

【是否原创】是
【首发渠道】TiDB 社区
问题描述
在开发测试环境,业务开发同事遇到一个奇怪的问题,同样的 sql,只因为查询条件一个参数区别,耗时竟然差异巨大:
第一条sql,执行耗时 2.74s:
select name, uid, size, etag, mtime, display_name, appendable from objects where bucket_id = '.bucket.meta.bucket_b' and name like '%' and name > 'dir10' order by name asc limit 1001;
第二条sql,执行瞬间返回,非常快:
select name, uid, size, etag, mtime, display_name, appendable from objects where bucket_id = '.bucket.meta.bucket-d' and name like '%' and name > 'dir10' order by name asc limit 1001;
两条 sql 查询条件差别只有 bucket_id = ‘.bucket.meta.bucket_b’ 和 bucket_id = ‘.bucket.meta.bucket-d’ 的差别。
其中满足第二条 sql 查询条件 bucket_id = ‘.bucket.meta.bucket_d’ 的记录数比第一条还要多:
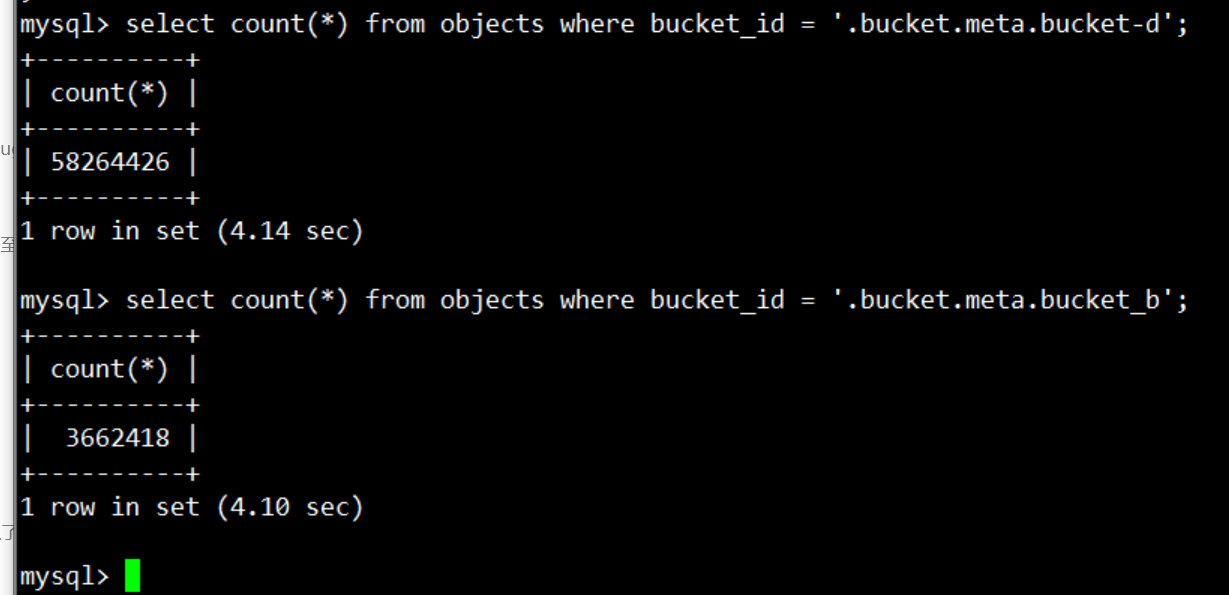
所以业务同事就疑惑了, 为什么满足语句二的记录数更多,需要过滤的条数更多,但是语句二能瞬间返回,语句一却很慢,是不是集群出现什么异常!
问题排查
mysql> show create table objects\"G
*************************** 1. row ***************************
Table: objects
Create Table: CREATE TABLE `objects` (
`id` bigint(20) NOT NULL /*T![auto_rand] AUTO_RANDOM(5) */,
`bucket_id` varchar(192) NOT NULL,
`name` varchar(512) NOT NULL,
`version_id` varchar(64) NOT NULL,
...
PRIMARY KEY (`id`),
UNIQUE KEY `idx_nm_bkt_ver` (`name`,`bucket_id`,`version_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![auto_rand_base] AUTO_RANDOM_BASE=206132466 */
1 row in set (0.00 sec)
表 objects 中只有一个业务相关的唯一索引 idx_nm_bkt_ver,它是三个列的联合索引。
mysql> explain select name, uid, size, etag, mtime, display_name, appendable from objects where bucket_id = '.bucket.meta.bucket_b' and name like '%' and name > 'dir10' order by name asc limit 1001\"G
*************************** 1. row ***************************
id: Projection_7
estRows: 1001.00
task: root
access object:
operator info: ogw.objects.name, ogw.objects.uid, ogw.objects.size, ogw.objects.etag, ogw.objects.mtime, ogw.objects.display_name, ogw.objects.appendable
*************************** 2. row ***************************
id: └─Projection_28
estRows: 1001.00
task: root
access object:
operator info: ogw.objects.bucket_id, ogw.objects.name, ogw.objects.uid, ogw.objects.size, ogw.objects.mtime, ogw.objects.etag, ogw.objects.display_name, ogw.objects.appendable
*************************** 3. row ***************************
id: └─IndexLookUp_27
estRows: 1001.00
task: root
access object:
operator info: limit embedded(offset:0, count:1001)
*************************** 4. row ***************************
id: ├─Limit_26(Build)
estRows: 1001.00
task: cop[tikv]
access object:
operator info: offset:0, count:1001
*************************** 5. row ***************************
id: │ └─Selection_25
estRows: 1001.00
task: cop[tikv]
access object:
operator info: eq(ogw.objects.bucket_id, ".bucket.meta.bucket_b"), like(ogw.objects.name, "%", 92)
*************************** 6. row ***************************
id: │ └─IndexRangeScan_23
estRows: 38954.42
task: cop[tikv]
access object: table:objects, index:idx_nm_bkt_ver(name, bucket_id, version_id)
operator info: range:("dir10",+inf], keep order:true
*************************** 7. row ***************************
id: └─TableRowIDScan_24(Probe)
estRows: 1001.00
task: cop[tikv]
access object: table:objects
operator info: keep order:false, stats:pseudo
7 rows in set (0.00 sec)
- 使用 IndexRangeScan 走 idx_nm_bkt_ver 索引扫描数据,扫描位置 name > “dir10”
- 扫描中使用 Selection 过滤,过滤条件 bucket_id = “.bucket.meta.bucket_b” 和 name = “%”
- 返回扫描过程中满足条件的 TableRowID
- 根据 rowid 查询记录返回需要的列
从查询计划上看,因为索引 idx_nm_bkt_ver 覆盖了 sql 查询条件中的 bucket_id 和 name 列,这里使用 IndexLookUp 查询计划走 idx_nm_bkt_ver 索引是完全没有问题的,通过索引 idx_nm_bkt_ver 扫描选出来的记录也是满足升序排序的。所以可以说很好的满足了查询条件的要求:
where bucket_id = '.bucket.meta.bucket_b' and name like '%' and name > 'dir10' order by name asc limit 1001;
查看两条语句的 sql,执行计划是完全相同的,那么为什么会出现执行耗时差别那么大的问题,难道是执行计划统计数据不准,执行 analyze table objects 后,仍然如此,通过 explain analyze 分析下执行情况:
mysql> explain analyze select name, uid, size, etag, mtime, display_name, appendable from objects where bucket_id = '.bucket.meta.bucket_b' and name like '%' and name > 'dir10' order by name asc limit 1001\"G
*************************** 1. row ***************************
id: Projection_7
estRows: 1001.00
actRows: 1001
task: root
access object:
execution info: time:2.75s, loops:2, Concurrency:OFF
operator info: ogw.objects.name, ogw.objects.uid, ogw.objects.size, ogw.objects.etag, ogw.objects.mtime, ogw.objects.display_name, ogw.objects.appendable
memory: 187.3 KB
disk: N/A
*************************** 2. row ***************************
id: └─Projection_28
estRows: 1001.00
actRows: 1001
task: root
access object:
execution info: time:2.75s, loops:2, Concurrency:OFF
operator info: ogw.objects.bucket_id, ogw.objects.name, ogw.objects.uid, ogw.objects.size, ogw.objects.mtime, ogw.objects.etag, ogw.objects.display_name, ogw.objects.appendable
memory: 196.8 KB
disk: N/A
*************************** 3. row ***************************
id: └─IndexLookUp_27
estRows: 1001.00
actRows: 1001
task: root
access object:
execution info: time:2.75s, loops:2, index_task: {total_time: 2.74s, fetch_handle: 2.74s, build: 62.8µs, wait: 2.96µs}, table_task: {total_time: 11s, num: 1, concurrency: 4}
operator info: limit embedded(offset:0, count:1001)
memory: 235.7 KB
disk: N/A
*************************** 4. row ***************************
id: ├─Limit_26(Build)
estRows: 1001.00
actRows: 1001
task: cop[tikv]
access object:
execution info: time:2.74s, loops:1, cop_task: {num: 112, max: 587.4ms, min: 141.6ms, avg: 339.6ms, p95: 488.2ms, max_proc_keys: 823941, p95_proc_keys: 770500, tot_proc: 38s, tot_wait: 4ms, rpc_num: 112, rpc_time: 38s, copr_cache: disabled}, tikv_task:{proc max:573ms, min:139ms, p80:411ms, p95:469ms, iters:59923, tasks:112}
operator info: offset:0, count:1001
memory: N/A
disk: N/A
*************************** 5. row ***************************
id: │ └─Selection_25
estRows: 1001.00
actRows: 1241
task: cop[tikv]
access object:
execution info: tikv_task:{proc max:573ms, min:139ms, p80:411ms, p95:469ms, iters:59923, tasks:112}
operator info: eq(ogw.objects.bucket_id, ".bucket.meta.bucket_b"), like(ogw.objects.name, "%", 92)
memory: N/A
disk: N/A
*************************** 6. row ***************************
id: │ └─IndexRangeScan_23
estRows: 38950.61
actRows: 60842866
task: cop[tikv]
access object: table:objects, index:idx_nm_bkt_ver(name, bucket_id, version_id)
execution info: tikv_task:{proc max:438ms, min:101ms, p80:299ms, p95:344ms, iters:59923, tasks:112}
operator info: range:("dir10",+inf], keep order:true
memory: N/A
disk: N/A
*************************** 7. row ***************************
id: └─TableRowIDScan_24(Probe)
estRows: 1001.00
actRows: 1001
task: cop[tikv]
access object: table:objects
execution info: time:2.45ms, loops:2, cop_task: {num: 32, max: 1.07ms, min: 615µs, avg: 785.4µs, p95: 1.07ms, max_proc_keys: 42, p95_proc_keys: 42, tot_proc: 21ms, rpc_num: 32, rpc_time: 24.3ms, copr_cache: disabled}, tikv_task:{proc max:1ms, min:0s, p80:1ms, p95:1ms, iters:44, tasks:32}
operator info: keep order:false, stats:pseudo
memory: N/A
disk: N/A
7 rows in set (2.74 sec)
```
从这里或许可以看出问题,使用 IndexRangeScan 检索 bucket_id = '.bucket.meta.bucket_b' and name like '%' and name > 'dir10' 时候,estRows: 38950.61,但是实际检索了 actRows: 60842866,导致 tidb 向 tikv grpc q请求次数达到 tasks:112 次。
*************************** 6. row ***************************
id: │ └─IndexRangeScan_23
estRows: 38950.61
actRows: 60842866
task: cop[tikv]
access object: table:objects, index:idx_nm_bkt_ver(name, bucket_id, version_id)
execution info: tikv_task:{proc max:438ms, min:101ms, p80:299ms, p95:344ms, iters:59923, tasks:112}
operator info: range:(“dir10”,+inf], keep order:true
memory: N/A
disk: N/A
同样的对比第二条 sql,bucket_id = '.bucket.meta.bucket_d' and name like '%' and name > 'dir10' 的情况,estRows: 1036.13,实际检索到 actRows: 2417, grpc 次数为 tasks:1。
*************************** 6. row ***************************
id: │ └─IndexRangeScan_23
estRows: 1036.13
actRows: 2417
task: cop[tikv]
access object: table:objects, index:idx_nm_bkt_ver(name, bucket_id, version_id)
execution info: tikv_task:{proc max:453ms, min:1ms, p80:297ms, p95:361ms, iters:85858, tasks:1}
operator info: range:("dir10",+inf], keep order:true
memory: N/A
disk: N/A
到这里就可以看出同样的执行计划,耗时差别很大的原因了:检索满足第一条 sql 记录的需要扫描的索引条数是 60842866 条,而第二条只需要 2417 条,两者 grpc 次数分别为 112、1,这就是真正原因。
查询出 bucket_id = ‘.bucket.meta.bucket_d’ and name like ‘%’ and name > ‘dir10’ 要过滤 60842866 条无效记录,所以导致问题的原因怀疑跟数据集的特征有关,通过下面查询来验证:
这张图中,查询语句一满足条件的第一条记录的 name,满足条件的 name 值为 dirMp2/object0.obj,而在 name > ‘dir10’ 且 name < ‘dirMp2/object0.obj’ 存在的记录数为 60841625 条。

同样的的,查询语句二满足条件的第一条记录的 name 为 dir10/0bj1.txt,对比语句一的条数是 2 条。

经过上面对比验证,因为数据集的问题,满足语句一和语句二查询条件需要过滤的索引条数存在巨大差异,导致语句一需要扫描过多数据。
如果把语句一中 name 的过滤条件改一下,把 name 改为 上面的 “dirMp2/object0.obj” 避免掉检索这么多无效记录,就可以提高速度:

解决方法
上面已经找到了问题的原因,如果能适当的选择 name 的范围,那么使用 idx_nm_bkt_ver 索引还是比较高效的,但是根据业务情况,没办法找到那个合适的值。
问题的转机发生在观察到他们查询条件中 bucket_id 一般都作为查询条件而且是用的 “=” 条件。
使用 bucket_id = ‘.bucket.meta.bucket_d’ and name like ‘%’ and name > ‘dir10’ 的查询语句,把联合索引从 ( name , bucket_id , version_id ) 调整为 ( bucket_id , name , version_id ),这样的筛选性才是最好的。
调整索引后,两条 sql 执行速度都特别快,问题得到完美解决。
针对这个问题,关于联合索引:
- 一般筛选性强的列放在前面,筛选性弱的列放在后面
- 如果使用了索引中某个列,但是这个列不是索引的第一位,那么不能高效使用这个索引检索数据
- 对于使用索引中的列 “=” 和 “>” 这种,把 “=” 用到的列放在前面
业务的同事,就是严格参考第一条,把筛选性强的放在了前面,但是没有考虑好 sql 查询条件特征,导致查询性能不理想。如果 sql 是 where name = “XXX” 这种类型,那么把 name 列放在前面无疑是十分高效的,所以具体情况要根据具体 sql 来分析。
其他
这里发现执行计划有个地方没有优化好,当前使用的版本是 4.0.11,不知道后面的高版本有没有改进,没有测试。问题如下:
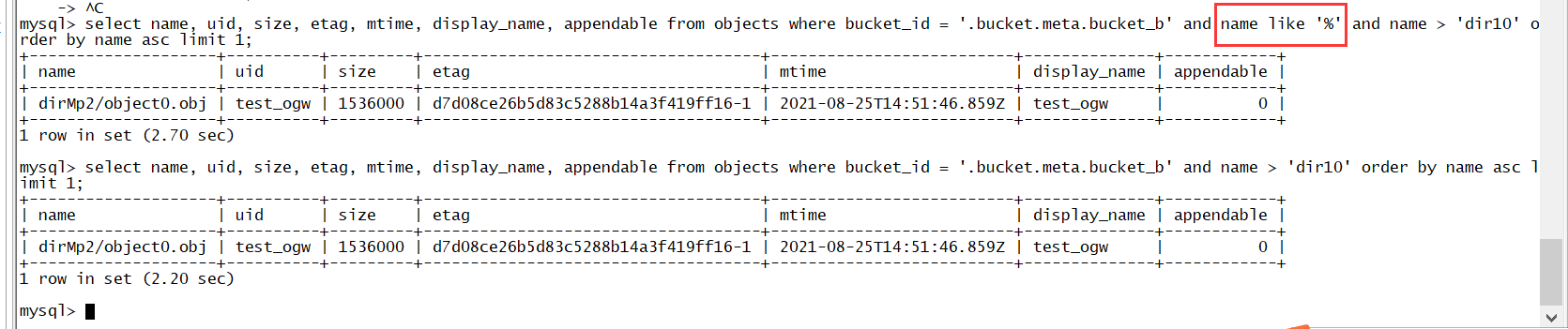
这里 name like ‘%’ 等价于 name is not null, 而其他条件 name > ‘dir10’,保证了 name like ‘%’ 在执行时候是可以优化掉的,从结果上看,对应时间分别为 2.70s 和 2.20s,耗时增加了 0.5s。执行计划看这部分:
*************************** 5. row ***************************
id: │ └─Selection_25
estRows: 1001.00
task: cop[tikv]
access object:
operator info: eq(ogw.objects.bucket_id, ".bucket.meta.bucket_b"), like(ogw.objects.name, "%", 92)
这个 like(ogw.objects.name, “%”, 92) ,等价语句这个部分是可以去掉的,期待官方的优化。