

TiDB订单业务集群优化分享
--2019-11-12 58公司 春雷
1、汇总
1.1、问题
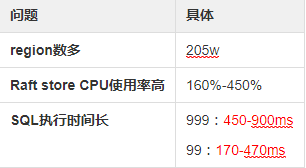
问题:某订单业务准备迁移,开启双写后,发现业务的消息有积压,关闭双写后即恢复
业务层分析:业务开启双写的方式为:异步处理,线程池,其中一个线程池消费慢的话,会导致整体变慢
数据库层分析:数据库消费能力差(SQL执行时间长),导致上游业务出现堆积
处理及优化:
业务层:后期会改成消息队列的方式,即消费慢的话也不会影响整体
数据库层:优化数据库层,减少SQL执行时间
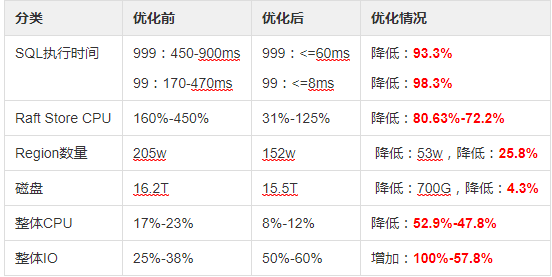
1.2、优化前后对比
2、具体
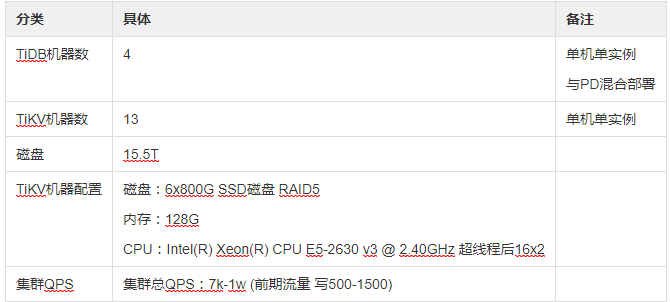
2.1、集群信息
2.2、当前问题
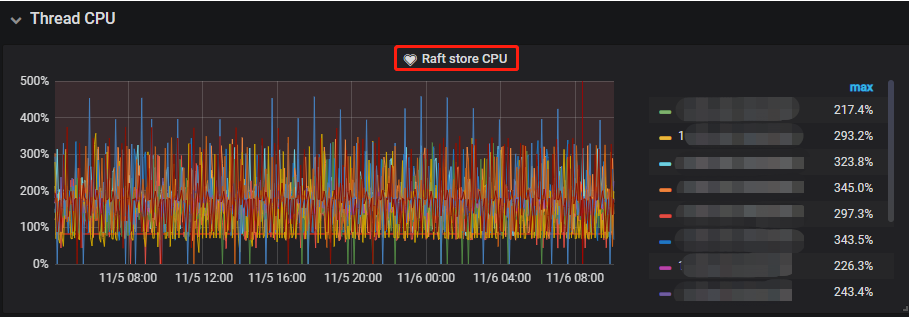
2.3、当前问题监控情况
2.3.1、 Raft store CPU
2.3.2、SQL执行时间
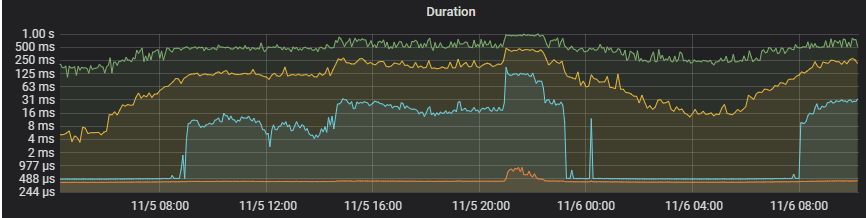
2.3.3、cpu情况
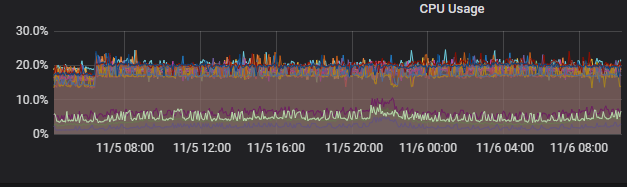
2.3.4、IO情况

3、优化
3.1、优化具体
<1>版本升级
3.0.2 升级至 3.0.5 完成
<2>更改tikv的参数
store-pool-size
- 处理 raft 的线程池线程数。
- 默认值:2
- 最小值:大于 0
[raftstore]的 store-pool-size 2改成4 完成
<3>开启静默region 完成
用于减少 raftstore CPU 的消耗
将 raftstore.hibernate-regions 配置为 true
<4>开启region merge
Region merge 指的是为了避免删除数据后大量小甚至空的 Region 消耗系统资源,通过调度把相邻的小 Region 合并的过程。 在后台遍历,发现连续的小 Region 后发起调度。
4、优化前后对比
4.1、优化前后对比
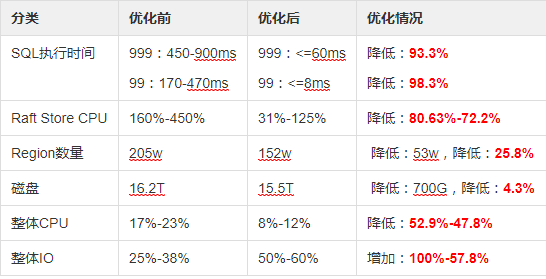
4.2、优化前后的监控情况
4.2.1、优化前后SQL执行时间
【优化前】
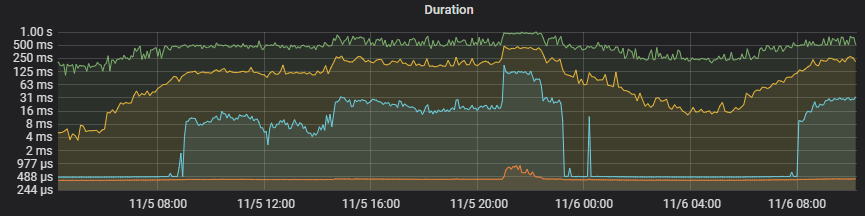
【优化后】
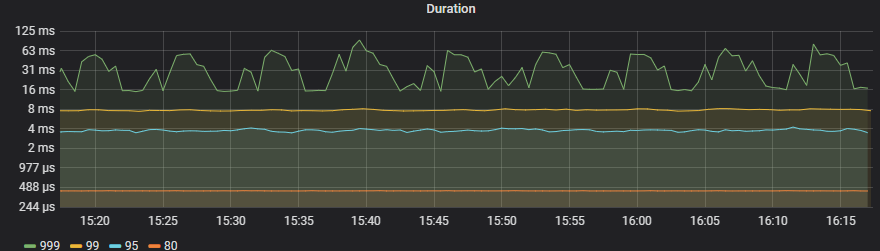
4.2.2、 优化前后Raft store CPU情况
【优化前】
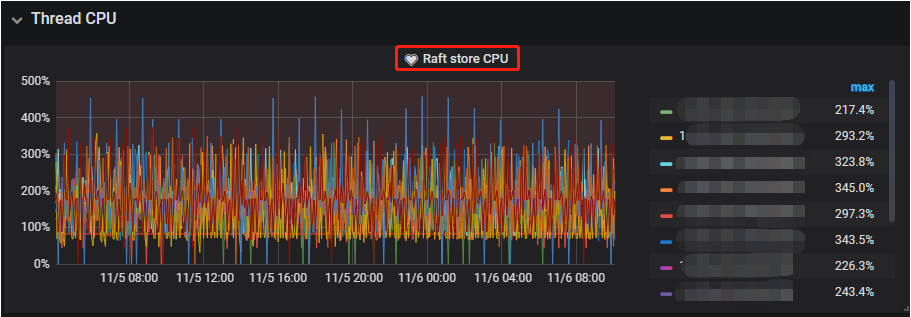
【优化后】
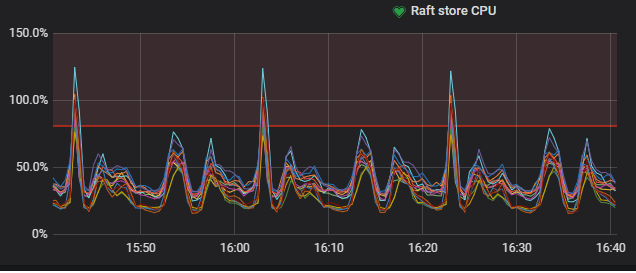
4.2.3、 优化前后CPU情况
【优化前】
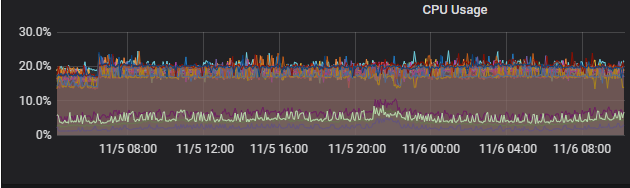
【优化后】
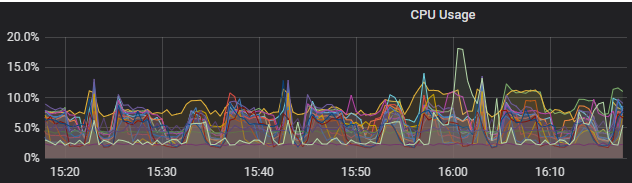
4.2.4、 优化前后 IO使用情况
【优化前】

【优化后】

4.2.5、优化前后各个tikv实例的region等情况
【优化前】

【优化后】

相关阅读: