

过去的两年我在大树金融担任大数据团队负责人,打造了一套一体化无边界的大数据基础平台,其中的一些架构思路和做法值得分享一下。
何谓一体化无边界、它的架构要点、典型应用案例,这些是我接下来要讲的。
一体化无边界
所谓一体化,指的是一套基础架构同时支撑 分析挖掘、线上业务 和流处理。 所谓无边界,指的是同样的组件我们用客户也用、既可以平台/API嵌入业务系统也可以业务逻辑嵌入数据平台。
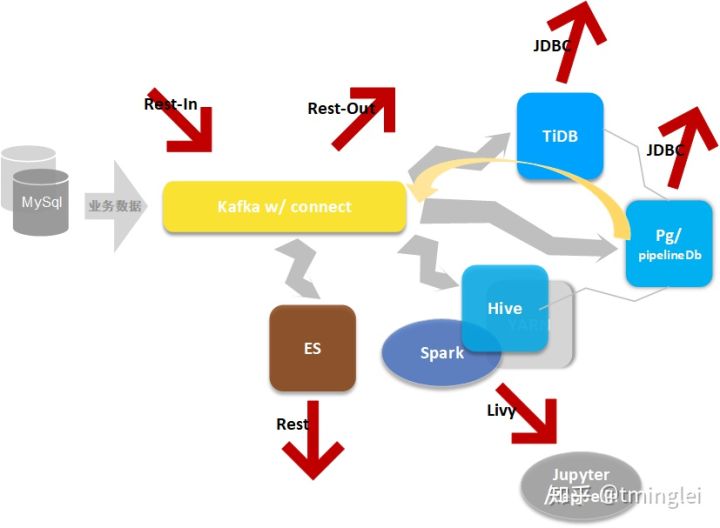
这是我们的基础架构及业务影响图,
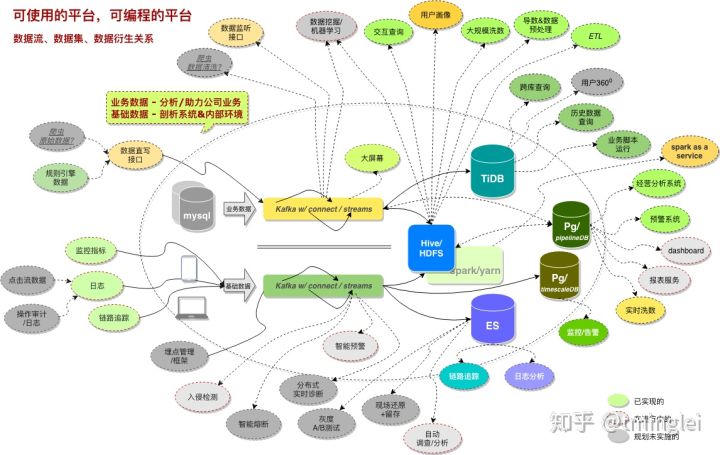
接下来讲下它的要点:
架构要点
抽象点说,数据总线连接各类存储、计算组件,组件能力的不同组合可以满足各类业务场景。
这里 数据总线/同步能力是关键。正是基于强大的数据同步能力,不同来源的数据可以在数据仓库里被直接访问,不同计算可以分散到不同组件、最后结果汇集于所需要的地方,让平台上不同组件可以取长补短、互通有无。
比如,
[存储体系]

通过实时同步,
- 形成了 热-温-冷(MySQL-TiDB-Hive/HDFS)存储体系
- 线上MySQL专心存储热数据,不再需要分库分表
- TiDB汇集所有线上业务数据,可提供全量、跨库查询
- Hive/HDFS有所有数据,业务数据+日志数据,支撑大规模分析挖掘
~
[计算转移]
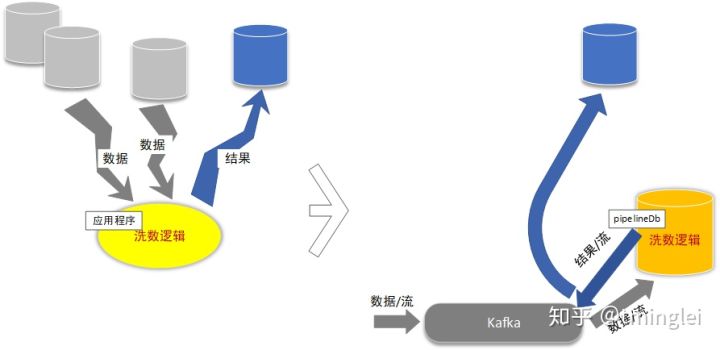
借助实时同步,我们转移了洗数逻辑,不再需要访问不同系统获得数据(直接推送给它),业务迭代更快速(SQL、实时上线),计算结果同步到原来的目标数据库(外部应用不受影响)。
~
依托强大的数据总线/同步能力,让我们在选择和组合业务所需的存储、计算能力方面更加自由。
大数据平台一些常见的能力/要素如下:
- 快速检索(for 查询)能力
- 快速扫描(for 分析)能力
- 海量存储能力
- 廉价存储能力
- 大规模(批处理)计算能力
- 流处理计算能力
- 图存储&计算能力
- 函数&算法生态能力
- 数据输出/可视化能力
- 资源调度/管理能力
- 元数据管理能力
- 等等
我们的一些组件选型及看中的能力如下:
- Kafka w/ connect(数据总线,CDC)
- Hadoop w/ Hive/HDFS/YARN(海量廉价存储,快速扫描,计算资源&调度)
- Spark(大规模分析计算,跨源访问,流处理,机器学习)
- Flink(流处理,CEP,等)
- TiDB(大规模存储,快速检索,复杂查询,MySQL生态)
- PostgreSQL w/ pipelineDb/timescaleDb/*_fdw(流处理,监控数据处理,复杂查询,跨源访问,Pg生态)
- ElasticSearch w/ ELK(日志数据处理,模糊查询)
- 等等
总线连通的做法还有几个相关的问题需要考虑:
- 被连接的各存储组件,需要具备流式入库和 CDC(Change Data Capture)能力。(MySQL、Pg、TiDB、ES 具备这方面能力,Hive 这边,我们开发了流式入库的能力,同时支持了修改/删除。)
- 统一的数据交换格式以及版本迭代
- 归档删除,热存储组件删除历史数据时,全量仓库那边不能删除。(我们通过约定删除机制解决了这个问题。)
如上,针对分析挖掘、线上查询、批处理、流处理等应用场景,我们并没有独立的基础架构。但我愿顺着这个思路展开,看看针对不同业务/场景提供的解决方案:
分析架构
面向数据分析和风控人员
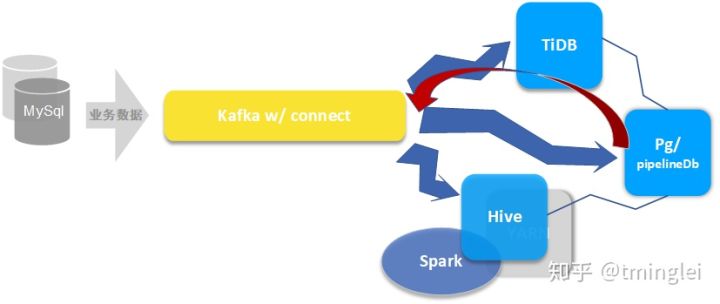
Hive 和 Pg 是主力,
- Hive w/ spark 我们做了些优化后,性能还不错,日常大作业和交互查询都在上面
- 对于精确小查询,又碰上 Hadoop 资源吃紧,我们建议走 TiDB
- 中间表和输出结果放 Pg,是对外报表的主要后端
- 借助 pipelineDb 及其他辅助插件,中间表可以在 Pg 实时生成,并按需同步到其他地方
线上架构
面向线上业务系统

TiDB 是主力,
- 历史/全量查询、跨库查询 以及业务脚本运行都走 TiDB
- 需要同时访问冷热数据的,用 Pg + Mysql_fdw 支持(注:适用于条件明确的查询,条件模糊/大查询不适合)
- Pg w/ pipelineDb 用作实时洗数,结果实时同步到需要的地方(计算过程中需要用到线上MySQL主库 或 TiDB 数据的,可以自由访问)
流处理架构
既能支撑大规模分布式计算,又兼具PgSQL生态优势。
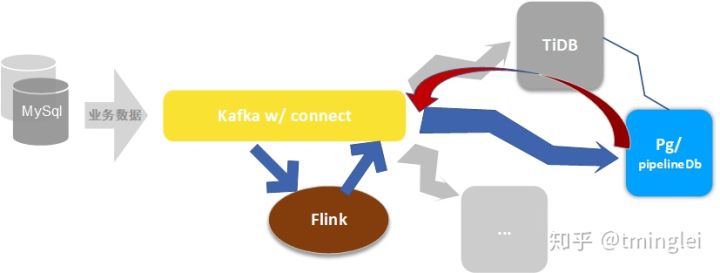
在数据流动的各个环节都可以自由处理,
- Flink 主要用于超大规模数据预处理 以及 CEP 等特殊场景(开发、部署及管理成本要高些)
- Pg w/ pipelineDb 推荐日常使用,Pg 生态,复杂 join、访问外部数据方便
- 借助数据总线 Flink 和 Pg/pipelineDb 可以轻松整合
开放架构
这一部分落实 “无边界”大数据平台的想法
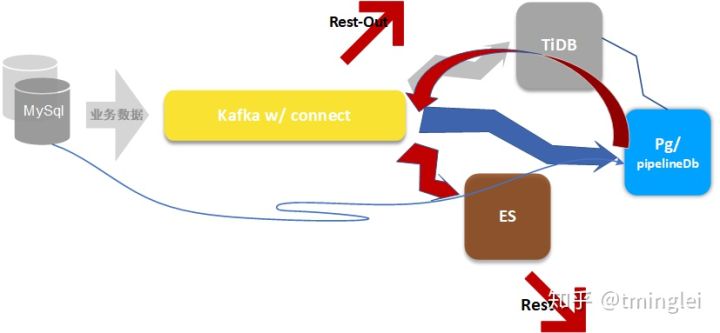
核心组件服务化,
- Kafka 服务化,数据直写&消费
- Spark 服务化,计算资源开放
- TiDB、Pg 通过 JDBC 服务化
- ES 通过 Rest 接口服务化
开放架构让大数据平台融入业务系统,同时通过流处理业务逻辑也可以托管在大数据平台上。
说不好 是业务系统选择了大数据平台,还是大数据平台融化了业务系统。用一个词描述可能更合适,那就是 “平台化”。
案例-运营策略优化
这是公司客户关系管理委员会提出的一个项目,其基本想法是,根据不同地方持续收集的用户及行为数据,进行客群细分(营销阶段、用户意愿等),据此作出营销决策(流转,手段等),执行/反馈,并不断作出评价和改进。
营销决策由CRM系统负责,客群细分在大数据平台上进行。
落实方式其实是用户画像,分为相对稳定部分和实时变化部分。数据分析团队负责稳定部分的用户标签,通过每日的全量脚本作业在Hive上运行实现;大数据团队负责实时部分的用户生命周期、导流状态等,在 Pg/pipelineDb 上开发实现。两份数据最终同步到ES,在那里合并后等待CRM系统使用。
为了更好的适应用户操作及系统事件,还同时做了用户事件处理,对不同来源的相关数据做出处理后生成用户事件,实时推送给CRM系统。事件处理在 Pg/pipelineDb 里进行,生成结果通过 Kafka-rest http API 提供给 CRM系统实时消费。
基础数据架构
前面讲述的各个架构有一个共同点,那就是都跟业务数据有关。这个不太一样,它是关于基础数据的。
何谓基础数据,指的是非业务逻辑产生的日志、监控、链路追踪这些基础设施和运行时系统自身的数据。而作为业务的基础数据,则包括采集、可靠传输、存储、融合,以及基于这些数据的衍生系统和业务。

基础数据架构要点如下,
- 采集端,整合日志、监控、tracing SDK(融合,traceId 嵌入日志)
- 传输网络,为日志、监控、tracing 数据提供统一传输(缓存,数据加工,智能路由 等)
- 总线&入库,为大规模实时数据分析提供便利
- 存储体系,ES 支持日志分析,Pg w/ timescaleDb 支持监控数据分析(扩展的 Pg SQL 语法&函数,可自由关联外部数据)
- 监控&配置管理(基础数据体系本身也需要监控,并且需要集中的配置管理)
业务数据 + 基础数据,交叉融合,是我构想的双剑合璧、数据大融合。关于基础数据的应用我有很多构想,这里不作展开。
写在最后
存储、计算、融合、治理。
存储、计算一般可通过选择避免研发,但融合、治理还是得自己操心。
上述描述很好的解决了数据融合问题,但对数据治理没怎么触及。
我们目前对数据治理作的直接研发不多,但已经做了很好的铺垫了。
数据治理的核心数据血缘方案一个常见的思路,是四处搜集/提取数据集、数据转换相关的元数据信息,把他们拼接、呈现出来就是我们期望的数据血缘关系图了。
上述做法很巧妙的把很多数据表定义、数据处理逻辑集中化、文本化了,这种情况下的爬取、分析,比起源码扫描分析、日志扫描分析、数据文件分析等等,要简便了多少?
实际上,由于 kafka connect、mysql、pg、hive、airflow 等已有了还算可以的元数据管理功能,我们目前对专门开发元数据管理系统的需求不是很大。
平台性能方面,日入库/处理数据量 3~4 亿条(几十GB)的样子,迁机房造成大量重生数据时达到过 20多亿条/天,我们在自建机房的物理机总数量 20台左右。增加资源肯定能提升性能,根据我在前东家网宿处理更大规模数据量的经验,百亿级别的数据量应该不用调整架构。
平台运维方面,我们做了 Schema 自适应调整、自动检查修复、故障隔离、故障重启、监控/预警、数据质量报告等,所以,不出意外的话,日常运维还是比较省心的。
以上,建成的大数据基础平台其实是一套穷人的大数据平台,以较低的门槛便捷的满足各种应用场景的需求,并可以随着业务壮大做出调整和优化。愿平台后续的运营者使用愉快!