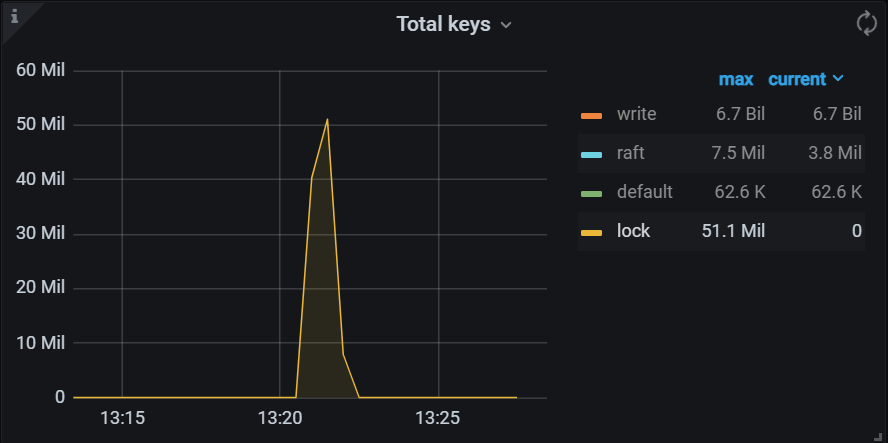
回退到 pipelined 写入流程,通过 raft 写入多副本,Rockdb 的 lock CF 出现 lock 信息,在 {clusterName}-TiKV-Details->RocksDB - kv 标签下。
性能测试
对乐观锁、悲观锁、pipelined 写入、in-memory lock 进行压力测试。
| 类型 | cpu | 内存 | 磁盘 | 网卡 | NUMA | 节点数 | 机器数 |
|---|---|---|---|---|---|---|---|
| TiKV | 96线程 | 384G | 2 * 2.9T NVME | 40000Mb/s | 2 node | 6 | 3 |
TiKV 部署:在每块 NEME 盘上部署一个 TIKV 节点,分别绑定一个 NUMA node,单台机器 2 个 TiKV 节点,配置参数如下(变动的参数只跟压测的事务类型有关)。
server_configs:
tikv:
pessimistic-txn.in-memory: true
pessimistic-txn.pipelined: true
raftdb.max-background-jobs: 6
raftstore.apply-pool-size: 6
raftstore.store-pool-size: 6
readpool.coprocessor.use-unified-pool: true
readpool.storage.normal-concurrency: 16
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 38
readpool.unified.min-thread-count: 5
rocksdb.max-background-jobs: 8
server.grpc-concurrency: 10
storage.block-cache.capacity: 90G
storage.scheduler-worker-pool-size: 12
TiDB、pd 独立部署,均为高配置服务器,其中 TiDB 节点足够多,能使压测性能瓶颈集中在 TiKV 上,使用 LVS DR 模式做负载均衡。
测试工具 sysbench,压测脚本 oltp_write_only,64 张表,1000w 数据,直观比较各种模式下性能差异。
压测结果 TPS:

压测结果 Latency:

从压测结果上来看:
- 性能排行从高到底:in-memory > optimistic > pipelined > pessimistic
- 在压测线程较小时,in-memory 和 optimistic 性能接近,等到并发增大,可能是 optimistic 事务冲突重试的原因导致 in-memory 后来居上
- 随着并发数增大,TiKV 磁盘 iops、带宽很快增长,pessimistic 和 pipelined 磁盘负载较早出现压力,后面时延增加较快,对应 TPS 增长相对缓慢
- 当接近 TiKV 磁盘性能瓶颈时,in-memory 和 optimistic 能支撑集群更大的 TPS。
悲观锁优化
对比下 in-memory、pipelined 两个特性,对于悲观锁的性能提升。

TPS 提升:
- in-memory 提升明显,始终维持在一个较高值 35% 以上
- 同并发下 Latency 减少,对应 TPS 增长
- 高并发下,减少磁盘 io 压力、减少了 raftstore 压力
- pipelined 提升在 10% 左右,在较小并发时异步写入 Latency 减少,支撑了较大的 TPS 提升;当磁盘压力增大,慢慢出现性能瓶颈,提升越来越小。
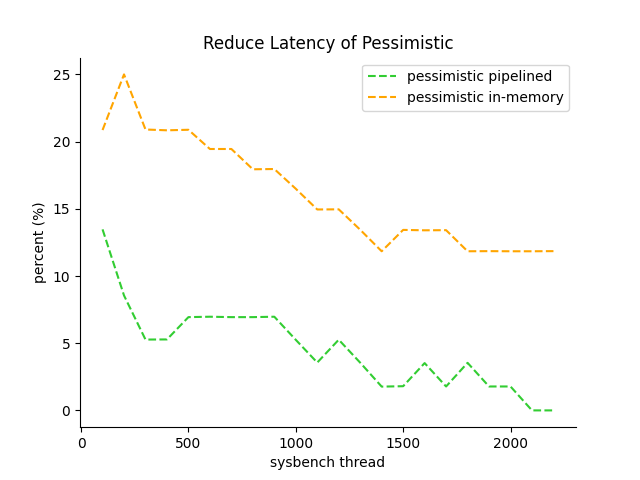
减少 Latency:
- 在并发小时,时延提升明显,分别能到到 20%、10% 的提升。
- 在并发增大后,磁盘出现较大压力,由于时延增加太大,总提升越来越不明显
- in-memory 维持在 10% 以上
- pipelined 降到 5% 以下
总结
从压测数据来看,v6.0.0 版本的内存悲观锁是非常有吸引力的新特性。
通过减少 DML 时延、避免悲观锁 raft 写入多副本、减少 raftstore 处理压力以及磁盘带宽,能达到可观的写入性能提升:
- Tps 提升 30% 上下
- 减少 Latency 在 15% 上下
在内存悲观锁的使用中,要注意锁丢失问题,如果影响业务的正确性逻辑,应关闭 in-memory lock 与 pipelined 写入这两个悲观事务特性。
参考
官方文档:内存悲观锁
内存悲观锁 RFC In-memory Pessimistic Locks
Tracking Issue: In-memory Pessimistic Locks