

1. 回顾,以最佳实践为起点
作为一款 HTAP 数据库,TiDB 能同时处理来自用户端的 OLTP 在线业务与 OLAP 分析业务。针对分析类需求,优化器会自动将请求路由到列存的 TiFlash 节点;而对于在线请求,优化器会自动路由到行存 TiKV 请求。对于 HTAP 数据库,我们最关心的莫过于占用大量资源的分析类查询是否会影响到在线的 OLTP 业务,针对这个问题,TiDB 在物理层上对 TiKV 与 TiFlash 进行了隔离,很好的避免了这种情况。
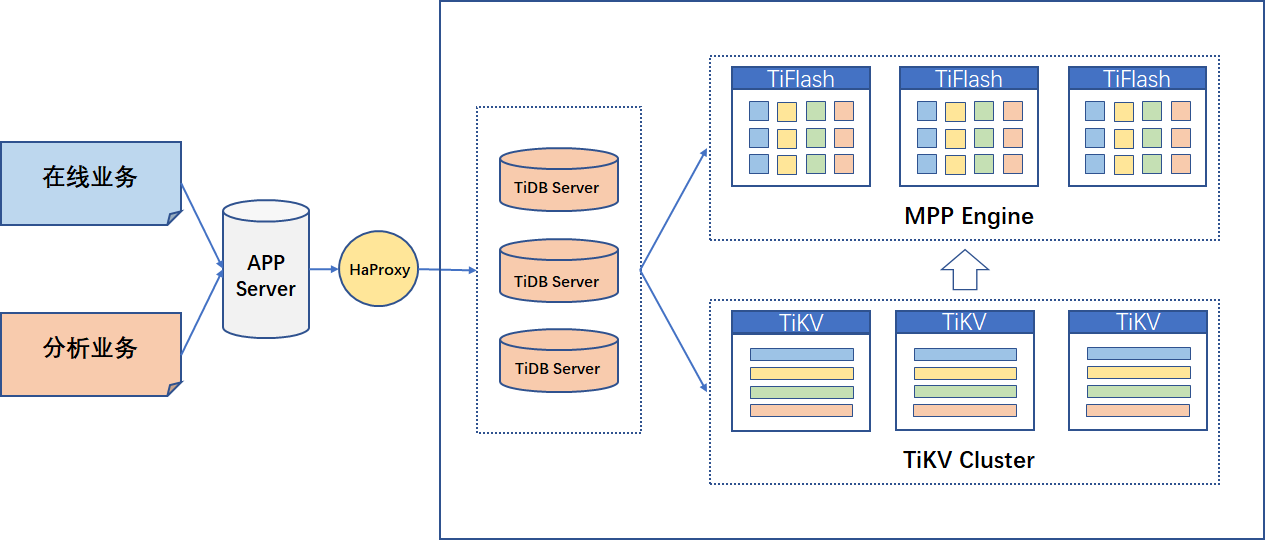
2. 反思,最佳实践结构之痛
通过资源隔离的方式,我们解决了业务之间的相互影响。然而要想实现更灵活、高效的应用,上面的架构中仍然存在一定的问题:
- HAProxy 暂时没有高可用功能
- 对于 TiDB Server 来说,没有做到 TP 业务与 AP 业务的隔离
对于以上的两个问题,我们可以采用以下的两种方案规避上面的风险。
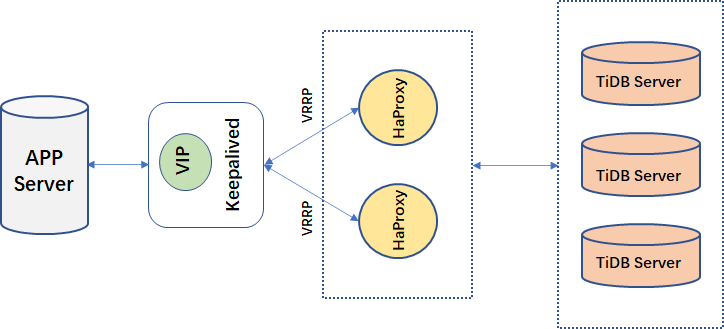
2.1 HAProxy 的高可用方案
在生产环境中,一般我们是不会单独使用 HaProxy 做 DNSRoundRobin 的。任何一个单点非高可用结构都会导致系统的不可用。HaProxy 本身是一个无状态的服务, 对于无状态服务,我们可以通过多个服务来来规避单节点的可用性风险。另外,在 HaProxy 之上,我们可以通过 Keepalived 的探活脚本将 VIP 飘到一个可用的节点上,以完成单入口的高可用结构。
2.2 TP 与 AP 的隔离方案
在 HTAP 场景中,我们已经通过将数据在物理层面上存放在 TiKV 与 TiFlash 上来隔离 OLTP 和 OLAP 查询请求,真正实现了存储引擎级别的隔离。在计算引擎上,也可以通过 TiDB 实例级别设置 isolation-read 参数来实现 engine 的隔离。配置 isolation-read 变量来指定所有的查询均使用指定 engine 的副本,可选 engine 为 “tikv”、“tidb” 和 “tiflash”(其中 “tidb” 表示 TiDB 内部的内存表区,主要用于存储一些 TiDB 系统表,用户不能主动使用)。
无论前端是否做 HAProxy 的高可用,在 roundrobin endpoint 的时候,HAProxy 无法判断 TiDB Server 的 isolation-read engine 隔离机制是什么样的。这样就可能造成一个尴尬的局面,HAProxy 可能将 OLTP 的查询请求路由到了 isolation-read 设置为 tiflash 的节点上,使得我们无法以最佳的姿态来处理请求。亦或是说,某些我们强制使用了 hint 走 TiFlash 的分析类查询,可能会被路由到 isolation-read 设置为 tikv 的结点上,SQL 请求抛出异常。
从功能点出发,我们需要重新定义一下 HTAP 数据库:
- 我希望存储层数据是分离的,OLTP 和 OLAP 业务互不影响
- 我希望计算层的请求是分离的,OLTP 和 OLAP 请求互不影响
3. 变更,需求驱动架构转型
3.1 基于 HAProxy 的改造
为了解决计算层 TiDB Server 的路由,我们可以使用两套 HAProxy 将 TiDB Server 集群进行物理上的区分。一套 HAProxy 集群用来管来 isolation-read 为 tikv 的 TiDB Server,另一套 HAProxy 集群用来管理 isolation-read 为 tiflash 的 TiDB Server。出于高可用的考虑,我们仍然需要在 HaProxy 集群上做高可用,这样一来,可以抽象出如下的架构:
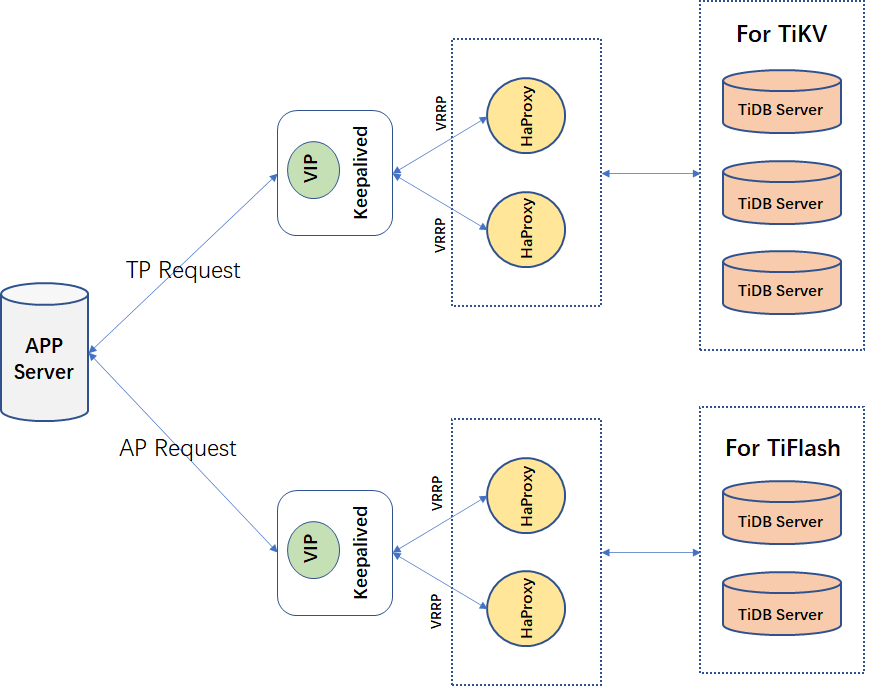
从整体架构上来看,这样的一套架构设计基本满足了我们的需求,计算层 TiDB Server 被物理隔离开,前端的 Proxy 也做了高可用。但这样的结构还是存在缺陷的:
- 结构较为复杂,以致为了保证系统的高可用性,花费的相对物理结点较高
- Proxy 的出口不统一,需要两套 Keepalived 维护两个 VIP,在业务逻辑中需要进行编码操作
如果采用这样一套架构,从削减成本的角度考虑,我们可以进行结点混部。两套 keepalived 集群我们可以考虑部署在一套三节点的机器上,通过 virtual_router_id 进行物理隔离。或者直接部署一套 keepalived 集群,不使用 keepalived 中自带的 VIP,在一套 keepalived 分别部署两套 vrrp script,各自的探活脚本中维护独立的 VIP。HAProxy 我们也可以使用 keepalived 的机器进行部署,做成一套 2 * (3 * Keepalived + 3 * Haproxy) 的结构。如此改进的集群架构,虽然可以将机器成本压缩到和维护普通集群相同,但仍然无法从架构上削减复杂性,也无法更改两个入口带来的不变。
3.2 使用 ProxySQL 实现 SQL 的路由
现在来看,我们需要的是一款 TP/AP 分离的 Proxy。从需求上来看是比较匹配 MySQL 读写分离的,或者明确的说,我们的需求就是需要一款 SQL 路由的工具。
想必接触过 MySQL 的同学都会了解 ProxySQL 这款产品。ProxySQL 是一款基于 MySQL 的开源中间件产品,是一个灵活的 MySQL 代理工具。作为一款强大的规则引擎中间件,ProxySQL 为我们提供了很多特性:
- 灵活强大的 SQL 路由规则,可以智能的负载 SQL 请求
- 无状态服务,方便的高可用管理方案
- 自动感知结点的监控状态,快速剔除异常结点
- 方便的 SQL 监控分析统计
- 配置库基于 SQLite 存储,可以在线修改配置并且动态加载
- 相比于 MySQL query cache 更灵活的 cache 功能,可以在配置表中多维度的控制语句缓存
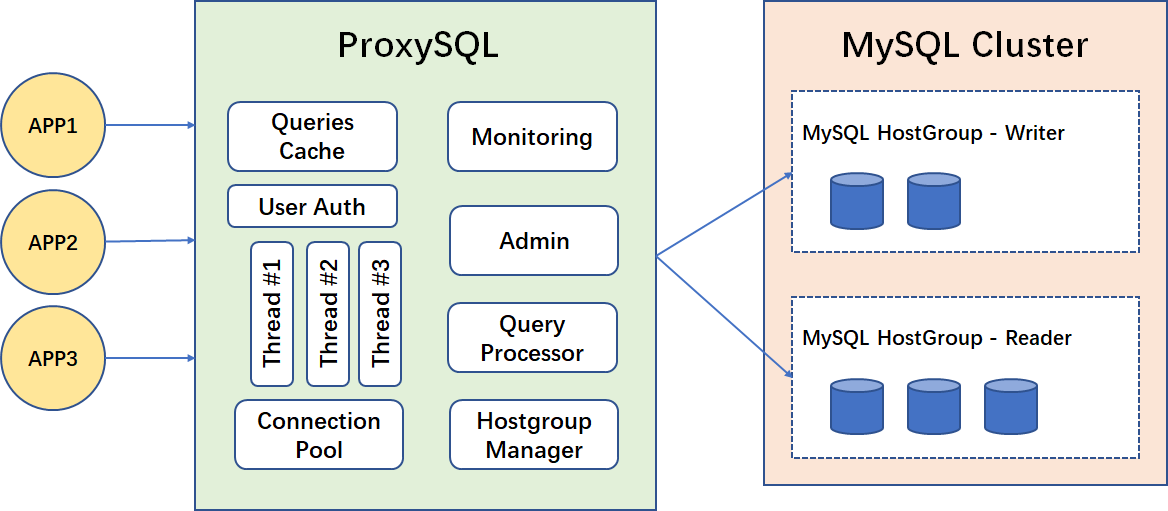
在我看来,ProxySQL 是一款强大到没有什么多余功能的产品,他的每一个特性都能切实的命中用户的痛点,满足用户的需求。如果硬要说有什么不足的话,我能想到的就是由于路由功能带来的性能衰退,但这样的衰退在其他的 Proxy 工具中依然存在甚至更甚。
作为一款“大尺码”的 MySQL,TiDB 是否可以很好的适配 ProxySQL 呢?答案是肯定的。我们可以简单的复制 ProxySQL 在 MySQL 读写分离的方案,进行 TP/AP SQL 请求的路由操作。甚至来说,以上介绍的种种强大的功能,在 TiDB 中仍然适用,在某种程度上,弥补了 TiDB 生态的不足。
3.3 全链路的高可用
对于一套数据库系统,任何一个环节都可能成为故障点,所以任何服务都不能以单点的形式存在。TiDB Cluster 的任何组件都是有高可用并且可扩展的。ProxySQL 也可以配置高可用集群。对于 ProxySQL 的高可用,目前流行的主要有两种方案:
- 多个相互独立的 ProxySQL
- 使用 ProxySQL 的高可用集群
ProxySQL 本身是无状态的服务,所以前端多个相互独立的 ProxySQL 本身就是对可用性的一种保障。但由于多个 ProxySQL 是独立的,相关的配置文件无法互联。对任何配置进行改动无法自动同步,这对管理来说是存在风险的。如果使用集群版的 ProxySQL 高可用,为了保证集群状态的 watchdog 进程可能本身对于集群就是一种负载。
正如前面所处,对于一套集群,我们期望能有一个入口。而前端的 ProxySQL 本身是有多个入口的。我们可以采用 Keepalived + haproxy 的方式进行一个 endpoint 的负载均衡,或者说担心多级 proxy(HAProxy + ProxySQL)带来的性能大量衰退,我们可以自己维护 Keepalived 的探活脚本控制 VIP。对于网络监管比较严格的公司,可能关闭了 VRRP 协议,那么可以选择 Zookeeper 服务注册与发现来维护 ProxySQL 的状态,在 Zookeeper 中管理集群的 VIP。
针对于多 endpoint 的统一入口高可用方案,每个公司都有自己的解决架构。就我而言,相比于 Keepalived + HAProxy 或者在 Keepalived 的脚本中做负载均衡,我更倾向于使用 zookeeper 来管理集群的状态。我们需要仔细的去规划 Keepalived 的算分制度,为了减少 HAProxy 对性能的衰减,可能又要在脚本中管理另一套 VIP 或者关闭失败结点上的 Keepalived 服务。当然,使用什么方案还要配合我们自己的技术栈,只有适合自己的才是最佳实践。

在上面的架构中,TP 与 AP 的请求通过 APP 程序接入到后台的 TiDB Cluster。作为程序的唯一入口,Keepalived 的探活程序会选择一台可用的 ProxySQL,在之上创建一个 VIP。这个 VIP 将作为应用程序与 TiDB Cluster 对接的唯一入口。在 ProxySQL 集群中,根据 Router Table(mysql_query_rules)中配置的 TP 和 AP 的 pattern 配置,将 TP 与 AP 的 查询请求自动的路由配置好的 TP_GROUP 与 AP_GROUP 中。
综上所述,这样的架构能够解决我们之前的痛点问题:
- 应用程序与数据库集群使用唯一的接口
- 简单的高可用结构,通过一套 keepalived 与一套 Proxy 集群实现高可用性
- TP/AP 的请求能够自动的路由到对应的计算节点 TiDB Server 中
4. 践行,从案例入手求结果
部署了一个 demo 系统,简单的展示一下整套架构的运行流程与结果。
以下为结点上的组件列表:
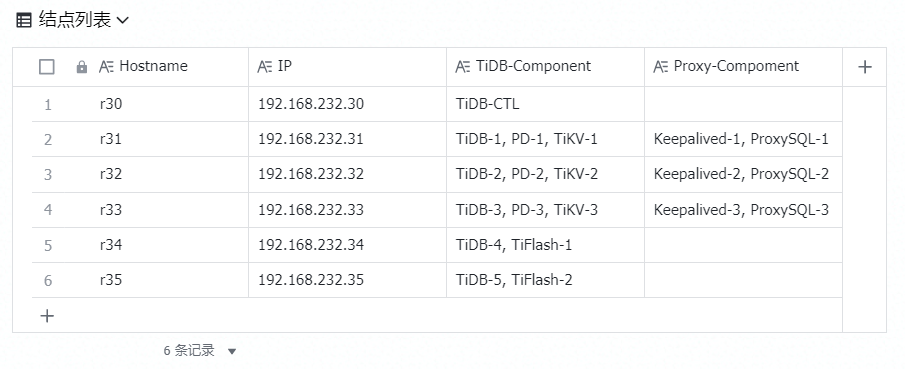
4.1 安装 TiDB
略,懂的都懂
4.2 安装 ProxySQL
可以选择使用 rpm 的方式安装 ProxySQL。但为了统一安装的位置,一般我会习惯使用源码进行编译安装,然后使用 rpmbuild 打成安装包部署到其他结点上。编译安装可以参考 INSTALL.md 文档
修改 proxy.cfg 文件,修改 datadir="/opt/tidb-c1/proxysql-6033/data"
使用以下命令可以启动 ProxySQL,或是配置 systemd 文件进行启动
/opt/tidb-c1/proxysql-6033/proxysql -c /opt/tidb-c1/proxysql-6033/proxysql.cfg
4.3 配置 ProxySQL
由于在本例中,我使用了三台独立的 ProxySQL 做高可用负载,需要在这三台机器上做相同的配置。如果选择了 ProxySQL 自带的高可用,那么只需要在一台机器上进行配置。
[root@r31 proxysql-6033]# mysql -uadmin -padmin -h127.0.0.1 -P6032 --prompt 'admin>'
## set server info
insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.232.31',14000);
insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.232.32',14000);
insert into mysql_servers(hostgroup_id,hostname,port) values(10,'192.168.232.33',14000);
insert into mysql_servers(hostgroup_id,hostname,port) values(20,'192.168.232.34',14000);
insert into mysql_servers(hostgroup_id,hostname,port) values(20,'192.168.232.35',14000);
load mysql servers to runtime;
save mysql servers to disk;
## set user
insert into mysql_users(username,password,default_hostgroup) values('root','mysql',10);
load mysql users to runtime;
save mysql users to disk;
## set monitoring user
set mysql-monitor_username='monitor';
set mysql-monitor_password='monitor';
load mysql variables to runtime;
save mysql variables to disk;
## set sql router rule
## this is just a demo
insert into mysql_query_rules(rule_id,active,match_digest,destination_hostgroup,apply)
values(1,1,'^select.*tikv.*',10,1),(2,1,'^select.*tiflash.*',20,1);
load mysql query rules to runtime;
save mysql query rules to disk;
4.4 配置 Keepalived
Keepalived 的安装参考 keeaplived-install,与 ProxySQL 的安装相同,推荐编译安装后达成 rpm 包或者直接 copy keepalived 的 binary。
Keepalived 的配置文件脚本如下
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script check_proxysql {
script 'killall -0 proxysql || systemctl stop keepalived'
interval 2
weight 10
}
vrrp_script test_script {
script 'echo `date` >> /tmp/aaa'
interval 1
weight 1
}
vrrp_instance proxysql_kp {
state MASTER
interface ens33
virtual_router_id 51
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1888
}
virtual_ipaddress {
192.168.232.88
}
track_script{
check_proxysql
##test_script
}
}
4.5 验证 ProxySQL
我打开了五台 TiDB Server 上的 general log 用来记录 sql 语句。
在 TiDB Cluster 中创建了两张表
- test.t_tikv(idi int),数据从 1 - 1000
- test.t_tiflash(idi int),数据从 1 - 1000
在前端使用简单的循环进行压测
for i in `seq 1000`; do mysql -uroot -P6033 -h192.168.232.88 -pmysql -e "select * from test.t_tikv where idi = $i"; done
for i in `seq 1000`; do mysql -uroot -P6033 -h192.168.232.88 -pmysql -e "select * from test.t_tiflash where idi = $i"; done
TiDB Server log 过滤关键字 “select * from test.t_tikv where idi =” 的条数。可以看出针按照路由表中配置的 TiKV SQL,1000 条较为分散的路由到了 TiDB-1,TiDB-2,TiDB-3 结点上。
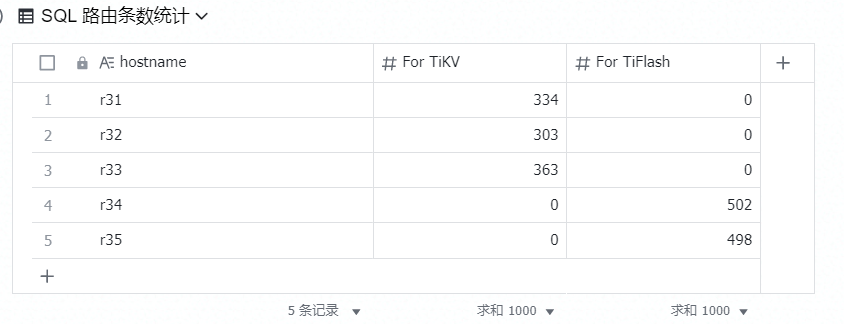
5. 彩蛋,你想要的审计功能
数据库审计是对数据库的访问行为进行监管的系统,他能够在发生数据库安全事件之后为事件的罪责定责提供依据。将审计日志抽取到实时数仓中进行风控处理,能够及时的发现风险,最大程度的挽回损失。审计日志在一些重要的金融、订单交易系统中至关重要。
5.1 如何捕获 audit log
与现在很多用户一样,曾经我也遇到过 audit 的需求。像 MongoDB 这样的开源数据库,很多都是不提供免费的审计功能的。审计功能对于很多金融类的场景是尤其的重要,为了完成审计功能,我们通常有两种方式:
- 在源码中解析语义
- 数据的流量采集
所谓的源码语义解析,其实就是我们在源码中手动的添加 audit 的功能。我们可以修改源码,将一些希望捕获的变量信息落盘到本地文件中。但是这种方式可能会造成大量的等待,影响数据库的性能。通过将这种写操作异步执行,可以稍微缓解性能的下降。
另一种数据流量采集的方式,相比于变量落盘这种方式,要稍微好一些。流量监控的思路是搭建一套与数据库相对独立的旁路系统,通过抓包或者探针等工具截获流量,将针对于数据库的请求打印到本地的文件中。这种方法本身与数据库不挂钩,异步的获取审计日志。
5.2 在 TiDB 中捕获 audit log
TiDB 上的审计目前来看主要有两种,一种是购买原厂提供的审计插件,另一种是开启 general log 功能,在 tidb log 中可以查看到 sql 语句。需要注意的是,由于前端我们使用了 HAProxy,我们需要配置 forwardfor 参数以捕获客户端的 IP。general log 会将所有的包括 select 在内的请求都记录在 tidb log 中,根据以往的测试来看,会有大概 10%-20% 的性能损失。记录的 sql 语句包括时间或 IP 等其他的信息可能不能满足我们的需求,并且从 tidb log 中整理出 audit 也是一个较大的工程。
5.3 在 ProxySQL 中获取 audit log
Audit 的需求是非常常见的。如 MongoDB,开源数据库的社区版本不提供 audit 功能也是较为普遍的。从整条链路来看,能获取到完整 audit 的结点有两个,一个是数据库端,一个是 proxy 端。ProxySQL 可以为我们提供了审计的功能。当我们指定了 mysql_enventslog_filename 参数,即设置开启审计功能。在审计文件中,我们可以捕捉到 ProxySQL 入口的所有 SQL audit。
在我的环境中,可以捕捉到以下格式的 audit log,基本满足了用户的大部分需求:
{"client_addr":"192.168.232.36:55908","creation_time":"2021-06-06 10:55:39.373","duration":"4.721ms","event":"MySQL_Client_Close","extra_info":"MySQL_Thread.cpp:4332:process_all_sessions()","proxy_addr":"0.0.0.0:6033","schemaname":"information_schema","ssl":false,"thread_id":40064,"time":"2021-06-06 10:55:39.377","timestamp":1622991339377,"username":"root"}
5.4 通过探针截获 audit
可以通过 systemtap 做成 probe 挂在 proxysql 上,根据一些 proxysql 关键字,比如说,run、execute、query、init、parse、mysql、connection 等尝试追踪到这些函数的调用栈与参数。打印这些参数可以获取到处理请求时的 ip 与 statement。如果这些函数没有办法追踪到 audit 信息,那么可以考虑使用暴力破解的思路,追踪 proxysql 的所有函数(通过 function("*") 来匹配)。根据结果定位到指定的函数。但这种方法在开发时需要一台较为强大的服务器。
目前通过虚幻能够追踪到的审计日志如下:
>>>>>>>>>>>>>>>>>>>[ function >> ZN10Query_Info25query_parser_command_typeEv ] [ time >> 1622953221 ] this={.QueryParserArgs={.buf="select ?", .digest=2164311325566300770, .digest_total=17115818073721422293, .digest_text="select ?", .first_comment=0x0, .query_prefix=0x0}, .sess=0x7f1961a3a300, .QueryPointer="select 1113 192.168.232.36", .start_time=2329486915, .end_time=2329486535, .mysql_stmt=0x0, .stmt_meta=0x0, .stmt_global_id=0, .stmt_info=0x0, .QueryLength=11, .MyComQueryCmd=54, .bool_is_select_NOT_for_update=0, .bool_is_select_NOT_for_update_computed=0, .have_affected_rows=0, .affected_rows=0, .rows_s ######
其中可以抓到 query point,从中可以获取到 query 的文本,用户的 client ip,而 function name 与 time 是我通过 systemtap 的脚本直接本底写入的。
使用外挂探针这种方式,能够很好的减轻 proxy 或者 database 的写日志等待,从而最小程度的减少对数据库性能的影响,基本可以忽略因为审计带来的性能损失。