

写冲突场景下的悲观/乐观事务模型选择
乐观/悲观模型是数据库常用的2种事务模型,首先从字义上对2种事务模型进行简单区分,比如我要更新Table中的一行数据,乐观模型就是“乐观”的认为不会有其他事务也同时更新同一行数据,所以拿数据时不用加锁,最后在提交时才判断下是否有同时更新的事务。悲观模型就是“悲观”的认为会有其他事务会更新我要更新的数据,所以会在拿数据时就会加锁,这样保证自己更新时数据不会被别人再修改。
乐观/悲观事务模型的大部分使用场景:读多写少+写冲突少用乐观模型,写多读少+写冲突多用悲观模型。如果事务模型选择的“不合适”,比如高并发+写冲突高的情况下采用乐观模式,大量的retry将会带来写入的性能严重下降。本文会结合具体业务场景中遇到的写入性能瓶颈,结合TiDB的乐观事务和悲观事务,通过压测数据给出合适的选择。
关键词:分区表,写冲突,悲观/乐观事务
业务场景介绍
业务简介
广告主实时监控业务,提供了广告的各个维度的消费监控数据,会以报表的方式在广告主报表平台提供给广告主实时查看,使得金主们能及时查看到广告的效果以及预算花费情况,360内部的产品和运营也会及时关注消费和广告效果数据,通过监控可以及时的发现和反馈问题,对广告投放或者推荐算法调优后实现广告主化最少的钱到达最好的广告效果。
业务架构
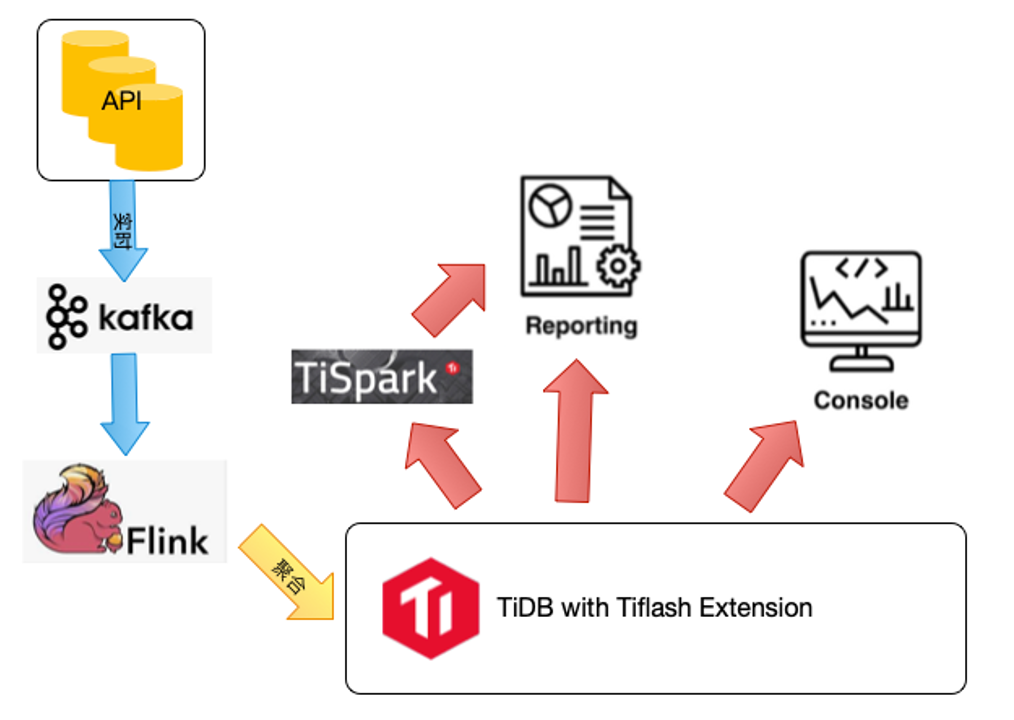
API日志(各种广告web节点和曝光日志/SDK日志)->kafka->Flink->TiDB
写入流程是:业务数据首先进入 Kafka,每 10~30 秒会有程序读 Kafka 数据,并通过flink聚合后生成当前批次的数据写入到 TiDB 中,每批次会有几十万的写入,采用的是TiDB按时间的分区表才存数据,一般保持30天,单分区数据量千万~亿。
业务的写入瓶颈
- 业务写入 SQL 主要是:insert on duplicate key update,Batch size为 50(相当于单SQL一次insert 50个values),单表写入并发10~30。insert on duplicate key update在insert时一旦表中有了跟唯一索引匹配的数据,就触发update操作。在分区写入初期由于没有重复的 uniq_key,所以主要是 insert。随着数据量增加,update 的操作也越来越多,insert:update大概1:10+。
- 虽然写入TiDB之前有一层flink聚合操作保证单批次的insert SQL中不会有冲突的记录,但是由于有多个写入流,多个写入流之间不保证没有duplicate key,并且单批次的聚合时间在秒级别,如果单批次的数据没有及时写入TiDB,下一个批次的数据也来了,这时TiDB中就有大量的写冲突的SQL在执行。
上面描述的SQL使用以及多并发写入流导致的写冲突,非常容易引发在流量高峰时TIDB的写入性能下降,导致kafka的lag挤压,客户不能及时看到广告的效果,影响广告主的投放,从而影响公司的收入。
TiDB乐观事务模型

TiDB 中分布式事务实现一直使用的是 Percolator 的模型,采用2PC(两阶段提交)实现,2PC主要分Prewrite和commit这2个阶段。大概的流程是:客户端开启事务,执行DML,客户端发起commit,下面开始2PC的prewrite阶段:TiDB 从当前要写入的数据中选择一个 Key 作为当前事务的 Primary Key,TiDB 并发地向所有涉及的 TiKV 发起 prewrite 请求,TIKV则进行检测后将满足条件的数据加锁。TIDB收到prewrite成功响应,TIDB向PD请求事务commit_ts,下面进入2PC的commit阶段:TIKV收到commit操作并check后执行commit(keys,commit_ts),并且清理prewrite的锁,TIDB收到2PC commit成功的信息并且反馈给客户端。
优点:事务最终提交 commit 时才会检测冲突,在事务提交的过程中锁检测的代价是比较大的,所以乐观事务在一些场景有较好的写入提升。比如基于id自增主键的写入情景,或者有唯一索引但是很少或者不会出现多个并发同时对同一个行的DML操作的情景。
缺点:事务冲突不可避免,乐观模式采用了内部重试功能。由下面2个参数控制:
tidb_disable_txn_auto_retry:这个参数控制是否自动重试,默认为 1,即不重试。
tidb_retry_limit:用来控制重试次数,默认10次,注意只有第一个参数启用时该参数才会生效。
重试的好处,写冲突的情况避免直接报错给client。重试的缺点:每次重试时间间隔会逐渐变长,写冲突高的情况下,一条SQL可能需要较长时间才能写入成功,另外TiDB 默认不进行事务重试,因为重试事务可能会导致更新丢失,从而破坏可重复读的隔离级别。
注意:
- TiDB从3.0才支持悲观事务,所以在V3.0.8之前都是默认乐观模式
- 如果集群是3.0.8之前的版本,升级到3.0.8+版本也是采用之前版本默认的乐观模式。
TiDB悲观事务模型

TiDB 在乐观事务模型的基础上支持了悲观事务模型,将上锁的时机提前到进行DML时。TiDB 的悲观锁实现的原理确实如此,在一个事务执行 DML (UPDATE/DELETE) 的过程中,TiDB 不仅会将需要修改的行在本地缓存,同时还会对这些行直接上悲观锁,这里的悲观锁的格式和乐观事务中的锁几乎一致,但是锁的内容是空的,只是一个占位符,待到 Commit 的时候,直接将这些悲观锁改写成标准的 Percolator 模型的锁,后续流程跟乐观模型一样。
开启条件:
(1)TiDB V3.0.8+新集群,或者tidb_txn_mode = ‘pessimistic’;
(2)业务端写入时采用“显示事务”(通过 [BEGIN|START TRANSACTION]/COMMIT 语句定义事务的开始和结束)。
注意:要想使用TiDB的悲观模式上面2个条件缺一不可。
写冲突情况下的测试流程
测试环境
- TIDB版本:V4.0.9
- 集群配置:2tidb+2pd+3tikv(tidb/pd共用服务器)
- 硬件配置:
cpu:E5-2630v2 2;
mem:16G DDR38;
disk: 系统盘300G Intel S3500 SATA SSD1; 数据盘flash:曙光 INTEL P4600 2.0T 1;
net:板载双网口千兆电网卡1;
power:单电源1;
测试用例
分区表
`CREATE TABLE dxl_test_cost (
id bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT ‘自增id’,
metric_request_all bigint(20) NOT NULL DEFAULT ‘0’,
metric_clicks bigint(20) NOT NULL DEFAULT ‘0’,
metric_views bigint(20) NOT NULL DEFAULT ‘0’,
/此处省略多个字段
dsp_type tinyint(4) unsigned NOT NULL DEFAULT ‘0’,
place_id int(11) unsigned NOT NULL DEFAULT ‘0’,
adspace_id int(11) unsigned NOT NULL DEFAULT ‘0’,
service_type tinyint(4) unsigned NOT NULL DEFAULT ‘0’,
adspace_prop int(11) unsigned NOT NULL DEFAULT ‘0’,
deal_mode tinyint(4) NOT NULL DEFAULT ‘-1’,
gray_version tinyint(4) NOT NULL DEFAULT ‘-1’,
user_client_category tinyint(4) unsigned NOT NULL DEFAULT ‘0’,
publisher_id bigint(10) NOT NULL DEFAULT ‘0’,
create_date date NOT NULL DEFAULT ‘2000-01-01’,
time_solt time NOT NULL DEFAULT ‘-01:00:00’,
create_time timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (id,create_date) ,
UNIQUE KEY idx_product_metric (adspace_id,time_solt,dsp_type,deal_mode,user_client_category,gray_version,create_date)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin AUTO_INCREMENT=25864263174
PARTITION BY RANGE COLUMNS(create_date) (
PARTITION p20210410 VALUES LESS THAN (“20210411”),
PARTITION p20210411 VALUES LESS THAN (“20210412”),
/次数省略了按天的分区
PARTITION p20210508 VALUES LESS THAN (“20210509”),
PARTITION p20210509 VALUES LESS THAN (“20210510”)
);
写入SQL列举:INSERT INTO dxl_test_cost
(
create_date,
time_solt,
dsp_type,
place_id,
adspace_id,
service_type,
adspace_prop,
deal_mode,
gray_version,
user_client_category,
publisher_id,
metric_request_all,
/此处省略了多个指标字段
metric_clicks,
metric_views
) VALUES (‘2021-05-06’,‘16:10’,1,xx,xxx,1,1,0,0,2,xxx,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0)
。。。。。。。。。。。。。。50条values
,(‘2021-05-06’,‘16:15’,1,xxx,xx,1,1,0,0,2,xxxx,0,0,0,0,0,0,0,0,0,0,0,0,0,33,0,0)
,(‘2021-05-06’,‘16:15’,1,xxx,xxx,1,1,0,1,2,xxxxx,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0)
ON DUPLICATE KEY UPDATE metric_request_all=metric_physical_request_all+values(metric_request_all),
/此处省略了多个指标更新
metric_clicks=metric_clicks+values(metric_clicks),
metric_views=metric_views+values(metric_views)
`
测试过程
(1)10个并发;默认乐观提交:tidb_txn_mode=pessimistic + Autocommit
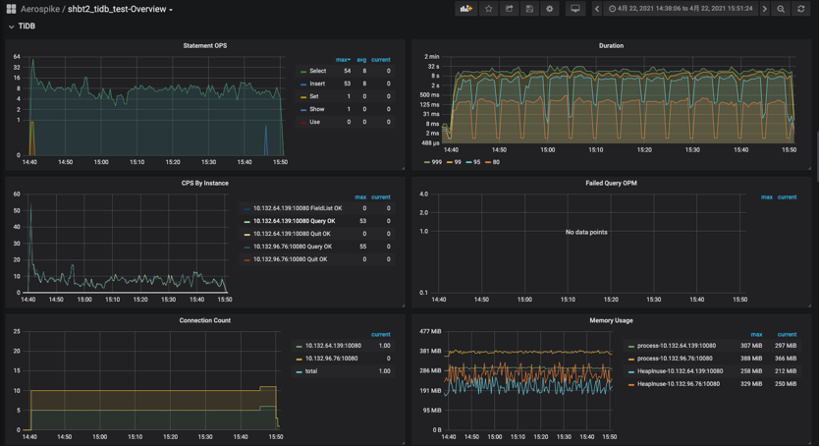
结果:QPS平均8,最高50左右,SQL执行时间2~10s,其实从tidb的日志来看有大量的SQL retry操作导致的写入性能不好。
注:本次乐观模式测试开启了tidb本身的自动重试(tidb_disable_txn_auto_retry=0,并且重试次数为10),目的就是业务端默认重试3次,没有开启重试前,业务重试3次也写入不成功,导致大量的写入失败,需要靠tidb的自动重试来保证数据能写入。
(2)10个并发;悲观模式提交:tidb_txn_mode=pessimistic + Autocommit=off(开启显示事务)
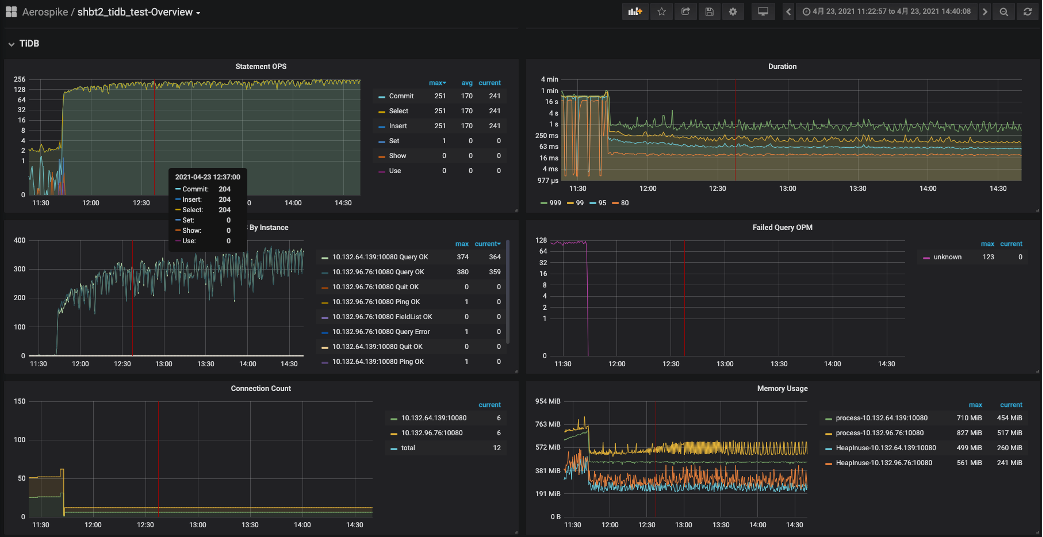
悲观模式下10个并发的写入性能:QPS平均170,最高能到251,SQL执行时间50~100ms,写性能比乐观模式提升10+倍。
测试结论
本次模拟的场景就是并发+写冲突场景下的乐观和悲观事务模式性能对比,发现悲观事务模式的写入性能比乐观事务模式提升了10+倍的性能,主要问题还是:写冲突高的情况下乐观模式的自动重试策略导致的写入延迟增加,悲观模式通过加锁的方式避免了重试的代价,在一定程度上提升了写入的性能。
注意:在写冲突+悲观模式的情况下,建议控制好并发,在一定的并发内提升并发可以继续提升写入,在我的环境下并发超过50时会产生大量的锁等待超时/死锁报错(过犹不及)。