

一. 背景描述
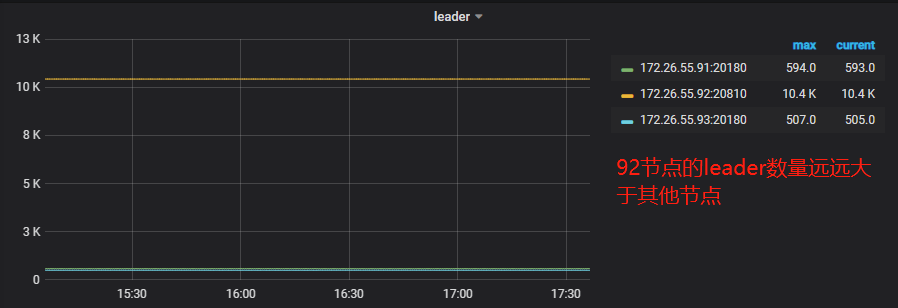
大家在使用 TiDB 的过程中有可能会遇到 Region 和 Leader 分布不均的情况,监控信息如下:
leader 信息:
region 信息:
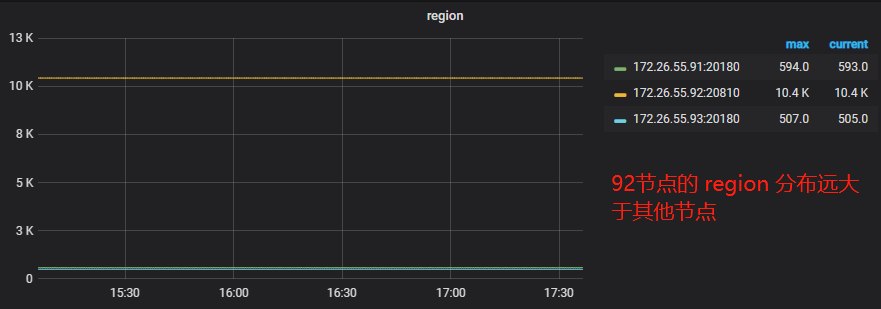
虽然最终解决了问题,但是整个排查及优化的过程还是很繁琐的,主要是因为架构的复杂度及对基础参数的不了解。为了方便以后对此类 region 分布不均问题的处理,结合官方文档的给出的思路整理一份排查及优化指南。
二. 官方排查问题思路
先贴一张 region 不均衡问题的官方的解释:


https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices#热点分布不均匀
方方面面的都介绍的很详细了,接下来根据实际情况来捋一下排查手段及优化步骤。
三. 查看 store 打分
排查 region 分布不均的问题,第一步就是先查看 store 的打分,主要参考下面这个指标:
Store Region score:每个 TiKV 实例的 Region 分数
PD 面板 -> Statistics -> balance -> Store Region score
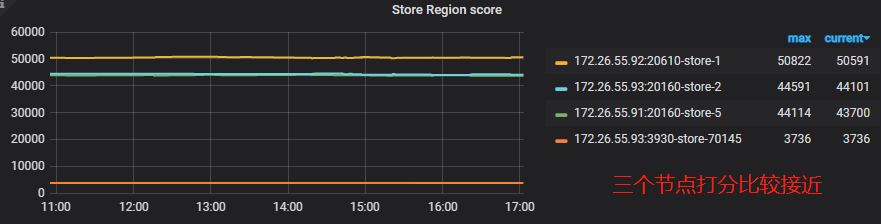
关于 store 的打分可以分为以下两种:
store 分数接近
打分比较接近,可以认定为均衡状态,进入以下排查流程:
1. 存在大量空 Region 或小 Region
1.1 问题排查
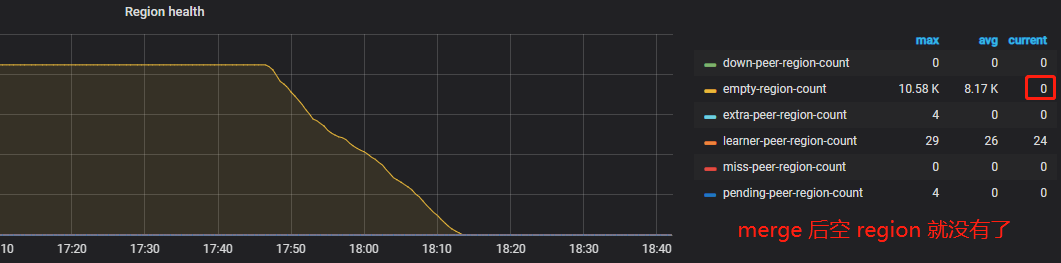
overview 面板 -> PD -> Region health
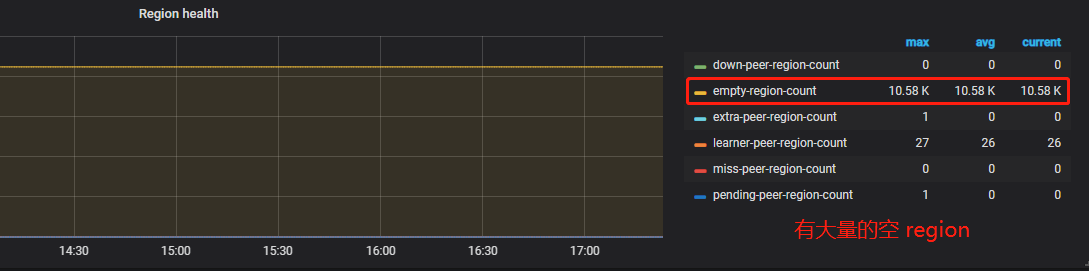
可以看到系统存在大量的空 region,此时我们需要开启 Region merge ,通过调度把相邻的小 Region 进行合并。开启后,PD 在后台遍历,发现连续的小 Region 后发起调度。
1.2 相关参数
PD 通过两个参数,触发 Region merge:
-
max-merge-region-size
- 控制 Region Merge 的 size 上限,当 Region Size 大于指定值时 PD 不会将其与相邻的 Region 合并。
- 默认: 20 (单位MiB)
-
max-merge-region-keys
- 控制 Region Merge 的 key 上限,当 Region key 大于指定值时 PD 不会将其与相邻的 Region 合并。
- 默认: 200000
1.3 操作步骤
接下来去系统中调整这两个参数:
pd-ctl -i -u http://172.XXX.XXX.XXX:2379 # 进入 pd 命令界面
» config show scheduler # 查看当前参数
{
"replication": {
"enable-placement-rules": "true",
"isolation-level": "",
"location-labels": "",
"max-replicas": 3,
"strictly-match-label": "false"
},
"schedule": {
"enable-cross-table-merge": "true",
"enable-joint-consensus": "false",
"high-space-ratio": 0.7,
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 4,
"leader-schedule-limit": 24,
"leader-schedule-policy": "count",
"low-space-ratio": 0.8,
"max-merge-region-keys": 0, #当前为0,所以没开启merge功能
"max-merge-region-size": 0, #当前为0
"max-pending-peer-count": 4147483647,
"max-snapshot-count": 18,
"max-store-down-time": "30m0s",
"merge-schedule-limit": 8,
"patrol-region-interval": "100ms",
"region-schedule-limit": 80,
"region-score-formula-version": "v2",
"replica-schedule-limit": 64,
"split-merge-interval": "1h0m0s",
"tolerant-size-ratio": 0
}
}
» config set max-merge-region-keys 50000 # 修改 max-merge-region-keys 参数
» config set max-merge-region-size 10 # 修改 max-merge-region-size 参数
2. 热点负载问题
2.1 问题排查
查看写热点:
PD 面板 -> Statistics - hot write -> Hot Region’s leader distribution
Hot Region’s leader distribution:每个 TiKV 实例上成为写入热点的 leader 的数量
查看读热点:
PD 面板 -> Statistics - hot read -> Hot Region’s leader distribution
Hot Region’s leader distribution:每个 TiKV 实例上成为读取热点的 leader 的数量
2.2 存在热点问题
2.2.1 相关参数
如果监控出现 hot Region,但是调度速度跟不上,不能及时地把热点 Region 分散开来,这时候需要调整部分参数:
-
hot-region-schedule-limit
- 控制同时进行的 hot Region 任务。该配置项独立于 Region 调度。
- 默认值:4
-
hot-region-cache-hits-threshold
- 设置识别热点 Region 所需的分钟数。只有当 Region 处于热点状态持续时间超过此分钟数时,PD 才会参与热点调度。
- 默认值:3
2.2.2 操作步骤
pd-ctl -i -u http://172.XXX.XXX.XXX:2379 # 进入 pd 命令界面
» config show scheduler # 查看当前参数
{
"schedule": {
"hot-region-cache-hits-threshold": 3,
"hot-region-schedule-limit": 4
}
}
» config set hot-region-schedule-limit 8 # 通过调大这个参数,可以加快热点的调度速度
» config set hot-region-cache-hits-threshold 2 # 调小这个参数使 PD 对更快响应流量的变化
2.3 不存在明显热点
从监控上看不到明显的热点情况,但是从 TiKV 的监控可以看到部分节点负载明显高于其他节点。这是因为目前 PD 统计热点 Region 的维度比较单一,仅针对流量进行分析,在某些场景下无法准确定位热点。
2.3.1 相关调度器
可以添加 scatter-range-scheduler 调度器使这个 table 的所有 Region 均匀分布。
2.3.2 操作步骤
先定位热点所在的表:
select * from information_schema.tidb_hot_regions;
通过 curl 添加 scatter-range-scheduler 调度器:
curl -X POST http://{TiDBIP}:10080/tables/{dbname}/{tablename}/scatter
移除调度器语句:
curl -X POST http://{TiDBIP}:10080/tables/{dbname}/{tablename}/stop-scatter
这个添加调度器操作需要在业务低峰期进行,不然会影响线上性能。
3. store 软硬件差异
部分环境可能存在 tidb、tikv 所在物理机性能配置有差异的情况,可以通过参数配置控制 leader 和 region 的分布。
3.1 问题排查
通过不同机器之间的 cpu、内存、磁盘、网络等硬件的对比,以及操作系统、系统参数等环境对比。
3.2 相关参数
-
LEADER_WEIGHT
- Store 的 leader 权重
- 默认值:1
-
REGION_WEIGHT
- Store 的 Region 权重
- 默认值:1
3.3 操作步骤
先查看 store 的信息及默认权重:
» store # 查看所有 store 信息
» store 5 # 这里指定查看 store 5 的具体信息,简化了部分信息
{
"store": {
"id": 5,
"version": "5.1.0"
},
"status": {
"leader_count": 252,
"leader_weight": 1, # Store 的 leader 权重参数
"leader_score": 252
"region_count": 252,
"region_weight": 1, # Store 的 Region 权重参数
"region_score": 39609.138540376065
}
}
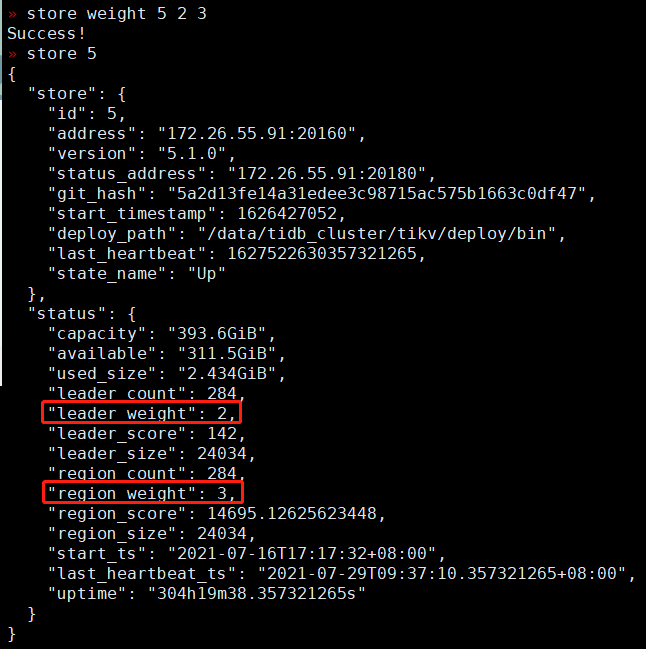
进行权重修改操作,设置 store id 为 5 的 store 的 leader weight 为 2,Region weight 为 3:
» store weight 5 2 3
如下图,可以看到 leader 和 region 的权重已更新:
store 分数差异巨大
如果不同 Store 的分数差异较大,可以进一步观察 Operator 的生成和执行情况,这时候可以分成两种情况:
1. Operator 有调度
1.1 问题排查
通过监看查看 Operator 的相关 Metrics,确认调度室正常的。
PD 面板 -> Operator -> Schedule operator check
Schedule operator check:已检查的 operator 的次数,主要检查是否当前步骤已经执行完成,如果是,则执行下一个步骤
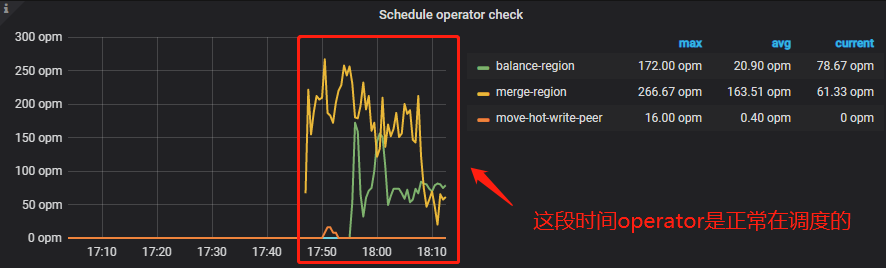
在调度正常的场景下,可能会出现调度速度慢的情况,可能存在以下情况:
1.2 调度速度受限于 limit 配置
PD 默认配置的 limit 比较保守,在不对正常业务造成显著影响的前提下,调大部分参数。
1.2.1 相关参数
-
leader-schedule-limit
- 同时进行 leader 调度的任务个数。
- 默认:4
-
region-schedule-limit
- 同时进行 Region 调度的任务个数
- 默认:2048
-
max-pending-peer-count
- 控制单个 store 的 pending peer 上限,调度受制于这个配置来防止在部分节点产生大量日志落后的 Region。
- 默认:16
-
max-snapshot-count
- 控制单个 store 最多同时接收或发送的 snapshot 数量,调度受制于这个配置来防止抢占正常业务的资源。
- 默认: 3
1.2.2 操作步骤
pd-ctl -i -u http://172.XXX.XXX.XXX:2379 # 进入 pd 命令界面
» config set leader-schedule-limit 8
» config set region-schedule-limit 4096
» config set max-pending-peer-count 32
» config set max-snapshot-count 5
加速调度还是要考虑到服务器的性能以及业务的繁忙程度!
1.3 调度任务相互竞争
系统中同时运行有其他的调度任务产生竞争,导致 balance 速度上不去。这种情况下如果 balance 调度的优先级更高,可以先停掉其他的调度或者限制其他调度的速度。
1.3.1 相关参数
-
leader-schedule-limit
- 同时进行 leader 调度的任务个数。
- 默认:4
-
disable-replace-offline-replica
- 关闭迁移 OfflineReplica 的特性的开关,当设置为 true 时,PD 不会迁移下线状态的副本。
- 默认:false
1.3.2 操作步骤
假设一个场景, Region 没均衡的情况下做下线节点操作,下线的调度与 Region Balance 会抢占 region-schedule-limit 配额,此时可以调小 leader-schedule-limit ,比如从 4 改成 2:
pd-ctl -i -u http://172.XXX.XXX.XXX:2379 # 进入 pd 命令界面
» config set leader-schedule-limit 2
或者打开禁止 PD 迁移下线状态的参数 disable-replace-offline-replica:
pd-ctl -i -u http://172.XXX.XXX.XXX:2379 # 进入 pd 命令界面
» config set disable-replace-offline-replica true
disable-replace-offline-replica 该参数已在 V5.0.0 版本中移除。
1.4 调度速度慢
如果遇到无理由的调度执行缓慢,这时候也可能是由于 TiKV 或者网络压力引起的:
1.4.1 相关监控
PD 面板 -> Operator -> Operator finish duration
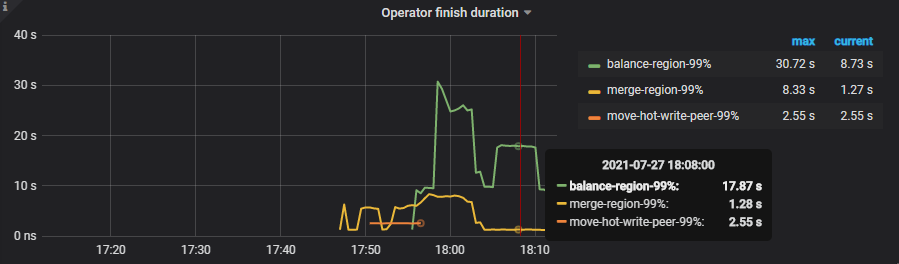
此时的 duration 的耗时比较高,与此同时观察下 TiKV 的状态:
Overview 面板 -> TiKV -> CPU
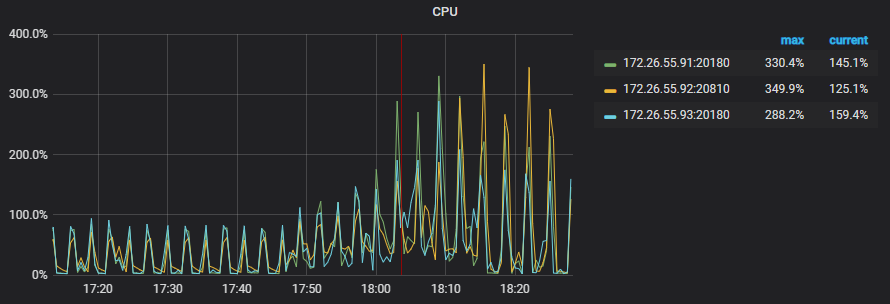
可以看到,CPU 基本被用满了,所以调度速度上不去。
2. Operator 未生成调度
没有生成调度可以分为以下三种情况:
2.1 调度器未启用
2.1.1 未启用调度策略
pd-ctl -i -u http://172.XXX.XXX.XXX:2379 # 进入 pd 命令界面
» scheduler show # 查看调度策略命令
[
"balance-hot-region-scheduler",
"label-scheduler"
]
这边并未启用调度器,我们可以手动添加 balance-region-scheduler 和 balance-leader-scheduler 这两个策略:
pd-ctl -i -u http://172.XXX.XXX.XXX:2379 # 进入 pd 命令界面
» scheduler add balance-region-scheduler # 增加 balance-region-scheduler 策略
Success!
» scheduler add balance-leader-scheduler # 增加 balance-leader-scheduler 策略
Success!

2.1.2 被部分参数限制
部分带有 limit 参数的配置如果被调成0,也有可能导致调度器不启用。
- leader-schedule-limit:同时进行 leader 调度的任务个数
- region-schedule-limit:同时进行 Region 调度的任务个数
- replica-schedule-limit:同时进行 replica 调度的任务个数
- merge-schedule-limit:同时进行的 Region Merge 调度的任务,设置为 0 则关闭 Region Merge
这些参数的值可以在 pd 命令行,通过类似 config show leader-schedule-limit 命令查看。
2.2 互斥策略
如果添加了 evict-leader-scheduler 策略,那么 PD 无法把 Leader 迁移至对应的 Store。
2.2.1 策略操作
pd-ctl -i -u http://172.XXX.XXX.XXX:2379 # 进入 pd 命令界面
» scheduler add evict-leader-scheduler 5 # 把 store 5上的所有 Region 的 leader 从 store 5 调度出去
» scheduler config evict-leader-scheduler # 查看该调度器具体在哪些 store 上
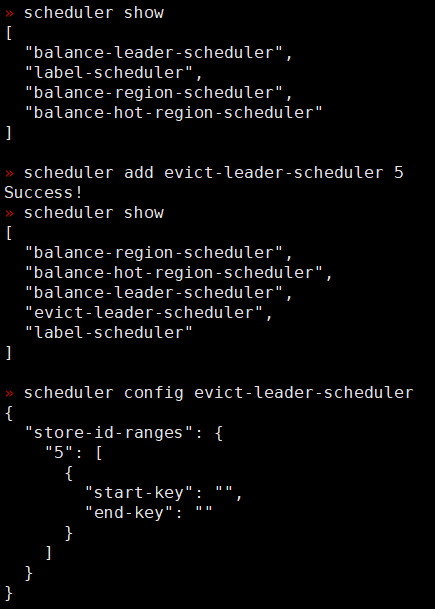
这里演示了下打开 evict-leader-scheduler 策略,如果需要均衡 leader 和 region 的分布,一般是需要关闭这个策略,使用以下命令:
» scheduler pause evict-leader-scheduler
» scheduler remove evict-leader-scheduler
2.3 集群拓扑限制
集群拓扑的限制导致无法均衡。比如 3 副本 3 数据中心的集群,由于副本隔离的限制,每个 Region 的 3 个副本都分别分布在不同的数据中心,假如这 3 个数据中心的 Store 数不一样,最后调度就会收敛在每个数据中心均衡,但是全局不均衡的状态。
四. 总结
上面只总结了几种常见的 region 分布不均的情况,如果实际应用中遇到了其他解决不了的状况,都可以发帖寻求社区成员和 CTC 的帮助。待问题解决后,再一起把问题描述、排查思路和实操步骤补充到这篇文档中,使更多遇到问题的小伙伴受益~