

摘要:TiDB 敏捷模式是一次非常成功的产品定位。它精准地捕捉了市场上一部分用户“既要鱼(MySQL 的易用),也要熊掌(分布式数据库的扩展性)”的痛点。它不仅仅是一个“测试模式”,而是一个可以承载真实业务、并伴随业务共同成长的生产就绪级解决方案。其带来的敏捷性、经济性和面向未来的可扩展性,使其在云原生数据库领域具备了独特的竞争优势。
--------------------------
上文:
给敏捷模式做下体检——多方位平凯数据库TiDB敏捷模式和MySQL的性能测试(上)
具体测试详情数据:
https://asktug.com/t/topic/1047571
-------------------------
8.集群HA测试
测试目标
本次测试旨在验证三节点 TiDB 集群在关键组件(TiDB、PD、TiKV)发生故障或整个节点宕机时的高可用性、服务自愈能力以及对线上业务性能的影响程度。测试通过模拟真实故障场景,观察系统在故障期间和恢复阶段的性能表现。
测试环境
- 集群架构: 三节点 TiDB 集群,每个节点混合部署了 TiDB、PD、TiKV 服务。
- 负载工具: SysBench,使用
oltp_read_write模式。 - 并发配置: 64 线程。
- 连接方式:通过部署HA连接虚拟IP,配置为192.168.151.100:4100
测试用例与结果分析
第一轮测试: Kill TiDB-Server
- 测试操作: 在 110s - 120s 期间,手动 Kill 103 节点的
tidb-server进程。 - 观测结果:
- 故障瞬间: SysBench 立即报错
FATAL: Lost connection to MySQL server during query,线程中断。这是因为浮动 IP 指向的 103 TiDB 实例被终止,导致所有通过该浮动 IP 的连接瞬间断开。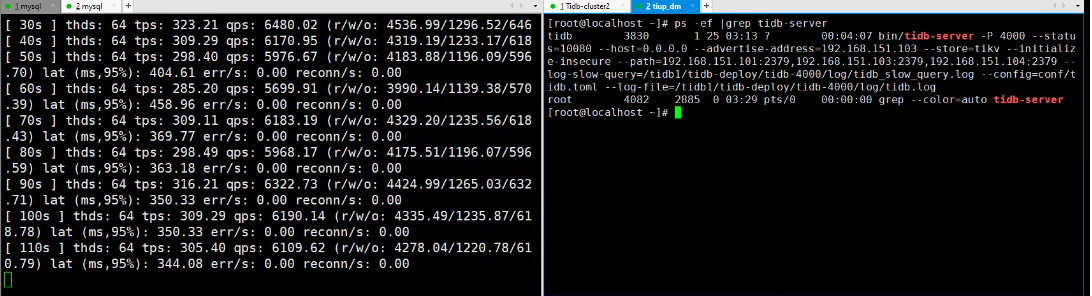
- 性能影响:
- 故障前 (10s-110s): TPS 稳定在
285 - 335之间,平均约 308。95% 延迟在325 - 458ms之间。 - 故障后 (重启负载): (重要变化) 重启 SysBench 后,浮动 IP 依然指向已恢复的 103 TiDB 节点。TPS 在恢复初期出现波动(最低
173.63),但迅速在 30s 内恢复到300+的水平,平均性能与故障前基本一致。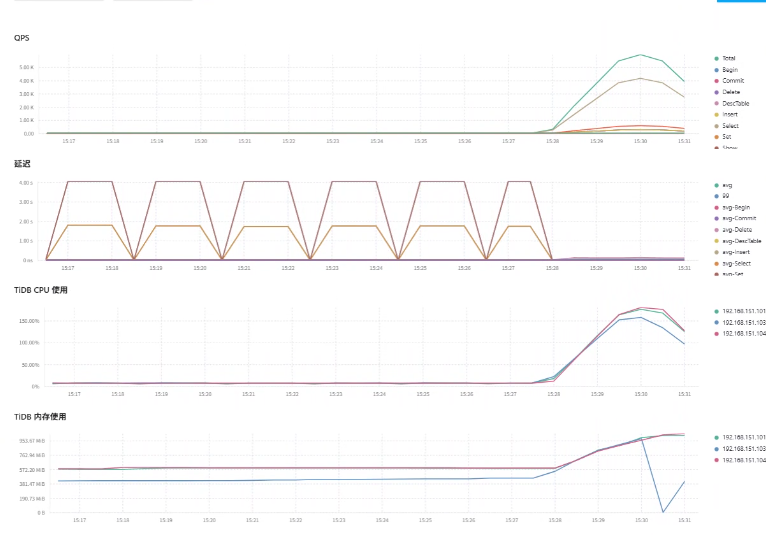
- 故障前 (10s-110s): TPS 稳定在
- 故障瞬间: SysBench 立即报错
- 结论:
- 高可用性: TiDB 是无状态组件,kill 掉一个 TiDB-Server 对集群本身(PD、TiKV、数据)毫无影响。只需重新启动该进程,服务即刻恢复。
- 业务影响: 通过负载均衡器HAProxy连接的应用,在某个 TiDB 节点宕机时,连接会自动路由到其他健康的 TiDB 节点。对于故障节点上的连接,应用需要配置合理的重试机制来重新建立连接。新查询会被无缝接管。
- 内部机制: TiDB 节点是无状态的。其高可用依赖于外部的负载均衡和应用的连接重试。
第二轮测试: Kill TiKV-Server
- 测试操作: 在 180s - 190s 期间,手动 Kill 103 节点的
tikv-server进程。 - 观测结果:
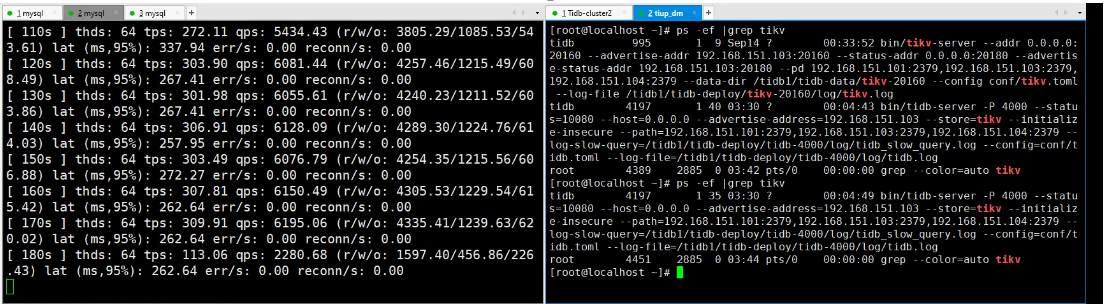
- 性能影响:
- 故障前 (10s-170s): TPS 稳定在
300 - 316之间(排除初始10s的预热阶段),平均约 305。95% 延迟较低(248 - 502ms)。 - 故障瞬间 (180s-200s): TPS 出现断崖式下跌(从
113.06骤降至33.41),95% 延迟飙升至 15.3秒。这表明有大量请求因 Region Leader 失效或副本重新均衡而超时。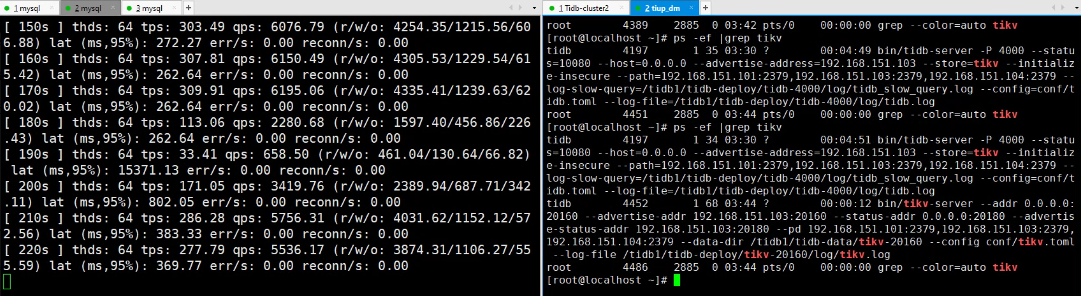
- 恢复期 (200s-240s): TPS 和延迟出现显著波动(
110 - 286),表明集群正在调度数据副本和选举新的 Region Leader。 - 完全恢复 (250s之后): TPS 恢复并稳定在
275 - 295之间,平均约 282,相比故障前下降约 7.5%。95% 延迟恢复至277 - 520ms。
- 故障前 (10s-170s): TPS 稳定在
- 性能影响:
- 结论:
- 业务影响: 在至少存在一个健康副本的前提下,对正在进行的事务和查询几乎无感知。可能会有极短暂的抖动(毫秒级),但无需人工干预,应用端无需重连。
- 内部机制: 依靠 Raft 共识协议。当 Leader Region 的节点失效,剩余副本会迅速选举出新的 Leader,整个过程自动完成。PD 会感知到节点下线,并后续在健康节点上补足数据副本,确保复制因子。
第三轮测试: Kill PD-Server
- 测试操作: 于 110s - 120s 期间 Kill 103 节点的
pd-server。 - 观测结果:
- 故障前 (10s-110s): TPS 非常稳定,平均 306,95% 延迟在
248 - 493ms。
- 故障后 (370s之后): 本次出现了异常情况。在故障发生约 260s 后(370s),TPS 再次暴跌至个位数(最低
1.30),95% 延迟高达 17.4秒,并持续了较长时间。
- 故障前 (10s-110s): TPS 非常稳定,平均 306,95% 延迟在
- 结论:
- 业务影响: 写入和查询完全无影响。集群的元数据管理和调度功能在几秒钟内完成新 Leader 选举,期间对数据操作无阻塞。
- 内部机制: PD 节点间通过 Raft 协议保证一致性。故障转移快速且自动。
- 高可用性: PD 集群本身具备高可用能力,Leader 选举快速。
第四轮测试: 模拟主机宕机
- 测试操作: 在 120s 时,直接关闭 101 主机(其上同时部署了 TiDB、PD、TiKV)。
- 观测结果:
- 故障瞬间: TPS 直接从
111降至0,并持续了 20s(130s, 140s 两个采样点),表明服务完全中断。 - 切换与恢复: 客户端重启新负载连接到其他节点后,服务恢复。
- 故障前 (10s-110s): 平均 TPS 304。
- 故障后 (新负载): 平均 TPS 198,性能下降约 35%。95% 延迟也更高。

- 故障瞬间: TPS 直接从
- 结论:
- 业务影响: 单节点主机宕机是最严重的故障场景。它同时影响了 TiDB、PD、TiKV 三个组件。
- 导致所有连接到该 TiDB 实例的客户端会话中断。
- 如果该节点是 PD Leader 或承载了大量 Region Leader,会引发元数据服务和数据服务的双重震荡。
- 即使服务恢复,由于集群资源减少(从 3 节点变为 2 节点有效工作),整体性能会出现下降,直到节点恢复并重新平衡。
- 业务影响: 单节点主机宕机是最严重的故障场景。它同时影响了 TiDB、PD、TiKV 三个组件。
综合结论:
- TiDB 节点故障
作为无状态计算节点,其故障不影响集群本身与其他现有连接。主要影响是导致直连该节点的客户端会话中断,业务恢复依赖于客户端的重连能力与负载均衡器的切换速度。新引入的 TiProxy 组件 能在此场景下实现连接的无感知迁移,显著提升业务连续性,尤其在节点计划内维护时效果更为突出。
- PD 节点故障
PD 集群通过 Raft 协议实现高可用。单个节点故障对服务无感知,影响极小;仅当多个节点同时故障时,才可能因 Leader 重选举导致元数据操作出现短暂延迟。
- TiKV 节点故障
这是对业务影响最直接的场景。节点故障会立即触发其承载的 Region Leader 重选举与数据副本的自动补齐,可能导致相关读写出现短暂的性能抖动和超时。集群能快速恢复服务且数据不会丢失,但整体吞吐量会因资源减少而下降,且在副本补齐过程中会占用部分后台资源。
- 整机/可用区宕机
该场景考验集群的极限高可用能力。只要故障未导致任一数据的所有副本同时丢失,集群就能通过 Raft 协议自动恢复服务,保证数据强一致性。恢复后,集群的总体服务能力会因资源减少而下降。
- 高可用能力综述
TiDB 的高可用性根植于其全组件冗余的架构与 Raft 共识算法的深度应用。从无状态的计算层(TiDB)、高可用的调度层(PD)到多副本的存储层(TiKV),共同构成了一个韧性的基础。如今,通过引入 TiProxy 等组件进一步增强业务连续性,使得 TiDB 能够在单一组件乃至单个可用区故障时,实现业务的快速自动恢复与数据的强一致性保证,为业务构建了更坚实的数据底座。
9.多集群管控功能
测试环境准备
SSH互信配置:
# 在TEM服务器上生成SSH密钥对并分发
sudo -u tidb ssh-keygen -t rsa -b 4096
sudo -u tidb ssh-copy-id tidb@<managed_node_ip>
多集群部署测试
部署平凯数据库敏捷模式集群
集群部署:
参考前面几章节,本部分直接略过。

日常管理测试
1、集群监控与告警
监控面板验证:
- 访问TEM监控中心,查看多集群监控数据
- 重点关注指标:QPS/TPS趋势、节点资源使用率、存储容量、网络流量
2、告警规则配置:
- 进入"监控中心"->"告警管理"
- 创建自定义告警规则:

# TiDB 服务器 P99 查询延迟超过阈值(例如 1 秒)
histogram_quantile(0.99, sum(rate(tidb_server_handle_query_duration_seconds_bucket[2m])) by (le, instance)) > 1
# TiKV GRPC P99 请求延迟过高(例如 0.5 秒)
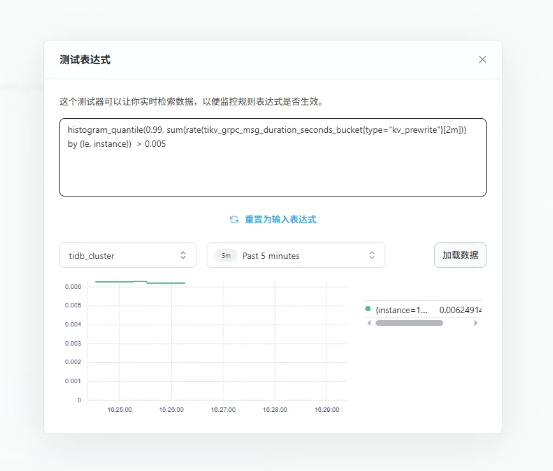
histogram_quantile(0.99, sum(rate(tikv_grpc_msg_duration_seconds_bucket{type="kv_prewrite"}[2m])) by (le, instance)) > 0.5
PromQL语法实时验证
触发告警验证是否配置正确
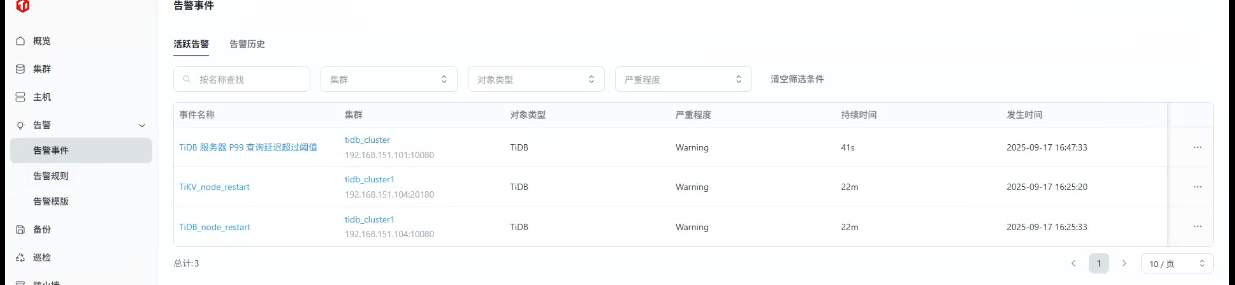
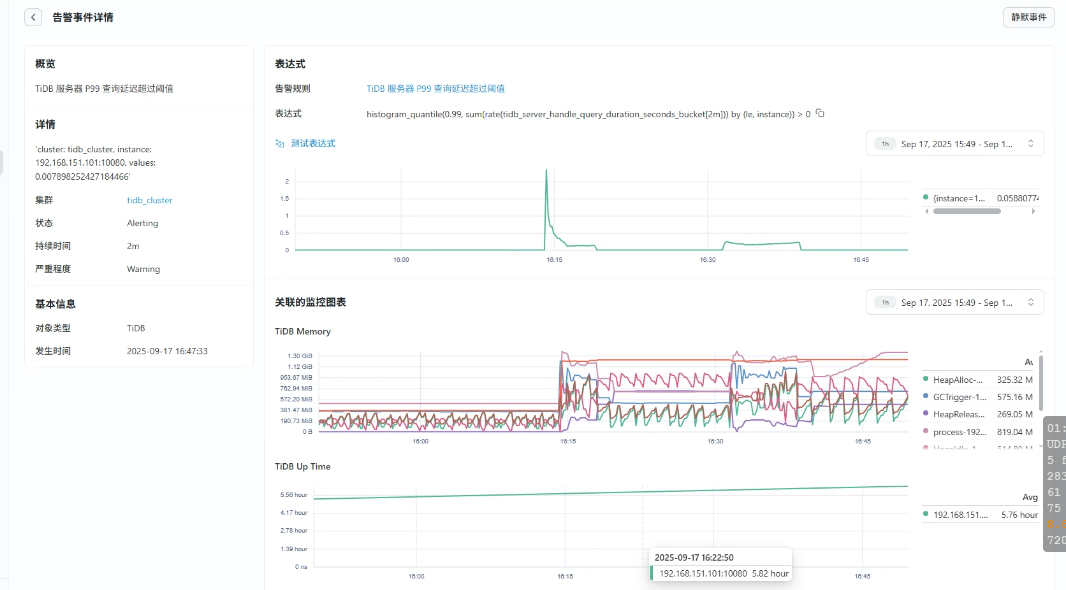
3、集群巡检功能
-
执行定期巡检:
-
进入"集群管理"->"巡检管理"
-
创建巡检任务,选择多个集群,设置周四自动巡检
-

-
手动触发立即巡检,检查巡检报告内容:
-
-
查看巡检报告:
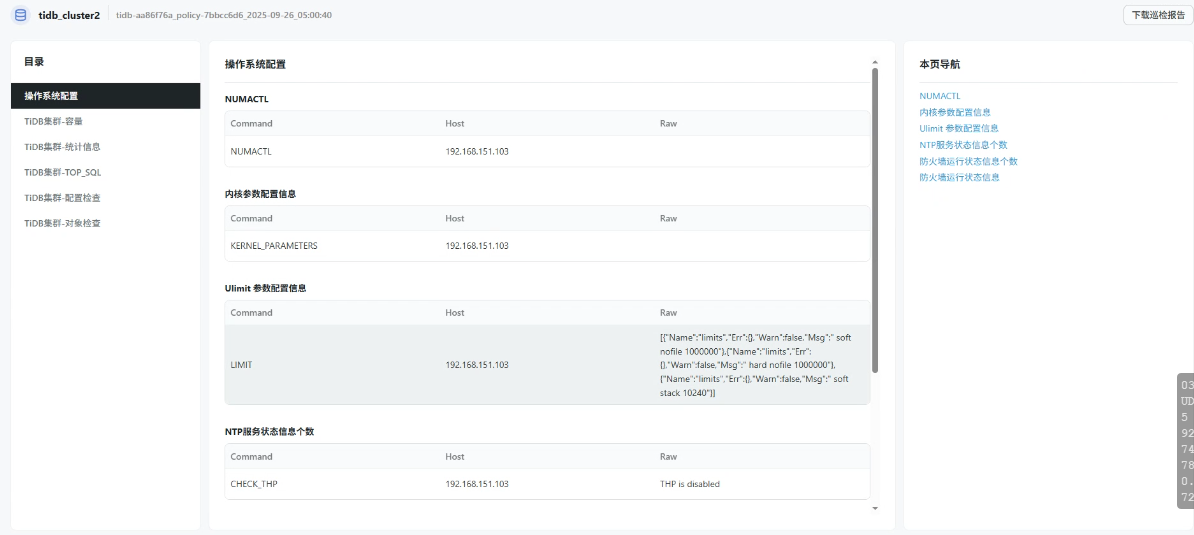
- 查看生成的巡检报告,了解集群状态和潜在问题
- 根据巡检建议进行优化调整
4、备份与恢复
-
配置备份策略:
-
进入"集群管理"->"备份恢复" -
为cluster-1配置全量备份策略:
- 备份类型:全量备份
- 备份周期:每天凌晨2:00
- 保留时间:7天
-
为cluster-2配置增量备份策略:
- 备份类型:增量备份
- 备份周期:每小时一次
- 保留时间:24小时
-
-
手动备份执行:
- 对cluster-1执行手动全量备份

- 监控备份过程,确认备份成功完成

- 对cluster-1执行手动全量备份
-
数据恢复测试:
选择cluster-1的备份记录,执行数据恢复
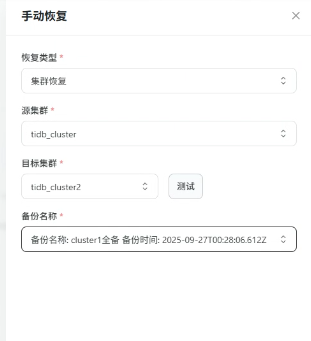
选择恢复到新集群cluster-3

验证恢复后的数据一致性
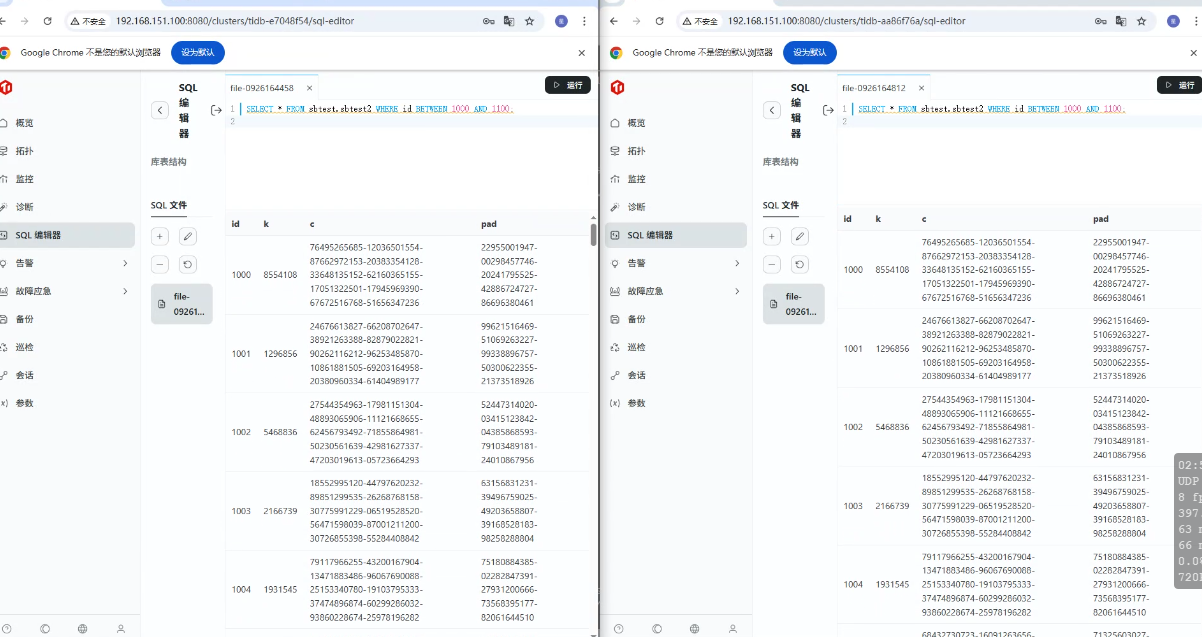
-- 在原始集群和恢复集群上执行数据校验 SELECT COUNT(*) FROM test.tbl; CHECKSUM TABLE test.tbl;
抽样验证:对关键字段进行抽样查询,验证具体数据内容
SELECT * FROM sbtest.sbtest2 WHERE id BETWEEN 1000 AND 1100;
备份策略配置:
- cluster-1:全量备份,每日02:00执行,保留7天
- cluster-2:增量备份,每小时执行,保留24小时
备份完整性验证:
# 检查备份文件状态
ls -lh /data/backup/cluster-1/
cat /data/backup/cluster-1/backupmeta
测试总结
| 测试项目 | 验收标准 | 通过要求 |
|---|---|---|
| 多集群部署 | 成功创建两个敏捷模式集群,TEM统一管理正常 | 集群状态正常,管理功能完备 |
| 监控告警 | 自定义告警规则生效,触发时间<3分钟,通知正常 | 三项指标全部达标 |
| 巡检功能 | 报告生成时间<5分钟,问题识别准确率>95% | 准确率>95%且包含具体建议 |
| 备份恢复 | 备份成功率100%,RTO<30分钟,数据一致性100% | 三项指标全部满足 |
核心优势:
- 统一管理界面显著降低多集群运维复杂度
- 白屏化操作有效减少命令行操作错误率
- 监控告警功能助力快速问题发现和解决
- 备份恢复机制保障业务数据安全可靠
10.优势与场景总结
1. 所在行业哪些场景会建议用敏捷模式
TiDB 敏捷模式并非一个“缩水版”的分布式数据库,而是一个针对特定场景进行精准优化的解决方案。基于其 “单机部署、简化运维、完整兼容 MySQL、保留核心弹性能力” 的特点,以下行业和场景是其理想的应用土壤:
-
金融科技与互联网金融:
- 创新业务与敏捷试错项目: 对于新的金融产品、营销活动平台或内部管理系统,在立项初期,业务规模和数据量不确定。敏捷模式可以快速搭建,让团队使用与未来生产环境(完整 TiDB 集群)完全兼容的数据库进行开发,极大降低前期基础设施投入和复杂度。
- 历史数据查询与归档系统: 对于一些非核心但需要在线查询的历史数据,使用敏捷模式可以以较低的成本存储,并利用 TiDB 的 SQL 能力提供查询服务,避免了在昂贵的核心交易库上保留全量历史数据。
-
互联网与 SaaS 服务:
- 初创期与成长期的 SaaS 应用: 当企业处于从 0 到 1 或 1 到 N 的阶段时,数据量会逐步增长。敏捷模式允许他们以一个极低的起点(单机)开始,享受 TiDB 的强一致性、高可用和 MySQL 协议兼容性。当业务规模扩大,数据量和并发量超越单机极限时,可以平滑地在线升级至完整的分布式集群,无需进行痛苦的数据迁移和代码改造。
- 微服务中的特定业务数据库: 在一个微服务架构中,并非所有服务都需要强大的分布式能力。对于某些数据量不大但希望获得稳定、可靠数据库服务的微服务,可以为其单独部署一个敏捷模式实例,实现资源隔离和技术栈统一。
-
物联网与智能硬件:
- 边缘计算场景: 在工厂、楼宇等边缘侧,计算资源有限,但需要处理和分析本地产生的设备数据。敏捷模式的轻量级部署和单机高性能非常适合在此类场景下作为边缘数据枢纽,进行初步的数据处理和缓存,再择机同步到中心云的全量 TiDB 集群。
-
传统行业数字化转型:
- 传统系统的现代化改造试点: 许多传统企业(如制造业、零售业)的核心系统仍基于 Oracle 或 DB2。在启动现代化改造时,可以选取一个非核心的业务模块,使用 TiDB 敏捷模式作为替代数据库进行试点。团队可以快速验证技术路线的可行性,并培养相关技术人才,成本可控,风险极低。
核心建议原则: 当业务需要 TiDB 的稳定性和生态(MySQL 兼容),但暂时不需要其极致的横向扩展能力,或者正在为未来的规模化扩张寻找一个可以平滑演进的数据库起点时,TiDB 敏捷模式是一个非常明智的选择。