

本人博客原文地址:https://blog.csdn.net/qq_22351805/article/details/114987229
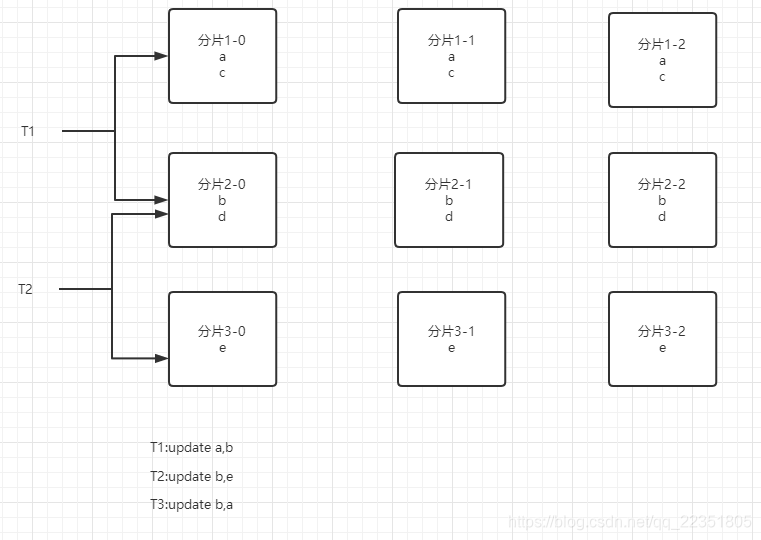
在进入正题之前,先来思考下跨节点的数据如何实现同进退(ACID),如果对分布式事务本身有一定了解可跳过这里。如图:
假设单机数据库的容量受限,需要将其中的数据(abcde,表示五条记录,不一定在同一张表)分散到不同分片1(ac)、2(bd)、3(e) ,各个分片可能分布到不同的节点,以达到扩展容量的目的。仅仅扩展容量是不够的,如果每个分片只有单个节点有数据,单点故障时,将出现数据丢失的风险,因此需要每个分片都有多个副本如(分片1-0,分片1-1,分片1-2)分散到不同的节点,并且通过一致性算法(raft,paxos)保证多个副本的数据一致。
现在来考虑同时对跨分片的数据读写事务操作:
T1: update a,b;
T2: update b,e;
T3: update b,a;
在单机数据库里,对于一条记录,会有集中的地方管理锁信息“如MySQL: innodb_row_lock”,事务提交时很容易检测到其是否已经被加锁了。但当某个事物的多条记录分布在不同节点,事情就变得不一样,假设每个节点都各自存储了自身所含所有记录的锁信息,那么当事务T1,更新记录a和b时,就要分别对这两条记录上锁,由于锁信息跨节点,因此就必须考虑如何确认跨节点记录是否被上锁和如何抢占锁的问题。
在单机数据库中,分乐观锁和悲观锁,这里可以参考一下:(假设a记录已上锁)
乐观锁:在向跨节点的b记录上锁时,不管b是否已经被上锁,直接请求加锁,如果锁已存在则回滚事务,然后重新从a开始事务。
悲观锁:在向跨节点的b记录上锁时,先询问b是否已经被上锁,当b所在节点反馈不存在b记录的锁时,则请求对b加锁,否则进入等待。
那么问题来了,乐观锁方案中,如果b更新频繁,那么该事务回滚重试的概率大大增加,严重影响效率。悲观锁方案中,在询问得到反馈b没有上锁的过程中,很可能其他的事务在这个时间差内给b加了锁,如何保证询问结果反馈过程中,其他事务不能抢占(考虑是不是可以将跨节点的锁信息汇总到某一处,避免两阶段确认?),另外当出现T1和T3两个事务并发执行,悲观事务下出现了死锁问题该怎么解决(T1占有a的锁,等待b的锁,T3占有b的锁,等待a的锁)。
既然有锁,那就不可避免得讨论MVCC的问题,如何在有锁的情况下,实现跨节点数据的高效访问,假设像MySQL一样使用readview,得如何参考(统一的地方保存readview?每个节点各自保存readview?),还是有其他更好的方式。同时,事务隔离级别能得到何种程度的实现,能否四种隔离级别都能实现。最后,当锁等待超时,如何清理锁,MVCC版本控制,过期版本的数据如何清理?
以上的疑问,写到这里可能还没有答案,带着这些疑问,来看看tidb如何应用percolator实现分布式事务。
@TOC
一、percolator概览
首先大概说下背景,谷歌搜索基于其倒序索引系统,谷歌采用map-reduce设计了一个批量创建索引的系统,解决海量数据索引创建的问题,但该系统并不擅长处理分布式海量索引数据实时更新。该系统存在问题我们目前并不是很了解,但是该问题有了一个指向:能否有一个支撑大量分布式数据,支持并发访问,支持跨节点数据实时事务更新的分布式数据库。这也是我们上面问题的解决方向。
1、percolator数据结构
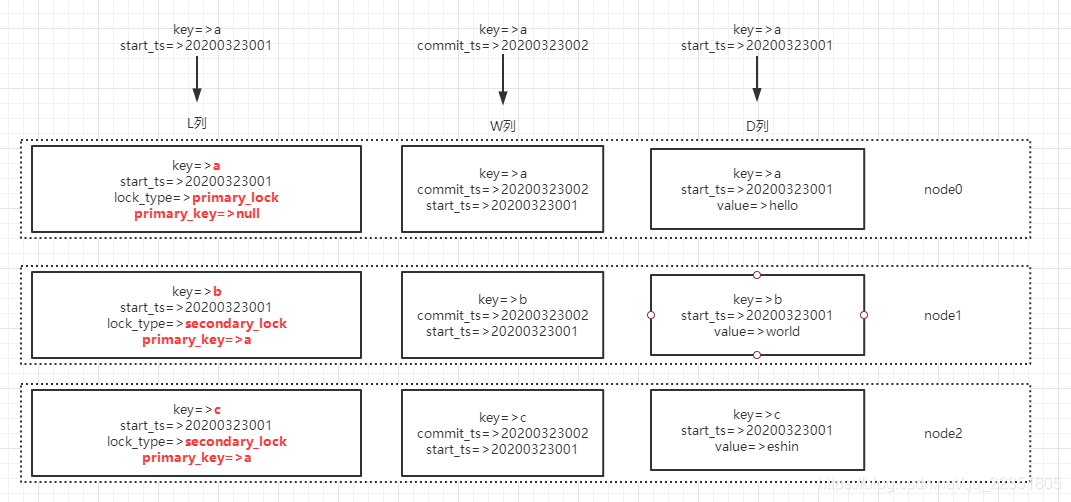
Percolator 在 Bigtable 上抽象了 5 Columns 去存储数据,其中有 3 和事务相关:
c:lock (后文中简称L列):
事务产生的锁,映射关系为${key,start_ts}=>${lock_type,primary_key,…etc}
- key:数据的key
- start_ts:事务开始时间(分布式系统需要能提供全局唯一的时间戳,用来保证事务不冲突)
- lock_type:事务执行时,会从所有执行写操作的行中随机选一行作为primary,lock_type赋值为:primary_lock,其与的行lock_type赋值为secondary_lock。
- primary_key:当lock_type为secondary_lock时,该值指向primary行。
c:write(后文中简称W列)
已提交的数据信息,存储数据所对应的时间戳,映射关系为
${key,commit_ts}=>${start_ts}
- key :数据的key;
- commit_ts: 事务的提交时间(同样需要提供全局唯一的时间戳)
- start_ts:该事务开始时间,通过这个时间+key,可以从c:data列找到对应的数据
c:data(后文中简称D列)
具体存储的数据,映射关系为:
${key,start_ts} => ${value}
- key: 真实的key
- start_ts : 对应事务的开始时间
- value: 真实的数据值
大致看下数据组织形式:
2、Percolator 事务流程
2.1、写操作流程
写流程分两个阶段(两阶段提交):prewrite与commit两个阶段
2.1.1、prewrite阶段
-
事务T开始,从全局时间授权模块(Timestamp Oracle(TSO))获取start_ts,在所有需要写操作的行中选一个作为primary,其他的均为secondary。
-
对primary行写入L列。即上锁,上锁前会检查是否有冲突:
- 该行已有其他客户端(session)上锁(primary_lock或secondary_lock)
- 该行最新W列的commit_ts>当前事务T的start_ts(说明当前事务开始后,有其他的事务先提交了对改行的修改)
当出现以上两种情况时,说明发生冲突,上锁失败,回退当前事务。否则上锁成功,当前事务写入L列(key=>T.key,start_ts=>T.start_ts,lock_type=>primary_lock,primary_key=>null。因为改行本身就是primary行,因此primary行指向null)
-
上锁成功后,写入D列更新即新版本的数据,以start_ts为版本号。由于当前数据未提交,D列对外不可见。(不可见的意思就是没有写W列,客户端查询通过W列查找版本号)
-
primary行上锁流程结束后,开始secondary行的prewrite流程,流程与primary行上锁流程相似,但是锁类型不一样,且锁的内容会多出对primary行的指向(lock_type=>secondary_lock,primary_key=>primary_key)
-
prewrite流程任何一步发生错误,都会回滚,删除新加的L列和新加的D列。
由上流程可以看出,数据的写入(写D列)是在prewrite流程完成,为什么在prewrite阶段就写了数据呢?为何不在commit阶段写?别急,继续往下看。
2.1.2、commit阶段
- commit阶段开始时,从全局时间授权模块获取commit_ts,commit_ts>start_ts.
- commit primary行,写入对应的W列数据(key,commit_ts,start_ts)表明版本号start_ts对应的数据已提交。
- 删除primary行的L列
- 如果primary行提交失败,整个事务回滚,删除新加的L列和新加的D列。如果primary行提交成功,则可异步提交其余的secondary行,secondary行的提交失败了也无所谓。
这里就可以看出,在primary行commit成功后(写入W列,删除L列),secondary行的commit就可以异步提交了,即便异步commit secondary行阶段发生异常(或者下次访问时还没来得及)没有清理锁,没有W列也没有关系,可以在下次读写的时候,根据secondary行的L列信息找到primary行(通过primary_key+start_ts)判断是否已经提交该事务(因此需要先写W列再删L列,如果primary行存在L列,说明事务还未提交,如果不存在L列,但存在对应W列,说明事务已提交,如果primary行同时不存在对应L列和W列,说明该事务回滚了)。
如果在commit阶段写入D列数据,假设是一行一行的提交并删除L列,那么肯定会出现部分可见部分不可见的情况,比如primary行commit了,写了D列并可见,其余的行还没有写入D列,就没法通过检测primary行commit的情况,来判断其余行的数据的可见性了额,因为没有D列的数据。那么这种方式就得等所有行的D列都写入后才能开始删锁向客户端响应事务状态,这样的话,就大大增加了这一部分数据加锁的时间了,同时也可能因为网络原因只有部分行完成了commit响应导致事务超时。
这里埋一个疑问,如果primary行的数据提交后被删除了,没有及时清理锁的secondary行该如何确定自身是否需要提交呢?
以上流程每行出现的L列、W列、D列,都会通过一致性算法(raft)复制多个副本到多个节点。
2.2、读操作流程
两阶段提交,prewrite写D列,但不可见,commit阶段写W列后可见,W列表示一个可见性,另一个类似于索引。当下一个事务T2读写查询时,将进行如下流程:
- 检查该行在T2.start_ts 这个时间点之前是否有L列,如果有则等待解锁,或者等待超时尝试清除。不可绕过L列直接访问W列查找更老版本start_ts_old的数据,否则产生幻读(该L列对应的版本提交后,T2.start_ts与start_ts_old之间就有多一个版本的数据)
- 该行不存在锁时,读取至T2.start_ts的最新数据,从start_ts开始倒序查找W列,找到对应的列中的start_ts,通过该值从D列找到对应的数据。
二、MVCC版本控制与锁清除、过期版本数据清除
1、TiDB的MVCC
由上面的内容可知,在某一行的W列中,包含一个commit_ts,一个start_ts。前者是数据真正对外可见的标志,后者是写入该数据的事务开始时间。两者都是全局唯一,均可作为当期数据的版本号,但以可用性来讲,用commit_ts作为版本号更为直接。
当系统运行一段时间,某行数据经历Tn次事务更新,在没有清除历史版本数据的情况下,就有Tn个版本的D列和W列,此时如果有第Tn+1事务开始读该行,开始时间为Tn+1.start_ts。
假设Tn.commit_ts <Tn+1.start_ts,那么Tn版本的数据对于Tn+1是可见的,同时(Tn.commit_ts Tn+1.start_ts]这个时间段内,该行不能有L列,否则Tn+1对该行的读将会阻塞,以防产生幻读。但是如果L列出现在(Tn+1.start_ts,+∞)时间段则不阻塞读。通过该机制很容易实现对历史版本数据的访问。
总的来说就是,新写入的数据不会覆盖旧的数据,而且通过版本号来区分版本,即便是delete或者truncate操作,数据也不会马上清除,而是等待GC的任务执行来清理。
2、锁清除与过期版本数据清除
TiDB本身包含GC机制用来清理历史数据(默认配置下,GC 每 10 分钟触发一次,每次 GC 会保留最近 10 分钟内的数据)。流程如下:
- 计算safe point时间点(如何计算?每行记录safe point不一样?)
- 清理锁,首先对于primary_lock,如果鉴定超时,则直接删除并且回滚对应事务,其次secondary_lock, 如果对应的primary行已提交,对secondary_lock对应的行也应该提交,否则回滚;如果 Primary 仍然是上锁的状态(没有提交也没有回滚),则应当将该事务视为超时失败而回滚。
这里回到上面的问题,如果secondary_lock找不到primary行怎么办;是否可认为primary行因回滚而删除而不是因为GC而被删除?这里需要明确的是,需要清理的都是位于上一次safepoint和此次safepoint之间的版本数据。因此需要先清理锁,保证secondary_lock能够找到primary行,这样的话,只要找不到primary行就可以认为该secondary_lock对应的事务回滚了。 - 进行GC清理。删除所有Key在safePoint之前的数据(每个 key 保留 safe point 前的最后一次写入,除非最后一次写入是删除),对于drop和truncate的大量连续数据删除,将通过连续区间删除的方式。
(v2.1以前GC是对每一个region操作,v3.0之后,只对region leader 操作GC)
三、乐观事务与悲观事务
在TiDB 新特性漫谈:悲观事务一文中,作者用了一个比方:去餐厅吃饭,来说明乐观事务和悲观事务:
乐观事务: 不管有没有位,直接去餐厅,去到要是没有位子就回来。
悲观事务: 先电联餐厅确定有没有位置,预订位置,然后再去。
如果餐厅的位置很多(冲突率低),那么直接去餐厅有座的概率就高,但是一旦每座就要白跑一趟;加入餐厅经常人满为患,直接去大概率就是要白跑一趟,这种情况下,打电话提前问下没有座位,然后支付定金预定代价更低。
这也引申出两种事务模型的适用场景:对于并发事务冲突率高的场景(某部分数据频繁修改)的场景。悲观事务控制可以避免因冲突而回滚的问题,但在冲突率比较低的场景,悲观事务比乐观事务性能要差。
1、乐观事务
percolator本身就是基于乐观事务模型的实现,来看下我从TiDB官网偷来的图:
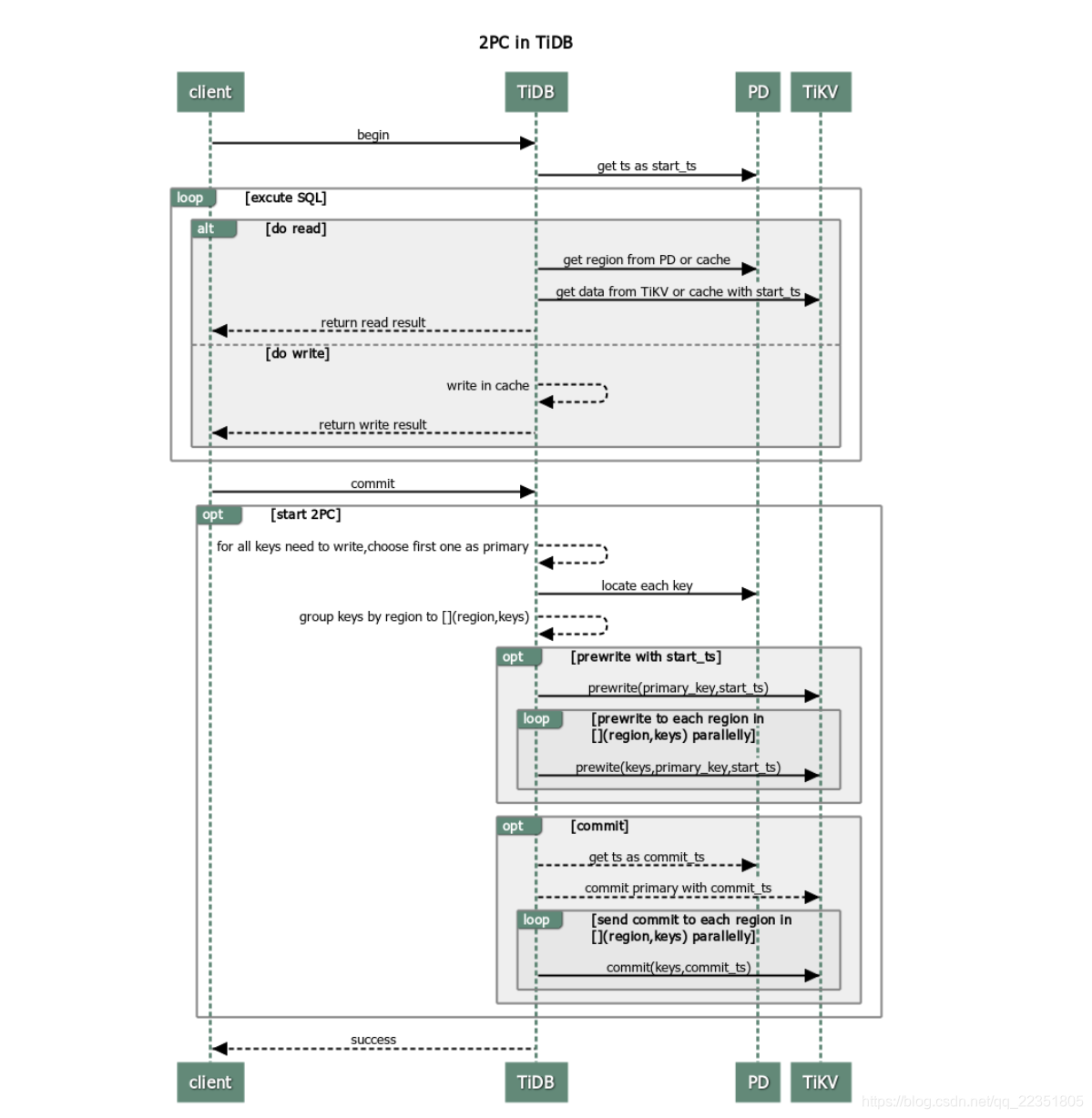
由第一章可知道percolator通过两阶段提交保证事务原子性(prewrite和commit两个阶段),在传统的2PC概念里,需要有一个专门的协调者(事务管理者)来记录事务状态,协调者如若宕机,事务的状态将得不到保证。然而在percolator中弱化了这一概念,取而代之的是通过L列和W列来标志事务的状态(参考第一章中为何可以异步提交secondary行)。
1.1、 percolator的prewrite阶段主要做了两件事,写数据(写D列,但是没有W列,对外不可见)和加锁(写L列),这也是会出现冲突的阶段。
-
首先在TIDB-server中,会先对落在同一个TIDB-server执行的不同事务进行冲突检测,如有冲突将不会再tikv中开始percolator的两阶段提交。但是TiDB-Server无法感知到其他TiDB-Server的检测情况,所以分布在其他TiDB-Server执行的事务检测冲突就得到tikv中判断了。当然也可以关闭TiDB-Server的冲突检测,全部在tikv层检测。
-
写写冲突:写写冲突存在两种情况:1、事务T1与事务T2,同时写某行时,T2先写了L列,T1此时会检测到冲突执行回滚;2、在T1获取start_ts1后到发起prewrite这段时间内,T2迅速获取start_ts2占有锁,并执行完两阶段提交,此时会存在最新W列的commit_ts>T1.start_ts1,此时也会回滚。
-
读写冲突:事务T获取到start_ts,开始查询[0,start_ts]期间的最新数据,结果发现这个期间存在L列,此时发生读写冲突。
对于读写冲突,可以参考第一章2.2中有说到如何解决。而对于写写冲突,在乐观事务模型中无法避免,可通过合并小事务,减少不同事务间的发生冲突的几率,但是事务不能过大,大事务容易导致OOM问题,同时数据准备时间长跟其他事务发生冲突的几率也会增大,同时事务提交的时间也增大。官方建议100-500行之间一个事务,但是具体得根据业务特性,比如插入远远多于更新的业务系统,该值可以考虑加大。
1.2、在commit阶段,也做了两件事,让数据对外可见(写W列),删除L列。
这个阶段容易出现锁超时或者因为网络问题导致锁残留的问题。但只要保证primary行完成提交,事务就可以任务提交完成,否则整个事务回退。(可参考第二章锁清除的内容)
乐观事务模型中,在高冲突率的场景,事务很容易提交失败。TiDB 乐观事务提供了重试机制,但tidb默认不重试事务,重试时将重新获取start_ts,必将导致无法保证可重复读。为解决高冲突场景重试的问题,在tidb v3.0之后的版本中,实现了悲观事务,并从v3.0.8 开始,新创建的 TiDB 集群默认使用悲观事务模型。
2、悲观事务
如果要解决percolator的prewrite阶段的锁冲突导致的回滚问题,那么就要开始两阶段提交前就要先检测锁冲突的情况。但是TIDB是个分布式系统,即便同一个tidb-server上的不同事务可以检测锁冲突,但是不同的tidb-server上的不同事务之间,就要有一个共同的地方保存锁信息共享锁信息。事实上TIDB也是这么做的。我又偷了一张官网的图:

TiDB的悲观事务是在乐观事务的基础上改过来的,可以看出跟乐观事务不同是上图红圈的部分,即开始2PC之前就进行锁冲突检测。
由图可以看出,TIDB将锁存储在tikv中以便所有的TIDB-server共享,并通过raft算法将锁内容复制到多个节点防止单点故障。
在悲观事务下,在percolator的prewrite阶段将不会出现写写冲突,但是依然存在读写冲突的情况。
写请求遇到悲观锁时,等待解锁或者锁超时即可。但是并发事务请求锁资源时,可能存在死锁情况,比如T1: update a,b;T3: update b,a;T1经过sql解析后,向tikv写入a行的锁,同时T2向tikv写入了b行的锁,此时T1/T2相互等待对方释放锁,出现了死锁的情况。
在乐观事务中,经过tidb-server 的解析,在prewrite阶段遇到锁冲突会回滚重试(锁超时时间很短),这个方式避免了死锁。
在悲观事务中需要能够检测并发的不同事务之间是否有循环依赖的关系存在,并在检测到循环依赖时(从tikv存储的锁信息中,很容易判断不同事务之间是否存在循环依赖的锁关系)提供仲裁,中止其中一个事务或让其重试(因其还没进入2PC阶段,因此代价很低)。TIDB的死锁检测机制是异步进行的,不影响正常写锁和后续流程进行,因此对不存在死锁的事务不会产生延迟。
悲观事务下,与MySQLinnodb的部分差异,这部分内容跟本文的原理内容关系不大,仅做汇总记录用。
- 有些 WHERE 子句中使用了 range,TiDB 在执行这类 DML 语句和 SELECT FOR UPDATE 语句时,不会阻塞 range 内并发的 DML 语句的执行。
举例:
CREATE TABLE t1 (
id INT NOT NULL PRIMARY KEY,
pad1 VARCHAR(100)
);
INSERT INTO t1 (id) VALUES (1),(5),(10);
BEGIN /*T! PESSIMISTIC */;
SELECT * FROM t1 WHERE id BETWEEN 1 AND 10 FOR UPDATE;
BEGIN /*T! PESSIMISTIC */;
INSERT INTO t1 (id) VALUES (6); – 仅 MySQL 中出现阻塞。
UPDATE t1 SET pad1=‘new value’ WHERE id = 5; – MySQL 和 TiDB 处于等待阻塞状态。
产生这一行为是因为 TiDB 当前不支持 gap locking(间隙锁)。- TiDB 不支持 SELECT LOCK IN SHARE MODE,使用这个语句执行的时候,效果和没有加锁是一样的,不会阻塞其他事务的读写。
- DDL 可能会导致悲观事务提交失败。MySQL 在执行 DDL 语句时,会被正在执行的事务阻塞住,而在 TiDB 中 DDL 操作会成功,造成悲观事务提交失败。(说明TiDB 没有实现类似MySQL的 MDL机制)
- START TRANSACTION WITH CONSISTENT SNAPSHOT 之后,MySQL 仍然可以读取到之后在其他事务创建的表,而 TiDB 不能。
四、事务隔离级别
1、可重复读
TiDB 实现了快照隔离 (Snapshot Isolation, SI) 级别的一致性。为与 MySQL 保持一致,又称其为“可重复读”。TiDB的事务隔离级别也是通过MVCC检测版本可见性。
- 只能读到该事务启动时已经提交的其他事务修改的数据
- 未提交的数据或在事务启动后其他事务提交的数据是不可见的
- 处于可重复读隔离级别的事务不能并发的更新同一行,当事务提交时发现该行在该事务启动后,已经被另一个已提交的事务更新过,那么该事务会回滚(因当前事务的start_ts < 最新已提交事务的commit_ts。)
此处与MySQL不同,MySQL在可重复读隔离级别下,并发的两个不同的事务生成的不同readview是可以更新同一条记录的。MySQL的可重复读隔离级别针对的是快照读,而对于update,select for update此类当前读并不隔离。因此MySQL可重复读的一致性要弱于TiDB。
2、读已提交
从 TiDB v4.0.0-beta 版本开始,TiDB 支持使用 Read Committed 隔离级别。read Committed 隔离级别仅在悲观事务模式下生效。在乐观事务模式下设置事务隔离级别为 Read Committed 将不会生效,事务将仍旧使用可重复读隔离级别。
(这里暂时还没搞明白为何乐观事务模式下设置事务隔离级别为 Read Committed 将不会生效)
参考
Percolator 论文笔记
经典论文翻译导读之《Large-scale Incremental Processing Using Distributed Transactions and Notifications》
Percolator分布式事务模型原理与应用
Percolator 和 TiDB 事务算法
TiDB 锁冲突问题处理
TiKV 的 MVCC(Multi-Version Concurrency Control)机制
GC 机制
TiDB 乐观事务模型
TiDB 乐观事务原理与实践
TiDB乐观事务
乐观事务模型下写写冲突问题排查
TiDB 4.0 新特性前瞻(二)白话“悲观锁”
TiDB 悲观事务模型
TiDB 新特性漫谈:悲观事务
悲观事务
TiDB 事务隔离级别
两阶段提交与三阶段提交
关于分布式事务、两阶段提交协议、三阶提交协议