

本文系上海 TUG 活动 “TiDB + Cloud” 实录整理,作者:UCloud 资深研发工程师 常彦德

我是 UCloud TiDB 产品的研发工程师常彦德,接下来的半小时我将和大家分享一下我们所做的把 TiDB 运行在公有云上的一些经验。今天的分享分为四个部分:第一部分是 UCloud TiDB Service;第二部分是我们为了将 TiDB 服务运行在公有云上做了哪些工作;第三部分是我们为了帮已有用户将业务无缝迁移到 TiDB 上面所做的另外一个产品及扩展;第四部分是讲我们在使用 TiDB 的过程中遇到的问题及解决方法。

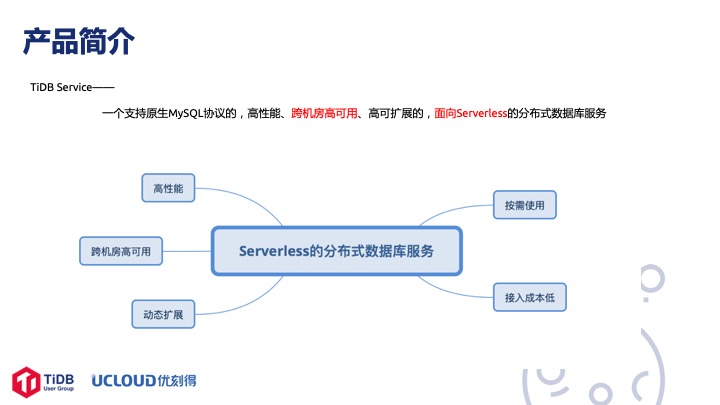
首先讲 TiDB Service,我们以服务的形式把 TiDB 运行在公有云上面,用户看到的是一个服务而不是一个实例。TiDB Service 是一个支持原生 MySQL协议的、高性能、跨机房高可用、高可扩展的、面向 Serverless 的 分布式数据库服务。跨机房高可用是因为我们在北京部署了这个服务,北京大概有四五个机房,所有的组件都是跨机房部署的。再就是 Serverless,在云上我们希望让用户简单快捷地使用 TiDB ,无需关心底层的物理资源和部署细节。我们这个产品是按需使用和付费的,当然最终的定价还没定下来,但基本上根据使用量和 QPS 指标来计费。
简单看一下演示,点击查看 Demo。第一步是创建实例,只需要输入一个实例的名称再输入一个 root 帐号的密码,点击确定基本上 1-2 分钟之内就可以部署好一套可用的TiDB 服务集群。第二步是添加用户。这里面首先添加一个只读用户,尝试连接数据库,连上去之后尝试着创建一个 DB 但是失败,需要返回修改权限。接下来演示一下 Binlog 同步服务,默认是没有开启 Binlog 服务的,可以开启后添加 Binlog Consumer,简单演示一下建好服务以后在源里面创造一个数据库,会同步到从库里去。TiDB Binlog 本来就支持 MySQL、Pb、 Kafka这些协议,我们做了最通用的MySQL,后期迭代会支持其他的格式。这边是在源里面创建了数据库,在目标里面看的时候已经同步过来了。演示到此结束。

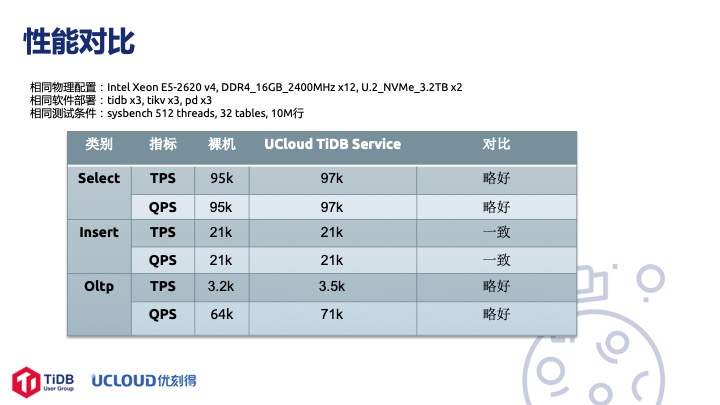
我们简单看下性能对比,特别强调一下这里做的是 TiDB 部署在物理机上,UCloud 部署在 Service 时的性能对比,并没有为了让性能数据好看而做一些特殊的考虑,就是简单地做了一个 Sysbench 的测试。这个测试跑的是 2.1.4 版本, 3 实例部署,物理机一模一样,软件部署了 3 个 TiDB, 3个 TiKV, 3 个 PD,全部跨机房部署。裸机跟 UCloud TiDB Service 对比性能基本一致,并没有什么损耗。
接下来讲一下为了实现大家在演示上看到的效果,我们后台做了哪些事情。

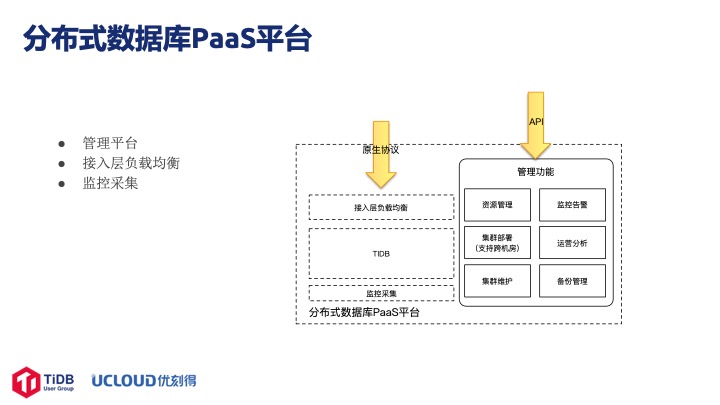
首先我们做了一个分布式数据库的 PaaS 平台,这个平台有几部分:
第一部分是物理机的资源管理,包括每次创建实例时的资源分配以及实例资源回收等等操作。
第二部分是集群部署。创建的过程先选取合适的物理机,检测资源是否满足。如果满足将分配特定的资源,然后再执行相应的创建工作,包括创建 TiDB、TiKV、PD 节点,创建相应的监控还有 LB 层,以及 VPC 网络初始化的工作。
第三部分集群维护。如果在某个节点发现某台物理机有异常,就把所有服务迁移到其他的节点上去,我们主要是做的是迁移、扩展、缩容这些工作。右边是监控告警,这块我们改造比较多。
第四部分是运营分析,也就是运营和备份管理。我们默认一天会备份一次数据,目前用户还不能自己选择什么时候备份、怎么备份,后期会做一个比较详细的备份策略。比如目前默认中国时间凌晨三点可能是一个比较空闲的时间,我们选择在这个时间点做备份,但有些服务在这个时间可能是高峰期,备份对线上业务会产生一定的影响。左边是 MySQL 本来的数据流,我们加了一层负载均衡,一是把 IP 地址统一成一个,二是在公有云服务运维上做一些帐号和系统方面的控制。
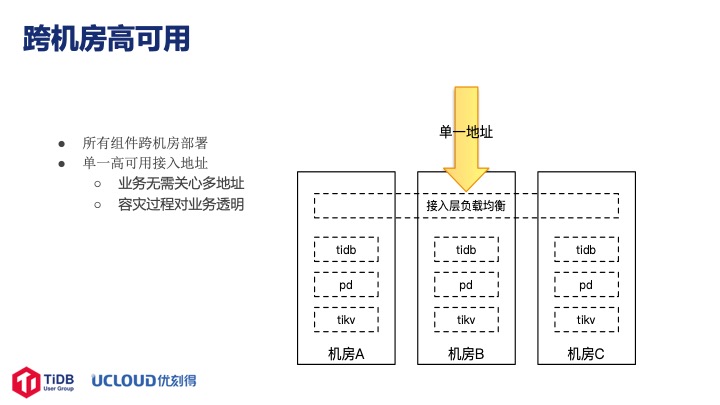
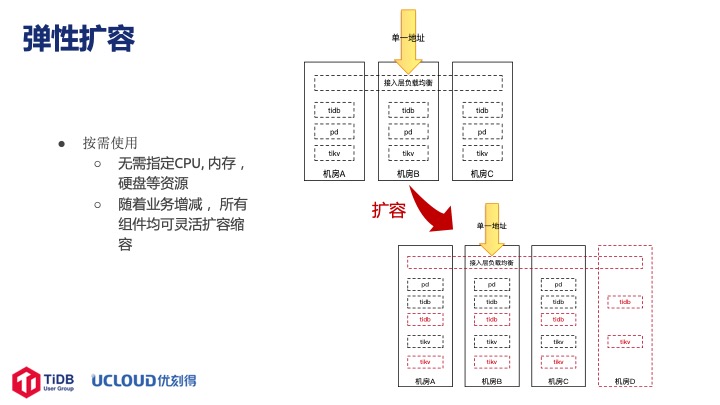
这一页讲的是跨机房高可用。机房目前部署在北京,大概有五个用的比较多,所有的机器、节点、组件都是跨机房部署的。单一地址的好处是业务不需要关注多个地址,即不需要在地址之间切换,此外有了统一地址的虚拟 IP 后运维时也不需要考虑地址,所有的操作对用户完全透明。
弹性扩容这块比较灵活,用户使用的时候不需要关注 CPU、资源,而是想放多少数据就放多少数据,想怎么用就怎么用。随着业务的增减,后台有运营监控,假如发现有一台实例资源使用率比较紧张或者内存使用非常满的时候会扩容,这块也严格保证是跨机房的。
还有就是对监控的改造。TiDB 本身提供的部署服务里面,包括 Grafana,Prometheus,都是单节点的,有风险。但是一些运营的决策是根据监控数据来的,比如某个实例内存非常紧张时需要扩容,这时候如果一个节点出问题,整个运营策略后面就没法支撑了。所以首先我们改造了 Grafana(它自身没办法使用 TiDB 作为存储)的源码,改掉了 Grafana 里的大量 Multi-schema 语句并且把字段改小,使之可以使用 TiDB 存储元数据。TiDB 支持 Grafana 以后就可以做高可用集群,这块我们也做了建库、互斥、Provisioning 的工作。之后还改造了 Prometheus 和 Alertmanager,全部都变成了集群化的模式。

接下来是一个用户实例监控系统,左边有一个LB,两个 Grafana 节点,通过 LB 连到Prometheus, 存储全部是远程,以实现高可用。
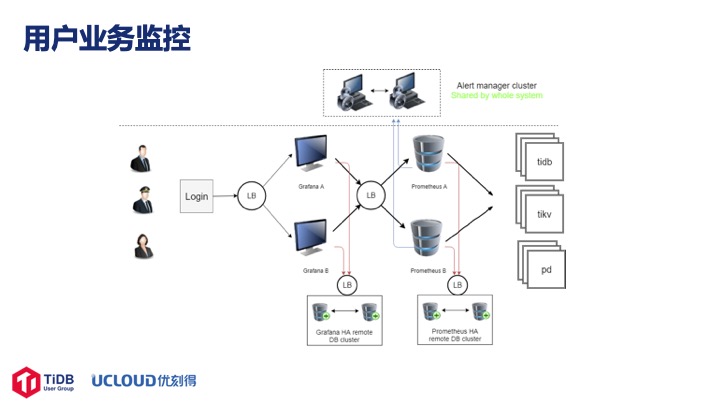
这是管理的图,最右边监控了所有物理机上的 Exporters,并且将所有用户的Prometheus 数据汇聚在一起。为了把 Alertmanager 兼容到 UCloud 告警体系里面,我们也做了一些修改。

接下来分享一下我们对 Binlog Driver 做的事情。当时有一个用户场景,需要把数据同步到自己的大数据里面去,他可以通过 Json 格式简单地解析 Kafka 里的数据,但是 TiDB Driver 默认输出的格式是 PB 格式,用户没办法简单地配置使用。我们就把 Kafka 里面的数据读出来后写成 Json 格式再写到另外一个Kafka里,当时 Binlog 组件还没开源,如果 Binlog 开源的话就可以直接改源码了。

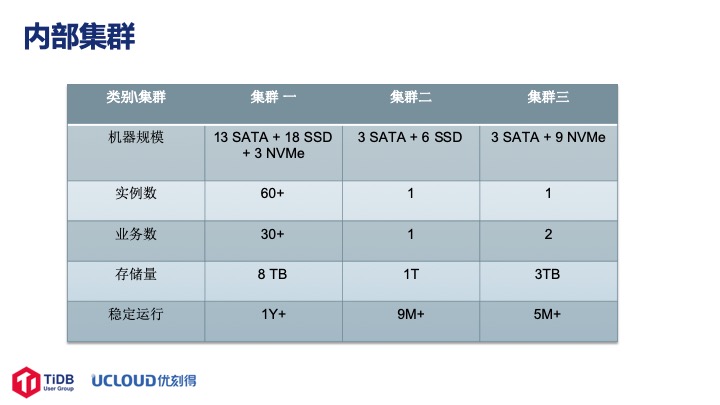
我们内部使用 TiDB 很长时间了,也做了一些打磨以及积累,现在有三个集群。比较大的是第一套集群,有 13 台 SATA,18 台 SSD,3 台 NVMe,上面部署了 60 多个实例,来自内部 30 多个业务部门,大概有 8 TB 的数据在上面,使用了一年多运行非常平稳。第二套集群有 3 台 SATA、6 台 SSD,数据量有 1TB,已经运行了九个多月。第三套集群是高性能集群,3 台 SATA,9 台 NVMe,有 3TB 数据,QPS 在一万左右,也已经稳定运行了五个多月。一年多的实践我们经历过物理机的宕机、异常重启,但整体看来 TiDB 运行的非常平稳,没有影响到用户的业务,我们觉得 TiDB 还是做的非常好的。
第三部分讲一下 UDTS,这是我们根据 TiDB 引申出来的一个产品。

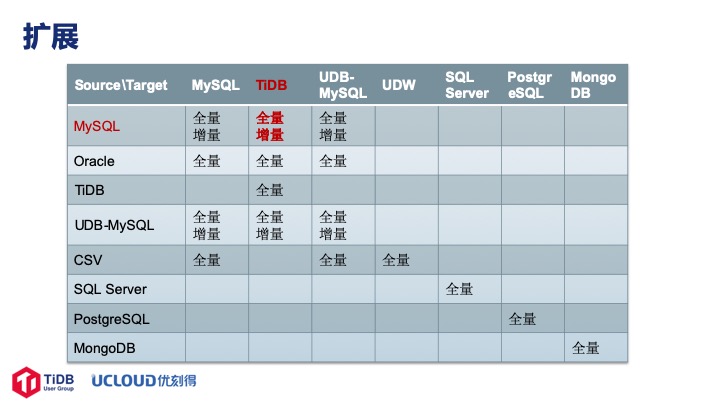
用户常问的一个问题是怎么把 MySQL 集群里的业务和数据平滑地迁移到 TiDB 上面去。其实迁移基本可以分为四个步骤,第一是全量迁移,第二是增量同步,第三是业务验证,第四是业务切换。
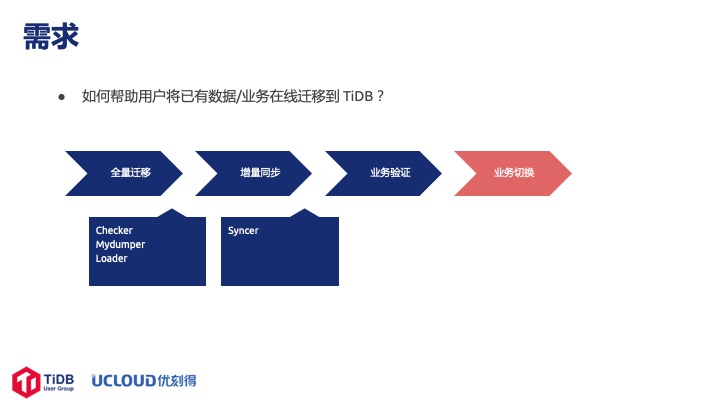
TiDB 虽然高度兼容 MySQL,但是正式上线之前还是要对业务做一次完整的验证才放心。PingCAP 官方提供了一些工具, 例如 Syncer、Mydumper、Loader、DM 都可以帮用户做这些事情。 但是有了这些工具之后用户还得自己部署,自己找机器,考虑数据量和相应的磁盘空间,所以我们就思考能不能在公有云上帮助用户把这些问题解决掉,于是就有了 UDTS 这个产品,成为了一种服务。用户不需要关心底层需要使用的物理资源,以及工具配置。在服务化的过程中我们还增加了一些其他的功能,比如失败自动重试,随时暂停、重启服务,以及完善的运行信息,比如从 MySQL 迁移到 TiDB 的开始和结束时间、迁移的数据量等等。
在开发这个产品的过程中我们也遇到了一些问题,并且做了相应的改造。第一个问题也是比较大的问题就是负载均衡层使用的软件不支持 Syncer 或者 Drainer 输出的 use db; ddl 语句的格式,于是我们改造输出 db.table 格式的语句 ;第二个问题是 DM 里面的 Syncer 并不支持 GTID,所以我们又做了 GTID 的支持;第三个问题是我们发现 MySQL 的连接经常不稳定,所以我们对连接池做了改造;第四个问题遇到的比较少,某些用户的 Binlog 是 STATEMENT/MIXED 格式,而默认只支持 Row 格式,我们自身希望用户修改格式后再进行,但有的用户觉得比较困难,所以我们也在尝试改造中。

我们做 UDTS 的初衷只是想把 MySQL 迁移到 TiDB 上, 但这个产品出来后一些部门问我们能不能做 Oracle 的迁移,我们实现后又问能不能做 UDB 数据库的迁移,所以最后我们越做越大就做成了这样一张图。
第四部分讲讲我们做的过程中遇到的一些问题。

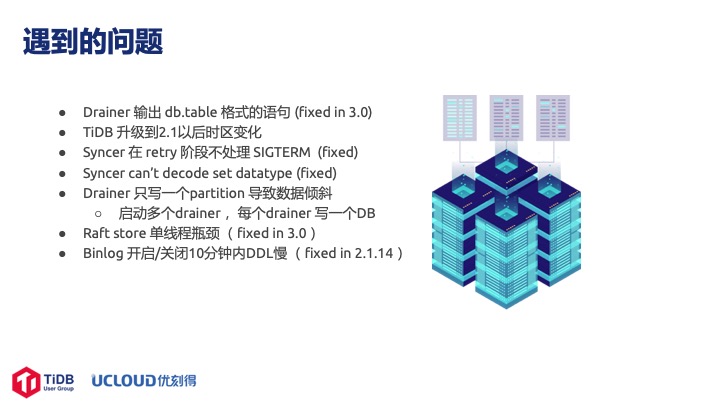
我们经历过宕机服务器重启等等一些事件,虽然 TiDB 整体运行非常平稳,但是在整个测试包括内部打磨的过程中遇到了一些小问题:
第一是输出 db.table 格式的语句对我们比较重要,官方在 3.0 已经 fixed。
第二是 TiDB 升级到 2.1 以后时区变化,导致几个使用了自带的 time 函数的用户的数据发生了一点问题,差了八个小时,后面应该不会再有这样的问题。
第三是 Syncer 在 Retry 阶段不处理 SIGTERM,当时提了 issue 以后官方很快解决了。
第四是 Syncer can’t decode set datatype,后来也解决掉了。
第五是 Drainer 只写一个 Partition 的问题,会导致数据倾斜。Kafka 一般都会创建三个 Partition, 但是后面两个都是空的,对性能也有一定的影响。目前还没解决,希望社区可以不断地完善解决这个问题。有一个方法可以 work around,就是启动多个Drainer,每个只负责一个 DB。
第六是 Raft store 单线程瓶颈告警不断,这个 3.0 已经解决掉了。
第七是 Binlog 开启关闭的问题。我们默认是不开启 Binlog 的,因为开启对性能有一定的影响。有用户使用的时候开启 Binlog,发现前 10 分钟内 DDL 非常慢,基本执行一条需要 1m30s,如果同时输入四五条就累加了,需要 6m 才能执行完, 2.1.14 把 10m 改成 1m30s 后这个问题基本上解决掉了。
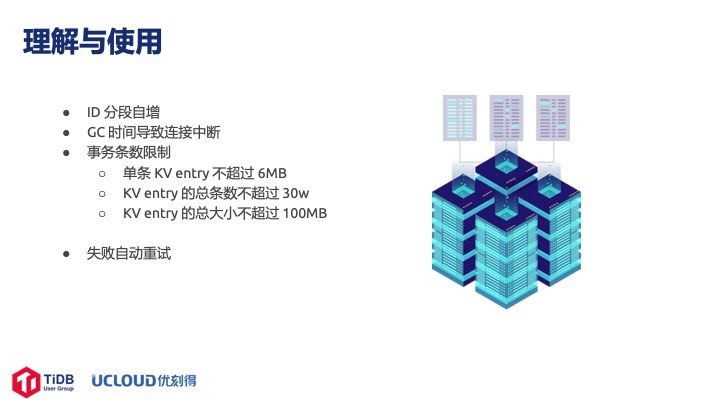
后面还有很多问题,不是 TiDB 的问题而是因为跟 MySQL 理解不同产生的问题:
第一是 ID 分段自增。用户比较困惑,后面写的 ID 怎么比前面的还要小,但是在 TiDB中确实是可能的,因为是分段自增节点,一般的业务也不会根据 ID 来做排序或其他相关逻辑,所以这个问题也不算大问题。
第二是 GC 时间导致连接中断的问题,这个遇到的比较多。TiDB 默认 GC 时间是 10 分钟,有一个非常复杂的查询跑 20 分钟才能跑出来,结果跑到 10 分钟的时候就断掉了;或是在备份大数据的时候, 备份执行超过10分钟就断了。我们发现是 GC 时间太短导致的 session 中断,把 GC 时间调长可以解决。
第三是事务条数限制。TiDB 跟 MySQL 相比是有很大的优势,但是内部其实并不是一条数据就可以做的。它的 KV entry 也有很多限制,默认 KV 层总条数不能超过 30w,我们建议一条语句里不要超过 10w 条数据。
最后是失败自动重试。有一个业务部门反映数据不一致的问题,查下来是因为 TiDB 使用了乐观锁,而且默认有失败自动重试十次的机制。如果代码写的不是非常健壮,两个事务冲突尝试重新提交后就可能导致这个问题。通过先 select for update 可以解决这个问题。
欢迎在本文下留言和常老师进行交流~
相关阅读: