

数据一致性是在一个需要容错的分布式系统中提出的概念。这里的一致性我们要特别搞清楚,主要有以下两层含义:
- Raft系统中所有节点的数据状态最终一致
- Raft系统中大部分节点的日志状态实时一致
一直以来一致性算法都是一个高深莫测的领域,特别是一致性算法的鼻祖Paxos,以复杂难懂而著称! 然而在耐心研读了raft的Paper以后,发现这一领域也并不是那么神秘。首先我想说raft的Paper质量非常好好!它不仅阐述了复杂的一致性算法,而且展示了一种解释复杂问题的方法。它深刻吸取Paxo抽象难懂的教训,在Paper中特别强调了Understandable! 嗯,Understandable, 作者是认真的。 为了证实Raft更容易理解和掌握,作者专门组织了一帮大学学生,分为两组,分别学习Raft和Paxos, 然后对学员的掌握情况进行测试,测试结果也以论文形式发出。真是下了不少功夫啊!
这里简单梳理一下Raft Paper中的框架内容,若要全面了解raft协议,强烈建议读原Paper.
一、Raft协议中规定了两种存储
- Log
为保证读写效率,raft采用了先写日志的原则。一个日志条目包含了对状态机中数据的操作。日志的写入是顺序的,效率较高。 Raft的Leader收到一个操作请求,首先将其append到自己的日志,然后将其广播到集群,大多数节点收到这个日志并Append, 这个日志就是确定可以Commit了。 Leader将这个日志操作在状态机中执行,这样就完成了。 - Replicated state machine
复制状态机中保存的是实际的客户数据,数据的读取都需要从状态机中读。因此Leader在返回给Client成功时,数据一定要写入状态机,不然会造成Client读取不到最新数据。
二、Raft规定一个节点的三种角色
- Leader
Leader是服务客户端的唯一server。 Leader要不断地向Follower发送心跳包还确保自己的Leader地位。 - Candidate
Candidate是一个临时角色,一般来讲,任何一个节点都不会长时间处于这样一种角色。它是由Follower节点转换来的。即当一个Follower节点在一定时间(Election timeout)没有收到Leader的心跳包,这个Follower就会转换为Candidate,发起投票选举自己为Leader, 如果它能获取到多数投票,它就会成为下一个任期(term)的Leader. 若不能,则有两种情况: 继续投票或转换角色为Follower. - Follower
Follower角色接受Leader的日志复制,负责高可用。当Leader挂掉时,其中最先Election timeout 的follower会变为Candidate, 发起投票选举自己为leader. 这里的Election timeout是一个时间范围内的随机值(Raft Paper建议150ms - 300ms.),这样确保不会一直有两个Candidate同时选举。 在TiKV中Election timeout是10s(如果处于无主状态,大约经过 raft-base-tick-interval default 1s * raft-election-timeout-ticks default 10 时间以后发起选举)
三、Raft协议使用三种RPC来广播信息
- AppendEntries RPC
Leader使用AppendEntries RPC来复制日志记录给其它Followers, 当然心跳包就是一个没有日志记录的 AppendEntries RPC。 - RequestVote RPC
Candidate发送RequestVote RPC来发起选举。 - InstallSnapshot RPC
当一个Follower角色落后Leader太多时,会使用InstallSnapshot RPC 来使其快速补充数据。任何一个节点都会做日志定期快照。可以参照Redis的Log Rewrite来理解这里的snapshot.
四、Raft协议四大主要活动
-
Leader election
集群中的Server从Follower角色开始,在经历Election Timeout周期没有收到Leader的心跳时,该Server会转换角色为Candidate, 将自己的任期加1, 投自己一票,并发送RequestVote RPC向集群中的其它Server发起投票。如果它能够获得大多数投票,它就会当选为Leader。当然这里面涉及到许多细节,这里不详细阐述。 Leader election活动在Raft系统中发生的并不频繁。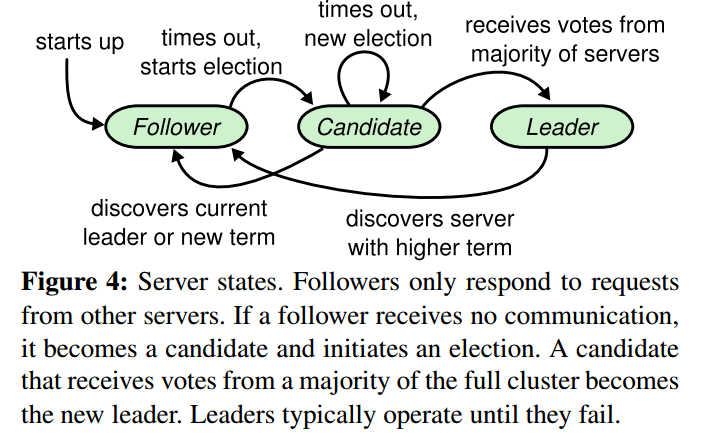
-
Log replication/heartbeat
Leader响应客户端请求,Client的每一个请求都是对状态机数据的修改。Leader收到请求后,首先将该命令Append到自己的日志中,然后发送AppendEntry RPC (Heartbeat也是AppendEntry RPC包,只是里面没有日志) 向集群中的其它节点广播这一操作,当大多数节点收到这一日志时,Leader就将该日志在状态机中应用(commit), 成功应用后才返回给Client成功。如果某个节点没有反馈成功收到这一日志,Leader会持续不断地向其广播,即使该日志已经成功Commit也不会停止,直到其收到为止。当然Raft采取了许多措施来保证日志的完整性和一致性。 Log Replication是Raft系统中最频繁的活动,它开始于Raft系统启动,终止与整个系统停止。 -
Membership change
理解Raft成员变更可以参考MySQL MGR中的View & ViewChanges. 当集群中某个节点宕机或者添加新的节点到集群时,会触发Membership change. Raft采用Joint Consensus机制来保证平滑过渡,并且不影响对Client请求的处理。这一活动在Raft系统中也不常见。 -
Log compaction
Log不能无限增长。Raft会定期对日志做快照(snapshot),这一操作与Redis中的Log Rewrite类似(如下图)。在实际的实现中,庞大的数据集可能会使日志占有巨大空间,即使经过压缩后,日志量还是很大,还应实现定时清理机制。TiKV中通过一些参数(如:raft-log-gc-size-limit)设定来控制Raft Log的残余量,超过这一设置会被清理以节省空间。
五、总结
简单来看,上述几个部分包含了Raft协议的主要内容。希望对了解Raft概貌有些帮助。对细节的阐述往往使问题变得复杂,学习新鲜事物时,我们可以先从全局来看其全貌,将其拆解为几大模块,然后再分别详细研究各个模块的细节,等了解了细节,再从全局来看各各模块之间的关系,直到彻底了解整个系统。