

作者介绍: 林佳,网易互娱计费数据中心实时业务负责人,实时开发框架 JFlink-SDK 和实时业务平台 JFlink 的主程,Flink Code Contributor。
本文由网易互娱计费数据中心实时业务负责人林佳老师分享,主要介绍网易数据中心在处理实时业务时为什么选择 Flink 和 TiDB,以及两者的结合应用情况。视频回顾点这里。
今天主要从开发的角度来跟大家聊一聊为什么网易数据中心在处理实时业务时,选择 Flink 和 TiDB。
首先,TiDB 是一个混合型的 HTAP 分布式数据库,具备一键水平伸缩、强一致性的多副本数据安全、分布式事务、实时 OLAP 等重要特性,同时兼容 MySQL 协议和生态,迁移便捷,运维成本极低。而 Flink 是目前最热门的开源计算框架,在处理实时数据方面,其高吞吐量、低延迟的优异性能以及对 Exactly Once 语义的保障为网易游戏实时业务处理提供了便捷支持。
Flink on TiDB 究竟可以创造怎样的业务价值?本文将从一个实时累加值的故事来跟大家分享。
一、从一个实时累加值的故事说起

接触过线上业务的同学应该对上述数据非常熟悉,这是一张经典的线上实时业务表,也可以理解为日志或某种单调递增的数据,包含了事实发生的时间戳、账户、购买物品、购买数量等。
针对这类数据的分析,假设使用 Flink 等实时计算框架,可以通过分桶处理,如 groupby 用户 ID,groupby 道具,再对时间进行分桶,最终将产生如下的持续数据。
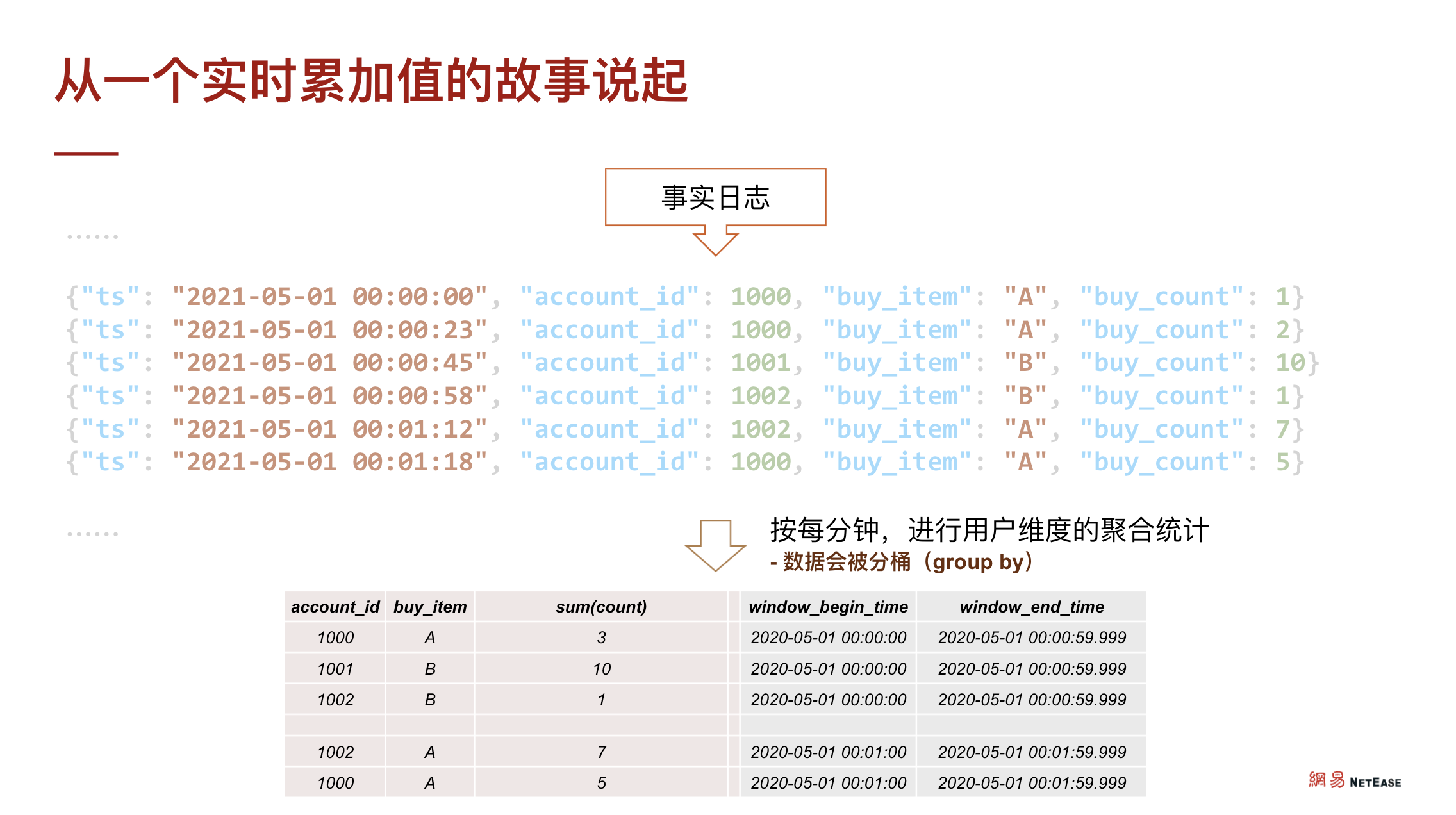
如果将上述持续数据落入 TiDB,与此同时 TiDB 仍保持已有的线上维度表,如账户信息、道具信息等,通过对表做一个 JOIN 操作就能快速从事实的统计数据中分析出时序数据所代表的价值,再对接到可视化应用,能发现很多不一样的东西。

整个过程看起来非常简单又完美, Flink 解决计算问题,TiDB 解决海量存储问题。但,事实真的如此吗?
实际接触线上数据的同学可能会遇到类似的问题,如:
- 多种数据源:各个业务方的外部系统日志,并且存在有的数据存储在数据库,有的需要以日志的方式调用,还有以 rest 接口调用的方式
- 数据格式多样:各个业务或渠道打的数据格式完全不同,有的是 JSON,有的是 Encoded URL
- 乱序到达:数据到达顺序被打乱

基于上述问题,我们引入了 Flink 。在数据中心内部,我们封装了一套称之为 JFlink - SDK 的框架,主要基于 Flink 对 ETL 、乱序处理、分组聚合以及一些常用需求进行模块化、配置化,然后通过线上数据源的配置,计算得到一些事实的统计或事实数据,最后入到可以容纳海量数据的 TiDB 中。

但是, Flink 在处理这批数据时,为了故障恢复,会通过 CheckPoint 保存数据当前的计算状态。如果在两次保存期间,发生了数据计算的 commit,即这部分计算结果已经刷出 TiDB 了,然后发生了故障,那么 Flink 会自动回退到上一个 CheckPoint 的位置,即回退到上一次正确的状态。此时,如图的 4 笔数据就会被重算,重算之后可能会被更新到 TiDB 中。
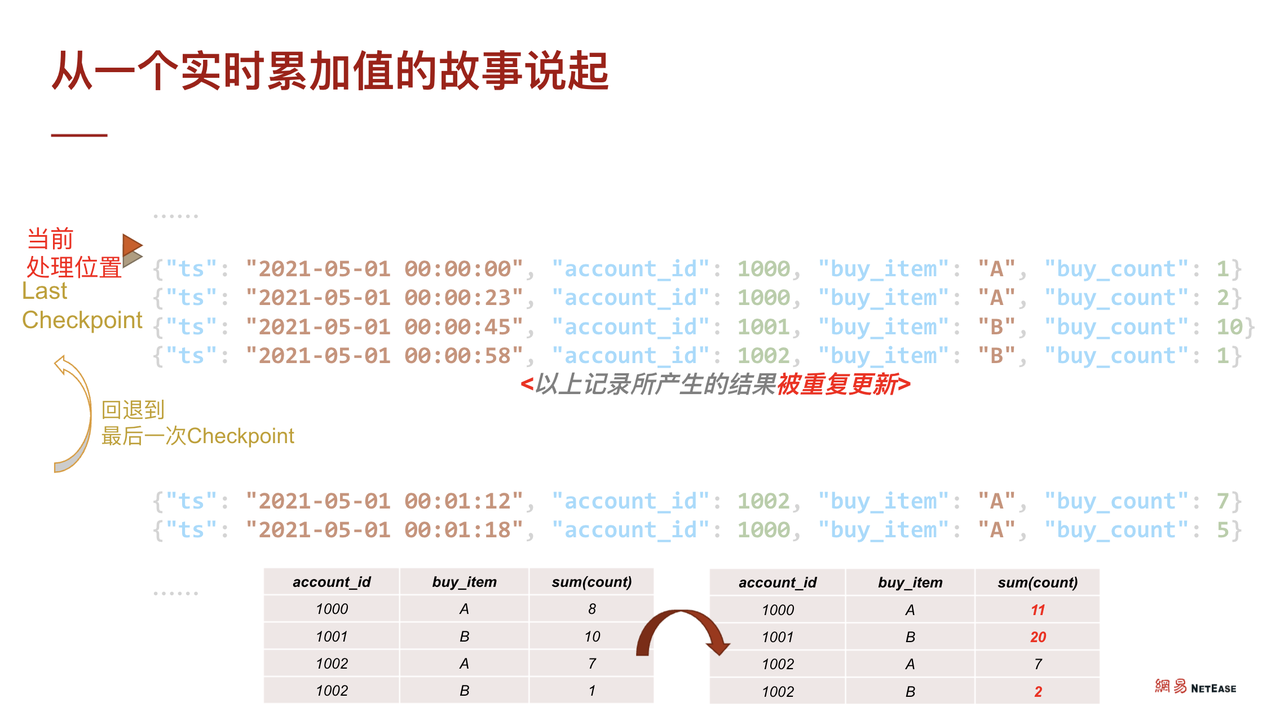
如果数据是个累加值的话,可以看到其累加值被错误地累加了两遍,这是使用 Flink on TiDB 可能出现的问题之一。
二、Flink 的准确保证
1、Flink 的准确保证
Flink 如何提供准确性保证?首先,需要了解 Flink 的 CheckPoint 机制。CheckPoint 类似于 MySQL 的事务保存点,指在做实时数据处理时,对临时状态的保存。
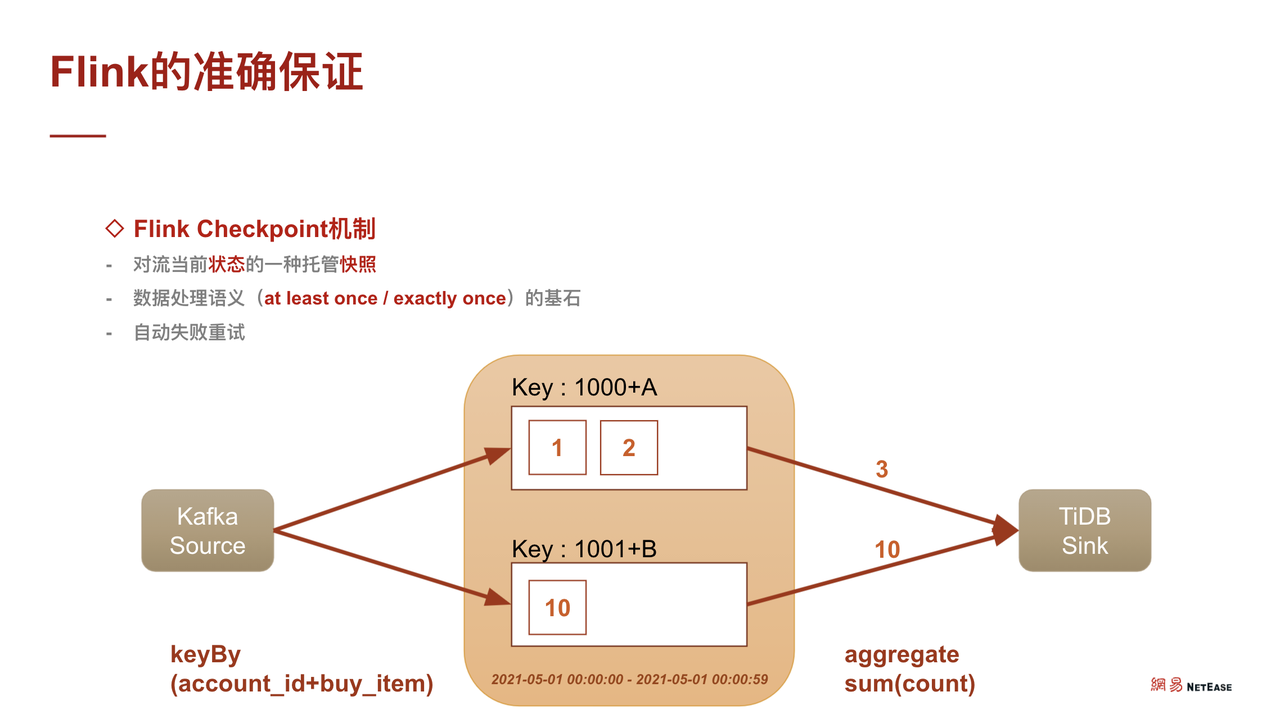
CheckPoint 分为 At least Once 和 Exactly Once,但即使选择使用 Exactly Once 也无法解决上面累加值重复计算的问题。比如从 Kafka 读了数据,以上述事实表为基础 account 是 1000、购买物品为 a 、购买数量分别为 1 件和 2 件,此时 Flink 处理数据就会被分到分桶里。与此同时,另一种 Key 会被 Keyby,相当于 MySQL 的 groupby 分到另一个桶里去计算,然后通过聚合函数刷到 TiDB Sink 中。
2、计算状态的保存
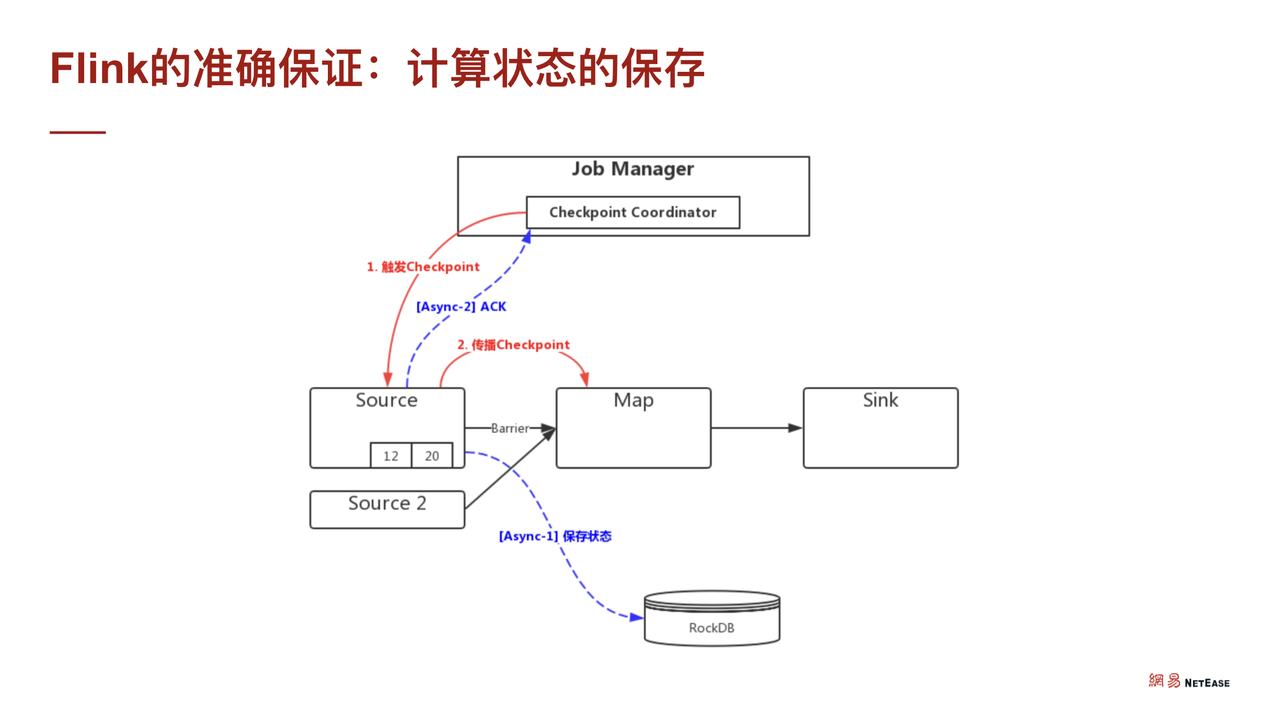
Flink 通过 CheckPoint 机制来保证数据的 Exactly Once。假设需要进行一个比较简单的执行计划 DAG,只有一个 source,然后通过 MAP 刷 TiDB sink。在这个过程中,Flink 是线性的,通过在数据流里面插入 CheckPoint barrier 机制来完成,相当于 CheckPoint barrier 走到哪里,哪里就触发线性执行计划中的算子保存点。
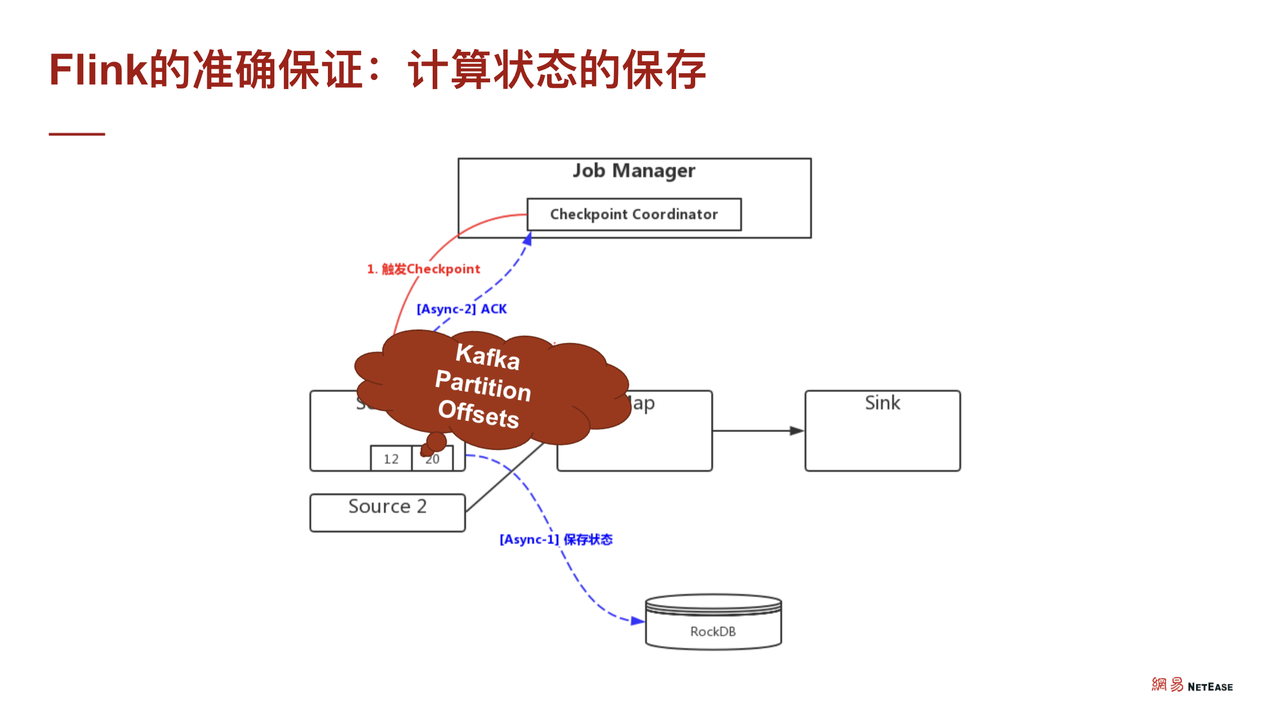
假设从 source 开始,那么会保存 source,如果是 Kafka,需要存一下 Kafka 的当前消费位置。在节点保存完毕之后,需要做下一个算子的状态保存,此处的 MAP 假设是分桶计算,那么它其实就已经存了桶里的累积数据。
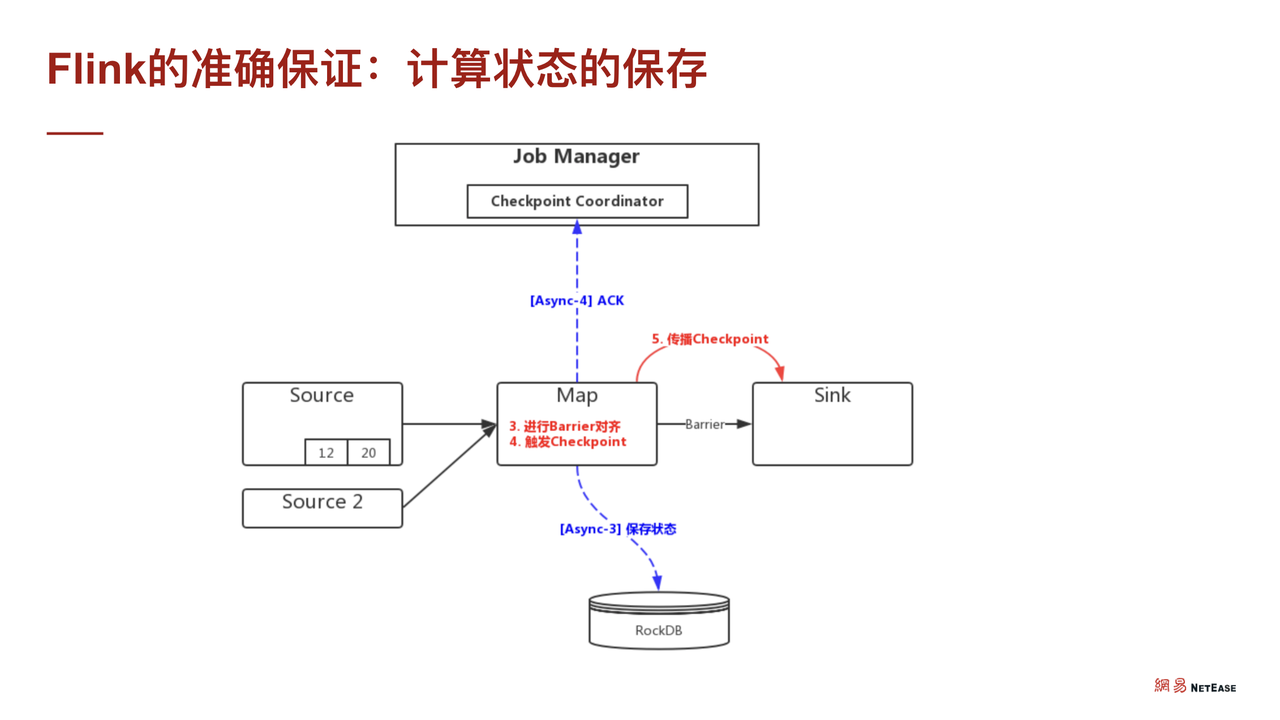
在此之后,CheckPoint barrier 就到达了sink,此时 sink 也去做相应的状态储存。当相应的状态存储分别做完之后,总的 Job Manager (相当于 Master) 汇报状态存储的 CheckPoint 已经完成了。

而当 Master 确认了所有的子任务都已经完成了分布式任务的 CheckPoint 之后,会分发一个 Complete 的信息。如上图模型所示,可以联想到它其实就是 2PC,分布式二阶段提交协议,每个分布式子任务分别提交自己的事务,然后再整体提交整个事务。被存下来的状态将存储在 RocksDB 中,当出现故障时,可以从 RocksDB 恢复数据,然后从断点重新计算整个流程。
3、Exactly Once 语义支持
回看 Exactly Once,上述方式真的能实现 Exactly Once 吗?其实不能,但为何 Flink 官方称这是 Exactly Once 呢?以下将详述其中缘由。
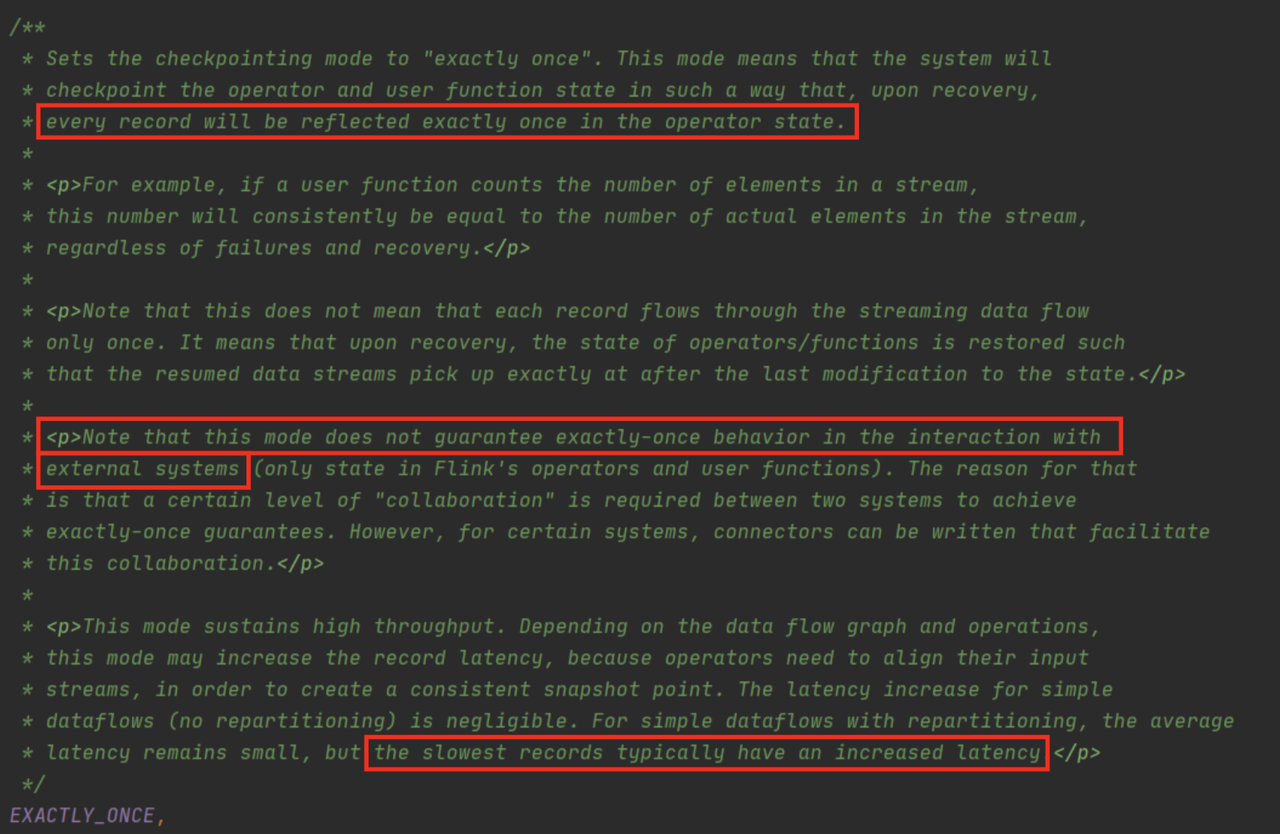
从上图的代码可以看出,Exactly Once CheckPoint 是无法保证端到端的,只能保证 Flink 内部算子的Exactly Once。因此,将计算数据去写入 TiDB 时,如果 TiDB 无法与 Flink 联动,就无法保证端到端的Exactly Once 了。
类比一下什么是端到端,其实 Kafka 就支持这种语义,因为 Kafka 对外暴露了 2PC 的接口,允许用户手动调整接口来控制 Kafka 事务的 2PC 过程,也因此可以利用 CheckPoint 机制来避免算错的情况。
但如果不能手动控制,那会怎么样呢?
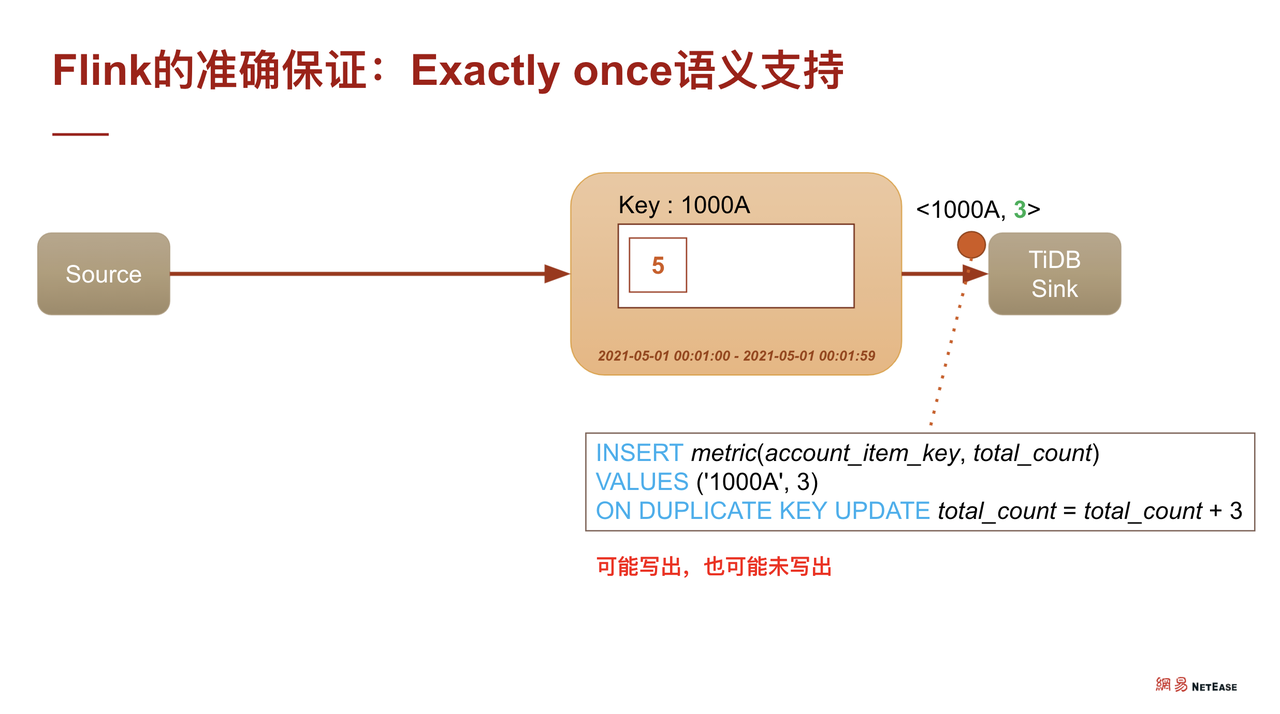
我们来看看如下实例,假设仍然将用户设置为 1000,购买道具为 A 的数据写入到 TiDB 的累加表,会生成如下 SQL:INSERT VALUES ON DUPLICATE UPDATE。当 CheckPoint 发生时,能否保证该语句被执行到 TiDB?
如果不加特殊处理,简单执行这条 SQL 的话,其实不能保证这条 SQL 究竟有没有被执行,如未执行,则会报错,退回到上一个 CheckPoint,皆大欢喜。因为它实际上没有计算,没有累加,也不会重复计算一遍,所以是对的。但如果已经写出,再去重复的退回上一个 CheckPoint,那么将会出现重复累加 3 的情况。

Flink 为了解决这个问题,提供了一种接口,可以手动实现 SinkFunction,控制事务的开始,Pre Commit、Commit、Rollback。
而 CheckPoint 机制本质是一种 2PC,当分布式算子在执行内部事务时,其实算子关联到 Pre Commit。同理,假设在 Kafka 中,可以通过 Pre Commit 事务将 Kafka 事务预提交。当算子收到 Job Manager(即 Master)同步的所有算子 CheckPoint 的状态保存都已完成时,此时 Commit,事务是必定成功的。
如果其他算子失败了,则需要进行 Rollback,确保事务没有被成功地提交到远端。这里如果有 2PC SinkFunction 加上 XA 全 section 语义的话,其实就可以做到严格意义的 Exactly Once。
但不是所有的 sink 都支持二阶段提交协议,比如 TiDB 内部是二阶段提交来管理协调其事务,但是目前来说,并没有把二阶段提交协议提供给用户手动控制。
4、幂等计算

那么,如何做到保证业务的 Exactly Once 结果落到 TiDB?其实也很简单,采用 At Least Once 语义加上一个 Unique Key,即幂等计算。
如何选择 Unique Key?如果一份数据有一个唯一标志,我们自然会选择其唯一标志。比如一份数据有唯一 ID,当一张表通过 Flink 同步到另一张表的时候,这就是很经典的利用其 Primary key 做 insert ignore 或者 replace into 的语义去重。如果是日志,可以选择日志文件特有的属性。而如果通过 Flink 去计算聚合结果,则可以用聚合的 Key 加上窗口边界值,或者其他的幂等方式来计算出数值,作为最终计算的唯一键。
如此,就可以实现结果是可重入的。既然可重入,再加上 CheckPoint 的可回退特性,就可以把 Flink 跟 TiDB 结合起来,做到精准的 Exactly Once 结果写入。
三、Flink on TiDB
在 Flink on TiDB 部分,我们内部的 JFlink 框架对 Flink 进行封装,然后在与 TiDB 联动上又做了什么?以下将详述。
1、数据连接器的设计

首先,是数据连接器的设计。因为 Flink 对于 TiDB 的支持或者说对关系型数据库的支持都比较慢,Flink Conector JDBC 在 Flink 1.11 版本才出现,时间还不太长。
目前,我们将 TiDB 作为数据源,把数据放在 Flink 处理,主要是通过 TiDB 官方提供的 CDC 工具,相当于通过监听 TiDB 的变更,将数据落到 Kafka。而 Kafka 又是非常经典的流式数据管道,所以通过 Kafka 将数据进行消费处理,然后再通过 Flink 进行处理。
但不是所有业务都可以用 CDC 模式,比如落数据时要增加一些比较复杂的过滤条件,或者落数据时需要定期读取某些配置表,亦或者先需要了解外部的一些配置项才能知道切分情况时,可能就需要手动的自定义 source。
而 JFlink 在封装时,其实是封装了业务字段的单调表来进行切片读取。单调是指某张表一定会有某个字段,单调变化的,或者是 append only。
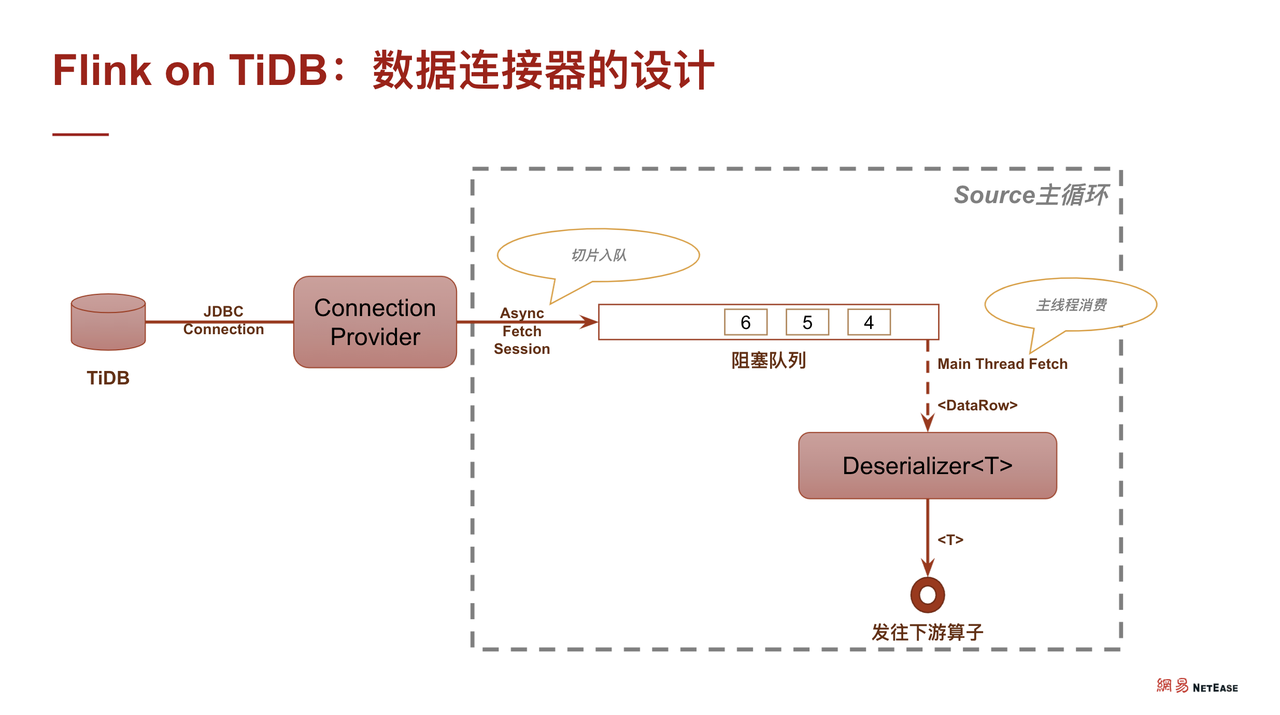
在实现上,TiDB 和 Flink 之间,封装了 JFlink TiDB Connect,通过一个连接词去创建跟 TiDB 的链接。然后通过异步线程来捞数据,再通过阻塞队列进行阻塞。阻塞队列的作用主要是为了流控。
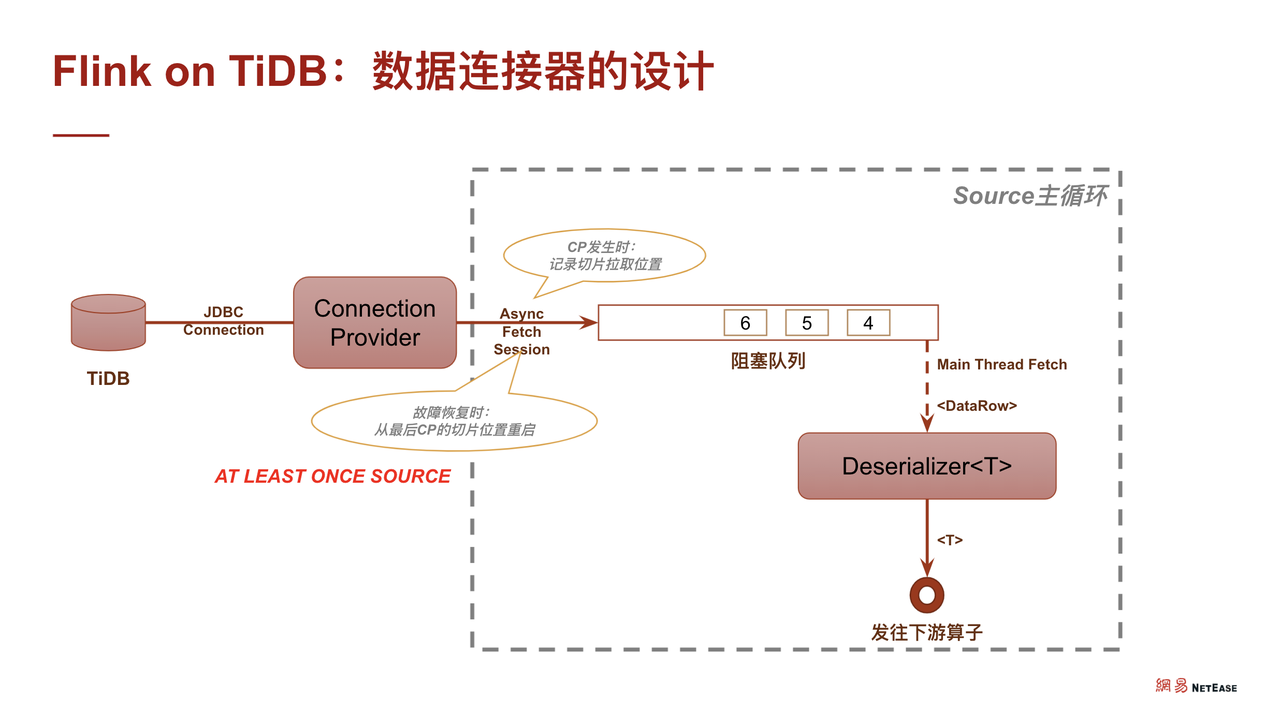
对于 Flink 的主线程,主要通过监听阻塞队列上的有非空信号。当收到非空信号时,就把数据拉出来,通过反序列化器作为整个实时处理框架的流转对象,然后可以对接后面各种模块化了的 UDF。在实现 source 的 At Least Once 语义时,如果借助 Flink 的 CheckPoint 机制,就变得非常简单了。
因为我们已经有个大前提,即这张表是一张由某个字段组成的单调表,在单调表上进行数据切分时,就可以记下当前的切分位置。如果发生故障,让整条流回退到上一个CheckPoint,source 也会回退到上一个保存的切片位置,此时就能够保证不漏数据的消费,即实现了 source 的 At Least Once。

对于 sink,其实 Flink 官方是提供了 JDBC sink,当然 source 也提供了JDBC sink,但是 Flink 官方提供的 JDBC sink 实现比较朴素,使用同步批量插入的语义。
其实同步批量插入是比较保守的,当数据量比较大时,且没有严格的先来先提交的语义,此时使用同步提交相对来说性能不是很高,如果使用异步提交的话,性能就会提升很多,相当于充分利用了 TiDB 分布式数据库的特性,支持小事务高并发,有助于提升 QPS。
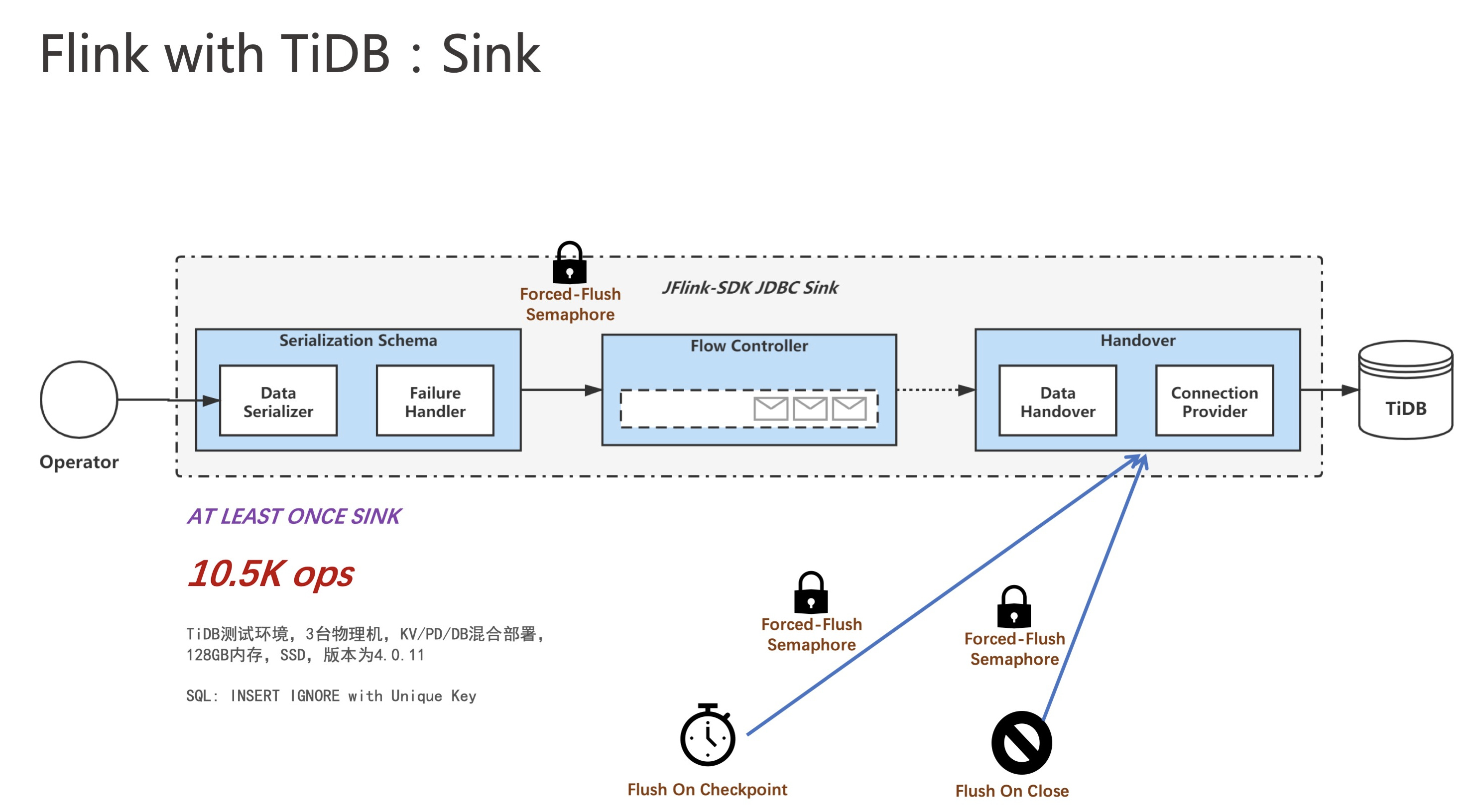
当我们实现 sink 时,实际上原理也非常简单。我们这里先讲讲 Flink 官方是怎么实现。Flink 官方是通过将 Flink 的主线程写到一张 buffer 中,当 buffer 写满时进行换页,同时拉起一条线程将数据同步到 TiDB。
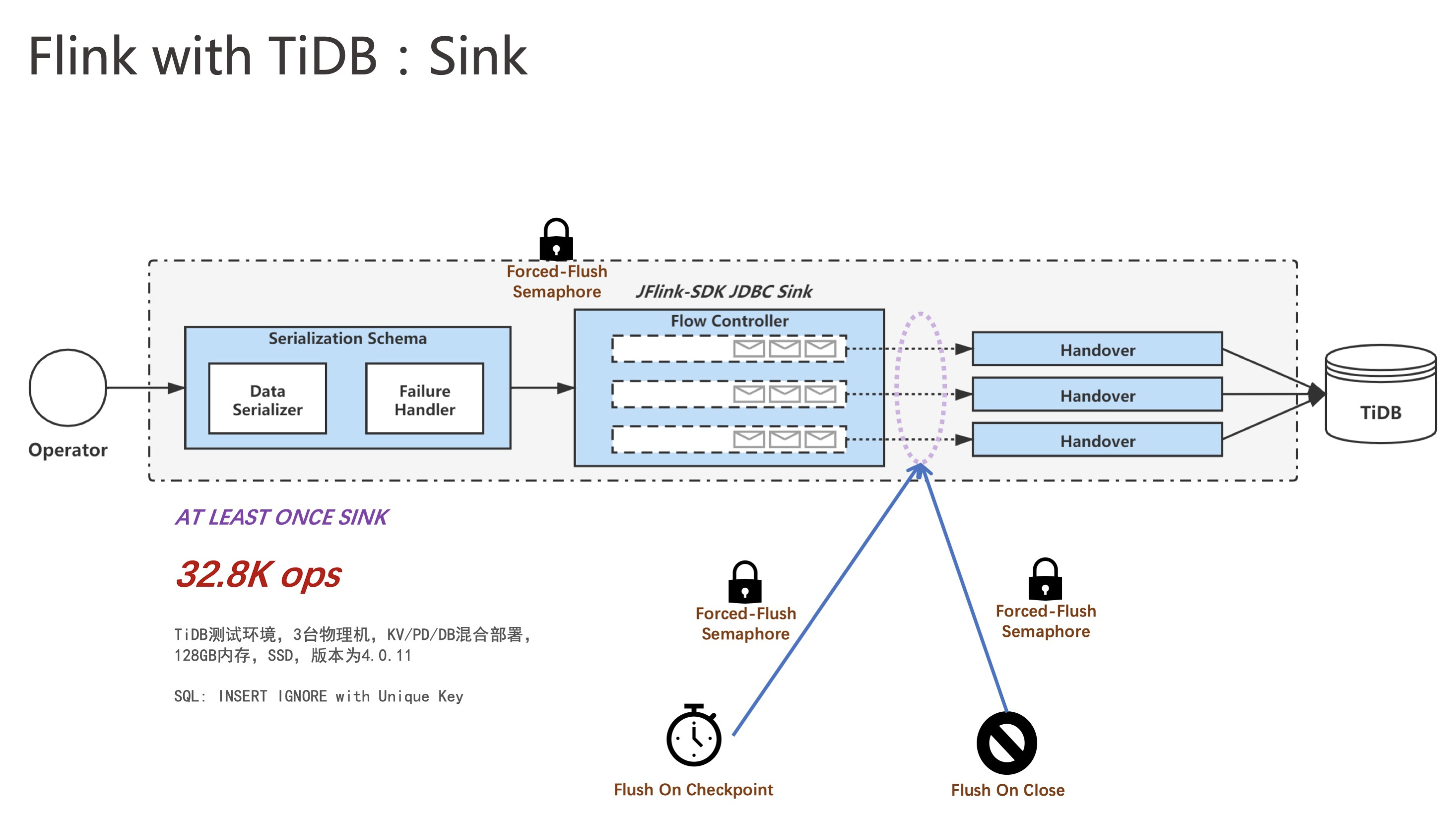
而我们的改进是通过一个阻塞队列来进行流控,然后把数据写到某个 buffer 页,当 buffer 页写满时,马上拉起一条异步线程去刷出,这样就可以保证在非 FIFO 语义下提升 QPS 的性能。实践证明,通过这种方式,我们可以把官方写出的 QPS 从大概 1 万多提升到 3 万以上。
不过在实现 sink 的 At Least Once 语义的时候就相对来说复杂一点。回想 CheckPoint 机制,如果我们要实现 sink 的 At Least Once,就必须保证 CheckPoint 完成时,sink 是干净的,即所有数据都刷出了,这样才能保证其 At Least Once。在这种情况下,可能就需要将 CheckPoint 的线程、普通刷出的主线程以及其他的换页线程等都加上。当触发 CheckPoint 的时候,同步把所有数据都保证刷干净之后,才去完成 CheckPoint。如此,一旦 CheckPoint 完成,sink 必然是干净的,也意味着前面流过来的所有数据都正确更新到 TiDB 了。
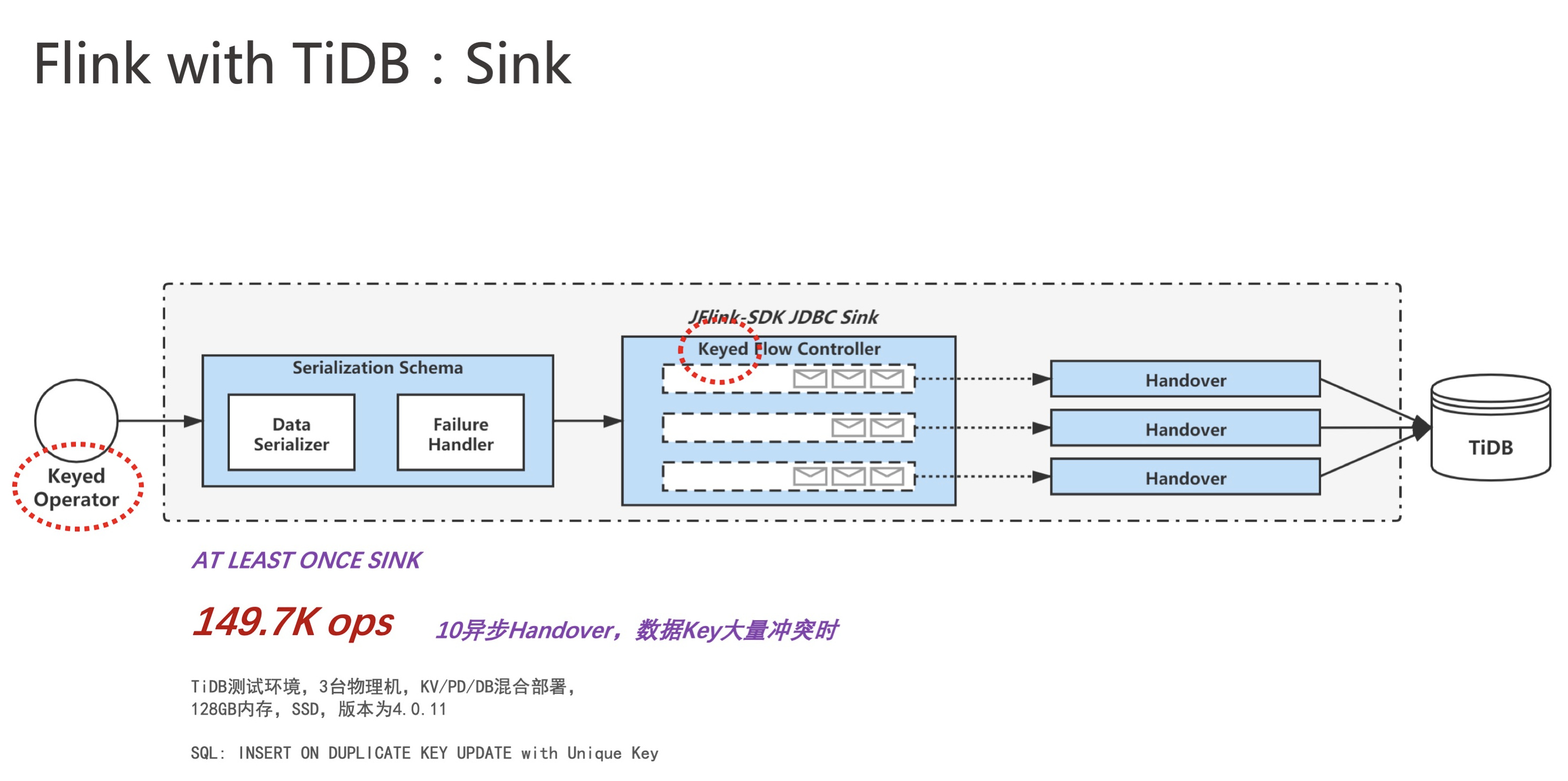
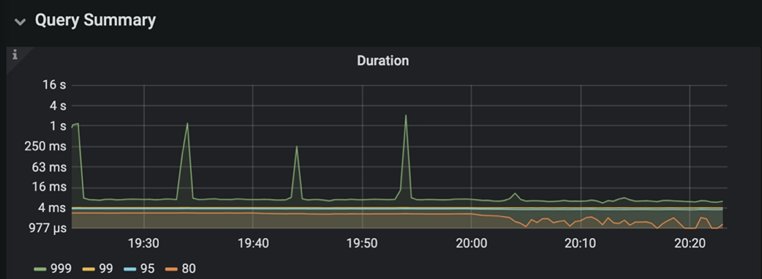
对于 INSERT ON DUPLICATE KEY UPDATE 的情况,如果业务场景是支持做异步批量事务提交的,可以通过在 Sink 前对数据关于入库唯一键做 keyBy 来提前解决事务冲突,来避免异步提交时大概率发生的事务冲突。这个预处理可以显著提升 Sink 的吞吐量,达到了150K OPS。一个典型的例子是,我们在于云音乐直播组小伙伴们交流时,发现他们在一个实时批量更新 TiDB 的业务上有比较大的request duration波动,通过实践我们提出的客户端冲突解决经验,成功地将 request duration 稳定地下降了一个量级:原先 99.9% 分位数可能达到 4s 的请求,现能稳定在 20ms 内完成,下图展示了他们优化前后的情况:
2、业务场景
我们目前技术中心计费数据中心使用 TiDB 跟 Flink 结合的应用场景非常多。如:
- 海量业务日志数据的实时格式化入库
- 基于海量数据的分析统计
- 实时 TiDB / Kafka 双流连接的支付链路分析
- 对通数据地图
- 时序数据
所以,可以看到其实 Flink on TiDB 在网易数据中心业务层的应用是遍地开花的,此处引用一句,“桃李不言,下自成蹊”,既然能用到这么广泛,也就证明了这条路其实是非常有价值的。
‼️ TiDB 社区精美周边领取指南:‼️
如果你想获得:
- TiDB 帆布包
- TiDB 解压魔方
- TiDB 纪念款金属芯签字笔1支
- TiDB 三合一充电线
任一款周边,可以按照以下指南领取: 【人人有份】TiDB 社区精美周边获取指南,人手一份