

本文系北京 TUG 线下活动 “不同业务场景下的数据库技术选型思路”实录整理,作者: 58 集团 DBA 旋凯

大家好,我是来自 58 集团的 DBA 旋凯,今天给大家带来的分享题目是 “58 集团数据库技术选型思路”。
首先,我给大家介绍一下我们集团的业务概况。我们的业务范围包含 58 同城、赶集、安居客、58 金融、中华英才、驾校一点通等公司。我们使用的数据库有 MySQL、Redis、MongoDB、ES、TiDB等,大概每天的访问情况在 8000 亿次左右,集群数量 4000+,物理服务器数量 1500+。

TiDB 在 58 集团的使用情况
我们现在线上生产环境一共有 11 套 TiDB 集群,版本为 3.0.3,物理机数量 80 台,数据总量 40T,每天的访问量在 10 亿次左右。我们一共有 2300 套 MySQL 集群,11 套 TiDB 集群,比例大概为 0.47%,访问量比例为 2%。
从响应时间来,TiDB 是分布式数据库,响应时间与单机的 MySQL 相比较高。之前我们做过的测试显示 TiDB 与 MySQL 响应耗时比在 1.2 到 1.5 左右,可以接受,所以正在将 MySQL 逐步替换为 TiDB 。
TiDB 在 58 集团的使用场景为交易账户流水(也是现在最大的一个库)、金融数仓、私有云监控、用户行为日志、语音机器人、客服系统、广告投放系统、交友系统、帖子信息等。


TiDB 的选型过程
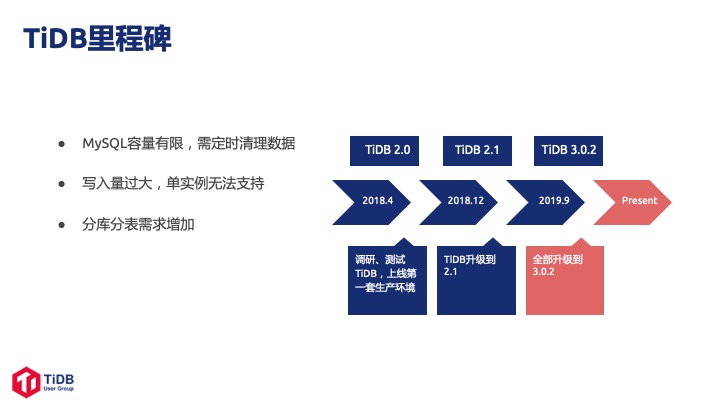
我们从 2018 年的 Q1 开始调研 TiDB 2.0,当时我们遇到的问题场景是私有云监控的数据存储在 MySQL,由于数据量巨大需要定期清理表,给 DBA 带来了很大的工作量。
我们知道 TiDB 后开始调研,最终在 2018 年 4 月上线了第一个 TiDB,迁移了公司内部系统的一个监控日志。第一套量非常小,访问量大概每秒2000 左右,整体数据量在 7T~8T 之间。2018 年 12 月,我们开始测试 2.1 GA 版本,这个时候线上已经有大概 4 套集群,存储了内部私有云的全部日志系统。到了 2019 年 9 月,我们线上和测试环境已经全部接入 TiDB 3.0.2。
我们使用 TiDB 主要解决了几个 MySQL 遇到问题:
- MySQL 单机容量有限,例如存储日志类数据需要定时清理的问题;
- 分库分表问题,58 集团没有中间件团队,开发侧需要自己运维分表场景,同时,分库分表后对于后期的数据聚合及 ETL 来说工作量也非常大;
- MySQL 自身高可用的问题(8.0 之后的 MGR 还可以),之前我们使用了 MHA, 但是增加了维护成本;
- MySQL 的从库延迟问题,之前我们进行 DDL 时会造成从库的延迟,这会对实时读造成很大的影响;
- 单机写入量过大 MySQL 承受不了的问题,58 集团的一个规矩是当单点写入达到 15,000 的时候,我们就会进行拆库,而 TiDB 可以进行多点写入。

这就引申出了我们选择数据库的一些思考维度:
- 社区活跃度,如果社区不活跃,遇到问题或 bug 无法得到解决,就会被 PASS;
- 方便运维,TiDB 自身的运维体系,包括高可用、一致性、监控等维度都非常好,我们可以很快地把它接入到内部的运维平台上;
- 能不能解决现有问题,例如我们遇到了大量的分库分表,大量的数据删除和写入等问题,超出了现有数据库的承受范围。
于是我们选择了 NewSQL 数据库的代表 TiDB 来解决这些问题。

前面我们提到使用 MySQL 时我们遇到的一些问题,那么TiDB 是怎么解决的呢?
- 首先 TiDB 是分布式存储,可以水平扩展,解决了我们单机容量小的问题;
- 其次 TiDB 具备的高可用特性解决了我们额外准备高可用服务带来的运维成本问题;
- 再次 TiDB 支持多点数据写入,解决了我们单机写入量在 15,000 左右就会出现瓶颈的问题;
- 最后 TiDB 提供了分库分表的聚合方案,它的监控体系也比较完善,不需要额外搭建监控体系。

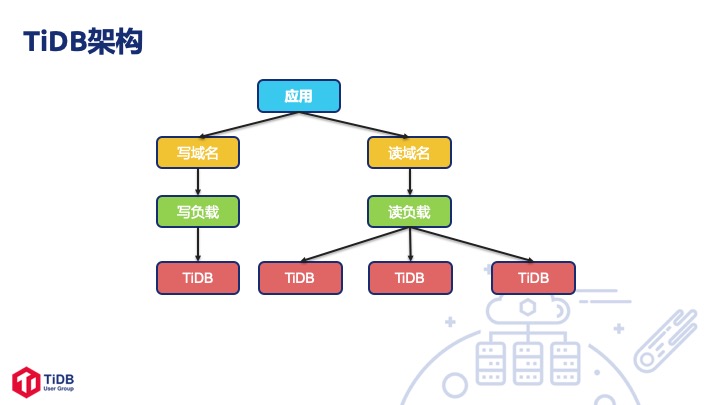
TiDB 在 58 集团的使用架构
我们的 TiDB 架构比较简单,应用上首先是分读写域名,后端使用 Load Balance 。默认情况下我们一套集群上有 4 个 TiDB 节点,一个写三个读,如果写达到瓶颈的话,可以扩容 TiDB 节点。
58 集团的 TiDB 体系建设
首先,我们建设了一个工单系统,开发人员要通过私有云平台去进行数据库的日常操作,比如 DDL、DML 等,不能直接连数据库。
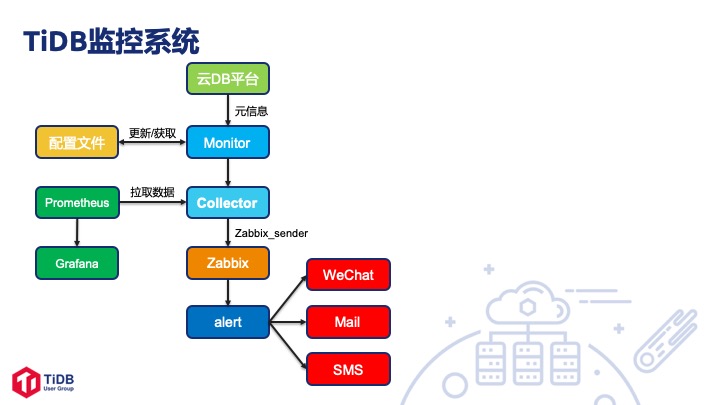
第二,我们做了一套监控系统,把 TiDB 的监控数据从 Prometheus 同步到我们的 Zabbix 上,然后在私有云平台上根据我们的数据模型进行展示。
第三,我们做了一个自助查询系统可以快速生成 SQL,而 SQL 可以直接进行数据导出,提高了 RD 使用平台的效率。
第四,我们做了一个报表系统便于管理集群,通过抓取 Prometheus 里的数据在运维平台上进行报表展示,每天的值班 DBA 通过报表可以掌握各集群的状态:是否有报错、容量是否充足、是否需要扩容等。
第五,我们做了一个日常巡检系统,会每天早晨九点和晚上六点对 TiDB 集群进行巡检。目前巡检项目比较简单,大概就十几项,能够帮我们及时发现一些隐患,比如某个时间点慢日志突然爆增,某个表上的索引缺失,或是错误日志里出现异常等。
第六,近期我们做了运维工具和备份系统,使得数据库能够满足审计的需要。
TiDB 工单系统介绍
我们的 TiDB 工单系统支持建表工单、改表工单、数据导出、数据变更、帐号授权等工单,能够满足大部分 RD 的日常需求。后端走的是 Inception 校验,再提交到 TiDB 去执行,和 MySQL 的路径一样。但我们在 Inception 那里和 MySQL 的规则做了一些区分,比如说目前 TiDB 不支持自增主键,但 MySQL 要求必须有自增主键。

监控系统
首先 Collector 会从云 DB 平台上拉取 TiDB 的硬件信息,再同步更新到 Ansible 的配置文件里比较一致性,如果不一致就进行更新。Collector 会到 Prometheus 上拉取监控数据,再把数据通过 Zabbix_sender 发送到 Zabbix 上,如果发现异常 Zabbix 后端会把告警发到微信、短信、邮件、IM 中。

TiDB 运维
运维工具这一块我们做了这么几项:我们有集群拓扑的查询工具、集群的状态检查、慢日志分析、TiDB 监控、检查、自动部署、会话管理这些工具。
58 集团使用 TiDB 的经验
最开始我们使用 TiDB 时,因为机器上有四块磁盘,于是我们在一台机器上布了 4 个 TiKV,但造成了宕机时间特别长的问题,最长的一次是一台 TiKV 机器宕机之后大概两个半小时没起来,解决方法就是打 label。打完 label,用了 3.0.1 后发现宕机时间还是比较长,于是我们寻求了 TiDB 官方人员的帮助,升级到 3.0.2 后宕机时间缩短到了一分钟左右。
第二是 SQL 语法报错,给大家举个例子,3.0.1 时 left join 超过 4 个时可能就会报语法错误,select for update 的执行也有问题,目前在新的新版本都已经解决掉了。
第三是我们之前选机器的时候,是根据磁盘去部署 TiKV 的,后来发现 CPU 资源不够用了,TiKV 越升级 CPU 使用越多。我们跟官方人员沟通后换了一个新的机型,增加了 CPU 的核数,然后减少了 TiKV 的数量。于是我们得出了一个结论:用最好的机器,用最新的版本,遇到问题都会解决的。


后续规划
这部分主要分为四个方向。
首先我们会对监控模型进行优化,现在只是简单地从 Prometheus 里拉取数据然后放到 Zabbix 去做报警,平台再根据 Zabbix 数据进行聚合和展示,不如 MySQL 的监控那么完善。
其次,我们会把 TiDB 和 TiKV 的自动扩缩容放到我们的运维平台上去做。
接下来我们会搭建一个慢日志系统。目前 MySQL 有慢日志系统,包括每日的报表和一个类似实时流水的日志,但是 TiDB 的日志格式和 MySQL 不太一样,目前我们就只能实时去文件系统里读,后续我们会单独做一套 TiDB 的慢日志系统。
最后是一个实时的数据恢复,因为现在 TiDB 官方还没有比较理想的备份系统,我们只是简单用 Mydumper 去进行备份,之后我们也会用 Binlog 做实时备份,并且对两块的数据进行连动。
Q&A
Q1:你好,我想问一下,58 集团的 TiDB 备份恢复系统是怎么实现的?是物理备份,还是逻辑备份,备份以后,这些文件有没有什么压缩之类的这样的优化?
A:是这样的,官方的物理备份还没有出,我们只是用 Mydumper 进行简单的逻辑备份。如果库比较小,我们会整个备份,如果比较大,我们会排优先级,会优先对一些重要的表进行单表的 Mydumper 备份,是逻辑备份,备份之后我们会放到专有的存储机上。Binlog 也会实时备份到存储机上,我们可以手动去找 Binlog 文件和备份文件,如果有需要可以进行相应恢复。
Q2:我想问一下,当前 58 集团的 TiDB 机器选型,大概用的是什么样的机器?
A:我们最开始引入 TiDB 的时候没有把它当做一个核心的数据库,所以我们采用了 DBA 这边的低配机器,当时是 32 核的 CPU,型号是 E5 的 2630,主频 2.1的,磁盘是 1.7T 的一个 PCIE 板卡,但是这个卡比较老了,是英特尔的 4530。上了 2.1 之后,我们发现 CPU 不够用了,当时看了下,业务也没有那么大量,我们就忍了。后续到了 3.0 之后,CPU 的核数需求上升了,然后我们就开始换机器选型,现在采用了和 MySQL 一样的配置机器,单台核数没变,还是 32 核,CPU 主频提到 2.4,磁盘是单盘 1.7T 的,内存都是 128 的。今年第三季度采购了一批新机器,内存是 256 的,CPU 的主频降到 2.1,核数是 48 核。
Q3:现在在一台物理机上起多少个实例呢?
A:现在使用 3.0 版本的机器是一个机器上使用一个 TiKV。我们后续的一个机型是 48 核的机器,内存增加,磁盘是三块 SSD。
Q4:请问一下,你刚才提到有一个 select for update,这种悲观锁的这种场景,之前 TiDB 并不支持,我想请问一下你们这边怎么解决的呢?
A:这个悲观锁我们用的也是比较少的。之前我们金融数仓的同事反馈说它的执行和预期不符,但是 DBA 是没有办法去修复这个问题的,所以我们暂时让他用乐观锁,我看官方的版本 3.0.3 里面也解决了这个问题,但后续还需要测试。
你有什么想和旋凯老师交流的吗?欢迎在评论区留言告诉我们吧!