

一、背景
1.1 关于 NUMA
统一内存访问架构(Uniform Memory Access,简称UMA),所有的物理存储器通过前端总线被均匀共享,即处理器访问它们的延迟是一样的,前端总线带宽是被共享的。
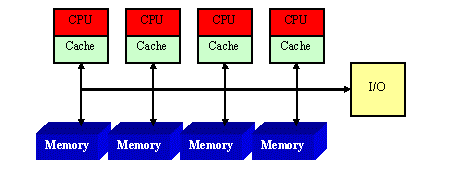 图 1. UMA
图 1. UMA
非统一内存访问架构(Non-uniform memory access,简称NUMA),是一种为多处理器计算机设计的内存架构,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
非统一内存访问架构的特点是:被共享的内存物理上是分布式的,所有这些内存的集合就是全局地址空间。所以处理器访问这些内存的时间是不一样的,显然访问本地内存的速度要比访问全局共享内存或远程访问外地内存要快些。
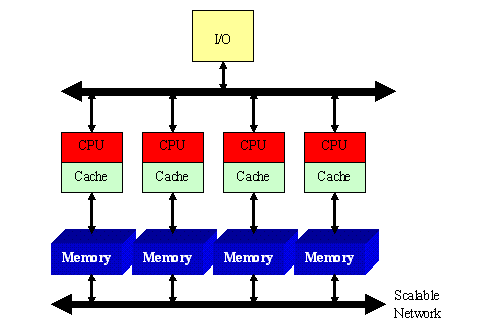
图 2. NUMA
1.2 主流 X86 CPU 的 NUMA 状况
TIDB 大多部署在 Intel X86 服务器上,其中 on premise 部署以双路服务器(即安装 2 块 CPU 的服务器)居多,即使在 vcore 数目(开启超线程后的逻辑 core 数)多如 96vcore 的双路 Intel 服务器上,我们也只能看到两个 NUMA node,这是由于 Intel 的传统架构是用一个 die 承载全部 core,共享一个内存控制器,即每块 CPU 为一个 NUMA node。
这样的架构具备更好的多路扩展性和软件兼容性,Intel Xeon 很早就实现了 4 路服务器的 NUMA 架构。
Intel 下一代 CPU 架构将转变其以往使用大面积 die 承载全部 core 的策略,不在执着于更大面积的 die(晶圆利用率低、良品率低),改为“可扩展”的单 CPU 多 die 架构(即单 CPU 多 NUMA node)。

图 3. Intel 新一代 CPU 的架构转变,引用自 Intel
AMD 早在其“推土机”时代就开始尝试模块化设计,但受制于制程、软件兼容性等因素,过分强调更多的核心数目而忽略了单核性能,使其在很长一段时间都未被市场认可,直到 ZEN 时代才真正可以和 Intel 抗衡,ZEN 架构的特点是模块化,用小面积的 die “拼接”出多核心的 CPU,每个 die 至多承载 8 core,这使得 AMD 在一定程度上延续着摩尔定律。而 Intel 则创造了一个 die 承载 28 core 的记录。
ZEN 架构的特点:
- 每个 die 最多 8 个 core
- die 面积小,晶圆利用率高,良品率高
- 每个 die 具备独立的内存控制器,即每个 die 为一个 NUMA node(图 4)
- 像贴拼图一样将多个 die 贴到一块 CPU 上,一块 CPU 上可以集成更多 core(图 5)
- die 之间、socket 之间通过 Infinity Fabric 连接(图 6)
AMD 的家用 CPU 产品线 Ryzen 逐渐成为了高端装机市场的主流,而其的服务器 CPU 产品线 EPYC 市场占有率还远低于 Intel Xeon。

图 4. die 内部架构,AMD 称其为 CCX 架构,引用自 AMD

图 5. AMD EPYC 多核服务器 CPU,引用自 AMD

图 6. 双路 EPYC 连接方式,引用自 AMD
1.3 过多的 NUMA node 带来的性能问题
服务器的负载特点与家用计算机偏重多任务处理的负载特点存在较大差异,一台服务器上运行的软件往往比较单一,尤其是从 CPU 使用率的角度看,服务器往往被一个程序占据绝大部分的计算资源。OS 可以将多个程序调度到不同的 NUMA node 上运算,但 OS 没法将一个单独的程序在多个 NUMA 上进行拆分处理。单机多 NUMA 的服务器在过去比较少见,我们还缺少 TiDB 在 ZEN 架构服务器【超多 NUMA node】上的部署经验。
二、硬件信息和测试模型
本次测试采用 4 台双路服务器,每台服务器配置为 128vcore,512GB 内存,8 NUMA node,2*3TB NVMe SSD,双万兆网卡。
2.1 NUMA 拓扑
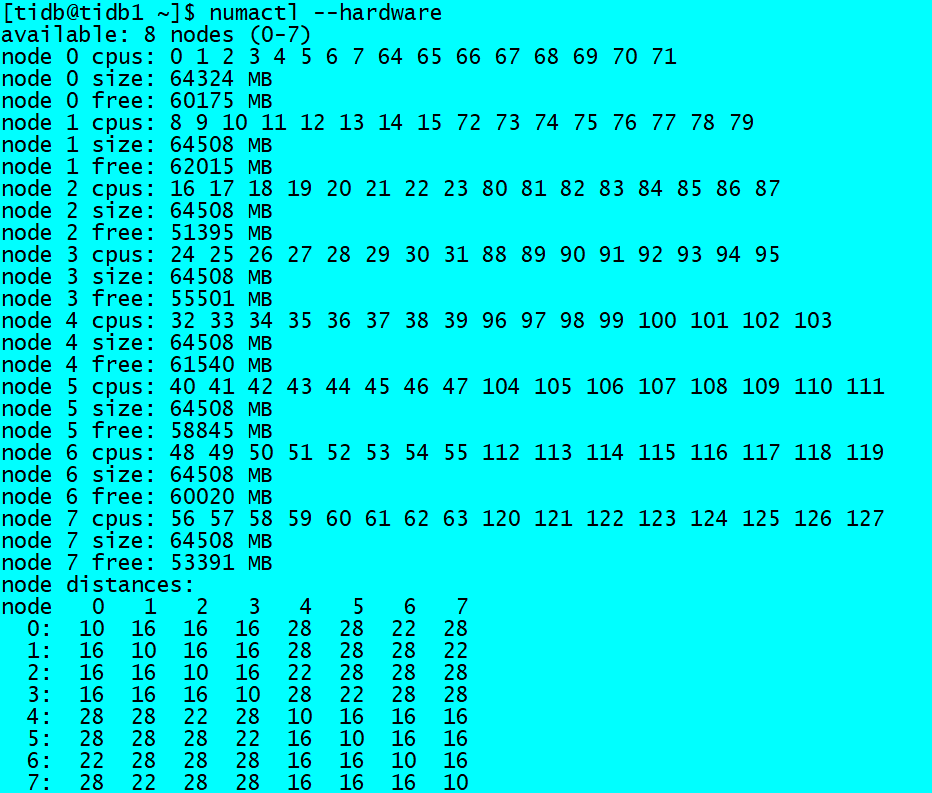
图 7. OS 提供的 NUMA 信息
根据 NUMA node 距离信息,可以得知 NUMA 逻辑架构如图 8 所示,与图 6 中 AMD 官方信息一致,图 8 中的:
- 线上的数字代表距离
- 每个 NUMA node 访问自己本地内存的距离为 10
- 访问远端内存的数据需要更大的距离,例如 node0 上的计算要访问 node7 上本地内存的数据,访问距离为 28 (12+6+10)
跨 NUMA node 的内存访问会造成延迟增加。除此之外,高频的跨 NUMA node 内存1访问会由于触及带宽瓶颈而进一步增加延迟。

图 8. 双路服务器的 NUMA 逻辑图
2.2 服务器硬件绑核信息
建议将存储节点绑定在 nvmessd 所在 NUMA node 上;同时还建议在计算资源充足时,让集群通讯的网卡独享一个 NUMA node。
硬件绑核信息:
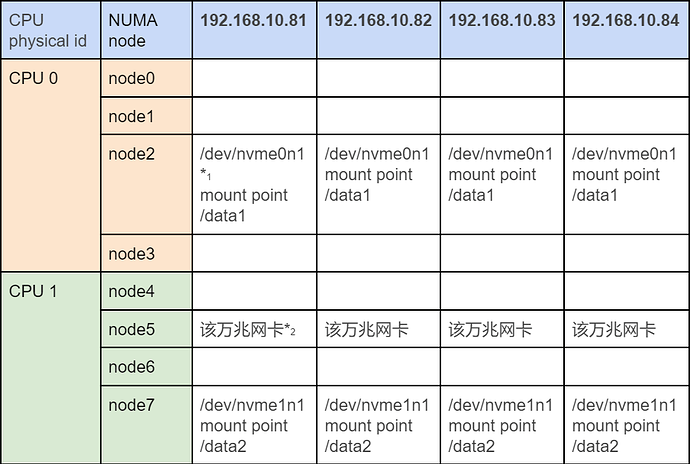
*1 查看磁盘绑核位置:cat /sys/block/nvme0n1/device/device/numa_node
*2 查看网卡绑核位置:ethtool -i eth0 输出的 bus-info 中 51 的 5 代表 node 5
2.3 测试模型和数据量
采用 sysbench 测试模型,8 个 sbtest 测试库,每个 sbtest 库 32 张表,每张表 10000000 行记录。以下测试每个 sysbench 实例使用独立的 sbtest 测试库进行压测,以减少多个 sysbench 进程由于数据争用而造成干扰。
三、BIOS 中 NUMA 相关设置策略
下面的描述摘自 DELL 服务器(AMD EPYC CPU)官方 BIOS 手册中有关 NUMA 设置的部分,单机数据库如 MySQL 使用 NPS1 设置可以有效的避免跨 socket(即物理 CPU)的内存访问。
在 TiDB 集群服务器上,我们更建议将设置调整为 NPS4,也就是不在 BIOS 层面做任何“优化”,展现 NUMA 架构在其硬件层面的样子,完全的手动挡模式。借助于 TiDB 的分布式、存储计算分离的架构,可以通过妥善的 NUMA node 绑定策略来进一步避免同一 CPU 内跨 die 的内存访问;同时,更精细的 NUMA node 绑定策略也带来了更好的计算资源隔离,减少多个实例部署在同一台服务器上的相互干扰。
NUMA and NPS
Rome processors achieve memory interleaving by using Non-Uniform Memory Access (NUMA) in Nodes Per Socket (NPS). The below NPS options can be used for different workload types:
- NPS0 – This is only available on a 2-socket system. This means one NUMA node per system. Memory is interleaved across all 16 memory channels in the system.
- NPS1 – In this, the whole CPU is a single NUMA domain, with all the cores in the socket, and all the associated memory in this one NUMA domain. Memory is interleaved across the eight memory channels. All PCIe devices on the socket belong to this single NUMA domain.
- NPS2 – This setting partitions the CPU into 2 NUMA domains, with half the cores and memory in each domain. Memory is interleaved across 4 memory channels in each NUMA domain.
- NPS4 – This setting partitions the CPU into four NUMA domains. Each quadrant is a NUMA domain, and memory is interleaved across the 2 memory channels in each quadrant. PCIe devices will be local to one of the 4 NUMA domains on the socket, depending on the quadrant of the IOD that has the PCIe root for the device.
四、TiKV 绑核策略
我们通过两种部署拓扑来对比 TiKV 在绑定 1 个 NUMA node 和 2 个 NUMA node 时的性能差距。为充分利用服务器资源,本测试采用 4 台服务器混合部署多个组件的方式,单机部署 2 TiDB 实例和 2 TiKV 实例。
部署拓扑 A:
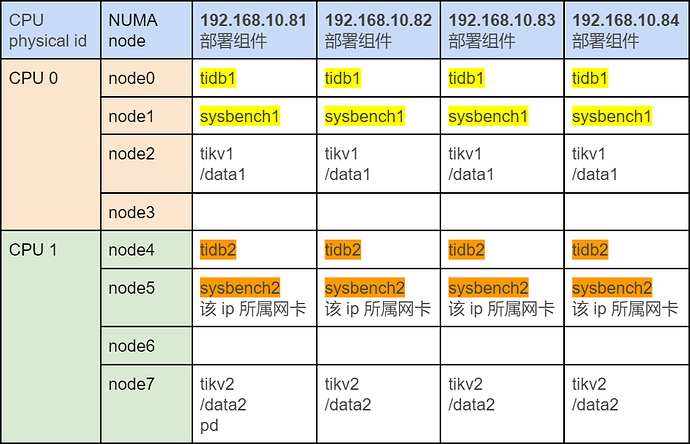
拓扑 A 配置参数:
tidb:
log.level: error
oom-use-tmp-storage: false
performance.max-procs: 16
performance.txn-total-size-limit: 2147483648
prepared-plan-cache.enabled: true
split-table: true
tikv-client.copr-cache.capacity-mb: 10240.0
tikv-client.max-batch-wait-time: 2000000
tikv:
coprocessor.split-region-on-table: true
pessimistic-txn.pipelined: true
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 12
server.enable-request-batch: false
server.grpc-compression-type: none
storage.block-cache.capacity: 64GB
storage.block-cache.shared: true
raftstore.store-pool-size: 3
部署拓扑 B:
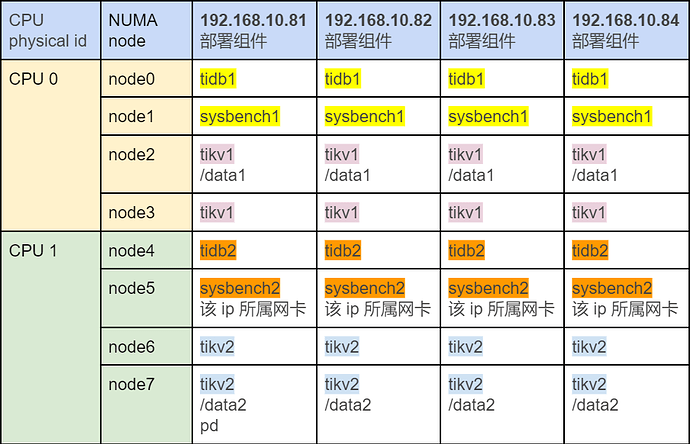
拓扑 B 配置参数:
tidb:
log.level: error
oom-use-tmp-storage: false
performance.max-procs: 16
performance.txn-total-size-limit: 2147483648
prepared-plan-cache.enabled: true
split-table: true
tikv-client.copr-cache.capacity-mb: 10240.0
tikv-client.max-batch-wait-time: 2000000
tikv:
coprocessor.split-region-on-table: true
pessimistic-txn.pipelined: true
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 24
server.enable-request-batch: false
server.grpc-compression-type: none
storage.block-cache.capacity: 128GB
storage.block-cache.shared: true
raftstore.store-pool-size: 3
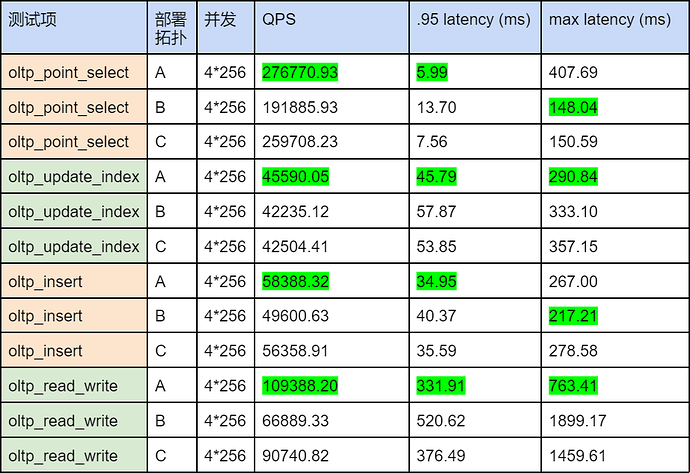
测试报告:
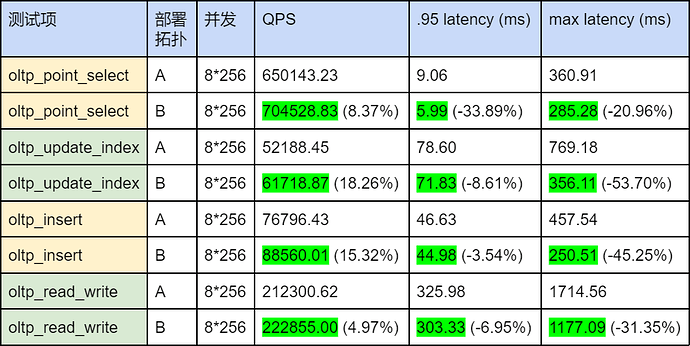
从测试结果可以得出,相比于绑定一个 NUMA node,将 TiKV 绑定至同一块 CPU 的两个 NUMA node 上可以获得 20% 以内的性能提升,这种部署方式适合单台服务器没有足够的磁盘来部署更多的 TiKV,如单机有 8 个 NUMA node,但只有 4 块磁盘,可以尝试单机部署 4 TiKV 实例,每实例绑定统一块 CPU 上的两个 NUMA node。
五、TiDB 绑核策略
在以往的 Intel 服务器使用经验中,我们就总结了每个 TiDB 实例要绑定在一个 NUMA node 上的使用经验。本测试我们对比 4 个 TiDB 实例各自绑定 1、2、4 个 NUMA node 三种绑定策略中的性能差距。
配置参数:
tidb:
log.level: error
oom-use-tmp-storage: false
performance.max-procs: 16
performance.txn-total-size-limit: 2147483648
prepared-plan-cache.enabled: true
split-table: true
tikv-client.copr-cache.capacity-mb: 10240.0
tikv-client.max-batch-wait-time: 2000000
tikv:
coprocessor.split-region-on-table: true
pessimistic-txn.pipelined: true
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 24
server.enable-request-batch: false
server.grpc-compression-type: none
storage.block-cache.capacity: 128GB
storage.block-cache.shared: true
raftstore.store-pool-size: 3
部署拓扑 A:
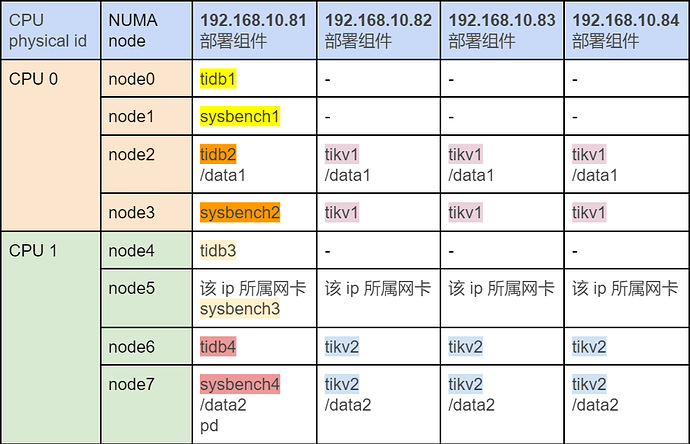
部署拓扑 B:

部署拓扑 C:
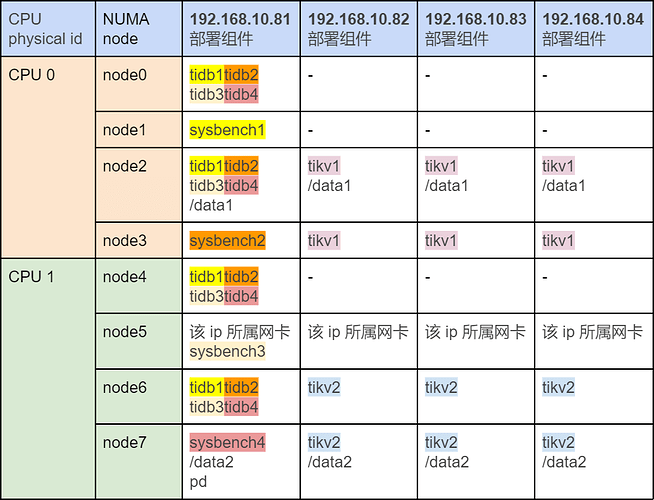
测试报告:
从测试结果可以得出,TiDB 实例需要严格执行与 NUMA node 的一对一绑定,才能最大化性能。
六、是否开启 kernel.numa_balancing
Linux 内核提供一个 numa_balancing 调度参数,通过本测试明确是否开启 OS 层面的 NUMA 自动平衡。
配置参数:
tidb:
log.level: error
oom-use-tmp-storage: false
performance.max-procs: 16
performance.txn-total-size-limit: 2147483648
prepared-plan-cache.enabled: true
split-table: true
tikv-client.copr-cache.capacity-mb: 10240.0
tikv-client.max-batch-wait-time: 2000000
tikv:
coprocessor.split-region-on-table: true
pessimistic-txn.pipelined: true
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 24
server.enable-request-batch: false
server.grpc-compression-type: none
storage.block-cache.capacity: 128GB
storage.block-cache.shared: true
raftstore.store-pool-size: 3
部署拓扑:
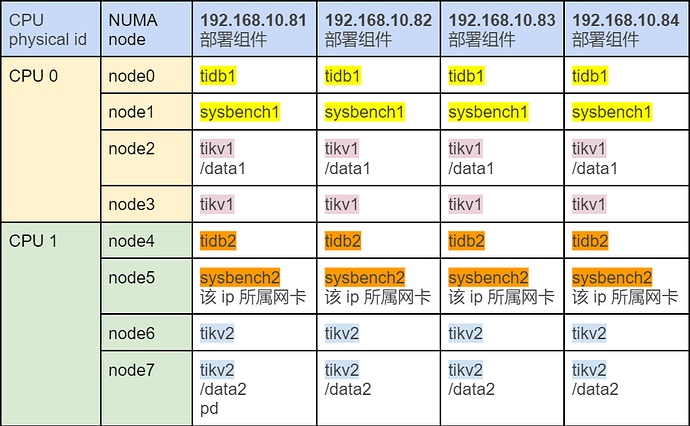
测试报告:

两个测试的 CPU 使用率,左 0 右 1:

图 10. CPU 使用率
可见,关闭 kernel.numa_balancing 的性能更好,打开 kernel.numa_balancing 会出现不必要的调度(右侧曲线)。
七、总结
结合以往使用经验,以及本次实测结果,总结多 NUMA 服务器部署建议如下:
- 采购服务器时,应充分规划,为每个 NUMA node 分配同样容量的内存。
- NUMA是物理架构,操作系统或者 BIOS 中禁用 NUMA 只是将所有核心逻辑合并为 1 个 NUMA node,物理架构并没有改变,性能会下降。
- DELL 服务器 BIOS 中 NUMA and NPS 配置为 NPS4
- 关闭 Linux 内核的 NUMA 自动均衡设置
sysctl -w kernel.numa_balancing=0 - 计算资源充足时,建议避开集群通信网卡所在的 NUMA node 进行绑核,给组件通信留有足够的计算资源。
查看网卡绑核位置:
ethtool -i eth0输出的 bus-info 中 51 的 5 代表 node 5 - TiDB 与 NUMA node 一对一绑定,根据需要单机部署多个 tidb-server
- TiKV 需要绑定到 nvmessd 所在的 NUMA node 上
查看磁盘绑定位置:
cat /sys/block/nvme0n1/device/device/numa_node - 8 NUMA node 的服务器上,建议部署 8 TiKV 实例,充分利用计算资源,通过单机管理更大数据量的方式来降低整体成本。如果在 8 NUMA node 服务器上部署 4 个 TiKV 实例,则建议将每个 TiKV 实例绑定在同一 CPU 的两个 NUMA node 上。
- TiDB 或 TiKV 内存不足时可以用 preferred 替代 membind 绑核参数,优先使用本 NUMA node 对应内存,内存不足会启用其他 NUMA node 的内存。
- 绑核后资源相对隔离,单机可以混合部署多种组件。
- 使用千兆网卡或万兆网卡时,依赖 irqbalance 做网卡中断调度,在使用 100G 或更大带宽的网卡时,考虑做网卡中断绑定设置。