

本文整理自 TUG 大使、随手科技大数据工程师韩超在 8 月 25 日 TUG 华南区首次线下活动分享。
随手科技是国内领先的个人理财应用服务提供商,旗下拥有随手记、卡牛、随管家等多款明星产品,目前用户规模已超过三亿。

在随手科技的发展过程中,业务遇到的一些痛点包括:开发面对的数据库分库分表的问题,数据冷热分离相关的问题等。
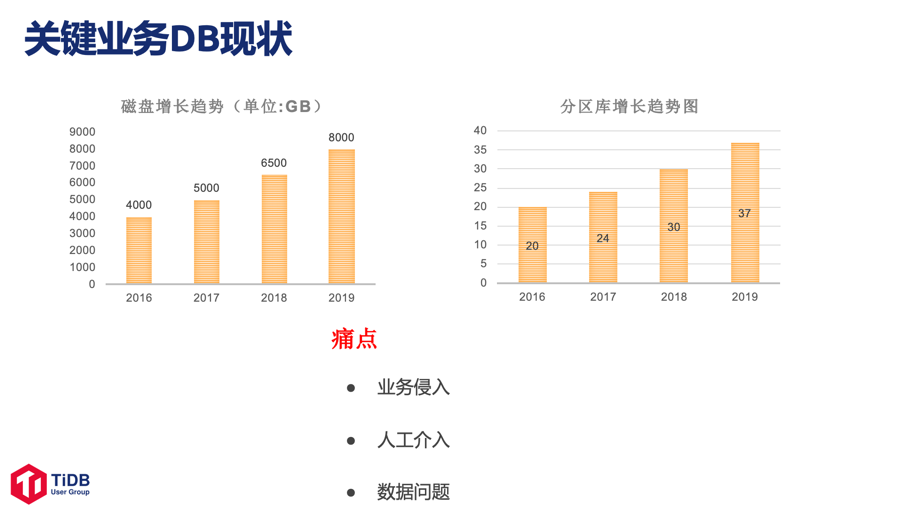
在随手科技的大数据业务建设过程中,一些痛点有:数据落地过程流程长,OLTP/OLAP 分散于多个组件。
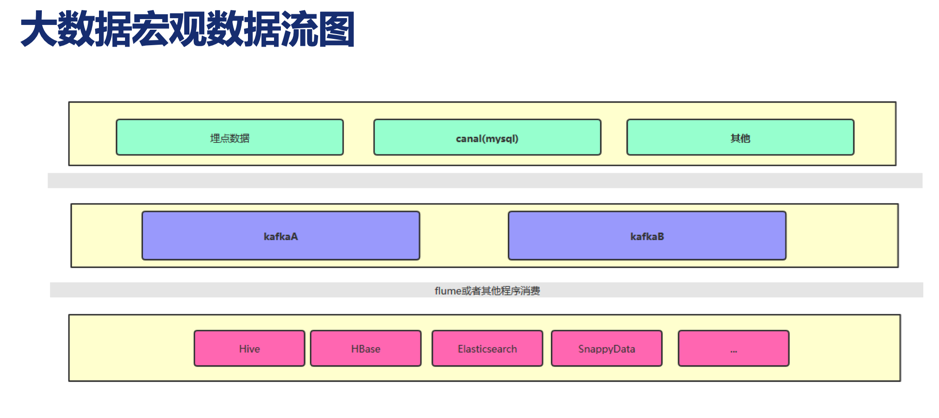
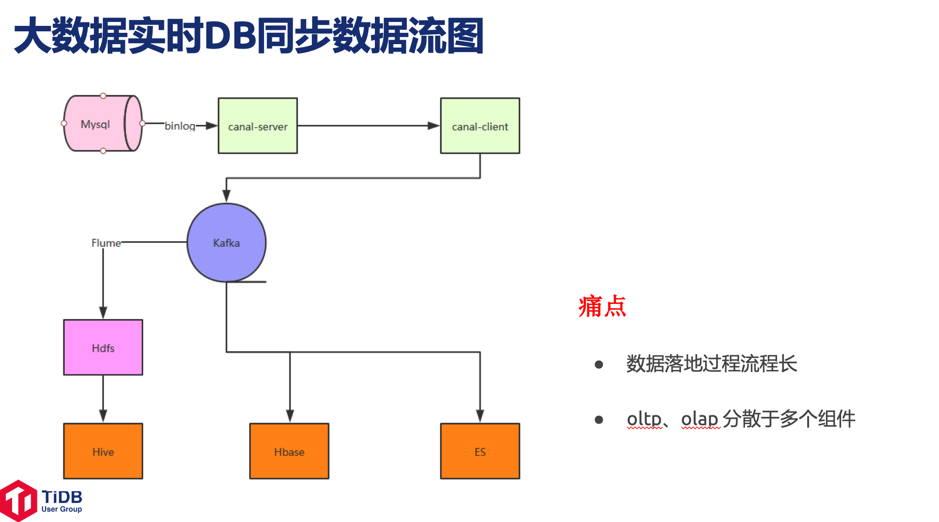
接下来随手科技看到了 TiDB,调研了 TiDB 及相关的工具和目前应用情况,了解到 TiDB 的特点:
- 高度兼容 MySQL;
- 能水平弹性扩展;
- 支持分布式事物;
- 是真正金融级的高可用;
- 拥有一站式 HTAP 解决方案;
- 是云原生 SQL 数据库。
基于此,随手科技最终选择了使用 TiDB。
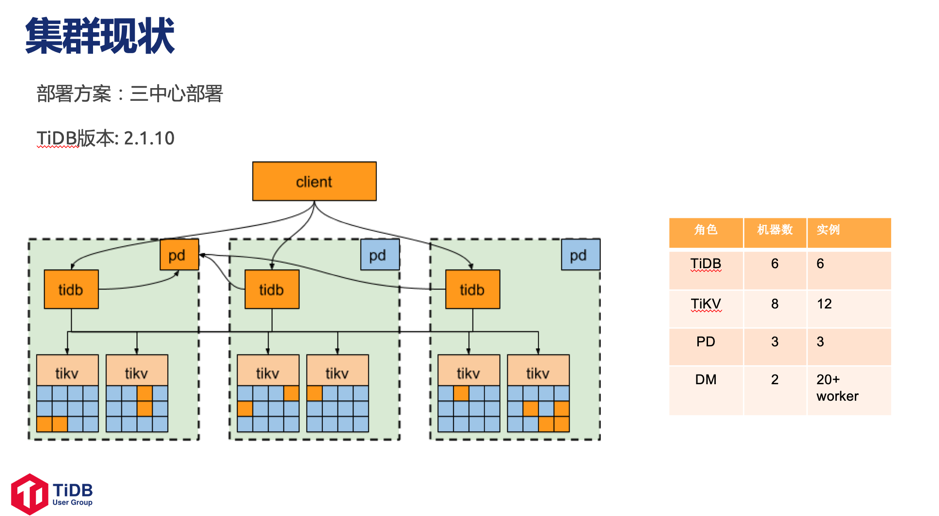
目前随手科技使用 2.1.10 版本的 TiDB,采用三中心部署方案,部署了 6 台 TiDB 机器和 8 台 TiKV 机器,部署架构图如下。
随手记使用 TiDB 的具体场景
随手记使用 TiDB 有两个典型场景。
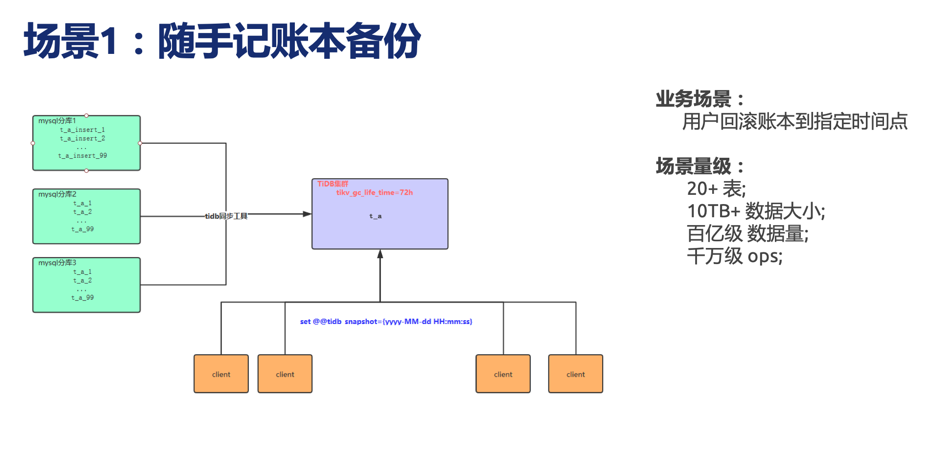
场景1
用户回滚账本到指定时间点,场景量级达到 20+表,10 TB+数据,百亿级数据量,千万级 OPS。
- 前方案:使用的是 Hive及 HBase 两个方案,问题是入库合并时间长(Hive),校验及修复成本耗时高。
- 现有方案:TiDB,通过调整快照时间,直接 SQL 查询,数据过程简单,修复及校验成本相对较低。
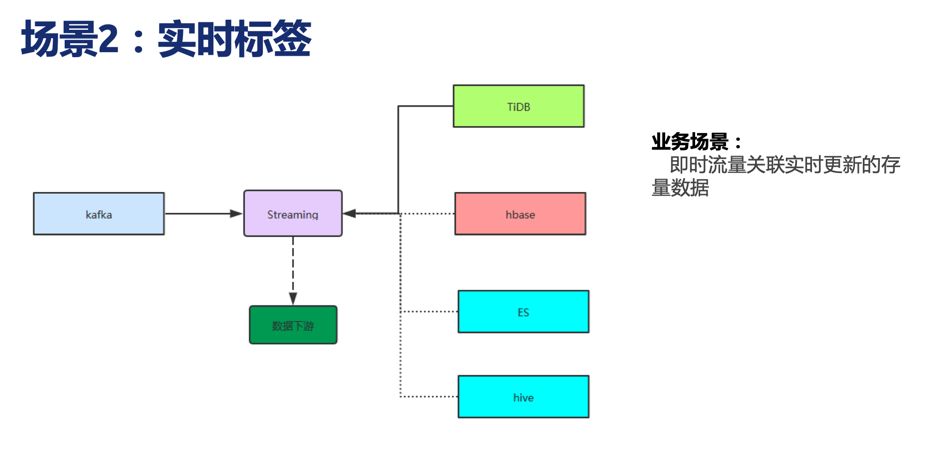
场景二
即时流量关联实时更新的存量数据。
业务:实时标签
场景:及时流量关联实时更新的存量数据
方案对比:
- Hive: 满足不了实时性要求。
- HBase、ES: 需要将流数据拆开请求得到结果,有一定开发成本,效率不高且对组件性能造成影响。
- TiDB:使用 TiSpark,将 Kafka 的数据转换成结构化的临时表,跟 TiDB 实时同步的表进行关联。
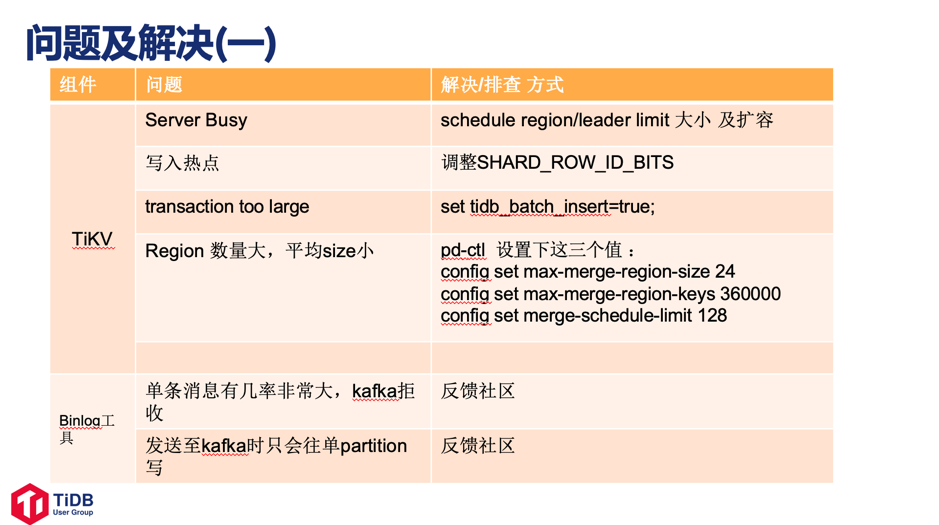
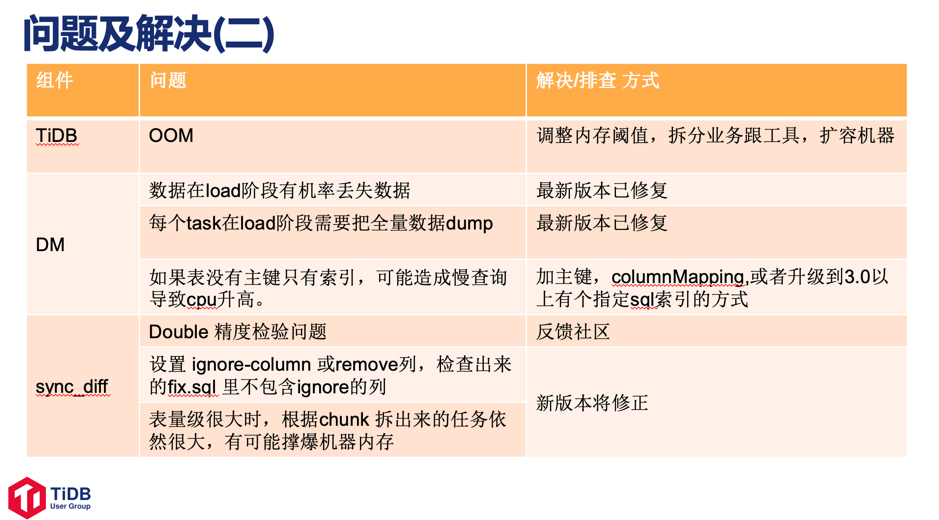
遇到的问题及相应的解决方案
在使用 TiDB 的过程中,随手科技总结了一些遇到了问题及其解决方案,主要问题有:主键冲突,数据热点,Kafka, DM工具,Task 相关问题等。
展望未来
对于未来 TiDB 的使用,随手科技有一些相应的规划:
- 积极推广 TiDB,从边缘到核心逐渐渗透,挖掘更多 TiDB 场景。
- 贴近社区,提升能力,回馈社区。
- 评估测试 TiDB 升级 3.0+ 版本。
随手科技的 TiDB 实践分享完之后,现场也有很多小伙伴们积极提出了一些问题。
Q&A
Q: 从开始调研到第一个集群上线大概多长时间?
A: 这个跟很多东西有关,我们其实今年三四月份才正式往下推。一开始是测试,测试的时候集群规模小,但其实更能暴露出来集群到了瓶颈点的问题,我们也做了很多可用性的测试以及暴力的测试,结果基本符合预期,然后我们选择符合场景的现有业务,迁移上去做试点,整个到上线时间大概花了几个月。
Q : 因为 to B 这一块,其实需要上层做决定,要去推业务,我们需要去说服老大去采纳技术,随手科技这边有没有什么样的杀手锏或者方案,可以分享一下这方面的故事或者一些经验?
A: 这个要分情况,我们老大本身就对 TiDB 有所了解,所以本身就很支持这个事情。
Q : 我想问一下,刚刚那个图表里面不是有排查嘛,排查过程是怎么样的,或者让同事他们首先可以去找,要不然找 issue 的话可能 contributor 会去做,如果想找问题的话要去哪找比较快或者更好上手?刚那个表那个里面有些排查还是非常重。
A: 因为有问题的话,其实我们首先反复进行了验证,确认不是因为我们误操作造成的。比如 DM 同步,我们做了挺多遍,首先确认我们没有误操作,第二确认数据在什么情况丢,在哪个阶段丢,丢的时候是哪个组件引发的。
我们的场景是分库分表合库,而且是几十个分库,量也大。这个过程是同步结束后,我们数据校验时发现一部分数据损失,并且是挺老的数据,我们重复同步了几次,均会有相同情况。接着丢失的数据都会在 DM 第一步 dump 下来的 SQL 文件出现。所以我们确认是在 Load 阶段发生的。丢失会丢掉整条insert sql,里面可能有几千行数据。然后 DM 会有一些报错,比如 server busy,连接丢失等。我们也试过把一个task 分批,几个 worker 跑完再起几个来降低 TiDB 压力,这种情况下不会丢失。所以我们把问题确定时 load 时发生异常的情况下 savepoint 应该有问题,然后我们将问题整理并反馈 TiDB 的同事,他们很重视并很积极的帮助我们,安排专人对接并排期解决,在此也非常感谢 TiDB 的小伙伴。