

本人接触 TiDB 半年有余,本文是针对TiDB在实际工作中落地的一个总结和思考,如有说的不对或者可以优化的地方,请多多指正,谢谢。
背景知识:
TiDB简单的架构分为3部分:tidb,tikv,pd
tidb :sql层语法解析,把sql语句转化为kv查询,同时生产语法树(后面对于TiDB这个产品我会用大写表示,对于tidb这个角色会用小写表示),如果算力不足,该角色具有横向扩展能力,我们可以理解是无状态的,今儿主角不是它,不做过多展开。
tikv :数据实际存放的地方,为达到强一致性,各节点使用的是raft协议,所以分为leader和follow的概念(后面具体介绍)。而最底层使用的是rocksdb作为存储引擎,在数据组织形式上,采用的是 kv 类型存储,也就是说你可以不用 tidb 而直接用tikv读取数据(这里说远了);
pd: 元信息保存 / 调度器, 先说元信息,pd 中就记录着存放哪些 region (一组连续的kv,TiDB的最小存储单位),而由于TiDB采用分布式架构,每个region都有 leader 和 follower 的角色,任何读写请求都会通过 leader 进行(新版本有个参数可以让你直接读follower),leader 会分布在不同的 raft store(可理解成 tikv 实例),pd就记录着 leader ,follower 和 raft store 的元信息,再说调度器,有了元信息之后,为提高并发度,tidb把读和写都定义为一个个的job,如并发索引扫描,多线程表关联,并发写等,然后由pd把任务下推到每个 tikv 节点;
MVCC: 多版本并发控制(要说明白这个篇幅有点儿大),MySQL是通过redo日志完成的MVCC,TiDB通过垃圾回收机制完成的MVCC,可以简单理解为数据在某一时间点的一致性快照;
Backup EndPoint: 发起备份命令的 Linux 主机,TiDB建议和 pd 节点部署在一起;
正文:
前面这些我都铺垫好了哈,下面正文就开始咯,我们假设有如下一套架构
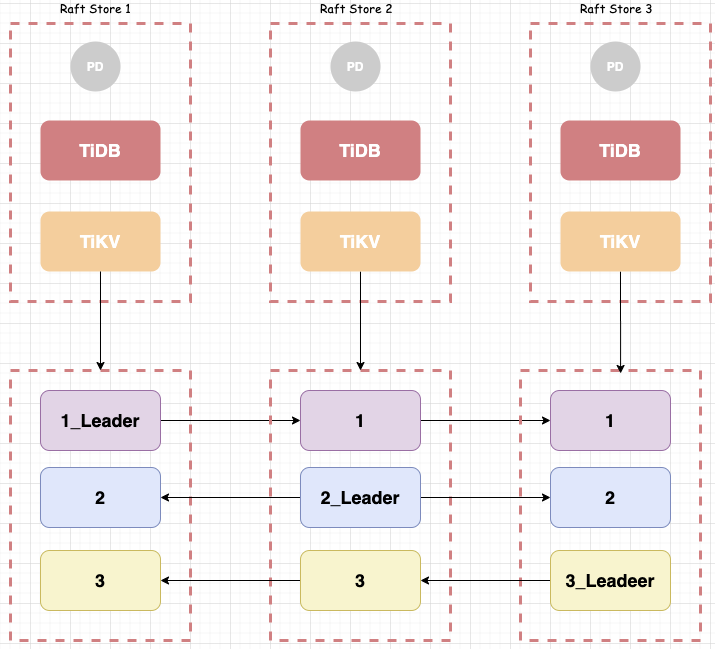
说明:上图,一共有3个 TiDB 实例,群集中有3条数据(当然我知道这不太可能,这里只是举栗)tikv里面的数据分布情况如上图,每个 tikv节点都有 leader。
tidb原生备份工具叫 br(Backup & Restore),整个备份流程还是比较简单的,个人理解流程为:
- 从 pd 拿到leader在哪个 tikv上
- 通过MVCC拿到一致性快照,题外话:那么咋拿到一致性快照呢?(之前说过TiDB内部有垃圾回收机制,回收的垃圾就是MVCC产生的数据之前的版本,通过tikv_gc_life_time参数设置最长保留时间,超过了这个时间就会被删除)
- 通过 pd 把备份任务下发到各个 tikv 节点上,其中包括一致性快照的 tso(TiDB内部产生的时间戳)和 leader所在 raft store 的元信息
- 每个 region 的 leader 收到备份命令后,开始读取 region 信息
- 备份文件到本地 or 远程存储上
那么:最终备份就是这么个形状
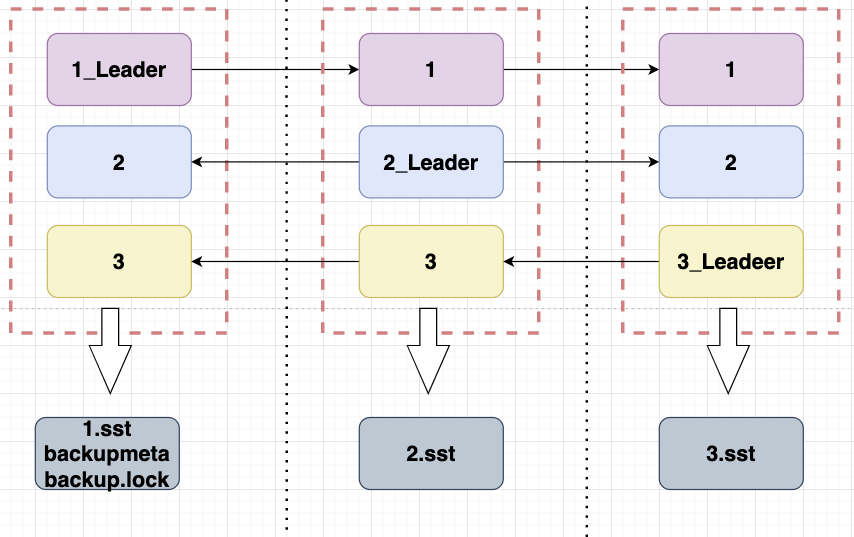
说明一下:
由于leader分布在不同的 tikv上,所以备份结束后的结果分布在不同的 tikv实例上(这个tikv实例有可能是同一主机也有可能是不同主机),然后最终备份出来的文件为3种类型的文件,引用tidb官网上的解释为:
SST 文件:存储 TiKV 备份下来的数据信息
backupmeta 文件:存储本次备份的元信息,包括备份文件数、备份文件的 Key 区间、备份文件大小和备份文件 Hash (sha256) 值
backup.lock 文件:用于防止多次备份到同一目录(特别重要)
这里有个猜想,如果少了个sst还能恢复么?我就直接说了,backupmeta记录着元信息,少一个就跟少了个binlog一样,所以答案是不能恢复,那么问题又来了,3节点群集备了个“稀碎”,要是多tikv节点+多群集咋办?
这里我就又直接说了:把本次备份的 sst 文件合并到一个统一的磁盘里呗,不过就又有个问题, 备份链路长,恢复结果不可控。如果采用这种方案会有两次资源调用,一次备份是使用本地磁盘 io 资源(其风险是磁盘坏块),另外会占用网络(其风险是网络传输丢包或质量低下,这个最近深有体会)
于是 br工具提供了2种玩儿法:
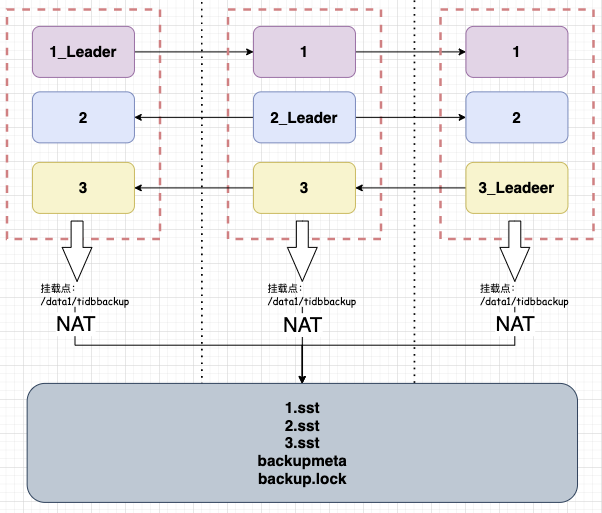
玩儿法一:后面假装接了个磁盘,把挂载点变为一个统一的网络存储,如图所示,您一看就明白,这样的玩儿法好处就是要么成功,要么失败,没那么多中间状态
玩儿法二:在备份时真的指向网络存储(如果有权限的话需要先设置在环境变量中)我们以 ceph 存储为例,如图您一看就有点儿懵,不过两句话就能解释明白
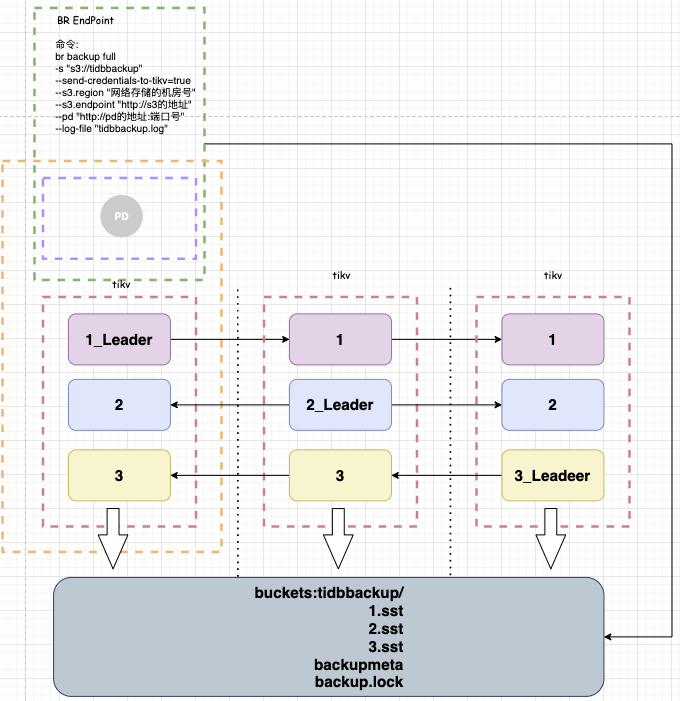
说明:
绿色框里的是backup endpoint,直接发起备份命令,他和pd节点在同一台linux主机上;
黄色的代表整个tidb群集;
pd节点连接着群集和br工具来获取备份元信息;
不过在实际落地时有个不是问题的问题,由于ceph中没有文件夹的概念(当然可以硬编码意淫成文件夹),所以最终的备份结果在ceph中就长这样,对于有强迫症的同学确实比较难以接受
mysqlbackup
mongobackup
binlogbackup
tidbbackup_clusterA_20210425
tidbbackup_clusterB_20210425
tidbbackup_clusterA_20210426
tidbbackup_clusterB_20210427
最后个人还是比较推荐备份到远端的:
第一,灾备的意义就是防止灾难,防止本地炸了之后备份无法读取;
第二,点在恢复的时候,为了保证数据可用(不缺少某个sst文件),官方建议要把所有的 sst文件分别拷到所有要恢复的主机上,如果群集体量大,确实不太方便;比如备份结果集为10G,3个节点就要分别把这10G的sst拷贝到3个tikv实例上,最终的数据量就是30G
最后的最后对这个架构还是有一些值得改进的地方,比如:
- 增量备份问题:br只是基于全库的一致性备份,对于增量备份我们可能还需要借助 dumpling 等 tidb binlog工具,而由于分布式架构 dump 工具要部署在各个 tikv 节点上,希望有个更轻量一点儿的工具。来搞定指定时间点恢复,这里我和TUG的各位大佬学到了一个小技巧:把GC时间调成1天,然后1天1整备,当然GC时间长会有维护各版本的性能损耗,请自行斟酌哈。
- 备份恢复更原生化一些,比如,我可以把非tidb的各种参数都打包好,然后直接 tiup br clusterA