

1 - 我们是怎么处理MySQL慢日志的
我们将MySQL慢日志拆分为两类功能:
- 每日报表;
- 实时慢日志流水;
每日报表:从业务线、MySQL集群、SQL三个维护,分析展示慢日志情况。
实时慢日志流水,顾名思义,开发人员可在web页面查看名下负责集群的当前慢日志情况。下面将逐一详细介绍。
每日报表 在业务线层面,包含慢日志数量变化的趋势图、单位时间(天)内各业务线的慢日志分布情况、以及慢日志数量、占比、周环比等。
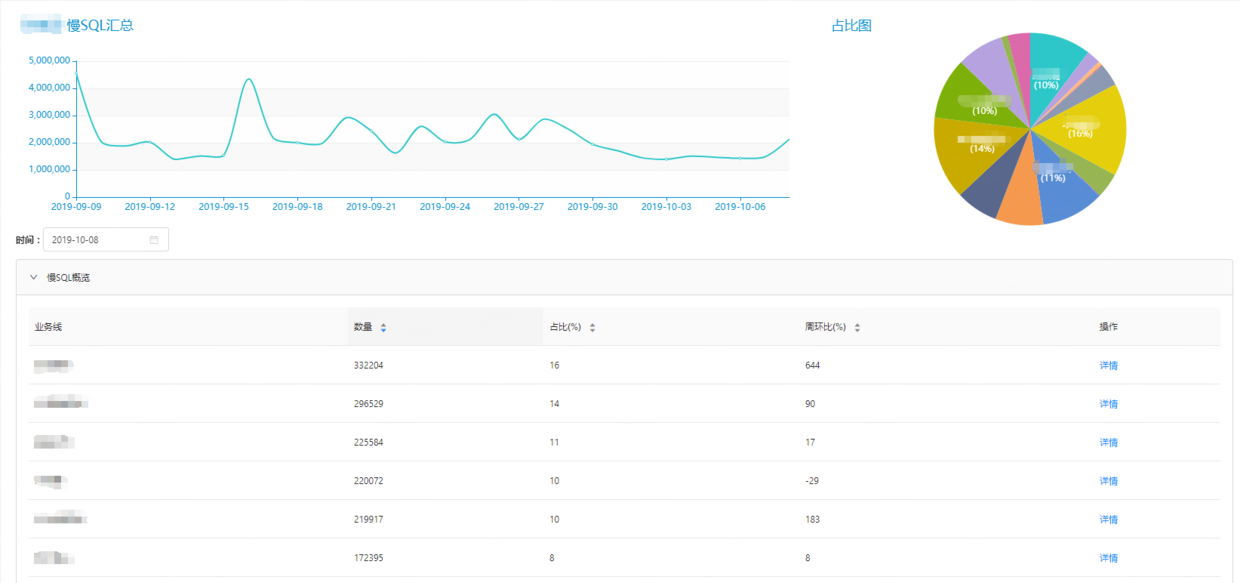
在MySQL集群层面,展示了以集群维度统计的慢日志变化趋势,以及SQL的数量、占比、优化建议等。
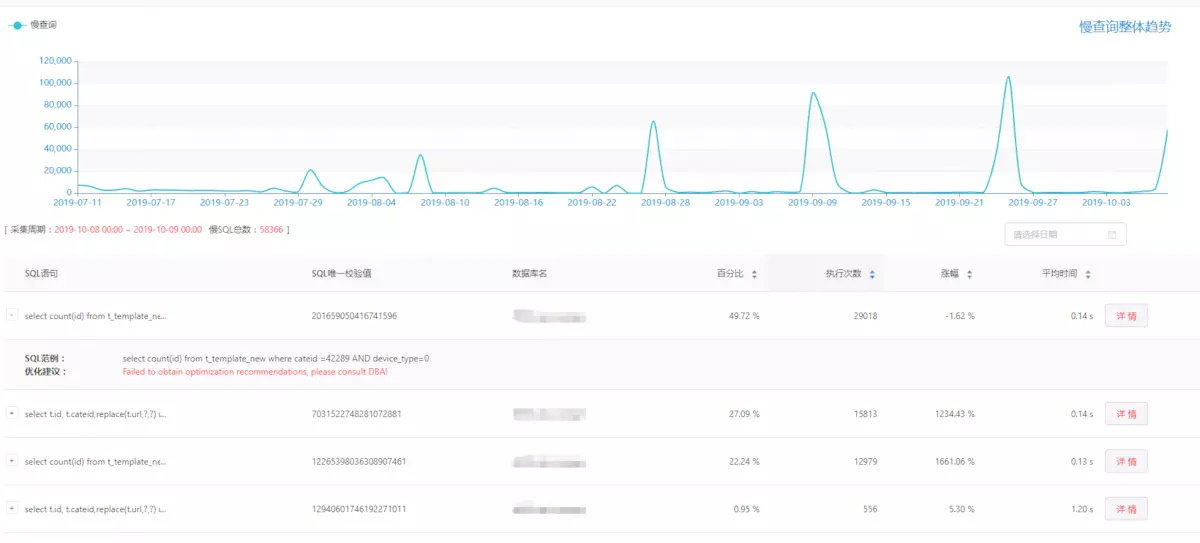
在SQL层面,展示了SQL维度的变化趋势和慢SQL的详情,其中开发人员可以看到一些基本信息,DBA会看到更多关于innodb的信息。
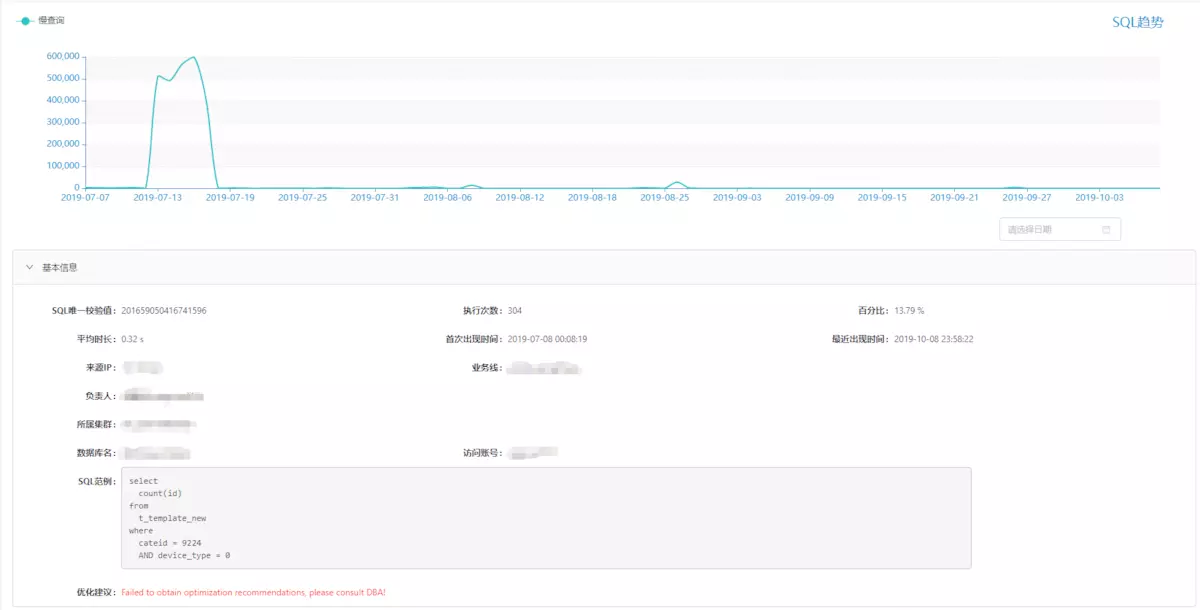
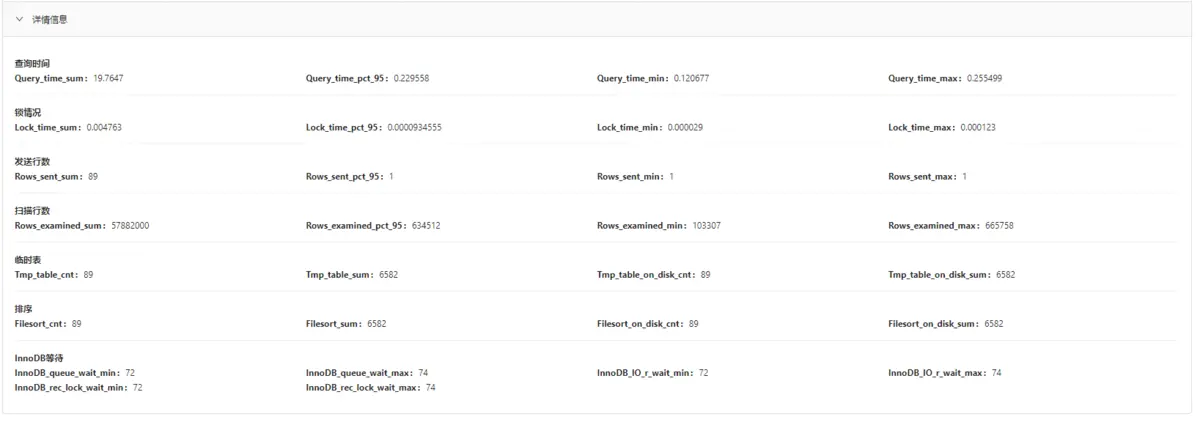
如何得到这些数据? 我们会在管理机上每天零点运行一个定时任务,进行如下工作:
- 按照ip、端口、日期切割MySQL慢日志文件;
- 拉取各节点的慢日志文件到管理机的指定目录;
- 借助pt-query-digest分析拉取到的慢日志,并将结果存入到指定的MySQL中;
- 加工pt分析的结果,包括关联业务线、负责人信息,获取优化建议等。
经过以上步骤,我们就得到了上面图中的数据啦。
实时慢日志流水 我们借助Elastic Stack实现了MySQL的实时慢日志,大致流程为:
- filebeat采集MySQL慢日志,上报kafka;
- logstash消费kafka中数据,同时对数据过滤、切割,存储到ES中;
- 开发人员在DB管理平台提交过滤条件,实时查询ES中数据。
正常状态下,慢SQL产生到可被查询到的延时在5s左右。
整体架构图如下:

filebeat配置:
#========================= filebeat global options ============================
filebeat.registry_file: /work/elk/filebeat/data/registry
fields:
host: 1.1.1.1
port: 3306
#================================ logging ======================================
logging.level: info
logging.to_files: true
logging.files:
path: /work/elk/filebeat/log
name: filebeat
rotateeverybytes: 1048576000 # = 1Gb
keepfiles: 7
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
- type: log
enabled: true
paths:
- /work/mysql3306/log/*_slow_*.log
multiline:
pattern: "^# User@Host:"
negate: true
match: after
fields:
log_topics: mysqlslow
#================================ Outputs =====================================
#------------------------------- Kafka output ----------------------------------
output.kafka:
enabled: true
hosts: ["2.2.2.2:9092","3.3.3.3:9092","4.4.4.4:9092"]
topic: '%{[fields][log_topics]}'
worker: 1
bulk_max_size: 10486090
timeout: 30s
broker_timeout: 10s
keep_alive: 0
compression: gzip
max_message_bytes: 1048609000
required_acks: 1
client_id: mysql3306
可能有人会问,为什么使用pattern: "^# User@Host:"来做日志切割,而不是用# Time。这是由于MySQL的慢日志中,相近时间的记录,只会有一条时间记录,用# Time来做分割,会使数据错乱。
同时,为了方便测试,这里采用的kafka没有做clientid的权限控制。
慢日志数据上报到kafka后,Logstash会消费并存储到ES中。由于经过了一层kafka缓存,数据格式稍稍发生了变化,只使用正则不太好处理,因此我们使用了在logstash的filter中嵌套ruby的形式来处理数据,一个简单的实例如下:
filter {
if [myid] == "slowlog" {
ruby {
code => "
a=event.get('message').scan(/"fields":{([^}]+)}/)
b=event.get('message').scan(/"message":"(([^\""]|\".)+)"/)
host = a[0][0].scan(/"host":"(d{1,3}.d{1,3}.d{1,3}.d{1,3})"/)
port = a[0][0].scan(/"port":(d+)/)
event.set('host',host[0][0])
event.set('port',port[0][0])
user = b[0][0].scan(/User@Host:s(.*)s@/)
if user.length > 0
event.set('user',user[0][0])
end
ip = b[0][0].scan(/User@Host.*@s{1,2}[(d{1,3}.d{1,3}.d{1,3}.d{1,3})]/)
if ip.length > 0
event.set('ip',ip[0][0])
end
thread_id = b[0][0].scan(/Thread_id:s{1,2}(d+?)s{1,2}/)
if thread_id.length > 0
event.set('thread_id',thread_id[0][0])
end
schema = b[0][0].scan(/Schema:s{1,2}(.*?)s{1,2}/)
if schema.length > 0
event.set('schema',schema[0][0])
end
query_time = b[0][0].scan(/Query_time:s{1,2}(.*?)s{1,2}/)
if query_time.length > 0
event.set('query_time',query_time[0][0])
end
lock_time = b[0][0].scan(/Lock_time:s{1,2}(.*?)s{1,2}/)
if lock_time.length > 0
event.set('lock_time',lock_time[0][0])
end
rows_sent = b[0][0].scan(/Rows_sent:s{1,2}(.*?)s{1,2}/)
if rows_sent.length > 0
event.set('rows_sent',rows_sent[0][0])
end
rows_examined = b[0][0].scan(/Rows_examined:s{1,2}(.*?)s{1,2}/)
if rows_examined.length > 0
event.set('rows_examined',rows_examined[0][0])
end
rows_affected = b[0][0].scan(/Rows_affected:s{1,2}(.*?)s{1,2}/)
if rows_affected.length > 0
event.set('rows_affected',rows_affected[0][0])
end
rows_read = b[0][0].scan(/Rows_read:s{1,2}(d+)/)
if rows_read.length > 0
event.set('rows_read',rows_read[0][0])
end
bytes_sent = b[0][0].scan(/Bytes_sent:s{1,2}(d+)/)
if bytes_sent.length > 0
event.set('bytes_sent',bytes_sent[0][0])
end
sql = b[0][0].scan(/SETs{1,2}timestamp=d+;\"n(.*)/)
if sql.length > 0
event.set('sql',sql[0][0])
end
"
}
mutate {
remove_field =>["message"]
}
}
}
在每个MySQL服务器上部署一个filebeat,我们就得到实时的慢日志流水。同样的,MySQL的审计日志、错误日志等也可以配置到filebeat中,统一上报处理,这里不再赘述。
2 - TiDB慢日志
上面介绍过了MySQL慢日志的处理方式,那么完全适用于TiDB吗?答案当然不是。由于MySQL和TiDB慢日志格式的差异,pt-query-digest的no-report方式,不能分析TiDB的慢日志(MySQL-SLA没做测试,不确定能否兼容),但是report的方式可以使用。
PS:吐槽一下官方,这个问题好久了,还没有修复。
MySQL的慢日志:
# Time: 190918 16:31:56
# User@Host: root[root] @ [127.0.0.1] Id: 284872077
# Schema: test Last_errno: 0 Killed: 0
# Query_time: 0.176018 Lock_time: 0.000322 Rows_sent: 24 Rows_examined: 63389 Rows_affected: 0
# Bytes_sent: 11529
SET timestamp=1568795516;
这里是SQL;
TiDB的慢日志(官方示例):
# Time: 2019-08-14T09:26:59.487776265+08:00
# Txn_start_ts: 410450924122144769
# User: root@127.0.0.1
# Conn_ID: 3086
# Query_time: 1.527627037
# Process_time: 0.07 Request_count: 1 Total_keys: 131073 Process_keys: 131072 Prewrite_time: 0.335415029 Commit_time: 0.032175429 Get_commit_ts_time: 0.000177098 Local_latch_wait_time: 0.106869448 Write_keys: 131072 Write_size: 3538944 Prewrite_region: 1
# DB: test
# Is_internal: false
# Digest: 50a2e32d2abbd6c1764b1b7f2058d428ef2712b029282b776beb9506a365c0f1
# Stats: t:pseudo
# Num_cop_tasks: 1
# Cop_proc_avg: 0.07 Cop_proc_p90: 0.07 Cop_proc_max: 0.07 Cop_proc_addr: 172.16.5.87:20171
# Cop_wait_avg: 0 Cop_wait_p90: 0 Cop_wait_max: 0 Cop_wait_addr: 172.16.5.87:20171
# Mem_max: 525211
# Succ: false
insert into t select * from t;
那么问题来了,既然pt工具不好用了,我们怎么办呢?
- 改造pt工具,兼容TiDB的慢日志格式;
- 根据TiDB的慢日志格式,因地制宜,保持最终与MySQL慢日志展示数据的一致性;
- 从TiDB慢日志相关表中获取数据;
经与官方沟通,后续有可能更改TiDB慢日志格式,保持和官方一致。因此,我们的实时慢日志采用了第二种方案:上传TiDB慢日志到ES,统一分析处理,保持最终展示数据的一致性;慢日志报表采用第三种方案:从慢日志表中读取数据后做汇总。
TiDB慢日志数据上报,复用MySQL实时慢日志的架构,稍作更改即可,在这里介绍一下与前文的区别:
filebeat配置:
#========================= filebeat global options ============================
filebeat.registry_file: /work/elk/filebeat/filebeat4000/data/registry
fields:
host: 1.1.1.1
port: 4000
#================================ logging ======================================
logging.level: info
logging.to_files: true
logging.files:
path: /work/elk/filebeat/filebeat4000/log
name: filebeat
rotateeverybytes: 1048576000 # = 1Gb
keepfiles: 7
#=========================== Filebeat prospectors =============================
filebeat.prospectors:
- type: log
enabled: true
paths:
- /work/tidb4000/log/tidb_slow_query.log
multiline:
pattern: "^# Time:"
negate: true
match: after
fields:
log_topics: tidbslow
#================================ Outputs =====================================
#------------------------------- Kafka output ----------------------------------
output.kafka:
enabled: true
hosts: ["2.2.2.2:9092","3.3.3.3:9092","4.4.4.4:9092"]
topic: '%{[fields][log_topics]}'
worker: 1
bulk_max_size: 10486090
timeout: 30s
broker_timeout: 10s
keep_alive: 0
compression: gzip
max_message_bytes: 1048609000
required_acks: 1
client_id: tidb4000
由于TiDB的慢日志中的每条记录都以# Time开头,因此filebeat的pattern更改为pattern: "^# Time:"。
Logstash的输入为kafka、输出为ES,和前文相同,这里介绍一下filter修改的部分:
filter {
if [myid] == "tidbslow" {
ruby {
code => "
a=event.get('message').scan(/"fields":{([^}]+)}/)
b=event.get('message').scan(/"message":"(([^\""]|\".)+)"/)
port = a[0][0].scan(/"port":(d+)/)
if port.length > 0
event.set('port',port[0][0])
end
host = a[0][0].scan(/"host":"(d{1,3}.d{1,3}.d{1,3}.d{1,3})"/)
if host.length > 0
event.set('host',host[0][0])
end
time = b[0][0].scan(/# Time:s(.*?)\"n/)
if time.length > 0
event.set('time',time[0][0])
end
user = b[0][0].scan(/# User:s(.*?)@/)
if user.length > 0
event.set('user',user[0][0])
end
ip = b[0][0].scan(/# User:.*@(d{1,3}.d{1,3}.d{1,3}.d{1,3})/)
if ip.length > 0
event.set('ip',ip[0][0])
end
Query_time = b[0][0].scan(/Query_time:s([1-9]d*.d*|0.d*[1-9]d*)\"n/)
if Query_time.length > 0
event.set('Query_time',Query_time[0][0])
end
Process_time = b[0][0].scan(/Process_time:s([1-9]d*.d*|0.d*[1-9]d*)/)
if Process_time.length > 0
event.set('Process_time',Process_time[0][0])
end
Request_count = b[0][0].scan(/Request_count:s(d+?)/)
if Request_count.length > 0
event.set('Request_count',Request_count[0][0])
end
Total_keys = b[0][0].scan(/Total_keys:s(d+)/)
if Total_keys.length > 0
event.set('Total_keys',Total_keys[0][0])
end
Process_keys = b[0][0].scan(/Process_keys:s(d+)/)
if Process_keys.length > 0
event.set('Process_keys',Process_keys[0][0])
end
DB = b[0][0].scan(/# DB: (.*?)\"n/)
if DB.length > 0
event.set('DB',DB[0][0])
end
Is_internal = b[0][0].scan(/# Is_internal: (.*?)\"n/)
if Is_internal.length > 0
event.set('Is_internal',Is_internal[0][0])
end
Digest = b[0][0].scan(/# Digest: (.*?)\"n/)
if Digest.length > 0
event.set('Digest',Digest[0][0])
end
Num_cop_tasks = b[0][0].scan(/# Num_cop_tasks: (d+?)\"n/)
if Num_cop_tasks.length > 0
event.set('Num_cop_tasks',Num_cop_tasks[0][0])
end
Cop_proc_avg = b[0][0].scan(/# Cop_proc_avg: ([1-9]d*.d*|0.d*[1-9]d*) /)
if Cop_proc_avg.length > 0
event.set('Cop_proc_avg',Cop_proc_avg[0][0])
end
Cop_proc_p90 = b[0][0].scan(/Cop_proc_p90: ([1-9]d*.d*|0.d*[1-9]d*) /)
if Cop_proc_p90.length > 0
event.set('Cop_proc_p90',Cop_proc_p90[0][0])
end
Cop_proc_max = b[0][0].scan(/Cop_proc_max: ([1-9]d*.d*|0.d*[1-9]d*) /)
if Cop_proc_max.length > 0
event.set('Cop_proc_max',Cop_proc_max[0][0])
end
Cop_proc_addr = b[0][0].scan(/Cop_proc_addr: (.*?)\"n/)
if Cop_proc_addr.length > 0
event.set('Cop_proc_addr',Cop_proc_addr[0][0])
end
Cop_wait_avg = b[0][0].scan(/# Cop_wait_avg: ([1-9]d*.d*|0.d*[1-9]d*|d*) /)
if Cop_wait_avg.length > 0
event.set('Cop_wait_avg',Cop_wait_avg[0][0])
end
Cop_wait_p90 = b[0][0].scan(/Cop_wait_p90: ([1-9]d*.d*|0.d*[1-9]d*|d*) /)
if Cop_wait_p90.length > 0
event.set('Cop_wait_p90',Cop_wait_p90[0][0])
end
Cop_wait_max = b[0][0].scan(/Cop_wait_max: ([1-9]d*.d*|0.d*[1-9]d*|d*) /)
if Cop_wait_max.length > 0
event.set('Cop_wait_max',Cop_wait_max[0][0])
end
Cop_wait_addr = b[0][0].scan(/Cop_wait_addr: (.*?)\"n/)
if Cop_wait_addr.length > 0
event.set('Cop_wait_addr',Cop_wait_addr[0][0])
end
Mem_max = b[0][0].scan(/# Mem_max: (d+?)\"n/)
if Mem_max.length > 0
event.set('Mem_max',Mem_max[0][0])
end
Succ = b[0][0].scan(/# Succ: (w+?)\"n/)
if Succ.length > 0
event.set('Succ',Succ[0][0])
end
SQL = b[0][0].scan(/Succ:.*\"n(.*?);/)
if SQL.length > 0
event.set('SQL',SQL[0][0])
end
"
}
mutate {
remove_field =>["message"]
}
}
}
这里没有全部提取TiDB慢日志中的所有信息,只获取了我们需要的部分。
后续流程与MySQL实时慢日志一样。由此,我们就得到了TiDB的实时慢日志。