背景: 有三个tidb 集群是用来汇总线上mysql 的数据,用dm 组件进行实时同步 mysql —> dm —> tidb
最开始的版本是4.0.9 ,后来发布了5.0 版本以后,在官方宣称的性能提升20%~30% 以及tiflash mpp 的诱惑下,打算先将这三个版本升级到5.0.1 。
1.升级后的性能表现 – 5.0.1
在升级了一个tidb 集群后, 发现集群整体的耗时比4.0.9 增加了不少,999 在800ms 左右.
在官方老师的排查下,总结原因如下:
由于我们上游每个mysql 实例中有一个心跳表,每秒更新次数比较多, 在多个心跳表的数据更新汇总到tidb中后,
CREATE TABLE `heartbeat` (
`p_id` varchar(128) NOT NULL,
`p_ts` timestamp(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3),
PRIMARY KEY (`p_id`) /*T![clustered_index] NONCLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
表结构里,p_id 是个字符串主键,没开 clustered index,所以内部实现为一个独立的唯一索引。
4.0.10 起,update 非唯一索引的列时也会对唯一索引进行加锁,事务提交后会在 write cf 留下 Lock 记录,所以这个问题极有可能是因为唯一索引(即主键)中有过多的 Lock 记录,这种情况如果需要读 value,则需要依次遍历 write 记录直到找到 Put 或 Delete,每遍历一个 Lock 都会产生一次 next。如果 Lock 特别多,那么 next 也就会特别多。
通过拿的一个 key 的 mvcc 信息可以看到:mvcc 信息是个 200 多万行的 json ,40 多万条 write 记录,除了最后一条,全部是 Lock 类型。与上面的结论基本一致 ~
相关的issue 为: https://github.com/pingcap/tidb/issues/25659
(此issue 修复的版本为:5.0.4 fix & 5.1.1)
我的临时解决办法为: 将一个集群的心跳表开启了聚簇索引。
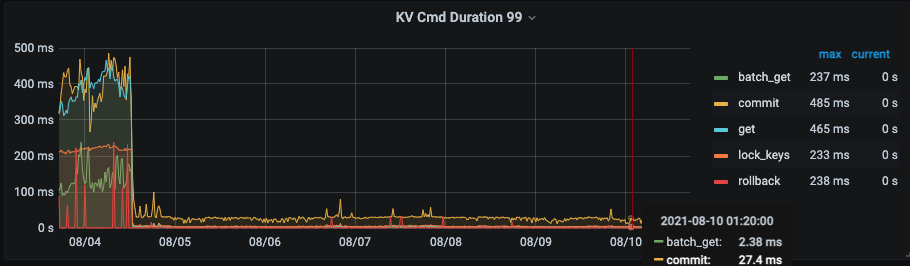
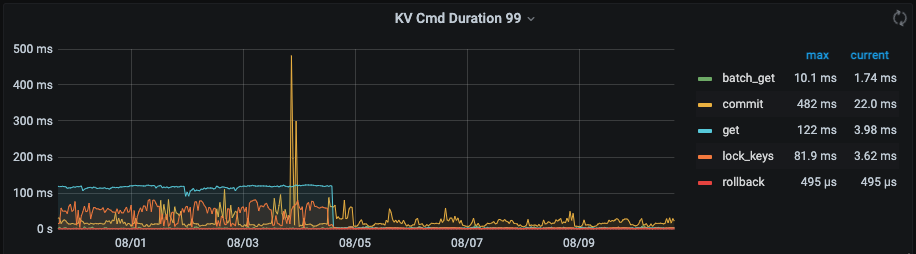
此时升级后的两个集群,一个耗时999为800ms 左右,另一个修改了心跳表的集群为300ms 左右
2.升级到5.1.1 后的性能体现
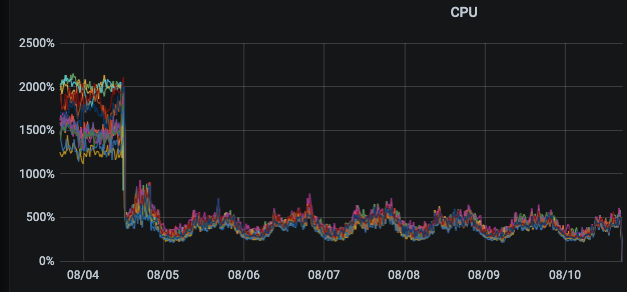
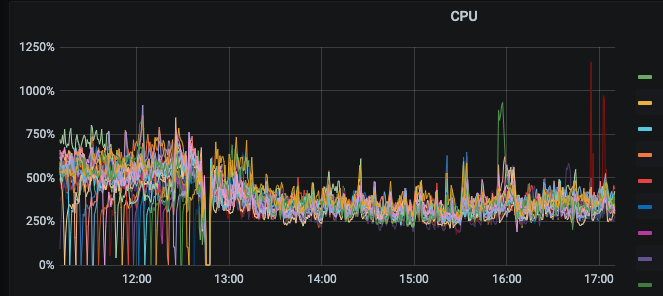
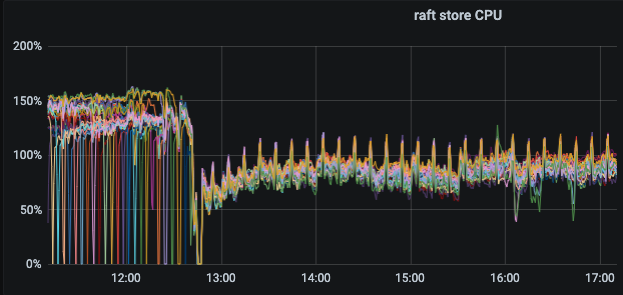
– 主要体现在耗时降低以及tikv cpu 使用率下降明显
集群1升级前后监控对比

集群2的监控


3.运行几天之后,各方面表现稳定,于是将第三套集群从4.0.9 升级到5.1.1

4.升级的注意事项:
1、sql 兼容性的问题: 从v4.x 升级到v5.x 后,部分比较复杂的sql 可能不兼容,比如:
select engine,cost,count(1) cnt from (select engine, if (delay_time = -1,-1,if(delay_time<10, 0, if (delay_time< 60,1, if(delay_time<300,2,3)))) cost
from (select engine, if(callback_time>0, if(callback_time>=send_time, callback_time-send_time, 0), -1) as delay_time
from tblTraceLog5 where create_time >= 1628586522 and create_time <= 1628586822 and engine =1) A) B group by engine,cost
线上业务如果升级务必将复杂的sql 先在测试环境跑一遍
2、5.x 版本中由于支持了字段类型的有损修改,如果使用了ticdc 同步tidb 到另外一个tidb 集群时,有损变更操作会导致下游延迟严重
--- 此问题官方老师反馈修改量较大,修复排期未知
总得来说5.1.1 版本各方面表现比较亮眼,尤其是对字段有损变更的支持。
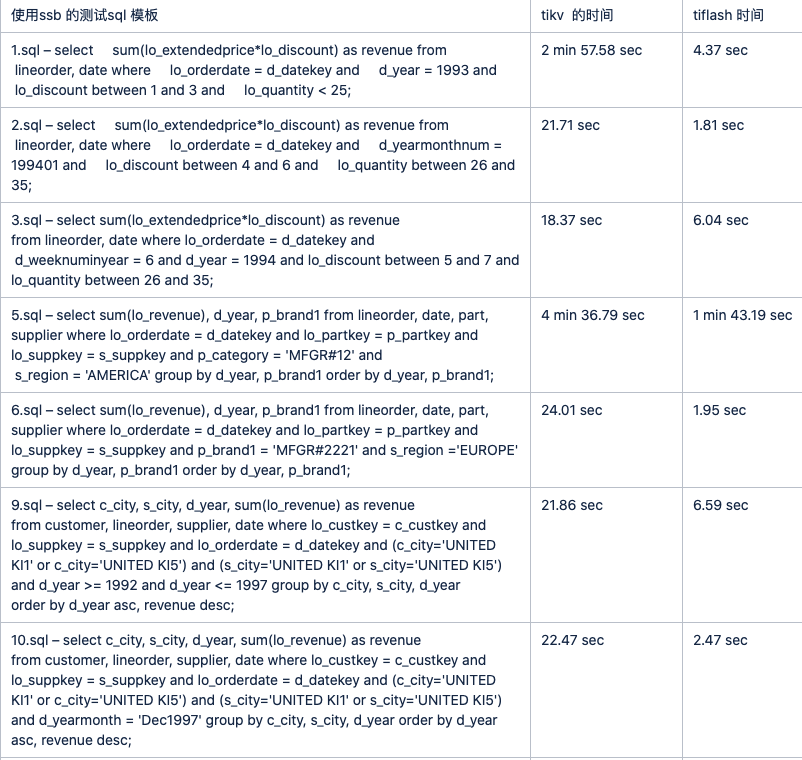
对于tiflash 的表现,只是用了ssb 模型进行了一波测试,结果如下