

【是否原创】是
【首发渠道】TiDB 社区
【首发渠道链接】其他平台首发请附上对应链接
背景介绍
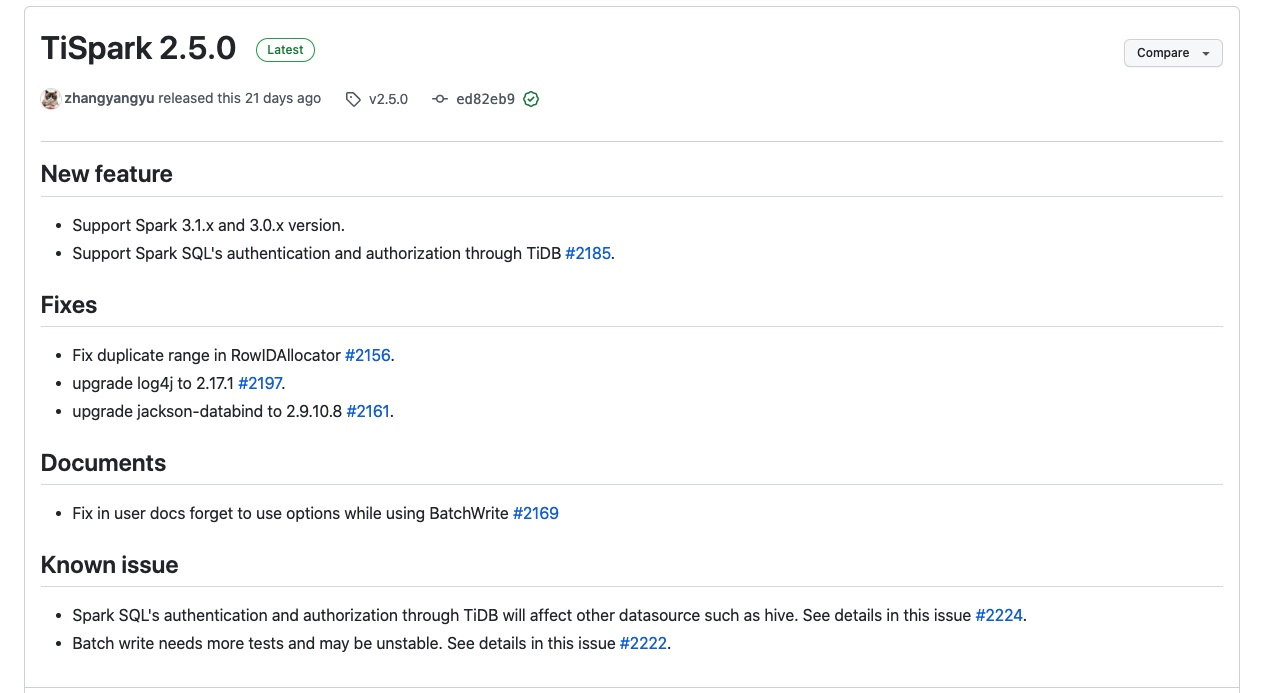
喜大普奔,TiSpark 2.5.0发布了,其中最重要的特性是支持了Spark 3.0.X和Spark 3.1.X。因为在k8s上跑TiSpark始终使用的Spark 3.0.3的环境(原因见:TiSpark On Kubernetes实践 关键解释中的说明),也因为统一技术栈的需要,想要统一TiSpark的运行环境到3.0.X,对TiSpark 2.5.0进行了初步测试。
本文描述了从TiSpar k2.4.1(Spark 2.4.5)到TiSpark 2.5.0(Spark 3.0.X/3.1.X)所需做出的修改,运行时状态对比,出现的问题及解决方案。
基础环境版本
- TiDB版本
TiDB 5.4.0 - 测试1:
TiSpark 2.4.1+Spark 2.4.5
submit环境Spark 3.0.3 - 测试2:
TiSpark 2.5.0+Spark 3.0.3
submit环境Spark 3.0.3 - 测试3:
TiSpark 2.5.0+Spark 3.1.2
submit环境Spark 3.1.2 - 特别说明
测试数据量为10万行。
spark的executor运行参数如下:
--conf spark.executor.instances=5 \"
--conf spark.executor.memory=1G \"
测试2和测试3的结果基本一直,出现的问题也类同,不做单独分析。
迁移时需要的修改
连接参数修改
TiSpark 2.4.1迁移到TiSpark 2.5.0,并结合Spark 3.0.3/3.1.2使用时,需要在Spark的conf中增加如下配置:

.set("spark.sql.catalog.tidb_catalog","org.apache.spark.sql.catalyst.catalog.TiCatalog")
.set("spark.sql.catalog.tidb_catalog.pd.addresses", pd_addr)
此配置可以在Spark代码中SparkConf()构建的时候set,也可以在Spark submit或者Spark的spark-defaults.conf文件中配置。
读取代码的修改
上一小节增加的两行表示在Spark中增加一个名字是tidb_catalog的catalog,此处的catalog类似database,对后续代码的影响就是:
use tidb_catalog.sbtest
或者
select * from tidb_catalog.sbtest.sbtest_o
切换数据库需要按照database+schema的方式,读取表时需要按照database+schema+table的方式。
此处需要注意,写回TiDB的时候,不需要指定database,完整的代码如下:
//通过 TiSpark 将 DataFrame 批量写入 TiDB
Map<String, String> tiOptionMap = new HashMap<String, String>();
tiOptionMap.put("tidb.addr", tidb_addr);
tiOptionMap.put("tidb.port", "4000");
tiOptionMap.put("tidb.user", username);
tiOptionMap.put("tidb.password", password);
tiOptionMap.put("replace", "true");
tiOptionMap.put("spark.tispark.pd.addresses", pd_addr);
String source_db_name = "tidb_catalog.sbtest";
String source_table_name = "sbtest_o";
String target_db_name = "sbtest2";
String target_table_name = "sbtest_t";
spark.sql("use "+source_db_name);
String source_sql = "select * from "+source_table_name;
spark.sql(source_sql)
.write()
.format("tidb")
.options(tiOptionMap)
.option("database", target_db_name)
.option("table", target_table_name)
.mode(SaveMode.Append)
.save();
运行情况
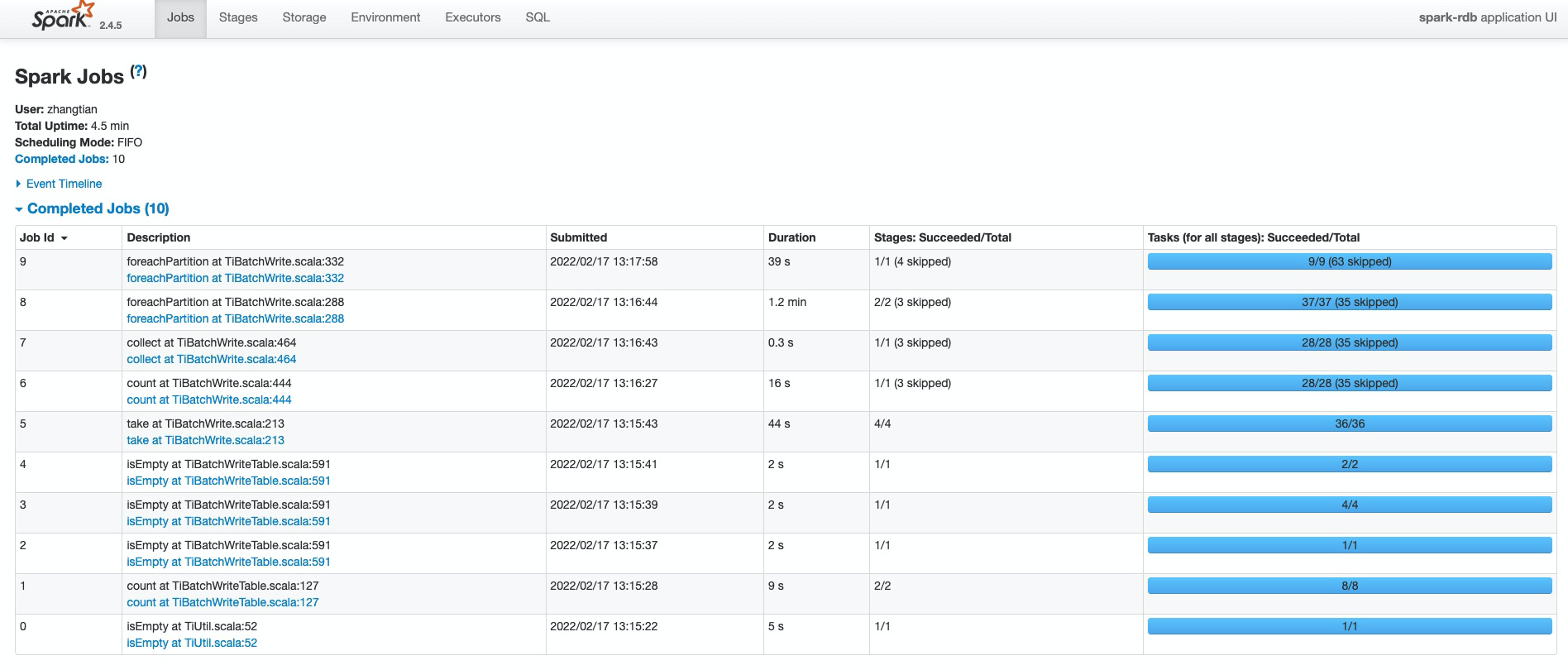
测试1运行状态
总体运行状态:
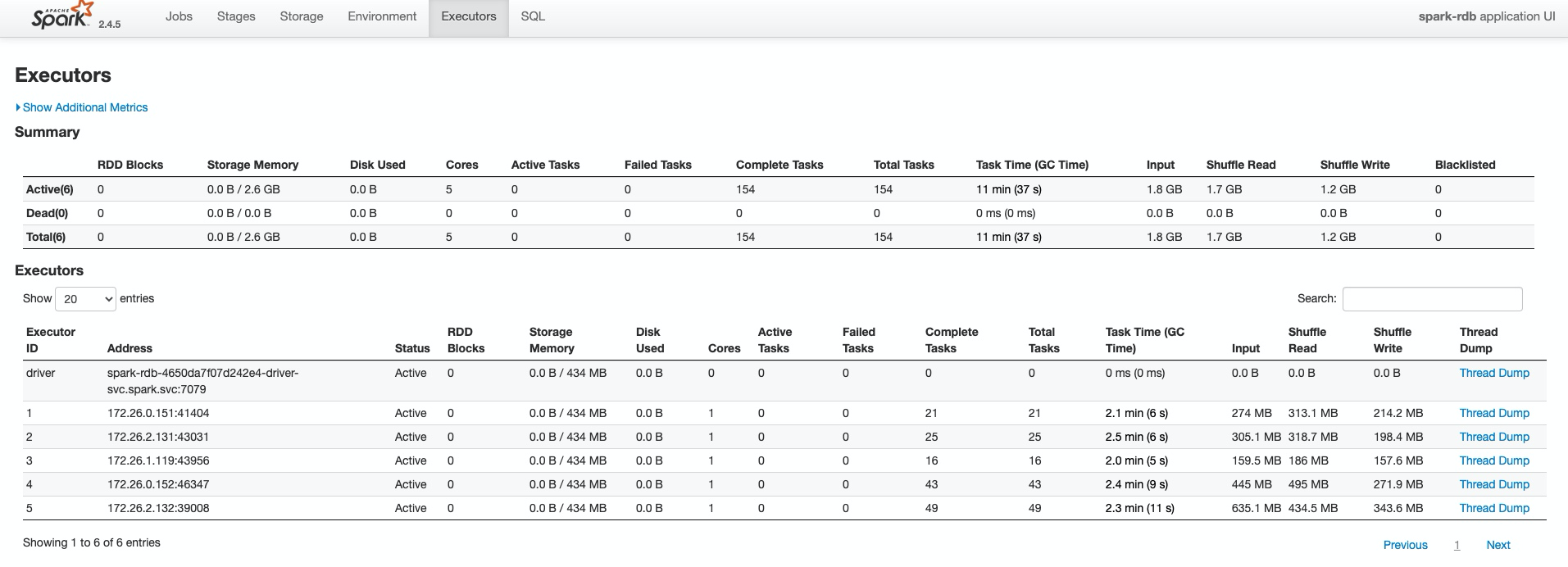
shuffle数据量情况:
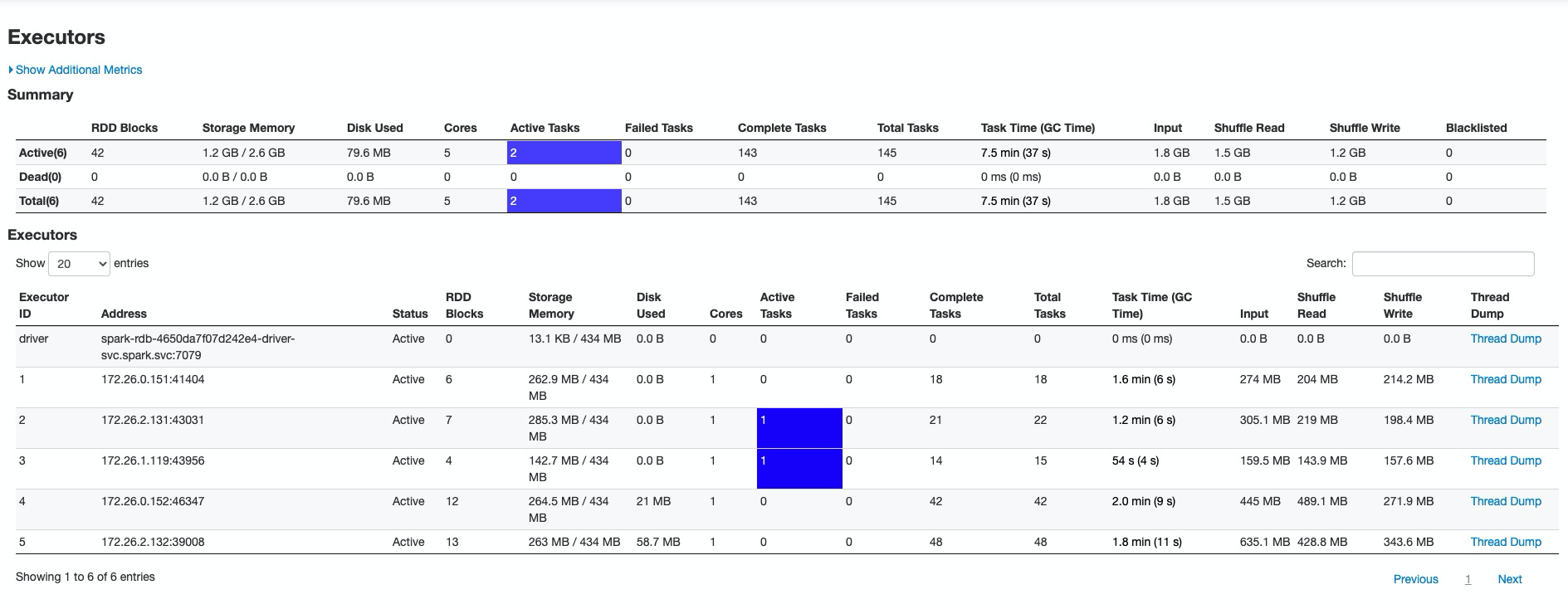
核心运行时间在3.3min:

运行时发现有溢出磁盘的情况:
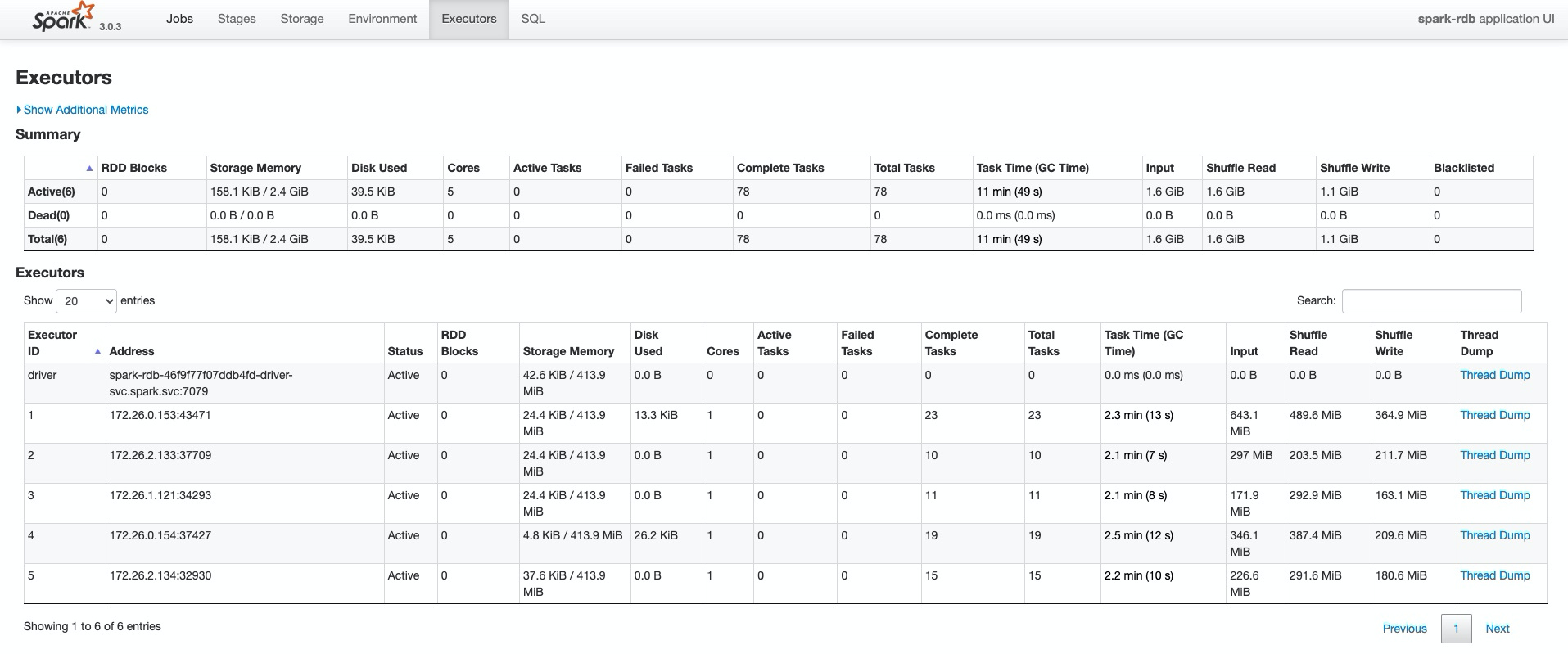
测试2/3运行状态
总体运行情况:
shuffle数据情况:
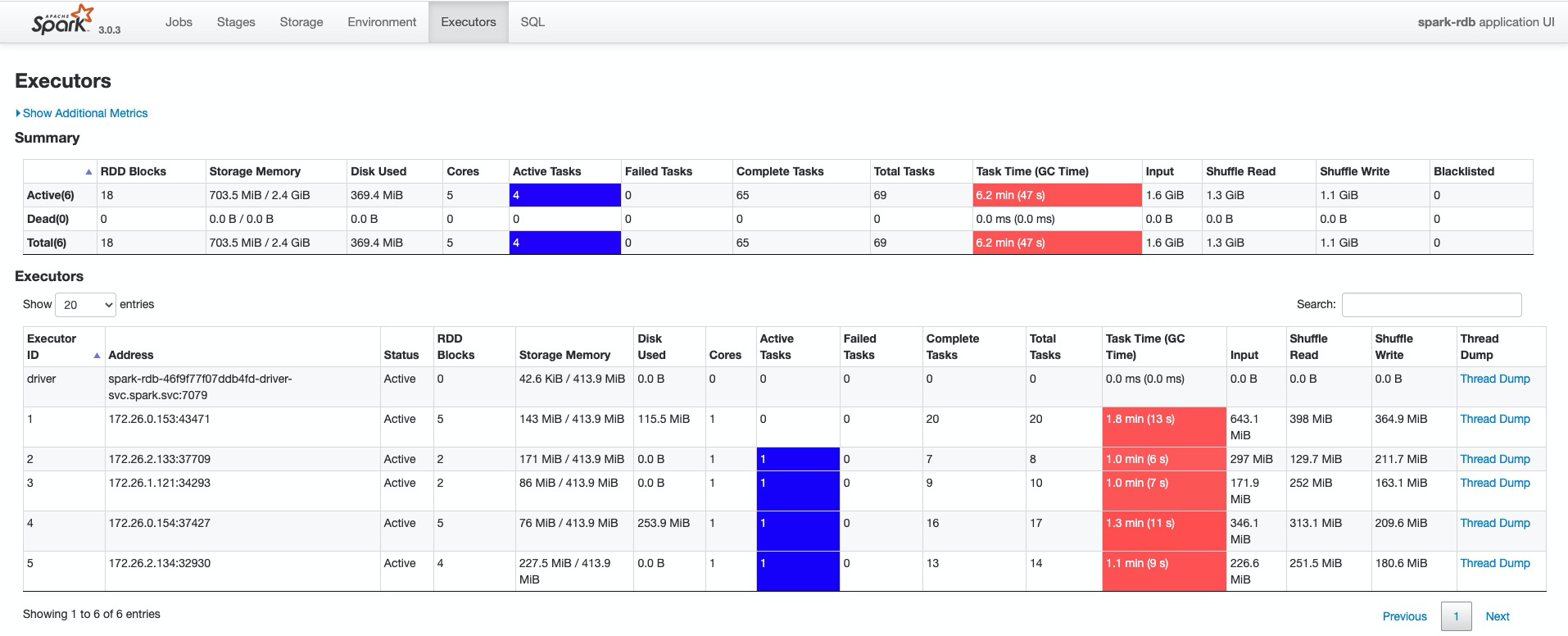
核心运行时间在3.2min:

运行时发现有溢出磁盘的情况:
测试对比
2.5.0版本运行时简化了一次判空动作,整体运行时间缩短了0.1min,磁盘溢出比2.4.1版本增多,偶尔会出现问题,对出现的问题总结如下。
常见错误与处理
ConcurrentModificationException
com.pingcap.tikv.exception.TiKVException: Execution exception met.
......
Caused by: java.util.concurrent.ExecutionException: java.util.ConcurrentModificationException
......
Caused by: java.util.ConcurrentModificationException
......
出现上述错误时,需要修改TiSpark源码,修改com.pingcap.tikv.util.ConcreteBackOffer这个类的backOffFunctionMap的定义和初始化代码:
private final ConcurrentHashMap<BackOffFunction.BackOffFuncType,BackOffFunction> backOffFunctionMap;
this.backOffFunctionMap = new ConcurrentHashMap<BackOffFunction.BackOffFuncType, BackOffFunction>();
重新编译TiSpark
mvn clean install -Dmaven.test.skip=true
重新编译Spark,重新运行即可解决。
Missing an output location for shuffle 3
org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 3
......
出现上述错误是因为Spark的运行内存不足,导出task失败重试,有很多种调优方式,列举两种:
- 对数据进行repartition操作,例如:
spark.sql(source_sql)
.repartition(50) //数据重分区,减轻内存负担
.write()
.format("tidb")
.options(tiOptionMap)
.option("database", target_db_name)
.option("table", target_table_name)
.mode(SaveMode.Append)
.save();
- 有条件的增加executor资源,例如:
--conf spark.executor.instances=5 \"
或
--conf spark.executor.memory=1G \"
迁移总结
整体迁移较容易,需要修改的也不多。2.5.0减少了一个步骤,对shuffle的使用有所增加,容易引起一些shuffle的问题,也能通过调整规避。下一步准备阅读源码对2.5.0的优化作进一步的理解和解读。