

数据库是每个公司的重中之重,它往往存储了公司的核心数据,一旦出现永久性损坏,对公司的打击会是灾难性的。分布式数据库虽然采用数据多副本备份机制来保证数据的可靠性,但同样也会面临多副本丢失的风险。灾难出现如何快速恢复也是DBA需要面对的问题,本案通过对具体示例的理解与操作介绍了分布式NEWSQL数据库Tidb对多副本丢失问题的处理。
一、TiDB 的整体架构:
TiDB 集群主要包括三个核心组件:TiDB Server,PD Server 和 TiKV Server。
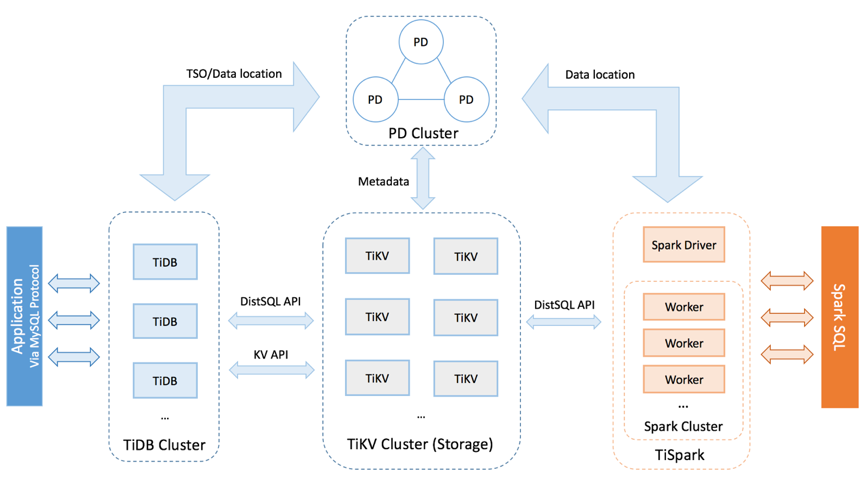
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个:一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 通过 Raft 协议保证数据的安全性。Raft 的 leader server 负责处理所有操作,其余的 PD server 仅用于保证高可用。
TiKV Server
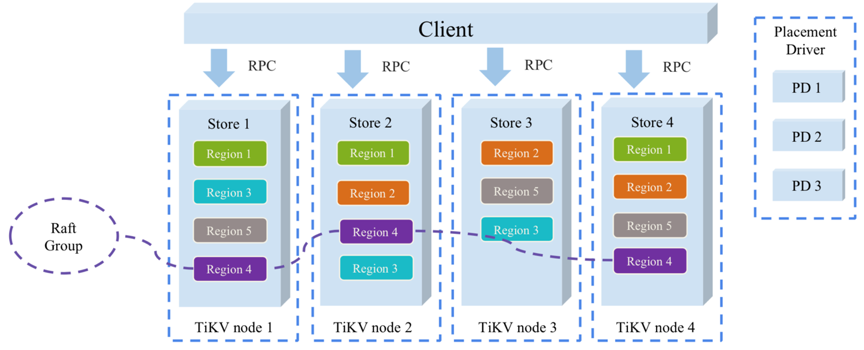
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
二、灾难恢复问题相关背景:
TiDB 默认配置为 3 副本,每一个 Region 都会在集群中保存 3 份,它们之间通过 Raft 协议来选举 Leader 并同步数据。Raft 协议可以保证在数量小于副本数(注意,不是节点数)一半的节点挂掉或者隔离的情况下,仍然能够提供服务,并且不丢失任何数据。图1中紫色部分为3副本的region。
对于 3 副本集群,挂掉一个节点除了可能会导致性能有抖动之外,可用性和正确性理论上不会受影响;
但是挂掉 2 个副本,一些 region 就会不可用,而且如果这 2 个副本无法完整地找回了,还存在永久丢失部分数据的可能。
在实际生产环境中,TiDB 集群是可能会出现丢失数据情况,如:
l 一个 TiDB 集群可能会出现多台 TiKV 机器短时间内接连故障且无法短期内恢复
l 一个双机房部署的 TiDB 集群的其中一个机房整体故障等
在上述这些情形下,会出现部分 Region 的多个副本(包含全部副本的情况)同时故障,进而导致 Region 的数据部分或全部丢失的问题。
这个时候,最重要的是快速地最大程度地恢复数据并恢复 TiDB 集群正常服务。
三、演练灾难恢复的部署架构:
本次演练采用较新的数据库软件版本v4.0.0-rc,主要关注Tikv中region的处理,此架构设计时将PD、TIDB、监控部署在一台机器之上,并未做冗余处理,Tikv选择5台机器,采用Tiup进行部署。下图为部署设计:

四、演练恢复前的相关信息及理解:
为更好的理解,我们将以拥有三百万条数据的t_user表作为操作的对象,在测试环境中模拟两副本以及三副本丢失的灾难场景,并进行对应的数据灾难恢复。
T_user表结构:
Create Table: CREATE TABLE t_user (
id int(11) NOT NULL,
c_user_id varchar(36) DEFAULT NULL,
c_name varchar(22) DEFAULT NULL,
c_province_id int(11) DEFAULT NULL,
c_city_id int(11) DEFAULT NULL,
create_time datetime DEFAULT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
查看t_user表在store的分布:

SHOW TABLE REGIONS 语句用于显示 TiDB 中某个表的 Region 信息。

从信息可以发现,t_user表有四个region,但是SQL命令未能详细列出region在不同的store上的分布,例如region的leader以及folloer如何在store进行分布,这里信息有助于我们更好理解region的分布。
通过pd-ctl工具可以找到更加详细的信息,
[root@tidb1 bin]# ./pd-ctl -i -u http://172.16.134.133:2379
» region 4009
{
“id”: 4009,
“start_key”: “7480000000000000FF4D5F728000000000FF224A9A0000000000FA”,
“end_key”: “”,
“epoch”: {
“conf_ver”: 23,
“version”: 36
},
“peers”: [
{
“id”: 4010,
“store_id”: 5
},
{
“id”: 4011,
“store_id”: 6
},
{
“id”: 4012,
“store_id”: 4
}
],
“leader”: {
“id”: 4010,
“store_id”: 5
},
“written_bytes”: 0,
“read_bytes”: 0,
“written_keys”: 0,
“read_keys”: 0,
“approximate_size”: 99,
“approximate_keys”: 773985
}
为更好的理解,根据以上的多个region信息我们可以绘制针对表t_user的数据region的分布图:
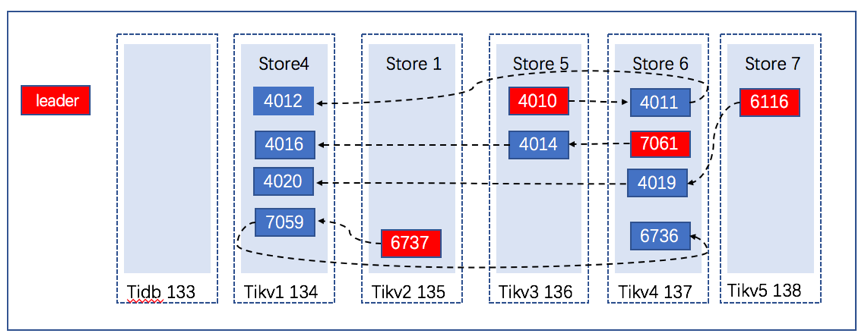
结合表t_user的region分布图,我们可以推论出如下的情况:
1、如果只宕掉一台机器:
由于是三副本集群,始终只有一个副本或者没有副本挂掉,tikv可用性和正确性理论上不会受影响。
2、如果同时宕掉两台机器:
三副本集群中,存在只有一个副本挂掉,也会存在两个副本同时挂掉的情况,当然只有一个副本挂掉,Tikv可用性和正确性理论上不会受影响。当有两个副本挂掉,Tikv集群将不可用。例如:在此例中,宕掉Tikv2 135和宕掉Tikb5 138这两台机器,只有两个region的一个副本挂掉,并不会影响到整个集群,但是如果是宕掉Tikv3 136和Tikv4 137,则会出现两个region的两个副本均挂掉,对此表的SQL无法查询,但由于还有一个副本的存在,通过复制幸存的副本进行复制并重新进行Leader的选举进行灾难恢复后数据任然能够被找回,当然可能挂掉的两个副本其中一个为Leader,部分数据未能从Leader同步到Follower则存在有少量未提交数据的丢失。
3、如果同时宕掉三台或更多机器:
理论上,一、二、三个副本挂掉的情况都有可能出现,然而会出现最为严重的情况,即为三副本的数据全部丢失,整个表的数据会因为某个region的丢失而出现数据库灾难恢复后表数据的丢失。例如如果是宕掉Tikv 1 134、Tikv2 135和Tikv3 136,会出现region的两副本挂掉的情况,通过灾难恢复可以找回,但是如果挂掉的是Tikv 1 134、Tikv3 136和Tikv4 137,将会有2个region的所有副本均丢失的情况,数据将出现丢失。
这里我们只是以一张表的region分布为例,实际环境中,表的region分布远比此复杂,在三副本设置的情况下,同时两台主机宕掉的情况下,出现两副本丢失的概率还是较大,当然实际生产中同时宕掉两台机器的情况较小,如果对容灾有更高要求,也可以选择五副本。
五、灾难场景副本丢失处理:
副本数据恢复包含两个部分:故障 Region 处理和丢失数据处理
故障 Region 处理,针对 Region 数据丢失的严重情况,可分为两种:
Region 至少还有 1 个副本,恢复思路是在 Region 的剩余副本上移除掉所有位于故障节点上的副本,这样可以用这些剩余副本来重新选举和补充副本来恢复,但这些剩余副本中可能不包含最新的 Raft Log 更新,这个时候就会丢失部分数据
Region 的所有副本都丢失了,这个 Region 的数据就丢失了,无法恢复。
可以通过创建 1 个空 Region 来解决 Region 不可用的问题
在恢复 Region 故障的过程中,要详细记录下所处理 Region 的信息,如 Region ID、Region 丢失副本的数量等
丢失数据处理
根据故障 Region ID 找到对应的表,找到相关用户并询问用户在故障前的某一段时间内(比如 5 min),大概写入了哪些数据表,是否有 DDL 操作,是否可以重新消费更上游的数据来再次写入,等等
如果可以重导,则是最简单的处理方式。否则的话,则只能对重要的数据表,检查数据索引的一致性 ,保证还在的数据是正确无误的
至此我们对Tidb副本的作用以及限制有也一定的了解,接下来我们会对region的两副本丢失和三副本丢失的场景进行演练。
同时宕掉两台机器
从表region的分布图可以看到,当宕掉tikv2 135、tikv5 138两台主机的情况下,整个集群并不会受到影响,因为只有一个region的副本分布在这两台机器之上,但这仅仅是当数据库的数据较小情况,当数据量增大PD调度将会对region的分布进行调度。对于挂掉一个副本的情况,在此不进行模拟。采用同时宕掉Tikv1 134和Tikv3 136这两台机器,会出现region的两个副本丢失:
先检查宕机前测试表的状况:
MySQL [sbtest2]> select count(*) from t_user;
±---------+
| count(*) |
±---------+
| 3000000 |
±---------+
1 row in set (6.98 sec)
同时宕掉Tikv 3 136和Tikv 4 137两台机器后测试表的情况:
MySQL [sbtest2]> select count(*) from t_user;
ERROR 9005 (HY000): Region is unavailable
正常的SQL语句出现region不可用的报错。
检查宕机的两台机器对应的store_id:
[root@tidb1 bin]# /root/tidb-v4.0.0-linux-amd64/bin/pd-ctl -i -u http://172.16.134.133:2379
» store
…
{
“store”: {
“id”: 5,
“address”: “172.16.134.136:20160”,
“labels”: [
{
“key”: “host”,
“value”: “tikv3”
}
],
“version”: “4.0.0-rc”,
“status_address”: “172.16.134.136:20180”,
“git_hash”: “f45d0c963df3ee4b1011caf5eb146cacd1fbbad8”,
“start_timestamp”: 1594632461,
“binary_path”: “/data1/tidb-deploy/tikv-20160/bin/tikv-server”,
“last_heartbeat”: 1594700897622993541,
“state_name”: “Disconnected”
},…
" {
“store”: {
“id”: 4,
“address”: “172.16.134.134:20160”,
“labels”: [
{
“key”: “host”,
“value”: “tikv1”
}
],
“version”: “4.0.0-rc”,
“status_address”: “172.16.134.134:20180”,
“git_hash”: “f45d0c963df3ee4b1011caf5eb146cacd1fbbad8”,
“start_timestamp”: 1594632462,
“binary_path”: “/data1/tidb-deploy/tikv-20160/bin/tikv-server”,
“last_heartbeat”: 1594700897744383603,
“state_name”: “Disconnected”
},
可以发现store ID 4和5 状态名为“Disconnected”,一段时间后状态会成为“DOWN”。
通过 pd-ctl config get 获取 region-schedule-limit、replica-schedule-limit、leader-schedule-limit、merge-schedule-limit
[root@tidb1 bin]# ./pd-ctl -i -u http://172.16.134.133:2379
» config show
{
“replication”: {
“enable-placement-rules”: “false”,
“location-labels”: “host”,
“max-replicas”: 3,
“strictly-match-label”: “false”
},
“schedule”: {
“enable-cross-table-merge”: “false”,
“enable-debug-metrics”: “false”,
“enable-location-replacement”: “true”,
“enable-make-up-replica”: “true”,
“enable-one-way-merge”: “false”,
“enable-remove-down-replica”: “true”,
“enable-remove-extra-replica”: “true”,
“enable-replace-offline-replica”: “true”,
“high-space-ratio”: 0.7,
“hot-region-cache-hits-threshold”: 3,
“hot-region-schedule-limit”: 4,
“leader-schedule-limit”: 4,
“leader-schedule-policy”: “count”,
“low-space-ratio”: 0.8,
“max-merge-region-keys”: 200000,
“max-merge-region-size”: 20,
“max-pending-peer-count”: 16,
“max-snapshot-count”: 3,
“max-store-down-time”: “30m0s”,
“merge-schedule-limit”: 8,
“patrol-region-interval”: “100ms”,
“region-schedule-limit”: 2048,
“replica-schedule-limit”: 64,
“scheduler-max-waiting-operator”: 5,
“split-merge-interval”: “1h0m0s”,
“store-balance-rate”: 15,
“store-limit-mode”: “manual”,
“tolerant-size-ratio”: 0
}
}
通过 pd-ctl config set 将这 4 个参数设为 0
» config set region-schedule-limit 0
Success!
» config set replica-schedule-limit 0
Success!
» config set leader-schedule-limit 0
Success!
» config set merge-schedule-limit 0
Success!
关闭调度主要为将恢复过程中可能的异常情况降到最少,需在故障处理期间禁用相关的调度。
使用 pd-ctl 检查大于等于一半副本数在故障节点上的 Region,并记录它们的 ID(故障节点为store id 4,5):
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total | map(if .==(4,5) then . else empty end) | length>=$total-length) }"
{“id”:3080,“peer_stores”:[4,6,5]}
{“id”:18,“peer_stores”:[4,5,6]}
{“id”:3084,“peer_stores”:[4,6,5]}
{“id”:75,“peer_stores”:[4,5,6]}
{“id”:34,“peer_stores”:[6,4,5]}
{“id”:4005,“peer_stores”:[4,6,5]}
{“id”:4009,“peer_stores”:[5,6,4]}
{“id”:83,“peer_stores”:[4,5,6]}
{“id”:3076,“peer_stores”:[4,5,6]}
{“id”:4013,“peer_stores”:[5,4,6]}
{“id”:10,“peer_stores”:[4,6,5]}
{“id”:26,“peer_stores”:[4,6,5]}
{“id”:59,“peer_stores”:[4,5,6]}
{“id”:3093,“peer_stores”:[4,5,6]}
我们可以看到表的两个region ID均在列表中,另外的两个region由于只丢失一个副本,并未出现在列表中。
在剩余正常的kv节点上执行停Tikv的操作:
[root@tidb1 bin]# tiup cluster stop tidb-test -R=tikv
Starting component cluster: /root/.tiup/components/cluster/v0.6.1/cluster stop tidb-test -R=tikv
+ [ Serial ] - SSHKeySet: privateKey=/root/.tiup/storage/cluster/clusters/tidb-test/ssh/id_rsa, publicKey=/root/.tiup/storage/cluster/clusters/tidb-test/ssh/id_rsa.pub
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.133
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.133
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.134
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.135
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.136
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.137
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.138
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.133
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.133
+ [Parallel] - UserSSH: user=tidb, host=172.16.134.133
+ [ Serial ] - ClusterOperate: operation=StopOperation, options={Roles:[tikv] Nodes:[] Force:false SSHTimeout:5 OptTimeout:60 APITimeout:300}
Stopping component tikv
Stopping instance 172.16.134.138
Stopping instance 172.16.134.134
Stopping instance 172.16.134.135
Stopping instance 172.16.134.136
Stopping instance 172.16.134.137
Stop tikv 172.16.134.135:20160 success
Stop tikv 172.16.134.138:20160 success
Stop tikv 172.16.134.137:20160 success
在所有健康的节点上执行(操作需要确保健康的节点关闭了Tikv):
[root@tidb3 bin]# ./tikv-ctl --db /data1/tidb-data/tikv-20160/db unsafe-recover remove-fail-stores -s 4,5 --all-regions
removing stores [4, 5] from configurations…
success
[root@tidb5 bin]# ./tikv-ctl --db /data1/tidb-data/tikv-20160/db unsafe-recover remove-fail-stores -s 4,5 --all-regions
removing stores [4, 5] from configurations…
success
[root@tidb6 bin]# ./tikv-ctl --db /data1/tidb-data/tikv-20160/db unsafe-recover remove-fail-stores -s 4,5 --all-regions
removing stores [4, 5] from configurations…
success
当然Region 比较少,则可以在给定 Region 的剩余副本上,移除掉所有位于故障节点上的 Peer,在这些 Region 的未发生掉电故障的机器上运行:
tikv-ctl --db /path/to/tikv-data/db unsafe-recover remove-fail-stores -s <s1,s2> -r <r1,r2,r3>,对于region较多的情况,此操作则较为繁琐。
停止PD节点:
[root@tidb1 ~]# tiup cluster stop tidb-test -R=pd
Starting component cluster: /root/.tiup/component
重启启动PD tikv节点:
[root@tidb1 ~]# tiup cluster start tidb-test -R=pd,tikv
这里需要启动PD才能连接到数据库。
检查没有处于leader状态的region(要保持没有):
[root@tidb1 ~]# pd-ctl -i -u http://172.16.134.133:2379
» region --jq ‘.regions[]|select(has(“leader”)|not)|{id: .id,peer_stores: [.peers[].store_id]}’
»
这里没有发现没有leader状态的region。
重新修改参数:
[root@tidb1 ~]# pd-ctl -i -u http://172.16.134.133:2379
» config set region-schedule-limit 2048
Success!
» config set replica-schedule-limit 64
Success!
» config set leader-schedule-limit 4
Success!
» config set merge-schedule-limit 8
Success!
检查查询数据是否正常
MySQL [sbtest2]> select count(*) from t_user;
±---------+
| count(*) |
±---------+
| 3000000 |
±---------+
1 row in set (9.95 sec)
至此恢复操作结束。
我们再看看region的分布:

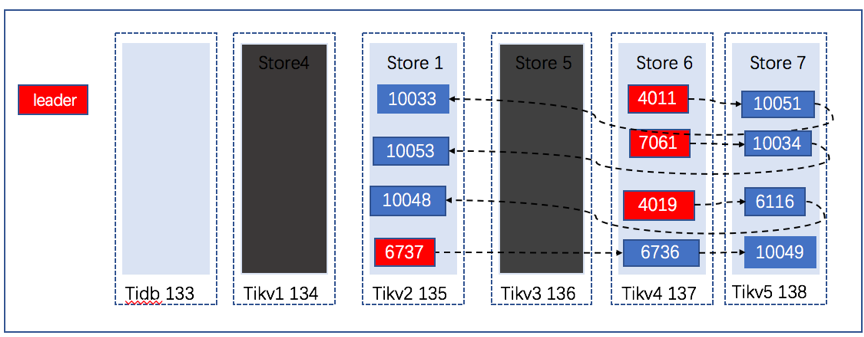
Region的副本进行了新的复制和分布。
同时宕掉三台机器 :
便于理解,先看表t_user新的region分布:


我们这次选择宕掉Tikv2 135、Tikv3 136和Tikv4 137,从分布图可以判断有两region会丢失三副本,一个region丢失两个副本,最后一个region丢失一个副本的情况。
同样的先检查宕机前测试表的状况:
MySQL [sbtest2]> select count(*) from t_user;
±---------+
| count(*) |
±---------+
| 3000000 |
±---------+
1 row in set (1.88 sec)
同时宕掉Tikv2 135、Tikv3 136和Tikv4 137两台机器后测试表的情况:
MySQL [sbtest2]> select count(*) from t_user;
ERROR 9005 (HY000): Region is unavailable
集群状态:

检查宕机的两台机器对应的store_id:
[root@tidb1 bin]# /root/tidb-v4.0.0-linux-amd64/bin/pd-ctl -i -u http://172.16.134.133:2379
» store
这里是1,5,6
通过 pd-ctl config get 获取 region-schedule-limit、replica-schedule-limit、leader-schedule-limit、merge-schedule-limit并通过 pd-ctl config set 将这 4 个参数设为 0
使用 pd-ctl 检查大于等于一半副本数在故障节点上的 Region,并记录它们的 ID(故障节点为store id 1,5,6):
» region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total | map(if .==(1,5,6) then . else empty end) | length>=$total-length) }"
{“id”:3089,“peer_stores”:[5,4,6]}
{“id”:47,“peer_stores”:[4,5,6]}
{“id”:75,“peer_stores”:[4,5,6]}
{“id”:30,“peer_stores”:[6,4,5]}
{“id”:135,“peer_stores”:[6,4,5]}
{“id”:4017,“peer_stores”:[6,7,5]}
{“id”:67,“peer_stores”:[4,5,1]}
{“id”:2289,“peer_stores”:[4,6,5]}
{“id”:18,“peer_stores”:[6,4,5]}
{“id”:39,“peer_stores”:[6,4,5]}
{“id”:51,“peer_stores”:[4,6,5]}
{“id”:10,“peer_stores”:[4,5,6]}
{“id”:14,“peer_stores”:[6,5,4]}
{“id”:83,“peer_stores”:[6,4,5]}
{“id”:59,“peer_stores”:[6,4,5]}
{“id”:6768,“peer_stores”:[1,6,4]}
{“id”:22,“peer_stores”:[4,5,6]}
{“id”:26,“peer_stores”:[6,4,5]}
{“id”:43,“peer_stores”:[6,4,5]}
{“id”:131,“peer_stores”:[6,4,5]}
{“id”:4009,“peer_stores”:[6,1,5]}
{“id”:2,“peer_stores”:[7,6,5]}
{“id”:63,“peer_stores”:[4,5,1]}
{“id”:87,“peer_stores”:[6,4,5]}
{“id”:6734,“peer_stores”:[6,1,5]}
{“id”:3080,“peer_stores”:[6,4,5]}
{“id”:3084,“peer_stores”:[6,4,5]}
{“id”:3076,“peer_stores”:[6,4,5]}
{“id”:34,“peer_stores”:[6,4,5]}
{“id”:127,“peer_stores”:[6,4,5]}
{“id”:3070,“peer_stores”:[6,4,5]}
我们可以看到表的三个region ID均在列表中,另外的一个region由于只丢失一个副本,并未出现在列表中。
在剩余正常的kv节点上执行停Tikv的操作:
[root@tidb1 bin]# tiup cluster stop tidb-test -R=tikv
在所有健康的节点上执行(操作需要确保健康的节点关闭了Tikv):
[root@tidb2 bin]# ./tikv-ctl --db /data1/tidb-data/tikv-20160/db unsafe-recover remove-fail-stores -s 1,5,6 --all-regions
removing stores [1, 5, 6] from configurations…
success
[root@tidb6 bin]# ./tikv-ctl --db /data1/tidb-data/tikv-20160/db unsafe-recover remove-fail-stores -s 1,5,6 --all-regions
removing stores [1, 5, 6] from configurations…
success
停止PD节点:
[root@tidb1 ~]# tiup cluster stop tidb-test -R=pd
Starting component cluster : /root/.tiup/component
重启启动PD tikv节点:
[root@tidb1 ~]# tiup cluster start tidb-test -R=pd,tikv
检查没有处于leader状态的region(要保持没有):
[root@tidb1 ~]# pd-ctl -i -u http://172.16.134.133:2379
» region --jq ‘.regions[]|select(has(“leader”)|not)|{id: .id,peer_stores: [.peers[].store_id]}’
{“id”:4009,“peer_stores”:[6,1,5]}
{“id”:6734,“peer_stores”:[6,1,5]}
»
这里没有发现任然有两个region处于没有leader的状态。另外丢失两副本的一个region以及通过unsafe-recover的方式进行了复制。
尝试访问表t_user
MySQL [sbtest2]> select count(*) from t_user;
ERROR 9002 (HY000): TiKV server timeout
或者
MySQL [sbtest2]> select count(*) from t_user;
ERROR 9005 (HY000): Region is unavailable
两次执行的结果有所不一样。
根据region ID,确认region属于哪张表,以备后续同步数据需要。
[root@tidb1 ~]# curl http://172.16.134.133:10080/regions/4009
{
“region_id”: 4009,
“start_key”: “dIAAAAAAAABN”,
“end_key”: “dIAAAAAAAABNX3KAAAAAAAt8fw==”,
“frames”: [
{
“db_name”: “sbtest2”,
“table_name”: “t_user”,
“table_id”: 77,
“is_record”: true,
“record_id”: 752767
}
]
两个region ID均属于同一张表。
创建空 Region 解决 Unavailable 报错。任选一个 Store,关闭上面的 TiKV,然后执行:
[root@tidb2 bin]# ./tikv-ctl --db /data1/tidb-data/tikv-20160/db recreate-region -p ‘172.16.134.133:2379’ -r 4009
initing empty region 17001 with peer_id 17002…
success
[root@tidb2 bin]# ./tikv-ctl --db /data1/tidb-data/tikv-20160/db recreate-region -p ‘172.16.134.133:2379’ -r 6734
initing empty region 17003 with peer_id 17004…
success
如果不关闭tikv会报错:
[root@tidb2 bin]# ./tikv-ctl --db /data1/tidb-data/tikv-20160/db recreate-region -p ‘172.16.134.133:2379’ -r 4009
thread ‘main’ panicked at ‘called Result::unwrap() on an Err value: RocksDb(“IO error: While lock file: /data1/tidb-data/tikv-20160/db/LOCK: Resource temporarily unavailable”)’, src/libcore/result.rs:1188:5
note: run with RUST_BACKTRACE=1 environment variable to display a backtrace.
停止PD节点:
[root@tidb1 ~]# tiup cluster stop tidb-test -R=pd
Starting component cluster : /root/.tiup/component
重启启动PD tikv节点:
[root@tidb1 ~]# tiup cluster start tidb-test -R=pd,tikv
检查没有处于leader状态的region(要保持没有):
[root@tidb1 ~]# pd-ctl -i -u http://172.16.134.133:2379
» region --jq ‘.regions[]|select(has(“leader”)|not)|{id: .id,peer_stores: [.peers[].store_id]}’
»
重新修改PD的参数并尝试访问表t_user
MySQL [sbtest2]> select count(*) from t_user;
±---------+
| count(*)
±---------+
| 1494555 |
±---------+
1 row in set (1.92 sec)
由于丢失掉两个region的所有副本,所以我们查询出的数据量减少,至此恢复测试结束。
我们再看看region的分布情况:

发现原来三副本丢失的region ID发生了改变。
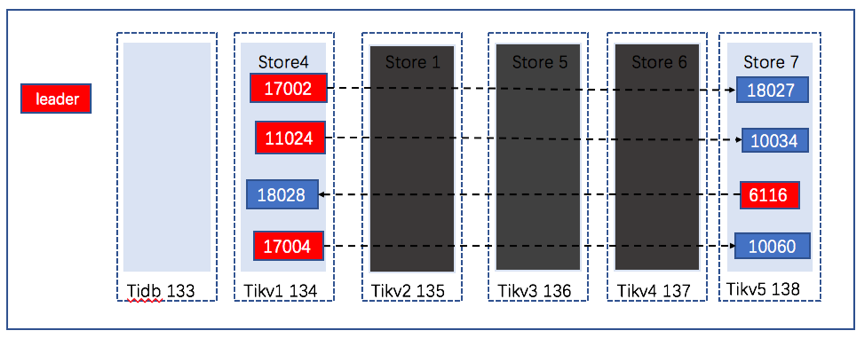
可以看到表t_user的所有region只有两副本。
总结
TiDB集群中数据存储Tikv如果宕了一台机器,那么并不影响集群的运行,数据库自身会进行处理,PD 会将其上的数据region迁移到其他的 TiKV 节点上。但如果同时宕机两台,甚至3台及以上灾难情况,相信通过上文的介绍理解和相关命令的查询以及修复,能迅速进行对应的恢复操作。
参考文档https://book.tidb.io/session3/chapter5/recover-quorum.html
微信公众号 IT那活儿 https://mp.weixin.qq.com/s/LXFCBVnBwX1ljHDSL2BlQw