

1.实验环境:
- A 机房: 2个 pd , B 机房: 1 个pd
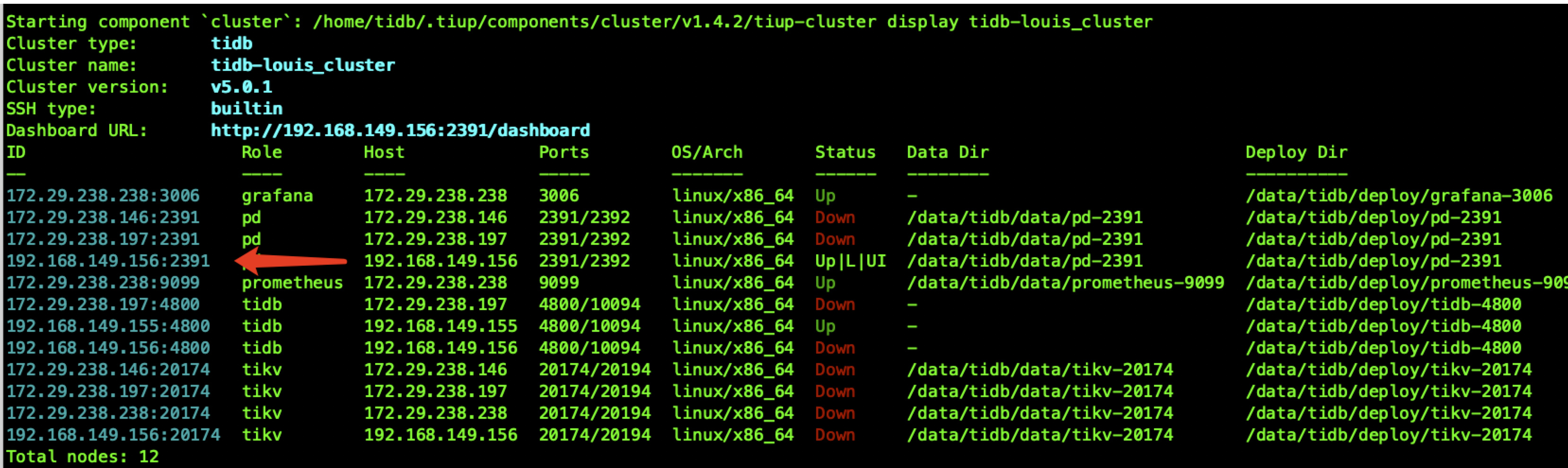
- 将三个pd 节点其中两个kill 掉(模拟A 机房挂掉),然后删除数据目录, 使用剩下的一个pd-server 通过pd-recover 来恢复服务
2.实验流程:
故障后的状态如下图
a.使用tiup下载pd-recover 软件
(这部分具体可参考官方文档https://docs.pingcap.com/zh/tidb/stable/pd-recover)
$ tiup install pd-recover
b.获取cluster-id & idAllocator
$ cd /data/tidb/deploy/pd-2391/log
[tidb@db-redis-149-156 log]$ cat pd.log |grep "init cluster"
[2021/06/16 21:17:28.592 +08:00] [INFO] [server.go:352] ["init cluster id"] [cluster-id=6940974019094123759]
– 去每个pd 日志目录下获取 idallocator
cat {{/path/to}}/pd*.log | grep "idAllocator allocates a new id" | awk -F'=' '{print $2}' | awk -F']' '{print $1}' | sort -r | head -n 1
c.停止旧的pd 集群的数据目录(包括还存活的那个pd 节点)
$ cd /data/tidb/data && rm -rf pd-2391
e.创建新的集群
- 模拟的情况是A机房挂了,此处假设在B 机房有相同的tiup 备份数据
- 重新启动pd 节点: tiup cluster start tidb-louis_cluster -N 192.168.149.156:2391
f.使用pd-recover
[tidb@db-redis-149-156 ~]$ tiup pd-recover -endpoints http://192.168.149.156:2391 -cluster-id 6940974019094123759 -alloc-id 27000
Starting component `pd-recover`: /home/tidb/.tiup/components/pd-recover/v5.0.2/pd-recover -endpoints http://192.168.149.156:2391 -cluster-id 6940974019094123759 -alloc-id 27000
recover success! please restart the PD cluster
g.强制删除故障的两个节点
tiup cluster scale-in tidb-louis_cluster -N 172.29.238.197:2391 --force
k.重启整个集群
tiup cluster restart tidb-louis_cluster
此时集群使用一个pd 节点提供服务
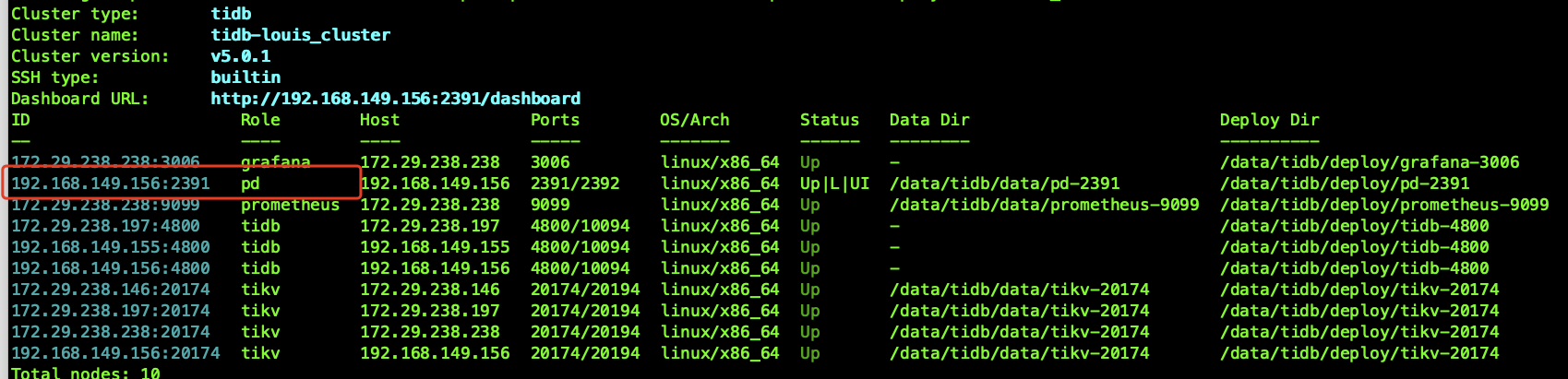
此处只是模拟两个pd 节点故障的恢复场景,最终目的是 在A 机房挂掉后,使用pd-recover 恢复pd 服务,
使用tikv-clt 强制恢复剩下的一个tikv 节点对外提供服务,后续整体的测试流程完善后再上传。