

不定期更新,记录一些小知识,欢迎指正,本帖尽量使用文字描述,相关图片尽量粘贴,方便大家搜索~

为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。 【TiDB 版本】: v3.0.7, dm-v1.0.2 【问题描述】: 我有一个这样的迁移规划,但最后一部分不知道是否可行,希望能给我一点建议和帮助。 打开DM全量+增量同步数据到TiDB 线上读流量切换到TiDB,进行观察 没有问题后写流量切换到TiDB,同时关闭DM。 第三步中可能部分服务在写Mysql通…
答: DM + 完全业务双写 该方案是在应用端实现双写,并且在指定时间窗口上线双写功能,运行稳定后,可评估写流量切换到 TiDB。
1)使用 DM 完成业务数据的全量和增量同步
2)寻找时间窗口将线上以及 DM 的流量同时切断,并确认数据是否完全同步
3)应用程序端上线双写功能
4)DM 不再作为增量同步的介质,评估后可计划下线
5)应用端正常写入数据到 MySQL 以及 TiDB
6)评估后,写流量切换至 TiDB
 tikv log 日志保存数量限制怎么限制 TiDB 系统架构与原理
tikv log 日志保存数量限制怎么限制 TiDB 系统架构与原理
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。 【TiDB 版本】:v3.0.8 【问题描述】:tikv 服务所在服务器的tikv log 一直增加,旧日志并未减少
答:
如果使用 tidb-ansible 部署,默认编辑 conf/tikv.yml 模板文件,修改相关的参数并执行滚动重启生效就可以了,包括 info-log-max-size、 info-log-roll-time 和 info-log-keep-log-file-num info-log-keep-log-file-num:这个参数是 rocksdb 的日志保留策略,tikv 日志目前还没有相关的参数,需要定期清理一下
rocksdb 的日志位于 {deploy_dir}/data 下的 raft 和 db 目录下,文件名为 LOG 和 LOG.old.xxx; tikv 的日志目前有 log-rotation-timespan,默认 24h 切换一次,对于历史日志需要通过定时任务清理下。
 上游mysql ddl,dm同步延迟近7个小时 数据迁移和数据同步
上游mysql ddl,dm同步延迟近7个小时 数据迁移和数据同步
@qizheng-PingCAP谢谢周末一直在支持+1 此问题已经解决,问题是在配置task配置文件时没有加 online-ddl-scheme: “pt” 这个过滤条件,导致最终上游mysql大表ddl操作卡住。 文件添加位置: [image] 因为我这是中途加入这个参数,所以已经有部分操作不可逆了,只能选择跳过卡住的binlog位点。 在跳过binlog这个操作上使用 sql-ski…
答:
DM 增量同步到 TiDB 太慢了
online-ddl-scheme: ‘pt’
这里面正常上游执行 pt-osc ,dm 会跳过相关的拷贝表操作,但是不设置这个参数,dm 还会处理
上游几千万的表执行这个操作,产生了大量的 binlog 需要消费
但是 rename 那里会报错,需要处理下,因为 tidb 不支持一个语句同时 rename 两个

知道了,我选监控的时间段选择了,最近一小时,所以显示了,老的数据。 但是。 [image] 在 tidb-cluster-pd 视图中,下线成功,还显示 3个 ,Tombstone 这个地方的显示是正常的吗?
答:
这个存在 PD 的 etcd 里面的数据,如果没有人为干预,这个是一直存在的。
3.0.5 使用 pd-ctl stores remove-tombstone 清理
 从3.0.8滚动升级至3.0.10,发现empty-regin-count 突然增加很多,什么原因?有没有办法Merge? TiDB 系统架构与原理
从3.0.8滚动升级至3.0.10,发现empty-regin-count 突然增加很多,什么原因?有没有办法Merge? TiDB 系统架构与原理
看文档上说的是 “如果 TiKV 不与 TiDB 集群配合运行,建议配置为 ‘default’” 这个怎么理解? 我们现在是 TIKV和TiDB都在使用的,如果配置为’default‘,有没有什么影响? 需要同时设置split-region-on-table: false吗? 我的目的是合并空Region,合并完以后,是否可以把 ‘namespace-classfier’ 改回到 …
答:
空 region
merge 默认情况下表之间是不会相互 merge 的,如果要开启,更改 PD 配置文件,加上 namespace-classifier = “default” (默认是 table), 注:这个参数不能通过 pd-ctl 动态更改。
同时,需要将 tikv 的按 table 分裂配置关闭:
[coprocessor]
split-region-on-table = false
操作:
- PD 参数 namespace-classifier = “default”
- TiKV 参数 split-region-on-table: false
- pd-ctl -i -u http://172.16.5.83:62479 config set max-merge-region-size 16 M config set max-merge-region-keys 50000
- ansible-playbook rolling_update.yml -t=pd,tikv
 mydumper runs with error: fork/exec bin/mydumper: argument list too long 数据迁移和数据同步
mydumper runs with error: fork/exec bin/mydumper: argument list too long 数据迁移和数据同步
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。 【TiDB 版本】:3.0 【问题描述】:使用dm迁移数据时,在dump数据时出错。问题原因可能是上游mysql数据中有3700多张表,在dm启动task时,自动生成table-list的参数太长了。 是否有什么方式可以通过指定正则表达式的方式来状态这个参数? 若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务…
答:
如果自动生成的 table-list 参数太长。
你可以为 mydumper 在 extra-args 手动用原始的 -x 来指定正则试试([https://pingcap.com/docs-cn/stable/reference/tools/data-migration/configure/task-configuration-file-full/# 完整配置文件示例 2]
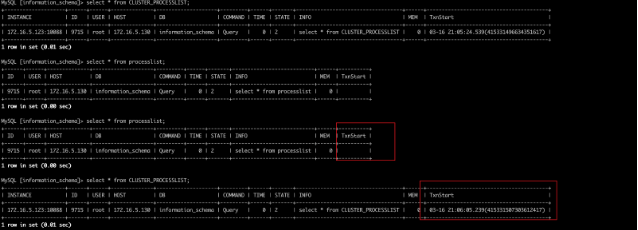
通过 information_schema.processlist 表和 information_schema.cluster_processlist 表查询连接,同一个连接,processlist 表中 txnstart 为空,cluster_processlist 表中 txnstart 字段是有值的,这个是正常的么?
版本:v4.0.0-beta-412-g6e2cbc025
答:这个只是对当前 select processlist / cluster processlist本身的语句才有这个问题, 因为 select processlist 是查memtable 那个算子不需要起事务,所以空,而 cluster 那个用的用的正常 tablereader 上层没感知下面表是真实表还是虚拟表都会启动事务所以有值…只有查 processlist/cluster process 本身才有这个问题
经测试符合预期:
调大 region size 的风险
答:
(1)热点调度不及时
(2)snapshot io 压力
(3)cop scan 时间长不利于并发
业务调研:分布式存储项目计划测试悲观锁,建议 v3.0.9 以上版本
sql 中出现 order by limit 1,索引选择可能走 order by 后面的索引
答:执行计划不稳定,limit 老问题,无论limit 多少
解决方案:
- 绑定 hints
- force index
3.0.13 预计修复执行带视图的 sql 连接直接断开
答:在 SQL 里把 View 写在 PartitionTable 前面,例如之前是 select * from partition_table, view where …; 改成 select * from view, parition_table where …。应该可以规避掉这个问题,但还是建议升级 TiDB 解决。
+1 推荐下《TiDB in Action》:https://book.tidb.io/session1/chapter1/tidb-architecture.html
答:
2.x 升级 3.x max-index-length 问题
升级时调大 max-index-length
2020年4月9日
目前 gc 是无法手动的
drainer.toml 更新后需要重启 drainer 进程

按照你提供的建议,我这边试了一下,发现没有什么变化,还是老样子,我的一个很大的疑问是,所有的节点的网络流量没有一个超过10MiB的,这个不合理,无论我怎么调整参数,网络流量,CPU使用都保证稳定,不会有太多变化,我怀疑是否tiKV底层针对region的snapshot有单独的处理队列(或者线程),而这个队列限制了这种迁移的速率。 如果调度的限制成倍的增大,但是监控上看没有引起什么变化的话,我有理由…
1 pd-ctl -u {pd_ip}:{pd_port} store limit {storeid} 32 (storeid 应该为不需要下线的节点的 storeid , 可以通过 pd-ctl -u {pd_ip}:{pd_port} store 查询)
2 region-schedule-limit 以及 replica-schedule-limit 调整到 64
3 注意线上节点的压力。如果压力升高的话可以把参数调整回来。
Mydumper 和 dm 需要 reload 权限,但由于各种原因不能赋权,可以指定 dm 指定 nolock参数
 loader 导入中断造成数据一致性问题 数据迁移和数据同步
loader 导入中断造成数据一致性问题 数据迁移和数据同步
这边 tidb_loader.checkpoint 的更新时机是跟导入的 SQL 同一个事务内执行的。所以不会出现你说的问题。
答:
loader 导入过程中如果需要 断电宕机等因素导致 loader 终止,再次执行 loader 即可,因为:tidb_loader.checkpoint 的更新时机是跟导入的 SQL 同一个事务内执行的
2020年4月10日
tidb 数据同步到 hadoop:可以用 kettle、sqoop 等用于异构数据源之间数据同步,增量同步到其他异构数据源可以开启 tidb binlog 同步到 kafka,也可以 select … into outfile 导出为 csv 格式的文本

我这边不会立马返回成功呢,要完全建完索引,才会返回成功,建了5个索引,都要1个多小时才能建完,返回sucess同时admin show ddl job 也会建完
添加索引不会立马返回成功是符合预期的,刚才确认了下 4.0 以及之前的版本都是这个行为,执行操作的命令返回 sucess,表示建索引完成。
 慢查询日志里出现一条很早的txnStartTS TiDB 系统架构与原理
慢查询日志里出现一条很早的txnStartTS TiDB 系统架构与原理
为提高效率,提问时请提供以下信息,问题描述清晰可优先响应。 【TiDB 版本】:TiDB-v3.1.0-rc 【问题描述】:查看tidb日志时,发现很多报错日志,有一个很早的txnStartTS [1586491363(1)] [1586490993] 若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
txnStartTS 转成 北京时间
[tidb@node5169 qihang.li]$ ./tools/bin/pd-ctl -u http://172.16.5.169:42379 tso 415888143313272835
system: 2020-04-10 10:56:03.103 +0800 CST
logic: 3

目前无缝升级需要 LB 和应用配合实现,在滚动升级前将要操作的 TiDB 节点从 LB 上摘除,等会话执行完成后再对该 TiDB 做升级操作,升级完成后将 TiDB 节点添加回 LB,并确认有流量进来。
答:
基本达到线上升级标准。
目前无缝升级需要 LB 和应用配合实现,在滚动升级前将要操作的 TiDB 节点从 LB 上摘除,等会话执行完成后再对该 TiDB 做升级操作,升级完成后将 TiDB 节点添加回 LB,并确认有流量进来。
一台TiKV机器宕机后连接 TiDB特别慢/查询也特别慢 TiDB 系统架构与原理
TIDB 3.0.2以及以后的版本修复了一系列 TiDB 与 TiKV 之间网络连接出现异常的 bug,包括但不限于: region cache 相关:https://github.com/pingcap/tidb/pull/11344 tikvclient 相关:https://github.com/pingcap/tidb/pull/11531 https://github.com/p…
问题:一台 TiKV 机器挂掉后,连接 TiDB 要 hang 10 几秒,查询 1000 多条记录的表都没有返回结果
报错:
[2020/04/09 15:16:00.830 +08:00] [ERROR] [client.go:197] [“batchRecvLoop error when receive”] [target=down_tikv_ip:20164] [error=“rpc error: code = Unavailable desc = transport is closing”] [stack=“github.com/pingcap/tidb/store/tikv.(*batchCommandsClient).batchRecvLoop\"n\"t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/client.go:197”]
[2020/04/09 15:16:01.854 +08:00] [ERROR] [client.go:169] [“batchRecvLoop re-create streaming fail”] [target=down_tikv_ip:20164] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp down_tikv_ip:20164: i/o timeout””] [stack=“github.com/pingcap/tidb/store/tikv.(*batchCommandsClient).reCreateStreamingClient\"n\"t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/client.go:169\"ngithub.com/pingcap/tidb/store/tikv.(*batchCommandsClient).batchRecvLoop\"n\"t/home/jenkins/workspace/release_tidb_3.0/go/src/github.com/pingcap/tidb/store/tikv/client.go:203”]
答:
TIDB 3.0.2 以及以后的版本修复了一系列 TiDB 与 TiKV 之间网络连接出现异常的 bug,包括但不限于:
- region cache 相关:https://github.com/pingcap/tidb/pull/11344 2
- tikvclient 相关:https://github.com/pingcap/tidb/pull/11531
- https://github.com/pingcap/tidb/pull/11370
建议可以的话升级到 3.0 的最新 release 版本再进行观察。
2020年4月11日
Issue: tidb-server refuses to start if no pump is registered with pd
opened by kolbe on 2019-04-23
Bug Report
Please answer these questions before submitting your issue. Thanks!
What did you do?
When trying to restart all TiDB cluster components simultaneously,...
如果 enable-binlog 为真,则 pump 实例必须可用。
如果我们使用配置 TiDB enable-binlog = true,建议的启动顺序为:PD -> TiKV -> Pump -> TiDB -> Drainer
2020年4月12日
选择存储引擎
EXPLAIN SELECT /*+ read_from_storage(tikv[t]) */ count(SUBSTR(name FROM 1 FOR 3) )FROM t;
SELECT /*+ read_from_storage(tiflash[t]) */ count(SUBSTR(name FROM 1 FOR 3) )FROM t;
2020年4月14日 10:15:30
 tidb-server对于sql的内存占用限制 应用适配和性能优化
tidb-server对于sql的内存占用限制 应用适配和性能优化
Hi @rongyilong-PingCAP,TiDB 4.0 RC 版本已经发布了,可以试试。我们在这个版本中默认支持了部分算子(比如 Hash Join)的中间结果落盘,这时候可以在不杀掉 SQL,也不过多使用系统内存的情况下执行完该 SQL 了。不过因为中间结果落盘了,执行性能会有所损失。
答:
- mem-quota-query 可以根据目前服务器的内存进行设置
- 该参数也需要和 oom-action=cancel 配合使用,避免 tidb server 出现 oom。
TiDB 4.0 RC 版本已经发布了,可以试试。我们在这个版本中默认支持了部分算子(比如 Hash Join)的中间结果落盘,这时候可以在不杀掉 SQL,也不过多使用系统内存的情况下执行完该 SQL 了。不过因为中间结果落盘了,执行性能会有所损失。
 SQL执行出现reading initial communication packet', system error: 0 "Internal error/check 应用适配和性能优化
SQL执行出现reading initial communication packet', system error: 0 "Internal error/check 应用适配和性能优化
你好, 抱歉,暂时可从以下链接查看,我们会持续更新官网: https://github.com/pingcap/tidb/blob/c02e92c02f31d67da0c7c2e02031c920eb264313/config/config.toml.example#L234https://pingcap.com/docs/dev/reference/configuration/tidb-se…
一个事务中条目大小的限制(以字节为单位)。
如果使用TiKV作为存储,则该条目表示键/值对。
注意:如果启用binlog,则此值应小于104857600(10M),因为这是Pumper可以处理的最大大小。
如果未启用binlog,则该值应小于10737418240(10G)。
txn-total-size-limit = 104857600
 【SOP 系列 01】 Release-2.1 升级到 Release-3.0 线上集群升级 TiDB 运维手册
【SOP 系列 01】 Release-2.1 升级到 Release-3.0 线上集群升级 TiDB 运维手册
01 Release-2.1 升级到 Release-3.0 线上集群升级 李仲舒 2020 年 2 月 10 日 一、背景 / 目的 分布式数据库集群运维过程有一定的复杂性和繁琐性,3.0 版本是目前被广泛使用的版本,相比 2.1 有大幅度增加性能,以及很多新增的功能和特性,整体架构、配置也有较大的优化。该篇根据广大用户的升级经验,尽可能将 Release-2.1 升级到 Release-…
答:
关于新增的 excessive_rolling_update.yml 和 rolling_update.yml 的关系:
如果部署采用 (默认)systemd 模式 ,使用 excessive_rolling_update.yml 来进行滚动升级操作,原因是涉及到 PD 滚动升级 1(以 v3.0.9 为例)的代码变动,该脚本仅本次升级使用一次,以后再次升级到后续版本均由 rolling_update.yml 来完成。
2020年4月15日

context canceled 是被中斷的意思,可能是 Ctrl+C 也可能是別的錯誤

![[image]](https://asktug.com/uploads/default/original/3X/f/9/f9346bdc7edce302aaf01aff5960c324e49e7989.png){kind=link}
![[image]](https://asktug.com/uploads/default/original/3X/0/5/0593fb04316d909af102b412de5390d18b765469.png){kind=link}
![[1586491363(1)]](https://asktug.com/uploads/default/original/3X/8/e/8eec60415fcb8aeaac2fb89d545d7325142258da.png){kind=link}
![[1586490993]](https://asktug.com/uploads/default/original/3X/5/4/5455ee728d03935f58c2c97444d34fee75f7caba.png){kind=link}
![[%E5%9B%BE%E7%89%87]](https://asktug.com/uploads/default/original/3X/1/e/1e8c002fedad6cae2a6a944893568f13458e8426.png){kind=link}
【系统版本 & kernel 版本】 CentOS Linux release 7.6.1810 (Core) 4.20.10-1.el7.elrepo.x86_64 【TiDB 版本】 3.0.5 【问题描述(我做了什么)】 TiDB 列的排序规则 [image] 已有的数据 [image] 执行的sql语句 [image] 【我期望的】 MySQL 列的排序规则 […
new_collations_enabled_on_first_bootstrap
- 用于开启新的 collation 支持
- 默认值:false
- 注意:该配置项只有在初次初始化集群时生效,初始化集群后,无法通过更改该配置项打开或关闭新的 collation 框架;4.0 版本之前的 TiDB 集群升级到 4.0 时,由于集群已经初始化过,该参数无论如何配置,都作为 false 处理。