

前言
本人的工作内容与制造业强相关,多涉及MES、ERP等系统,绝大多数使用着单机部署的数据库。在当前国产化替代的背景下,各业务系统都在找寻一款合适的国产数据库产品进行替换。TiDB 作为一款优秀的分布式 NewSQL 数据库,其敏捷模式的单机部署降低了使用成本,这一点吸引我参与这次体验活动。
平凯数据库的敏捷模式,支持单节点部署,将tikv、tidb、pd组件间的网络调用变为进程间调用,进一步降低延迟。依然支持分布式能力,未来可按需一键转换。总的来说,敏捷模式降低了TiDB的初步使用成本、优化了请求延迟。
本次体验重点关注敏捷模式的部署、数据压缩率、OLTP性能和可扩展性,并与社区版 MYSQL 8 进行对比。同时,在TEM中试用纳管敏捷模式集群的功能。
敏捷模式部署
机器清单
| 机器用途 | TEM组件 | TiDB集群 | MYSQL单机 |
|---|---|---|---|
| CPU | 4 | 8 | 8 |
| 内存 | 8 | 16 | 16 |
| 硬盘 | 100G | 150G | 150G |
| 操作系统 | openEuler release 22.03 (LTS-SP3) | openEuler release 22.03 (LTS-SP3) | openEuler release 22.03 (LTS-SP3) |
| 数据库版本 | TiDB 企业版 v7.1.8-5.2 | MYSQL 社区版 v8.0.43 | |
| IP地址 | 192.168.228.202 | 192.168.228.200 | 192.168.228.201 |
mysql配置
[mysqld]
datadir=/tidbx/mysql
socket=/var/lib/mysql/mysql.sock
log-error=/var/log/mysql/mysqld.log
pid-file=/run/mysqld/mysqld.pid
server-id=30007
log-bin=mysql-bin
innodb_flush_log_at_trx_commit=1
port = 3306
key_buffer_size=64M
max_allowed_packet=128M
net_buffer_length = 8K
read_buffer_size = 64M
innodb_lock_wait_timeout=300
tmp_table_size=167772160
tmpdir=/tidbx/mysql/tmp
log_timestamps=system
innodb_buffer_pool_size = 10G
join_buffer_size = 64M
sort_buffer_size = 64M
read_rnd_buffer_size = 64M
命令行部署
首先,上传sever包和toolkit包,搭建本地镜像仓。之后,开始编辑配置文件和部署集群
cd tidb-ee-server-v7.1.8-5.2-20250630-linux-amd64
./local_install
cp -R tidb-ee-server-v7.1.8-5.2-20250630-linux-amd64/keys ~/.tiup/
tiup mirror merge tidb-ee-toolkit-v7.1.8-5.2-20250630-linux-amd64
tiup cluster deploy tidbx v7.1.8-5.2-20250630 tidbx.yml
与常规部署对比,敏捷模式部署多了kind: fusion,配置文件如下:
global:
kind: fusion
user: "tidb"
ssh_port: 22
deploy_dir: "/tidb-deploy"
data_dir: "/tidbx"
monitored:
node_exporter_port: 9700
blackbox_exporter_port: 9715
server_configs:
pd:
replication.max-replicas: 1
replication.enable-placement-rules: false
tidb_servers:
- host: 192.168.228.200
monitoring_servers:
- host: 192.168.228.200
grafana_servers:
- host: 192.168.228.200
进行集群初始化和root用户修密
tiup cluster start tidbx --init
mysql -h 192.168.228.200 -P 4000 -uroot -p <<EOF
alter user root@'%' identified by '******';
EOF
完成敏捷模式部署后,设置以下参数
set global tidb_runtime_filter_mode=LOCAL;
set global tidb_opt_enable_mpp_shared_cte_execution=on;
set global tidb_rc_read_check_ts=on;
set global tidb_analyze_skip_column_types="json,blob,mediumblob,longblob,mediumtext,longtext";
set global tidb_enable_collect_execution_info=off;
set global tidb_enable_instance_plan_cache=on;
set global tidb_instance_plan_cache_max_size=2GiB;
set global tidbx_enable_tikv_local_call=on;
set global tidbx_enable_pd_local_call=on;
set global tidb_schema_cache_size=0;
-- 是否持久化到集群:否,仅作用于当前连接的 TiDB 实例
set global tidb_enable_slow_log=off;
敏捷模式相关进程如下,可以看到tikv、tidb、pd组件整合为了tidbx组件

体验TEM
部署流程
解压安装包
tar -xvf tem-amd64.tar
cd tem-package-v3.1.0-linux-amd64/
mkdir -pv /tem-data
mkdir -pv /tem-deploy
修改config.yaml配置文件:
global:
user: "tem"
group: "tem"
ssh_port: 22
deploy_dir: "/tem-deploy"
data_dir: "/tem-data"
arch: "amd64"
log_level: "info"
enable_tls: false
server_configs:
tem_servers:
db_addresses: "127.0.0.1:4000"
db_u: "root"
db_pwd: ""
db_name: "test"
log_filename: "/tem-deploy/tem-server-8080/log/tem.log"
log_tem_level: "info"
log_max_size: 300
log_max_days: 0
log_max_backups: 0
external_tls_cert: ""
external_tls_key: ""
internal_tls_ca_cert: ""
internal_tls_cert: ""
internal_tls_key: ""
tem_servers:
- host: "0.0.0.0"
port: 8080
mirror_repo: true
一键安装部署,很便捷
sh install.sh
部署完成后,检查TEM组件状态
TIUP_HOME=/tem-deploy/.tem tiup tem display tem-servers
纳管集群
前置步骤,添加凭证、添加可用主机
选择可用中控机
 选择需纳管的集群
选择需纳管的集群
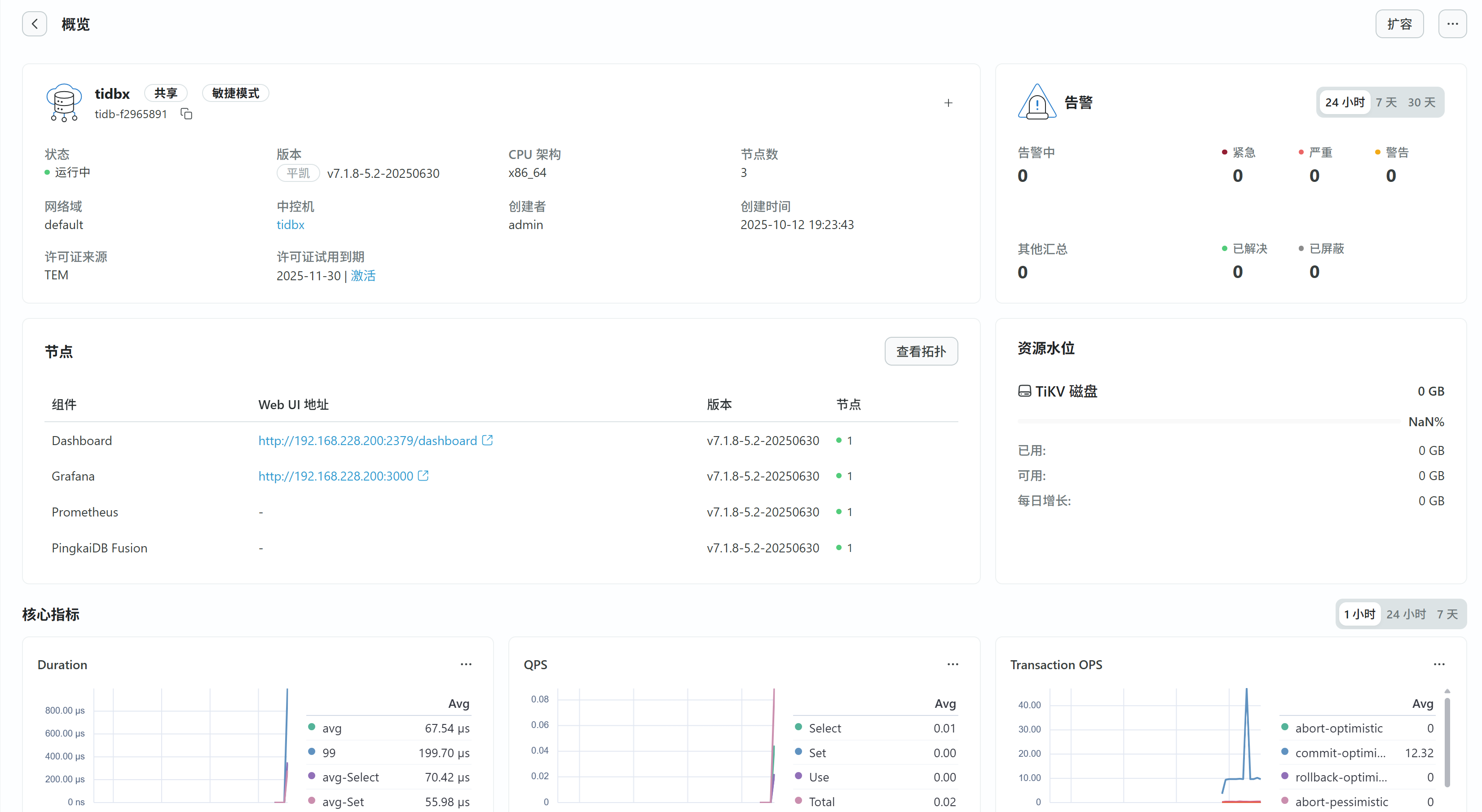
 填写数据库管理员账号密码,等待纳管任务执行成功
填写数据库管理员账号密码,等待纳管任务执行成功
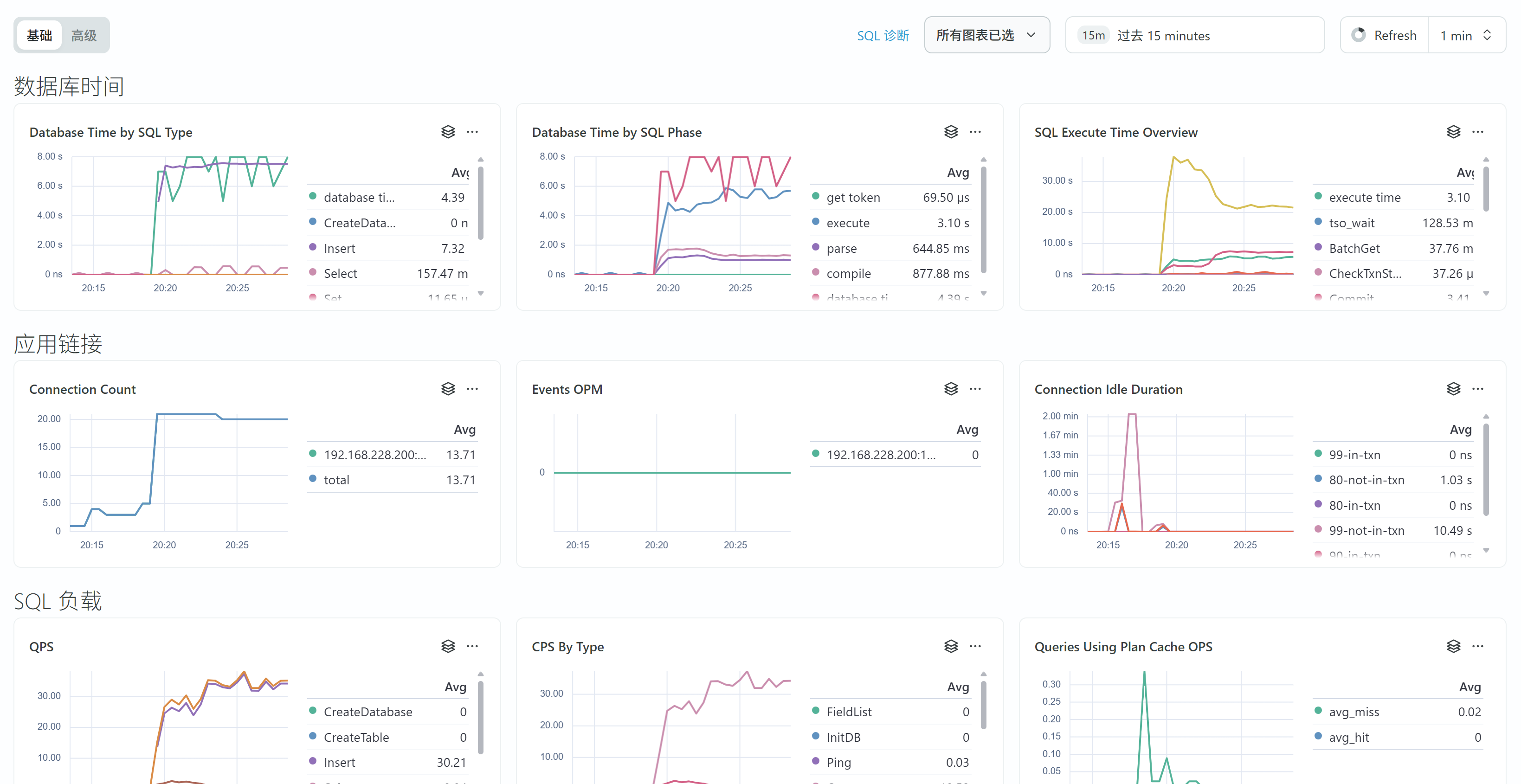
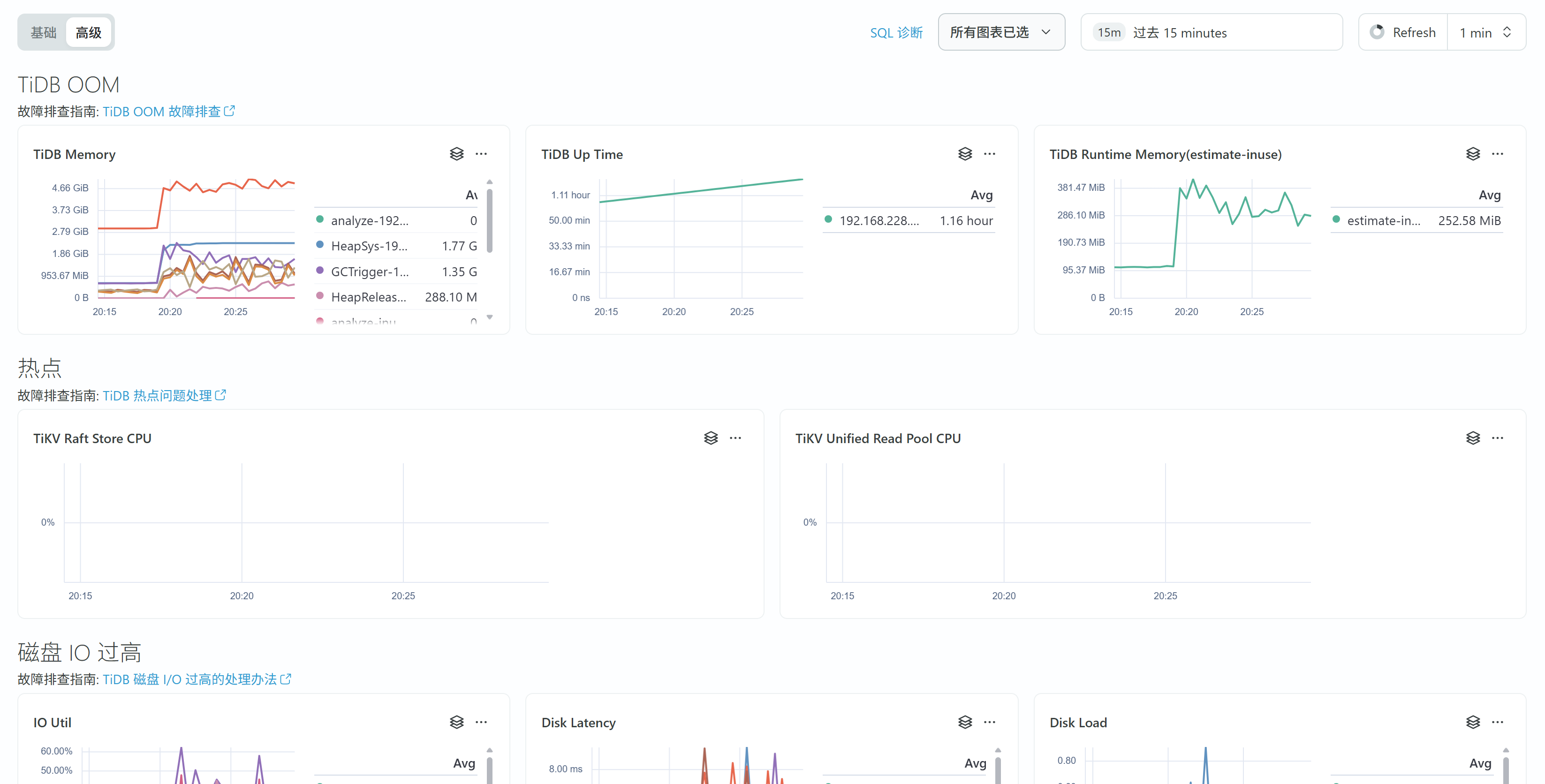
指标监控
基础指标很全面
 高级指标包括内存、IO、线程池CPU等等,常见问题也给出了排查指南
高级指标包括内存、IO、线程池CPU等等,常见问题也给出了排查指南
备份、闪回、巡检等
备份任务配置
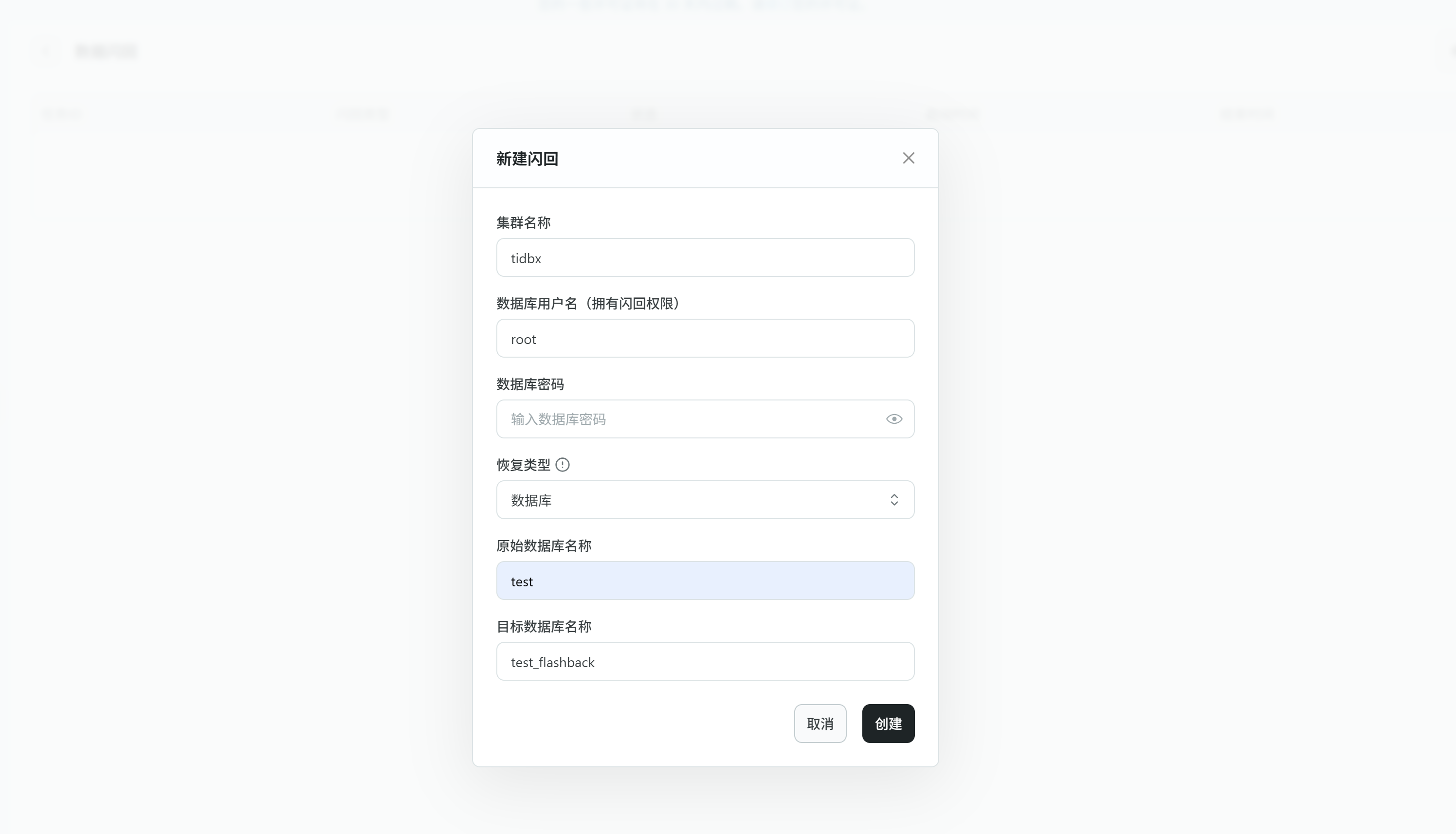
 可视化操作闪回
可视化操作闪回
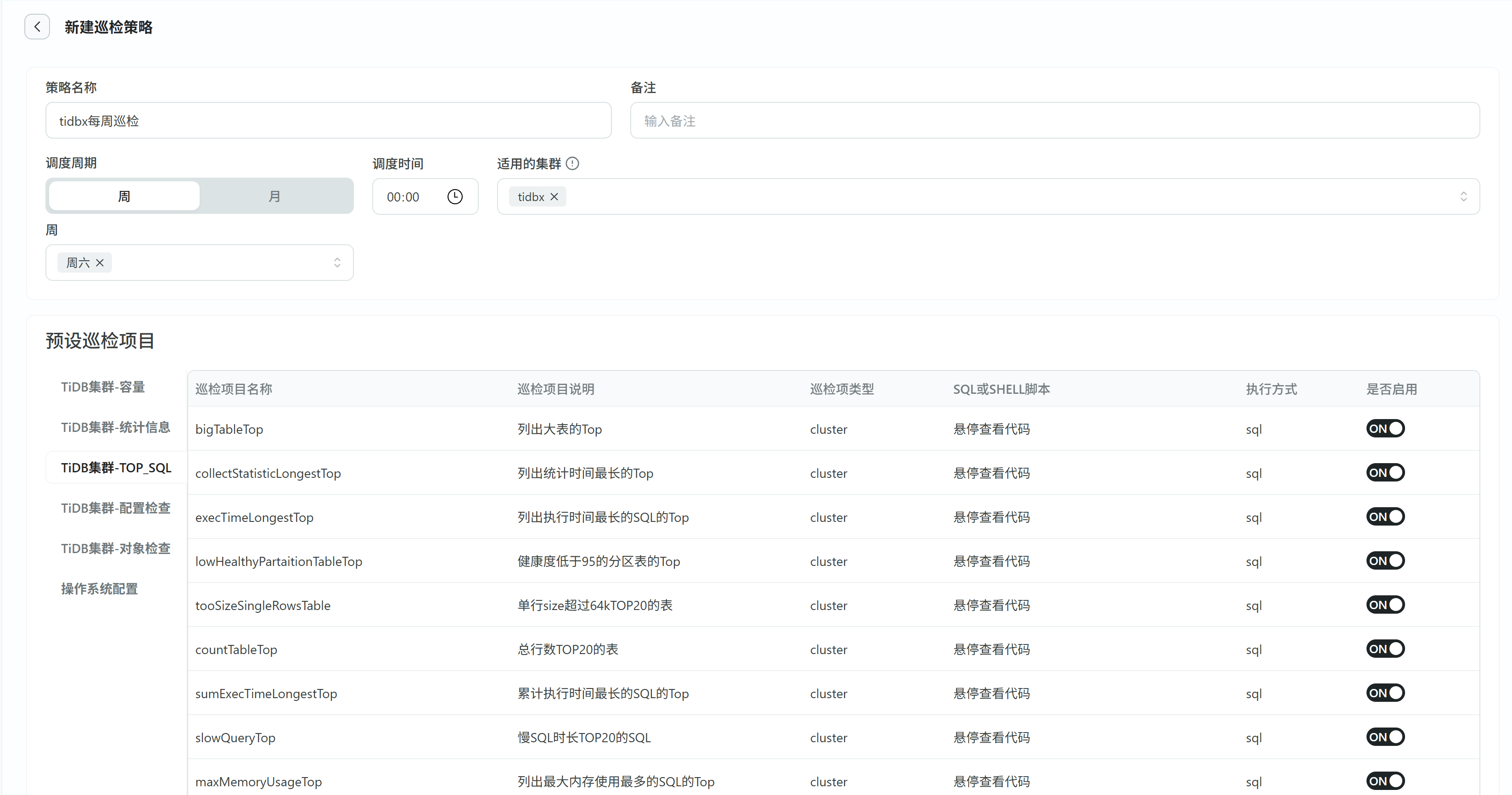
 定时巡检配置
定时巡检配置
数据压缩率对比
- 准备数据 使用 tiup bench 生成 500 Warehouse 的数据,大小约为50G
tiup bench tpcc prepare -P 4000 -D test --user=root --password=********* -T 8 --warehouses 500
- 数据压缩比
对 TiDB 执行合并
tiup ctl:v7.1.8-5.2-20250630 tikv --pd="127.0.0.1:2379" compact-cluster
在 TiDB 和 MYSQL 执行以下SQL,收集统计信息,统计各表数据量
ANALYZE table test.customer;
ANALYZE table test.district;
ANALYZE table test.history;
ANALYZE table test.item;
ANALYZE table test.new_order;
ANALYZE table test.order_line;
ANALYZE table test.orders;
ANALYZE table test.stock;
ANALYZE table test.warehouse;
SELECT table_schema AS '数据库名', table_name, ROUND((data_length + index_length) / 1024 / 1024, 2) AS '数据库大小(MB)' FROM information_schema.tables where table_schema='test' ORDER BY 3 DESC;
各表的数据量
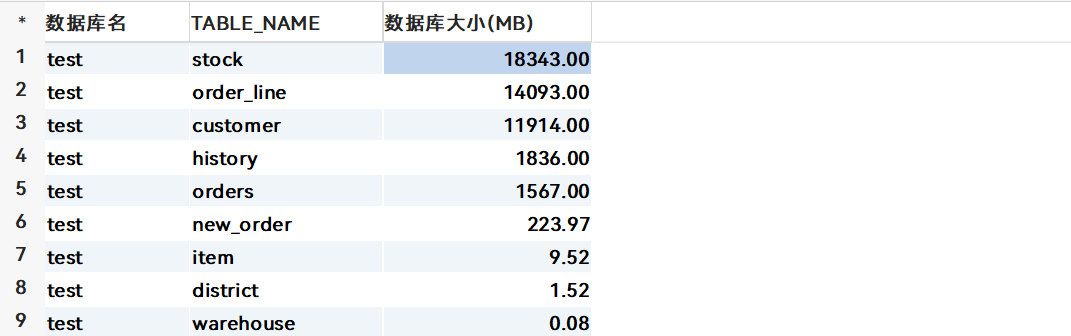
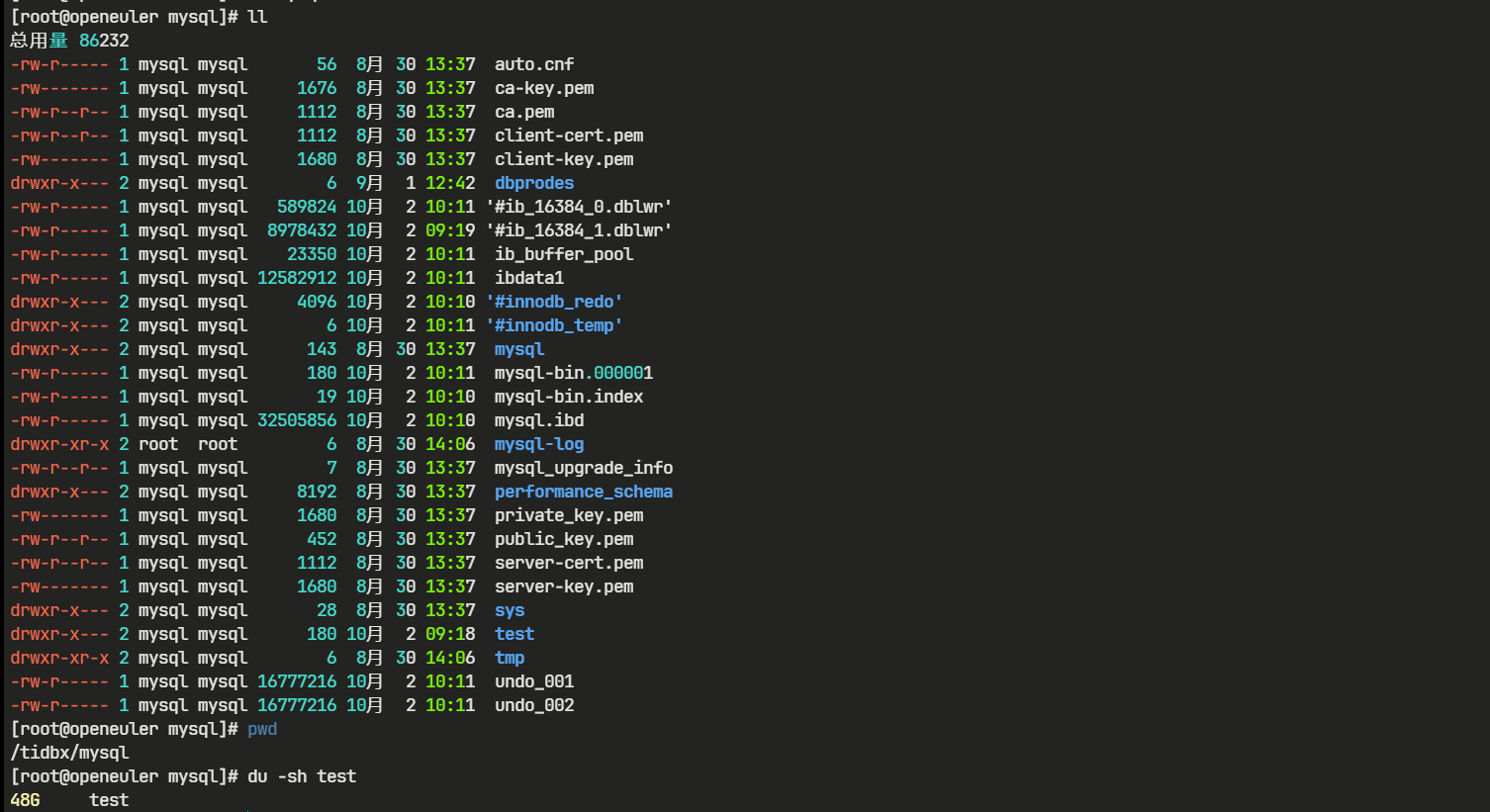
如下图,MYSQL 数据文件大小为48G
 如下图,TiDB 数据文件大小为22G
如下图,TiDB 数据文件大小为22G
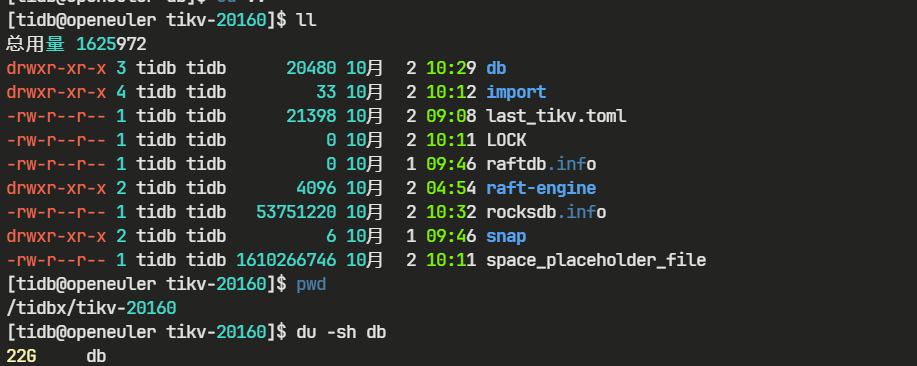
- 压缩比:48 GB / 22 GB ≈ 2.18
- 总结:本次测试中,TiDB 的存储效率约为 MySQL 的 2 倍,即 TiDB 能够在相同数据量下节省近一半的磁盘空间。
TPC-C 性能对比
TPC-C 是一个对 OLTP 系统进行测试的规范,使用一个商品销售模型对 OLTP 系统进行测试,其中包含五类事务:
| 事务 | 占比 | 关键动作 | 特性 |
|---|---|---|---|
| New-Order | ≈45% | 下新单 + 减库存 | 读写混合,唯一被计入有效吞吐量(tpmC) |
| Payment | ≈43% | 订单付款 + 更新余额 | 简单读写,高频热点行 |
| Order-Status | ≈4% | 查客户最近订单 | 只读,索引回表 |
| Delivery | ≈4% | 批量发货 + 清 NEW-ORDER | 范围更新,易出锁等待 |
| Stock-Level | ≈4% | 库存缺货分析 | 子查询 + 范围扫,长尾明显 |
TPC-C Benchmark 规定了数据库的初始状态,其中 ITEM 表中固定包含 10 万种商品,仓库的数量可进行调整,假设 WAREHOUSE 表中有 W 条记录
| 表 | 行数公式 | 说明 |
|---|---|---|
| ITEM | 100 000(固定) | 商品字典,只读 |
| WAREHOUSE | W(可调) | 仓库维度 |
| DISTRICT | W × 10 | 每个仓库 10 个地区 |
| CUSTOMER | W × 10 × 3 000 | 地区下 3 000 客户,热点行来源 |
| HISTORY | W × 10 × 3 000 | 客户交易历史,顺序插入 |
| STOCK | W × 100 000 | 仓库级库存,高并发减库存 |
| ORDER | W × 10 × 3 000 | 订单主表 |
| NEW-ORDER | W × 10 × 900 | 最近 900 笔待发货订单,Delivery 批量删除 |
| ORDER-LINE | ≈ W × 10 × 3 000 × 10 | 每订单 5~15 行明细,最大数据量 |
使用 tiup bench 工具 以 50 WAREHOUSE 进行OLTP测试
准备数据
tiup bench tpcc prepare -P 4000 -D tpcc --user=tpcc --password=****** -T 8 --warehouses 50
执行测试命令
tiup bench tpcc run -P 4000 -D tpcc --user=tpcc --password=****** --warehouses 50 --time 12m -T 16 run
| 指标 | TiDB | MYSQL |
|---|---|---|
| NEW_ORDER Avg(ms) | 102.3 | 215.6 |
| NEW_ORDER 95th(ms) | 142.6 | 369.1 |
| PAYMENT Avg(ms) | 63.1 | 139 |
| PAYMENT 95th(ms) | 100.7 | 243.3 |
| DELIVERY Avg(ms) | 264.5 | 295 |
| DELIVERY 95th(ms) | 335.5 | 436.2 |
| STOCK_LEVEL Avg(ms) | 68.8 | 34.8 |
| STOCK_LEVEL 95th(ms) | 96.5 | 60.8 |
| ORDER_STATUS Avg(ms) | 43.1 | 43.4 |
| ORDER_STATUS 95th(ms) | 65 | 79.7 |
| tpmC | 4760.7 | 2408.9 |
| tpmTotal | 10554.3 | 5308.7 |
| efficiency | 740.4% | 374.6% |
在此次 TPC-C Benchmark 中,TiDB(敏捷模式单机)在吞吐量、写延迟方面显著优于 MySQL,读延迟则与 MYSQL 相当。
- 吞吐量:TiDB 的吞吐量比 MySQL 高出 97%。
- 延迟:TiDB 的写延迟优势非常明显。通过敏捷模式的优化,订单查询的读延迟也略优于MYSQL。但在库存缺货状态分析场景下逊于MYSQL,可能需要调整 Block Cache 等参数。
可扩展性
在 TiDB 敏捷模式 下,可以采用 TiCD 组件构建两个集群的主-从或主-主高可用架构。也可以通过扩容tidb-server节点,从单机一键转为分布式。
TiCDC 实现高可用
有两个敏捷模式集群A、B,规划每个集群均创建一个 ticdc 组件,搭建两个集群间的双向复制,参考《TiCDC 双向复制》。
准备工作
用 Dumpling + Lightning 把 A、B 集群当前数据互相同步到对端,保证起点一致。
记录集群A、B在数据一致时刻对应的 TSO,后续 --start-ts 分别用这两个 TSO,避免重复回放。
下面为每个集群扩容一个 ticdc 组件
集群A的scale-out.yaml
cdc_servers:
- host: 192.168.228.200
port: 8300
集群B的scale-out.yaml
cdc_servers:
- host: 192.168.228.111
port: 8300
分别在集群A、B执行tidb cluster scale-out xxx scale-out.yaml
创建主从同步任务
集群A 创建A->B链路
cdc cli changefeed create --server=http://192.168.228.200:8300 \
--changefeed-id=a-to-b \
--sink-uri="tidb://user:pwd@192.168.228.111:4000/?worker-count=16&max-txn-row=256" \
--start-ts=<A集群对应TSO> \
--config=cfg-a.toml
cfg-a.toml
# 会在 KV 层打标记,TiCDC 识别到复制来的数据,即丢弃该条,从而天然避免回环
bdr-mode = true
# 可选:加数据源标记,方便排障
source-id = "dc-a"
enable-old-value = true
force-replicate = true
[mounter]
worker-num = 16
[filter]
rules = ["tpcc.*"]
集群B 创建B->A链路
cdc cli changefeed create --server=http://192.168.228.111:8300 \
--changefeed-id=b-to-a \
--sink-uri="tidb://user:pwd@192.168.228.200:4000/?worker-count=16&max-txn-row=256" \
--start-ts=<B集群对应TSO> \
--config=cfg-b.toml
cfg-b.toml
# 防止循环复制
bdr-mode = true
# 可选:加数据源标记,方便排障
source-id = "dc-b"
enable-old-value = true
force-replicate = true
[mounter]
worker-num = 16
[filter]
rules = ["tpcc.*"]
查看链路状态
cdc cli changefeed query -s http://192.168.228.200:8300 -c a-to-b
一键转分布式
和常规模式下类似,编辑 scale-out 配置文件,扩容 tidb-server
tidb_servers:
- host: 192.168.228.111
执行tidb cluster scale-out tidbx tidbx-cdc.yml,完成扩容,region自动重分布
总结
- TiDB 敏捷模式 能够完美替换 MES、ERP系统中的 MYSQL单机数据库。
- TEM 的可视化操作让运维更轻松、便捷;
- 吞吐量、写延迟、数据压缩率远优于 MySQL8 社区版,读延迟则与 MySQL 相当。未来一键扩容为分布式的可扩展性是MYSQL不具备的。