

作者:代晓磊,TUG 大使、360 数据库运维专家
本文主要介绍 TiDB 在 360 商业化业务线的应用实践,以及出现写热点时的优化思路和方法。
业务简介以及数据库选型
360 商业化广告主实时报表业务简介
广告主关键词实时统计报表业务,流程是:业务数据入 Kafka,每 30 秒会有程序读 Kafka 数据进行聚合存储到 TiDB 中,每批次会有几十万的写入,单表数据量1.2~1.5亿。
写入场景
业务写入 SQL 主要是:insert on duplicate key update,Batch为 100,并发为 300。并且每天创建一张新表进行写入,写入初期由于没有重复的 uniq_key,所以主要是 insert,随着数据量到达 2000 多万,update 的操作越多。
表结构如下:

数据库选型:MySQL or TiDB?

说到 TiDB 不得不提 TiDB 的架构,结合架构说说 TiDB 的特性:
- 可在线扩展:TiDB Server/PD/TiKV这 3 大核心模块各司其职,并且支持在线扩容,region 自动 balance,迁移过程对业务无感知。
- 高可用:基于 Raft 的多数派选举协议实现了金融级别的数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
- 无缝迁移:支持 MySQL 协议,业务迁移无需修改代码。
- 丰富的监控+运维工具:
- 监控:基于Prometheus + Grafana 的丰富监控模板;
- 运维工具:tidb-ansible 部署+运维;
- TiDB Data Migration(DM):将数据从 MySQL 迁移+同步的工具;
- TiDB Lightning:可以从 CSV 文件或者第三方数据源将数据直接导入到 TiKV;
- TiDB Binlog:备份工具,也可以重放到 Kafka/MySQL/TiDB 等数据库。
TiDB 最核心的应用场景是:大数据量下的分库分表,比如经常需要 1 拆 4,4 拆 8 等数据库无限制拆分情况,并且业务端还需要自己维护路由规则,TiDB 良好的扩展性解决了这些问题。
为了能满足这么大的写入量,曾经尝试过单实例 MySQL 去抗请求,测试完后发现单实例 MySQL 压力较大,为了分散写压力,又想走 MySQL 分库分表这种老路,TiDB 3.0.0GA 后,我们拿离线数据进行了压测,2小时1.5亿的数据存储(tps:2W/s),整个系统负载良好,所以决定使用TiDB。
系统配置
服务器硬件配置:
CPU: E5-2630v2*2;
MEM: 16G DDR3*8;
Disk: Intel S3500 300G1; flash:宝存1.6T1;
Net: 1000M*2
服务器系统版本:CentOS Linux release 7.4.1708 (Core)
TiDB 的版本:tidb-ansible-3.0.0
规模:2.8亿/天
存储:3.8T
TiDB 部署架构图:
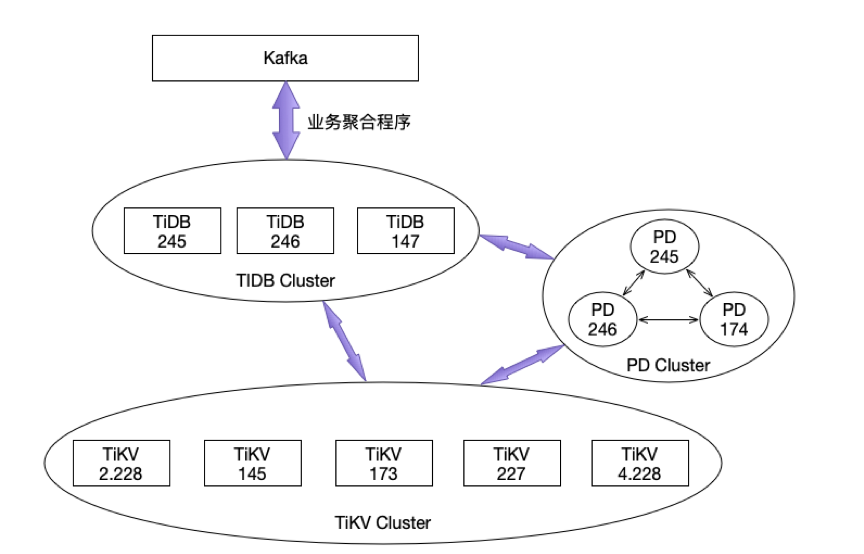
注:PD跟TiDB共用服务器
写热点问题
1. 热点现象描述
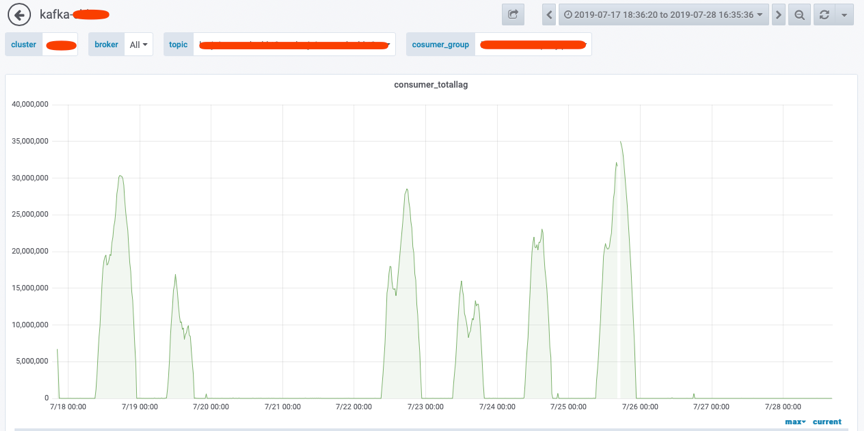
接到业务反馈:从 7 月份开始, Kafka 队列里面有大量的数据累积,等待写入TiDB,Kafka 高峰期的待写入 lag 有 3000 多万,接口的调用时间由之前的1s 变成现在的 3s~5s。我登录 TiDB 发现,单表的数据量由之前的 7000 飙升到1.2~1.5亿,虽然数据量几乎翻了一倍,但单条 insert 的性能不至于这么差。
下图是Kafka 当时的待写入的 lag 情况:
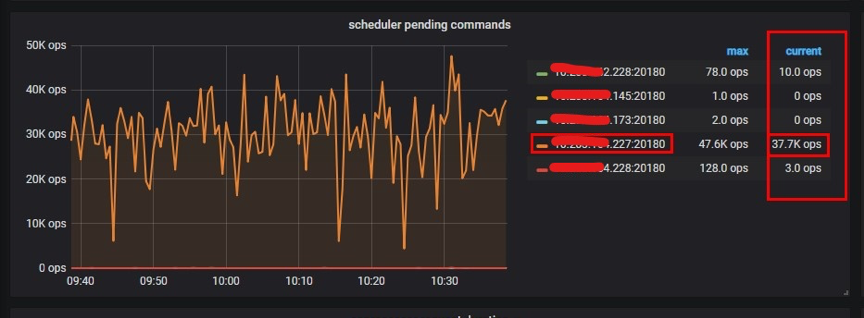
2. 查看 Grafana Overview 监控
TiKV 监控项:scheduler pending commands,发现 TiKV 227 节点大量等待的命令。
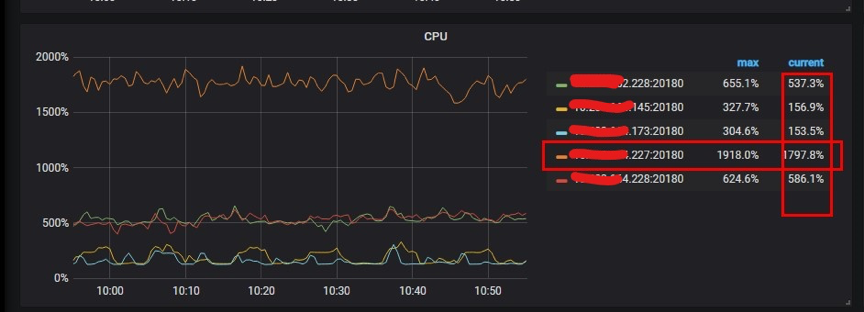
TiKV 监控项:CPU 使用也可能看出热点都集中在 227 这个 TiKV 节点上。
解决方案
DBA 可以根据线上写热点表的表结构不同而采用不同的优化方案。对于 PK 非整数或没有 PK 的表,数据在 insert 时,TiDB 会使用一个隐式的自增 rowid,大量的 Insert 会把数据集中写入单个 region,造成写热点。
此时可以使用 SHARD_ROW_ID_BITS 来打散热点,如果业务表可以新建的话(比如我们的报表业务是按天分表),可以结合 pre-split-regions 属性一起在建表阶段就将 region 打散。如果不满足上面的表结构(比如就是以自增 ID 为主键的表),可以使用手动 split region 功能。上面的两种方法都需要 PD 的参数调整来加快热点 region 的调度。
手动split热点
因为我的表结构是 ID 自增主键,所以我先使用手动 split 热点。
(1)找出热点 TiKV 的 store number
在 tidb-ansible 的 scripts 目录下 table-regions.py 脚本可以查看热点表和索引 region 分布情况:
python table-regions.py --host=tidb_host –port=10080 db_name tb_name
[RECORD – db_name.tb_name] - Leaders Distribution:
total leader count: 282
store: 1, num_leaders: 1, percentage: 0.35%
store: 4, num_leaders: 13, percentage: 4.61%
store: 5, num_leaders: 16, percentage: 5.67%
store: 7, num_leaders: 252, percentage: 89.36%
通过执行上面的命令,能查看热点表都在 store 7(227服务器) 这个 TiKV 节点。
(2)查看热点的表 regions 分布:
curl http:// ${tidb_host}:10080/tables/db_name/tb_name/regions > regions.log
(3)手动切分 region:
切分命令如下
pd-ctl -u http:// ${pd_host}:2379 operator add split-region region_id
使用命令找出store7的region id:
grep -B 3 ": 7" regions.log |grep "region_id"|awk -F': ' '{print $2}'|awk -F',' '{print "pd-ctl -u http://pd_host:2379 operator add split-region",$1}' > split_region.sh
(4)执行切分脚本就实现了region切分:
sh split_region.sh
参数优化
(1)调整PD调度参数
pd-ctl -u http://pd_host:2379 config set 参数值
“hot-region-schedule-limit”: 8
“leader-schedule-limit”: 8,
“region-schedule-limit”: 16
上面 3 个参数分别是控制进行 hot-regionleader egion 调度的任务个数。 这个值主要影响相应Region balance 的速度,值越大调度得越快,但是也不宜过大,可以先增加一倍看效果。
(2) TiKV 参数之:sync-log
跟 MySQL 的 innodb_flush_log_at_trx_commit(0,1,2) 类似,TiDB 也有一个 sync-log 参数,该参数控制数据、log 落盘是否 sync。注意:如果是非金融安全级别的业务场景,建议设置成 false,以便获得更高的性能,但可能会丢数据。
该参数是 TiKV 参数,需要调整 tidb-ansible 下 conf 目录中 tikv.yml,然后使用下面的命令,只滚动升级 TiKV 节点。
ansible-playbook rolling_update.yml –tags=tikv
注:本次优化保持默认true
优化后查看效果方式
(1)命令查看 leader 调度情况:
pd-ctl -u http:// ${pd_host}:2379 operator show leader
(2)查看 Grafana 监控图
PD 监控模块中:scheduler模块->Scheduler is running->balance-hot-region-scheduler 看这个是否有值,这个有值代表有热点 region 调度。
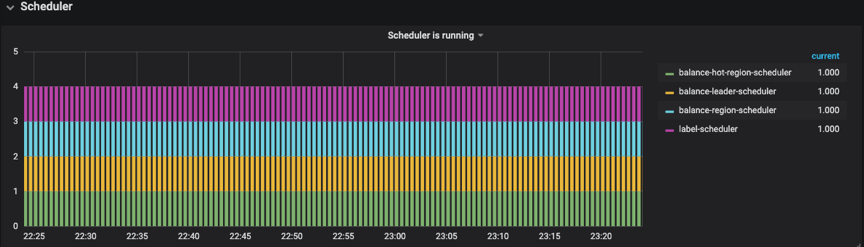
PD 监控模板中:Operator->Schedule operator create->balance-leader

其他就是从 Overview 中,TiKV 模块的 Leader、Region,CPU、Scheduler pending commands 等变化情况。
终极大招之表结构优化
通过手 split 的方式并没有较好地解决业务的写热点问题,我们采用了SHARD_ROW_ID_BITS 结合 PRE_SPLIT_REGION 的方式来打散热点。
对于 PK 非整数或没有 PK 的表,在 insert 的时候 TiDB 会使用一个隐式的自增 rowid,大量 INSERT 会把数据集中写入单个 Region,造成写入热点。通过设置 SHARD_ROW_ID_BITS 来适度分解 Region 分片,以达到打散 Region 热点的效果。使用方式:
ALTER TABLE t SHARD_ROW_ID_BITS = 4; #值为4表示 16 个分片
由于我们的表每天都会新建,所以为了更好的效果,我们也使用了PRE_SPLIT_REGIONS 建表预切分功能,通过配置可以预切分 2^(pre_split_regions-1) 个 Region。
下面的最新的表结构,重要的优化是:删除了自增主键 ID,建表时添加了SHARD_ROW_ID_BITS 结合 PRE_SPLIT_REGION 配置。
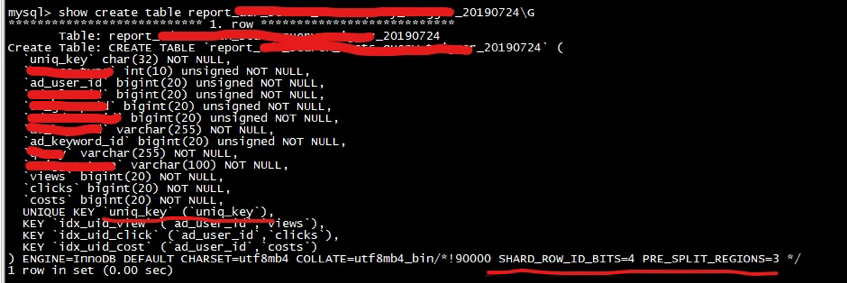
该建表语句会对这个表 t 预切分出 4 + 1 个 Region。4 (2^(3-1)) 个 Region 来存 table 的行数据,1 个 Region 是用来存索引的数据。
关于2个参数使用详情参见下面的链接:


TiDB FAQ | TiDB 官方用户文档
TiDB 是由 PingCAP 研发的一款定位于在线事务处理/在线分析处理(HTAP)的开源融合型数据库产品,实现了一键水平伸缩,强一致性的多副本数据安全,分布式事务,实时 OLAP 等重要特性,目前已广泛应用于金融服务、互联网、制造等行业。
Split Region 使用文档 | TiDB 官方用户文档
TiDB 是由 PingCAP 研发的一款定位于在线事务处理/在线分析处理(HTAP)的开源融合型数据库产品,实现了一键水平伸缩,强一致性的多副本数据安全,分布式事务,实时 OLAP 等重要特性,目前已广泛应用于金融服务、互联网、制造等行业。
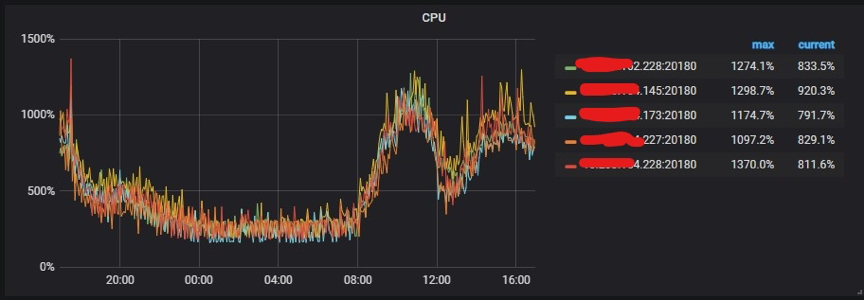
优化最终效果
TiKV 的 CPU 使用非常均衡:
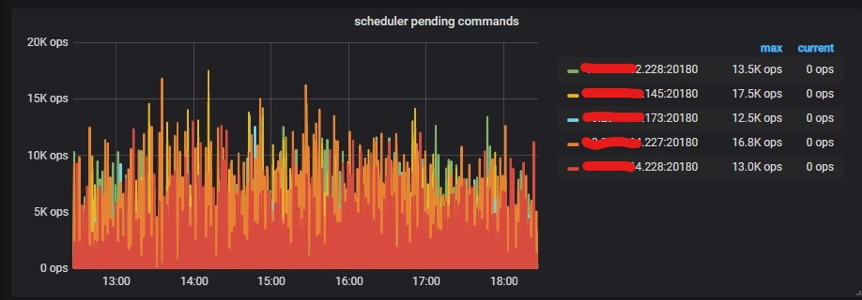
用命令调度来看也比较均衡:
总结
TiKV 作为一个分布式引擎在大部分业务写入中都能较好的分散热点 Region,本文只是拿 360 商业化业务的一个业务场景分享了热点 Region 的分散方法,目的是提供写热点优化的思路,希望能对大家有一定的帮助。本文调优过程中得到了 PingCAP 公司技术人员的大力支持,在此表示衷心的感谢。
作者简介
代晓磊,现360商业化-数据库运维专家。负责整个商业化业务线数据库运维,解决各种数据库疑难问题,推广TiDB等新开源数据库应用。
-
大街网经验累积阶段(2013-06~2019-02):
数据库方面:负责整个数据库Team。
具体做过的骄傲的事儿:
- DB规范制定
- 基于开源搭建大街自动化运维平台
- 大街DB高可用
- MySQL 版本在线升级 (5.1->5.5->5.6->5.7)
- 数据库优化
- 经历各种 DB 分库分表迁移
- DB 备份频度和恢复
- 拥抱开源技术,如 TiDB 数据库/Cobar 高可用中间件/inception 审核系统/Prometheus + Grafana 监控等
- 下线 memcache&ttserver,将大街缓存全部统一到 Redis
- Redis 高可用方案 (Redis cluster/codis/temproxy)
- Redis自动化监控和运维
-
人人网打怪升级阶段(2012-01~2013-06):
2012年校招进入人人,主要负责人人无线数据库以及线下OLAP数据库的维护。
数据分析方面:让数据驱动业务
具体做过的骄傲的事儿:
- 实现了做的了技术也玩的了业务
- 数据分析高效的支持