

作者:李坤,PingCAP 互联网架构师,TUG Ambassador,前美团、去哪儿数据库专家。
背景
从现有的数据库使用场景来看,随着数据规模的爆发式增长,考虑采用TiDB这种分布式存储的业务,通常都是由于触发了单机数据库的瓶颈,我认为瓶颈分为3点:存储瓶颈、写入瓶颈、读取瓶颈。我们希望TiDB能够解决这3个瓶颈,而存储瓶颈是可以首先被解决的,随着机器的扩容,存储瓶颈自然就可以几乎线性的趋势扩展;而写入和读取,我们希望能够利用上多机的CPU、内存,这样才能突破单机的读写性能瓶颈,这就需要将压力分摊到多台机器上。如果需要读写的数据,集中到了一台机器上,甚至一个region上,这就必然导致热点。
这里就从使用者的角度和大家分享下,处理和热点相关的问题一些思考和手段。
- TiDB和MySQL在设计Schema的时候,有什么区别?
- 当集群性能出现问题,如何分析是否由热点导致?
- 热点是读热点,还是写热点?
- 如何确定热点是产生在哪个表上?是数据热点还是索引热点?
- 确定热点后,如何处理?
TiDB和MySQL在设计Schema主键的时候,有什么区别
MySQL的使用习惯
MySQL上通常都建议使用int(bigint)类型的自增id作为主键,这是由于以下几个原因:
- 性能:随机写改为顺序写,性能更好
- 功能:更容易运维,比如osc改表,归档等
- 易用:方便id范围检索,分段update、delete数据
TiDB的使用对比
使用TiDB的用户,有相当一部分都是从MySQL迁移过来的,可能就会错误的认为任何情况都可以沿用MySQL设计Schema的习惯,而没有考虑分布式数据库的特点。我们分别针对以上几点,考虑TiDB该如何应对。(当写入qps达到一定大小时考虑,比如超过1k,否则可以沿用MySQL的方式)
- 从性能考虑,TiDB使用自增id并没有带来性能的好处。我们知道TiDB是按照range的方式将数据分为一个个region,我们希望TiDB的写入分散到各个region中把多机利用起来,而不是集中在一个range,新数据都集中在一起,这会带来数据热点,包括读热点和写热点,所以采用自增id反倒影响性能。
- TiDB可以在线改表,直接改元数据,不需要依靠自增id改表。分布式数据库,应该也不用怎么归档。
- TiDB根据业务需求,或许也需要分段检索,可以通过业务的一些特征来处理,比如订单号、时间等。
- 在MySQL中,基本上单机容量关系,单表到达不了自增ID的瓶颈值,但是在特殊的replace into场景中,一旦写入了一个大值却能够到达这一瓶颈,TiDB也是一样,这种问题是不好处理的。
SHARD_ROW_ID_BITS
TiDB 会在以下情况下采用一个隐式的自增 _tidb_rowid,作为数据的key
- 对于 PK 非整数的表
- 对于没有 PK 的表
- 对于组合主键,无论是否都为int类型
通过设置 SHARD_ROW_ID_BITS 可以把 _tidb_rowid 自动打散,解决写入热点问题。比如设置为4,代表16个分片 ,如果你的tikv个数在16个以内是足够用了。设置的过大会造成 RPC 请求数增多,增加 CPU 和网络开销。举例如下:
# 创建一个分16片的表,产生的key就是随机的了,可以分散在不同range范围的region中,最大可以同时利用16个region
CREATE TABLE t (c int) SHARD_ROW_ID_BITS = 4;
insert into t values(1);
insert into t values(2);
insert into t values(3);
insert into t values(4);
insert into t values(5);
mysql> SELECT _tidb_rowid,c from t order by c;
+---------------------+------+
| _tidb_rowid | c |
+---------------------+------+
| 1 | 1 |
| 6917529027641081858 | 2 |
| 5188146770730811395 | 3 |
| 3458764513820540932 | 4 |
| 1729382256910270469 | 5 |
+---------------------+------+
5 rows in set (0.00 sec)
我们来解析一下_tidb_rowid的真面目,转换为2进制就很清晰了。总共64位,它的前4位是4bit的随机数,也就是我们设置的SHARD_ROW_ID_BITS = 4,将顺序值转换为随机值解决热点问题;后面60位是自增的值,足够用了。
[~]$ echo "obase=2;ibase=10;1"|bc
_0000_00000000000000000000000000000000000000000000000000000000_001
[~]$ echo "obase=2;ibase=10;6917529027641081858"|bc
_1100_00000000000000000000000000000000000000000000000000000000_010
[~]$ echo "obase=2;ibase=10;5188146770730811395"|bc
_1001_00000000000000000000000000000000000000000000000000000000_011
[~]$ echo "obase=2;ibase=10;3458764513820540932"|bc
_0110_00000000000000000000000000000000000000000000000000000000_100
[~]$ echo "obase=2;ibase=10;1729382256910270469"|bc
_0011_00000000000000000000000000000000000000000000000000000000_101
TiDB使用建议
从以上几点可以看到TiDB并没有那么依赖自增id,那么TiDB用什么作为主键呢?
- 如果写入qps很小,依然用自增id也是没问题的
- 如果业务有一个随机并唯一的int类型的业务id,建议用该值作为主键,这样可以自然分散到不同region中;
- 如果业务有一个自增并唯一的int类型的业务id,建议不使用主键,将该id设为唯一索引,使用SHARD_ROW_ID_BITS = [4~6],分别对应最多16~64个tikv。
- 如果业务有一个唯一的字符串类型的业务id,同上。
当集群性能出现问题,如何分析是否由热点导致
当我们接手一个业务,或者业务在测试时反馈性能不理想,如何确定是否是热点导致的呢?
需要从几个方面观察,如果某个节点相比其他节点特别突出,说明这个节点有热点。
- 是否某个tikv节点的raft store、apply的cpu使用率偏高
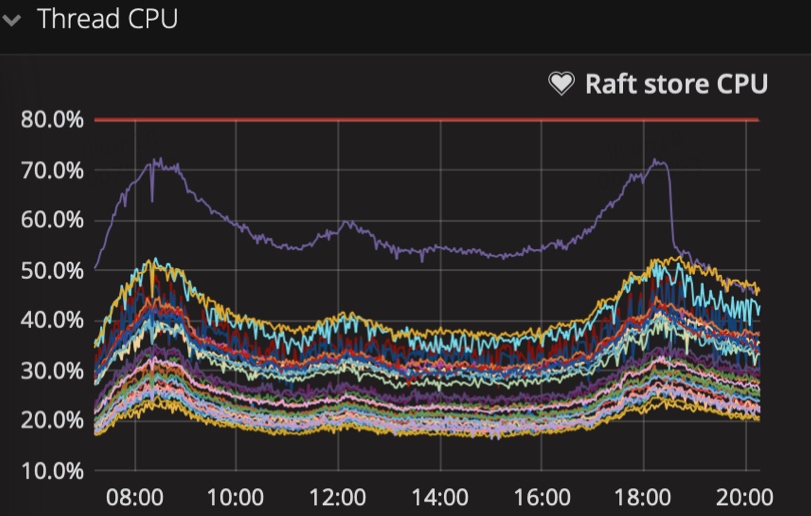
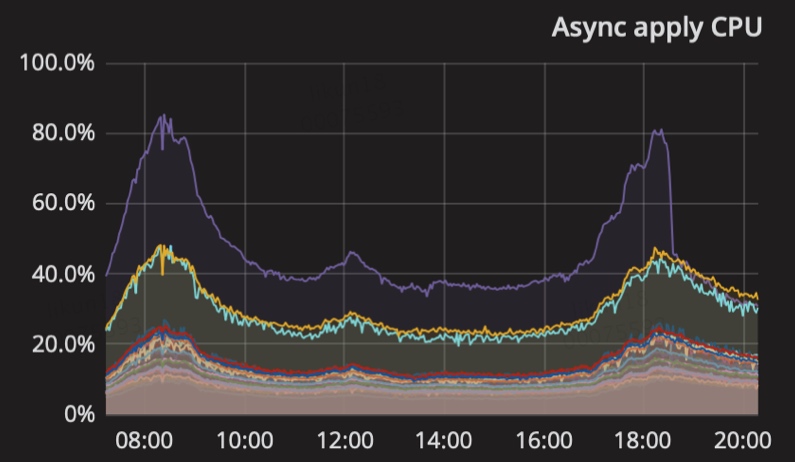
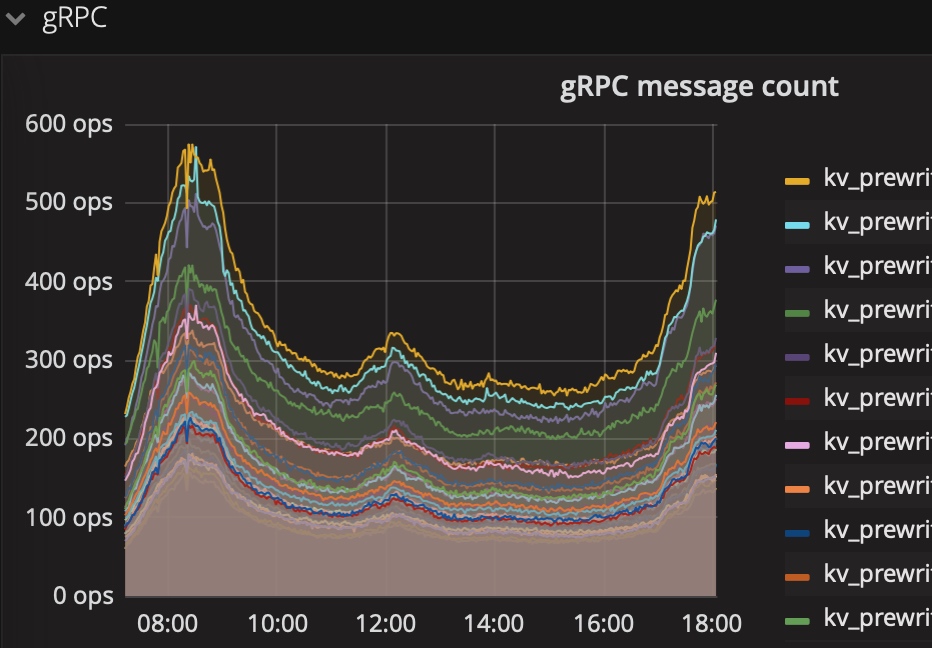
- 是否某个tikv节点grpc消息偏多
sum(rate(tikv_grpc_msg_duration_seconds_count{instance=~"$instance", type="kv_prewrite"}[1m])) by (type,instance)
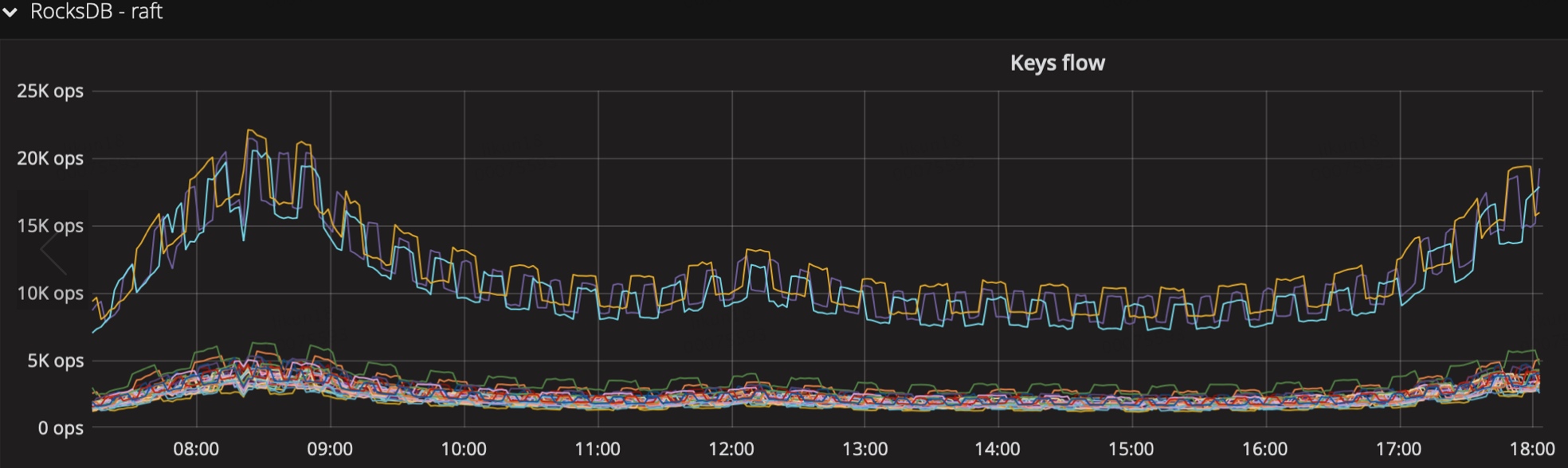
- 是否某个tikv节点流量偏多,重点关注下面3个指标(prometheus公式增加 by (instance) )
keys flow:按keys个数统计
read flow:读流量
write flow:写流量

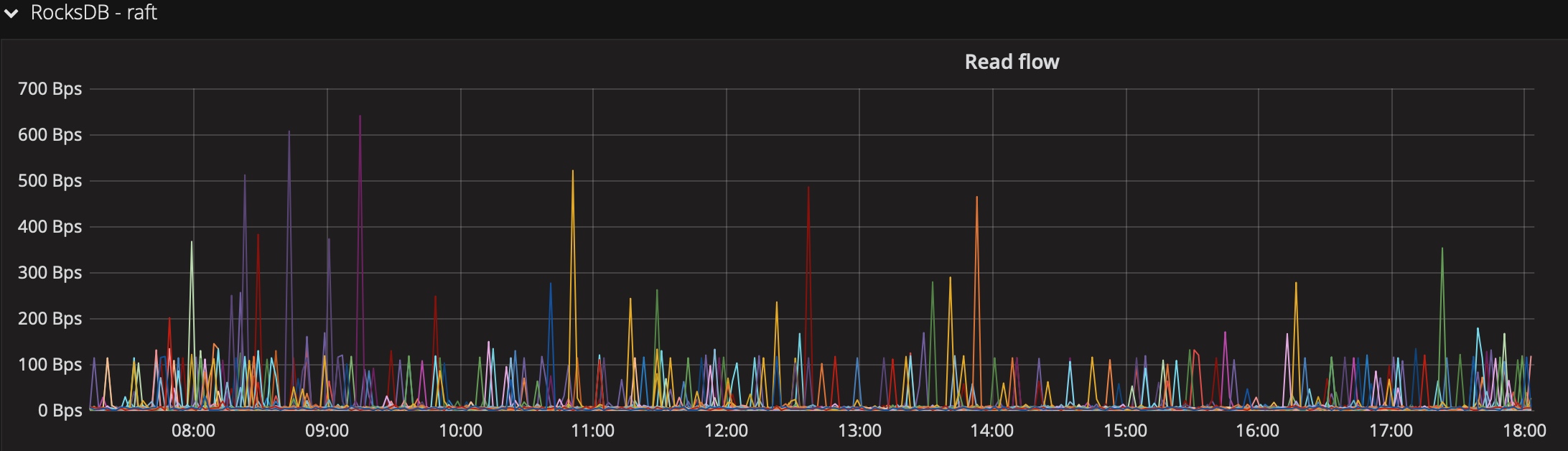
- 直接看监控中的hotregion面板,这里展示的是pd识别到的热点
目前统计热点的标准是根据总流量信息动态算分一个阈值,pd会将统计为热点的region,在每个store上面的个数保持均衡。如果某个store的热点region集中,则表示有热点。
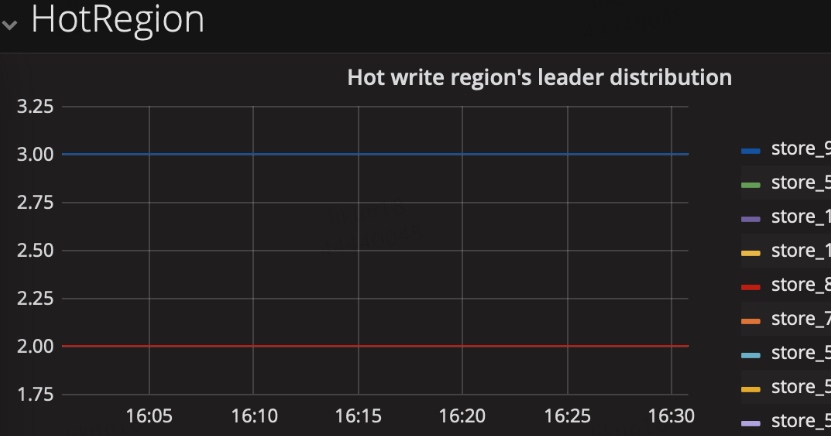
如何确定热点是读还是写
- 参考上一步read flow、write flow,看是哪一个类型流量不均匀
- 可以用官方pd_ctl命令行工具,执行 hot store、hot read、hot write 3种命令,可以直接看到哪个节点上是热点,读写热点的region分别存在哪些,来实时观察读写热点
命令的几个输出参数的含义:
as_peer/as_leader:按2个维度来统计,作为peer或者leader
total_flow_bytes:这个store总的流量
regions_count:这个store热点的region数量
region_id:region的id
flow_bytes:这个region的流量
hot_degree:表示 region 是持续热点,每分钟上报 1次,如果是热点,degree+1
AntiCount:类似 ttl,过了几次后才踢出hot cache(定期更新,如果判断 flowBytes < hotRegionThreshold,不会马上从 cache 清掉,如果没有这个判断,可能存在误判踢掉后后面又重新加进来)
Version:记录region分裂的次数
Stats:记录一些最近添加的信息
举例一小段输出:可以看出store 10上有1个热点region,在近643次都被上报为热点,该region分裂231次,很有可能是一直在region尾部追加数据导致的热点
"as_peer": null,
"as_leader": {
"10": {
"total_flow_bytes": 2307649,
"regions_count": 1,
"statistics": [
{
"region_id": 7705,
"flow_bytes": 2341686,
"hot_degree": 643,
"last_update_time": "2019-08-05T18:30:15.901413761+08:00",
"AntiCount": 1,
"Version": 231,
"Stats": null
}
]
},
如何确定热点是哪张表,是表数据还是索引
使用tidb的http接口,根据上一步的region_id,查看region,可以看到是表还是索引,如果是索引是哪个索引,如下面的例子,可以看到region为库db1的表table1的索引idx_column1
curl http://{tidb_ip}:10080/regions/12345
{"region_id":12345,"start_key":"xxxAAAAAJLX2mAAAAAAAAAAwOAAAAAATPu8gOAAAAAAB6M4gOAAAAAANMeywOAAAAAANMezA==","end_key":"xxxxAAAAAJLX2mAAAAAAAAAAwOAAAAAATPu8gOAAAAAAB6ZaAOAAAAAAMNDgQOAAAAAAMNDgg==","frames":[{"db_name":"db1","table_name":"table1","table_id":123,"is_record":false,"index_name":"idx_column1","index_id":3,"index_values":["11111","22222","33333","44444"]}]}
甚至可以使用mok工具,分析region的start_key和end_key对应的数据,https://github.com/disksing/mok,根据start和end返回的table和row,分析具体是哪部分数据
确定热点后,如何处理
- 如果是热点region不是唯一的,有多个,但都集中到某一个store上,先确认热点调度是否可运行(如果没有调整过默认是打开的),从pd_ctl执行config show all,查看2个地方:
-
region-schedule-limit 是否大于0
-
hot-region 部分是否开启
如果这2处正常,观察pd下的operator监控,调度中是否有较多的balance-region,而一直没有热点调度的指标,则可能是热点调度被抢占,这个问题在2.1.14解决,该版本加了hot-region-schedule-limit,将热点调度从region-schedule-limit调度中拆分开了
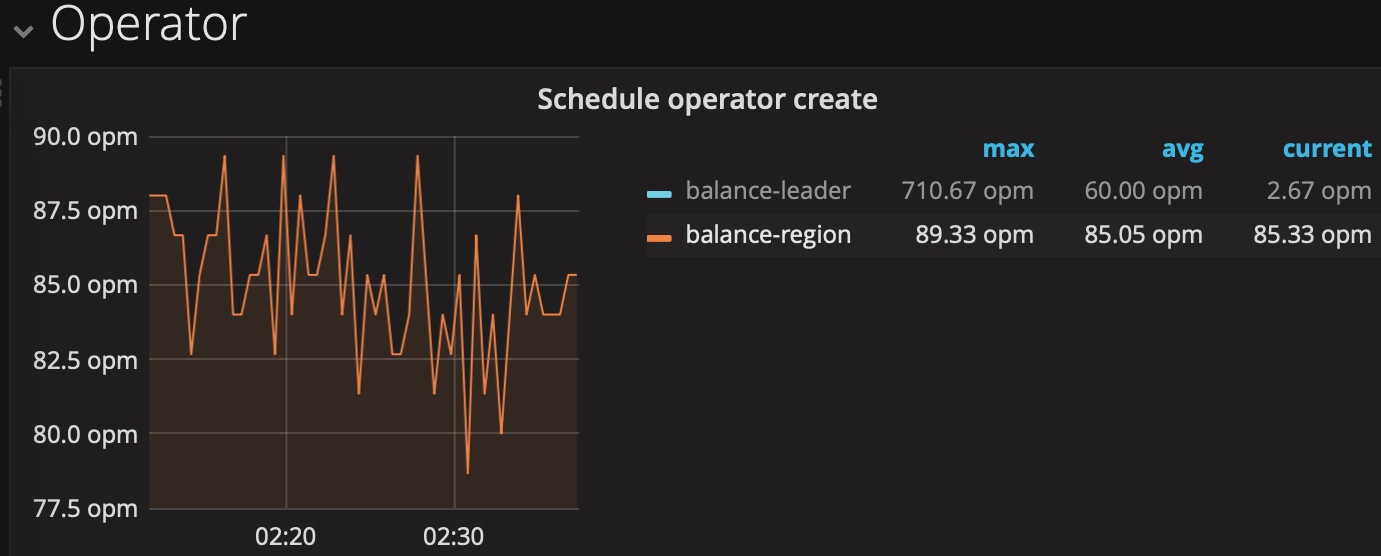
- 如果是由于前期设计不当,导致类似自增id的情形,导致热点region,目前是不能在线调整主键的,只可以去掉自增属性,需要业务配合整改 schema 设计;
- 如果是热点小表的问题,可以通过命令手动 split region
>> operator add split-region 1 --policy=approximate // 将 Region 1 对半拆分成两个 Region,基于粗略估计值,消耗更少的 I/O,可以更快地完成。
>> operator add split-region 1 --policy=scan // 将 Region 1 对半拆分成两个 Region,基于精确扫描值,更加精确
后续
目前分析热点问题,对于新手会有一点门槛,有时候复杂时要靠按region、store流量排序,才能分析出来。据了解官方在3.0和4.0的规划中,都将热点问题的排查和调度进行了优化,到时可能热点调度很可能就会变得很自动和直观,但我们了解其内部原理还是非常有好处的。