

Gravity 简介
Gravity 是一款数据复制组件,提供多数据源的全量、增量数据同步,以及向消息队列发布数据更新。
通过Gravity可实现数据中台、大数据总线、数据库不停服迁移、分库分表合并、微服务拆分的数据库实时双向同步、数据清洗等众多业务场景。
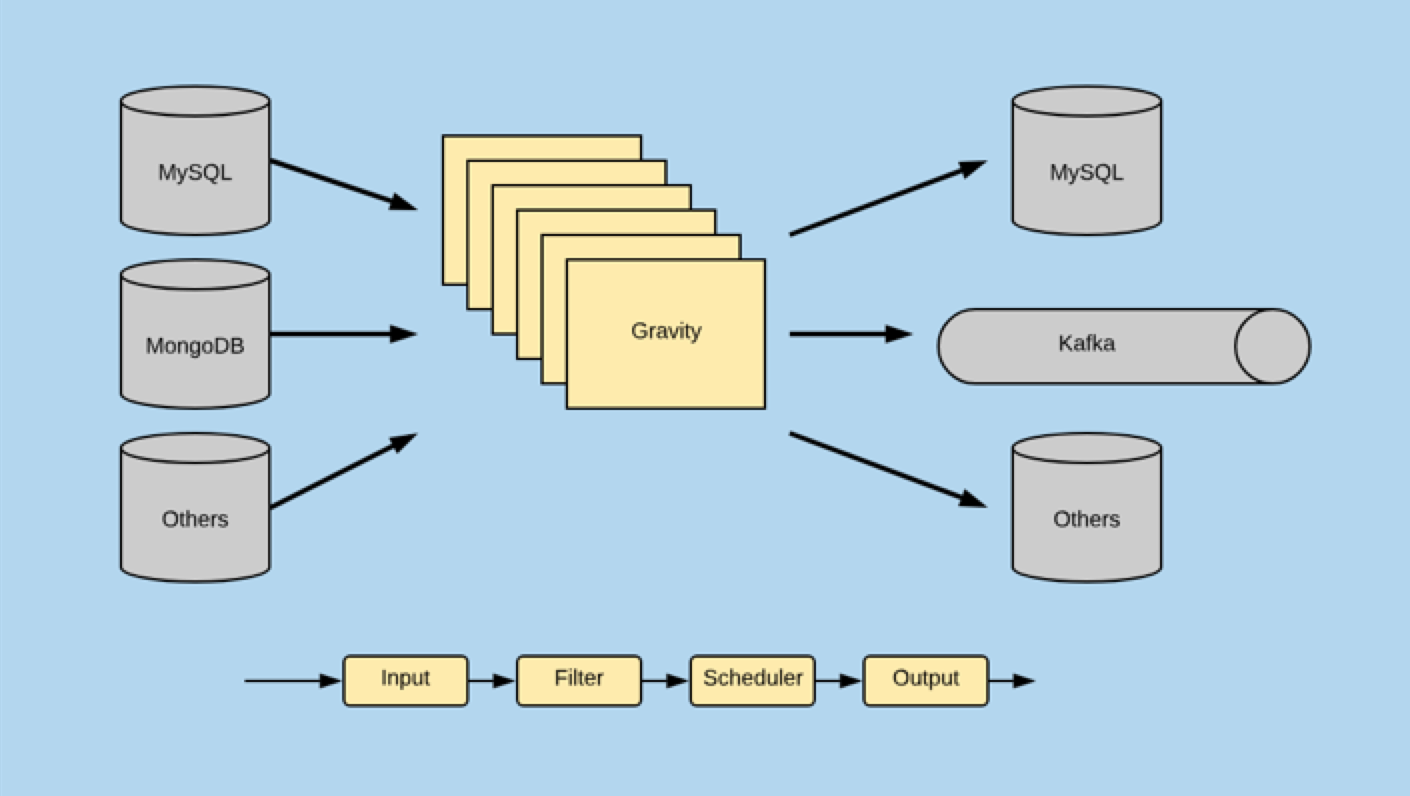
支持多种数据源和目标的,可灵活定制的数据复制组件
多数据源
- MySQL(全量、增量、全量+增量)
- MongoDB(增量)
- TiDB
多目的端
- MySQL
- Kafka
- Mongo
- TiDB
- ES
Cloud Native:
- K8S Operator调度,服务化管理
- 基于 Kubernetes 的 PaaS 平台,简化运维任务
插件化
- 通过插件化,实现各模块间灵活的组合
Gravity 单进程架构设计
单进程的 Gravity 采用基于插件的微内核架构,由各个插件围绕系统里的 core.Msg 结构实现输入到输出的整个流程。
type DDLMsg struct {
Statement string
}
type DMLMsg struct {
Operation DMLOp
Data map[string]interface{}
Old map[string]interface{}
Pks map[string]interface{}
PkColumns []string
}
type Msg struct {
Type MsgType
Host string
Database string
Table string
Timestamp time.Time
DdlMsg *DDLMsg
DmlMsg *DMLMsg
...
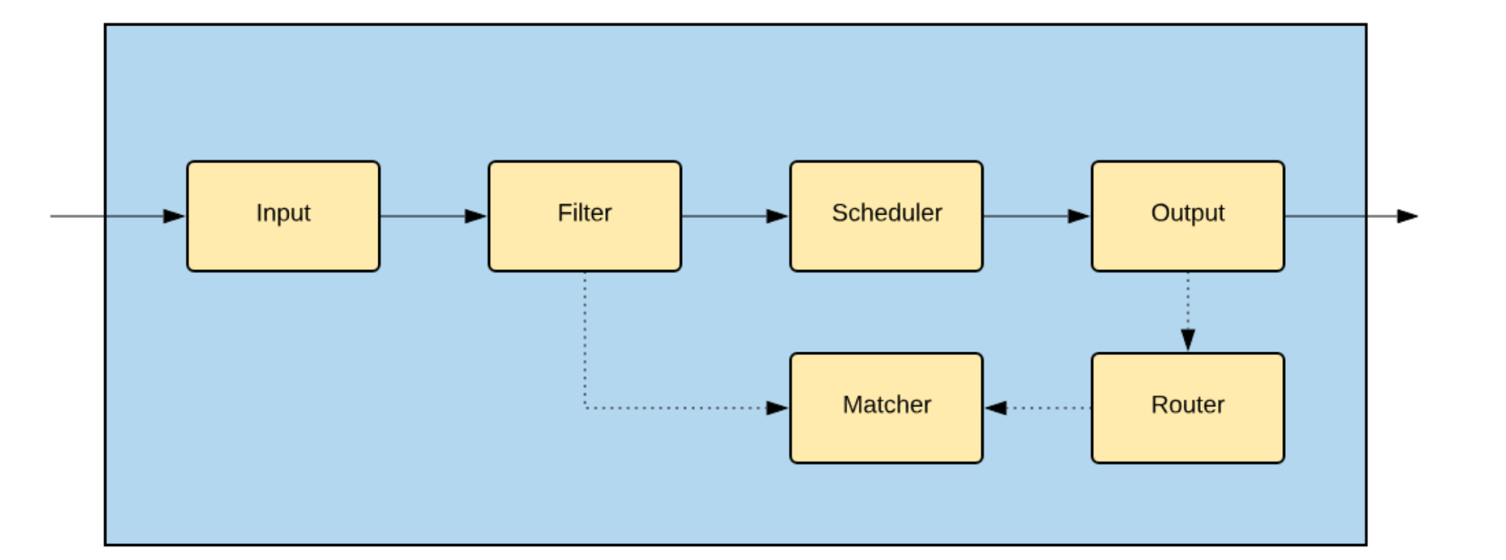
如上图所示,系统总共由这几个插件组成,各个插件有各自独立的配置选项:
- Input 用来适配各种数据源,比如 MySQL 的 Binlog 并生成
core.Msg - Filter 用来对 Input 所生成的数据流做数据变换操作,比如过滤某些数据,重命名某些列,对列加密
- Output 用来将数据写入目标,比如 Kafka, MySQL,Output 写入目标时,使用 Router 所定义的路由规则
- Scheduler 用来对 Input 生成的数据流调度,并使用 Output 写入目标;Scheduler 定义了当前系统支持的一致性特性(当前默认的 Scheduler 支持同一行数据的修改有序)
- Matcher 用来匹配 Input 生成的数据。Filter 和 Router 使用 Matcher 匹配数据

Input模块介绍
Input模块共有3种工作模式:
- batch(仅同步全量)
- stream (仅同步增量)
- replication 全量同步完成自动进入增量
注:Gravity对上游MySQL的配置要求 enforce-gtid-consistency=ON gtid-mode=ON binlog_format=ROW
Filter模块

原生代码、GRPC plugin
- 原生支持:reject 忽略匹配的源端消息
- 原生支持:delete-dml-column 删除源端 DML 消息里的某些列
- 原生支持:rename-dml-column 重命名源端 DML 消息里的某些列
- 支持用户自定义的的GRPC plugin
一致性保证
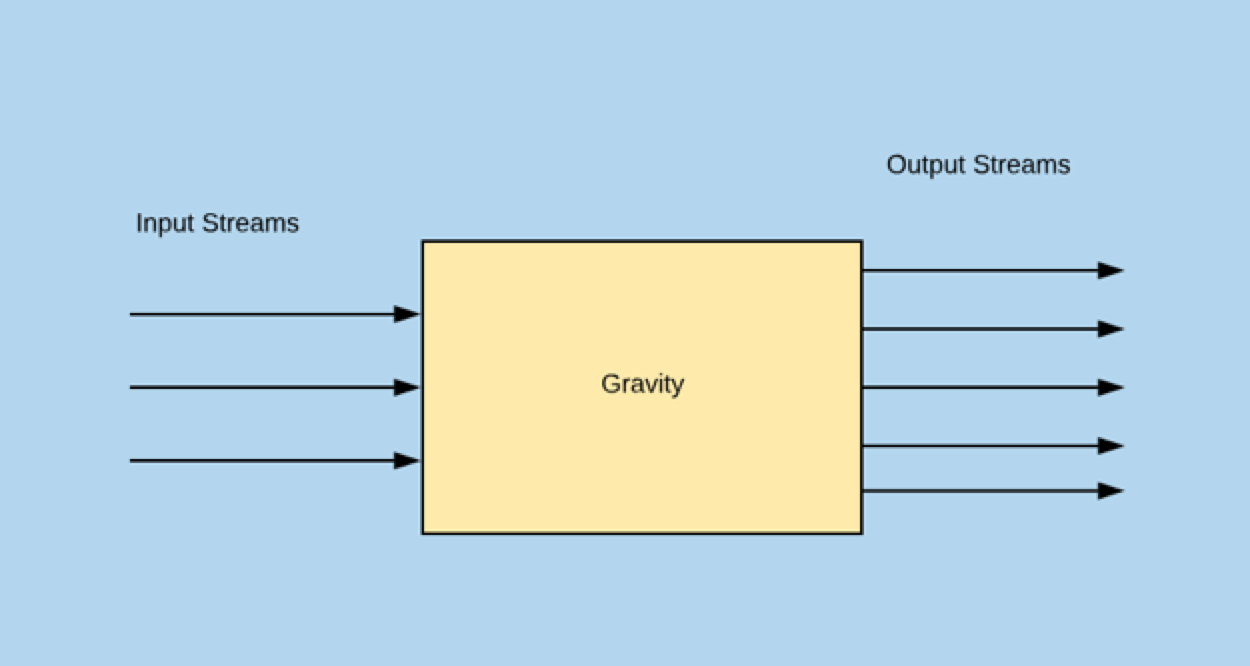
同一主键或唯一键有序,行级并发
- 通过主键或者唯一键进行hash,保证相同行的修改进入同一个go routine
- 没有主键或者唯一键,受限于max-full-dump-count
Output模块

通过Route与Matcher配合,可实现动态和静态路由,支持如下场景:
- 支持库/表rename
- 支持分表合并操作
双向复制
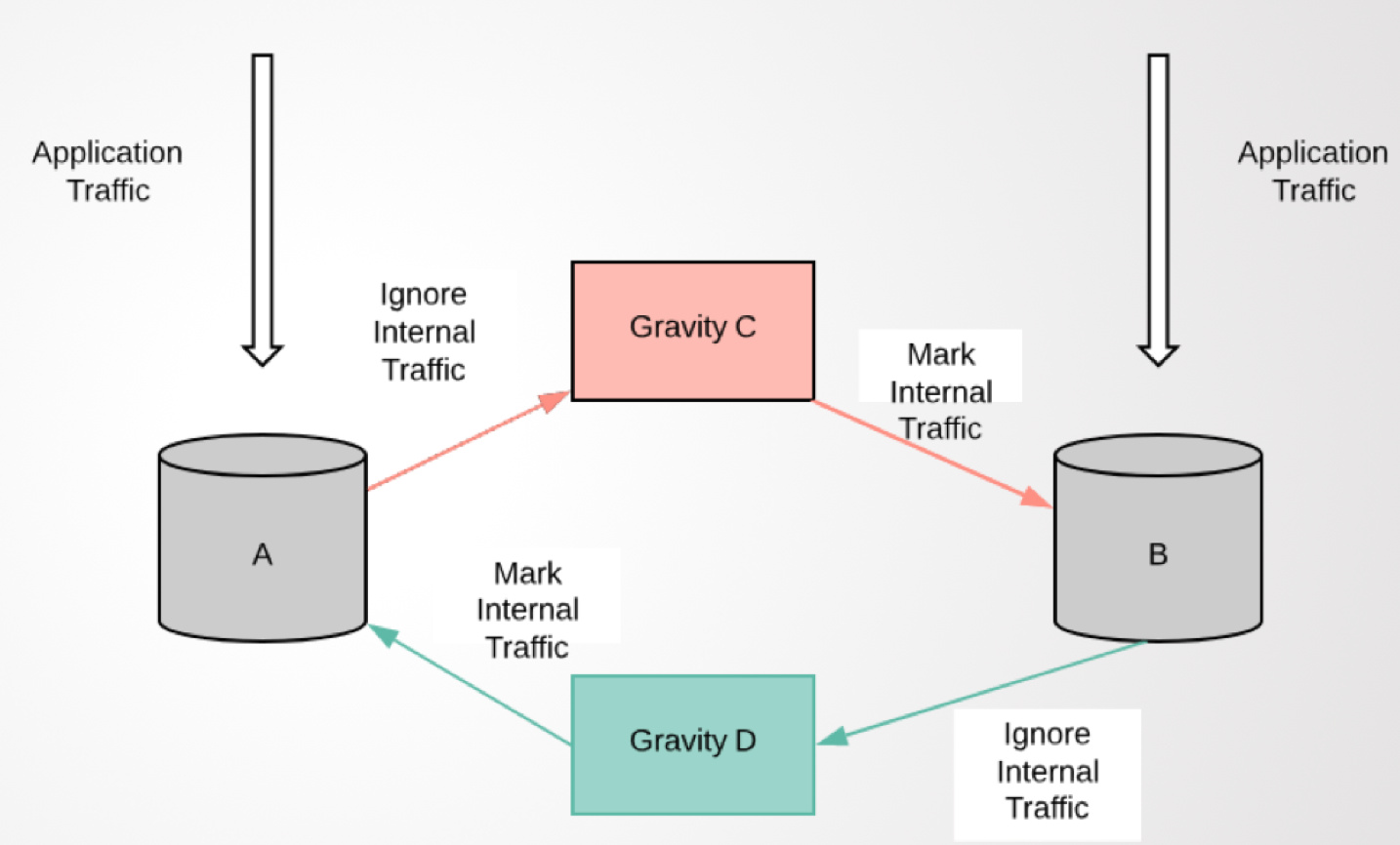
原理:
- 将经过Gravity的SQL和内部表封装成事务
- 收到 binlog 后检测内部表是否包含改事务,有则忽略
- fail-on-txn-tags 这个选项加了一个检查,除了内部表的名字,还看了一下内部表里特殊的一个 column(用来标识是哪个 pipeine 写入的)
集群架构
安装:
helm install --name gravity-operator ./
架构
- 安装集群、升级集群
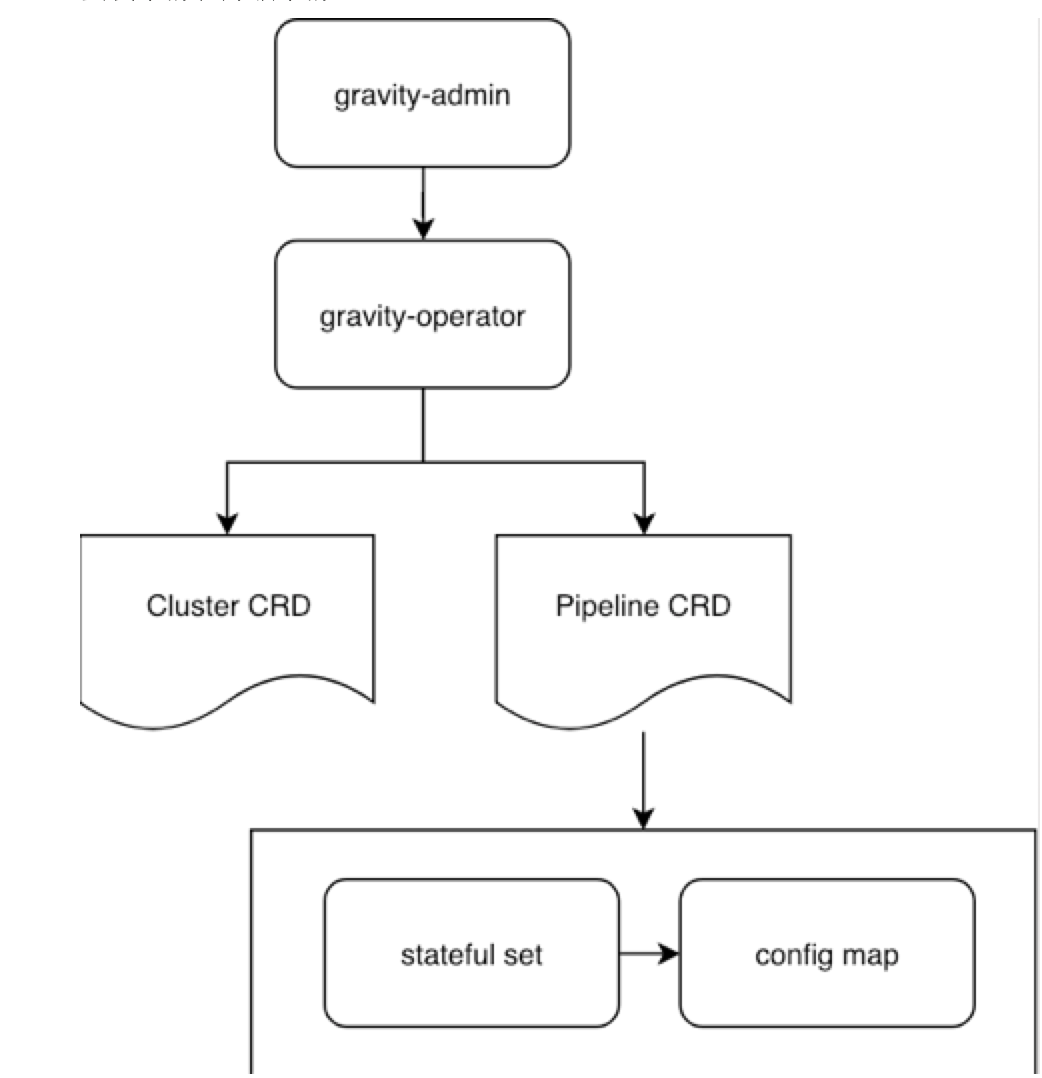
灵活的版本管理:
- CRD 管理集群(k8s自定义资源扩展API)
- Stateful set 防止脑裂

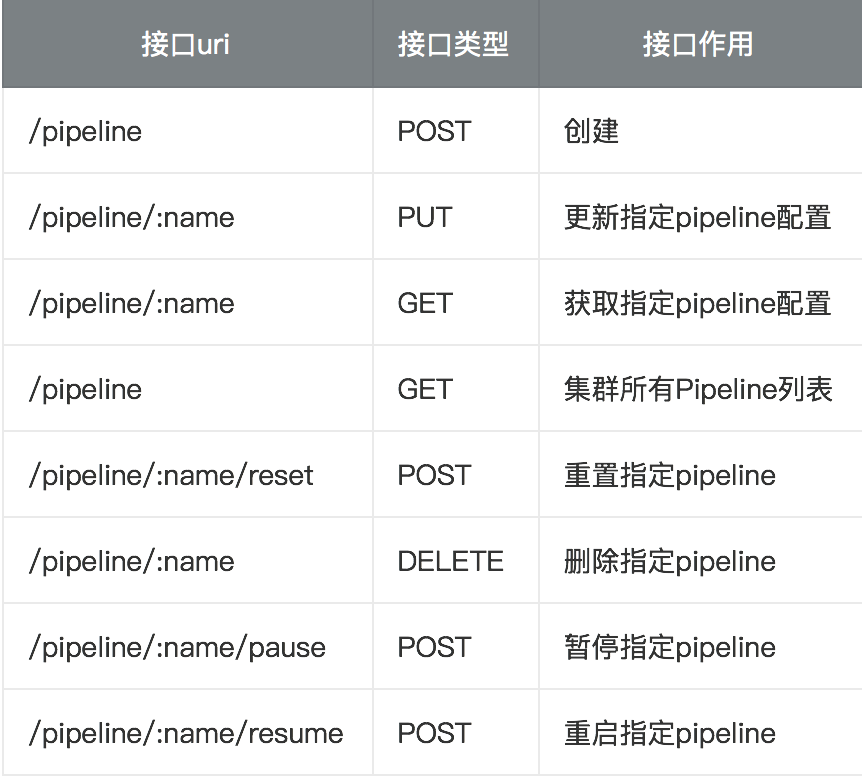
丰富的API
经典场景1
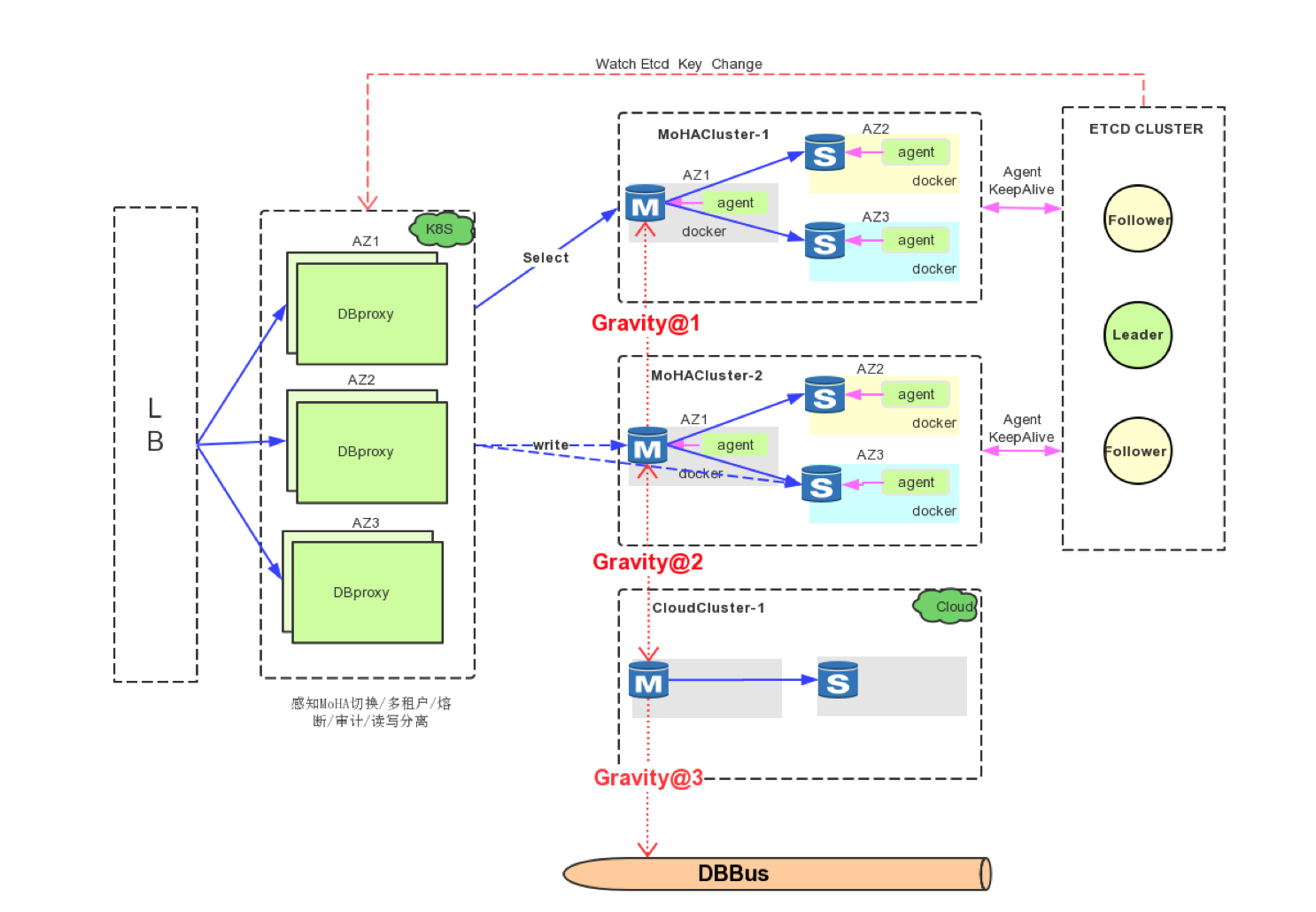
- Gravity@1:数据冷热分离场景 大支付流水场景,业务对于表的操作又包含事务以及联表查询。短期解决数据容量问题就可以通过Gravity中配置禁止delete操作路由到下游归档库(TiDB),来实现业务数据的冷热分离
- Gravity@2:混合云双向同步场景 对于混合云部署或数据迁移场景,传统的数据同步工具只支持单向数据同步。Gravity支持双向同步,能够对业务实现更加友好的迁移。另外gravity通过内部事务标签及pipeline名称,防止循环复制。
- Gravity@3:大数据同步场景 向第三方服务提供实时数据订阅功能。用户能根据自身业务需求自由消费增量数据,实现例如缓存更新策略等多种业务场景。
经典场景2
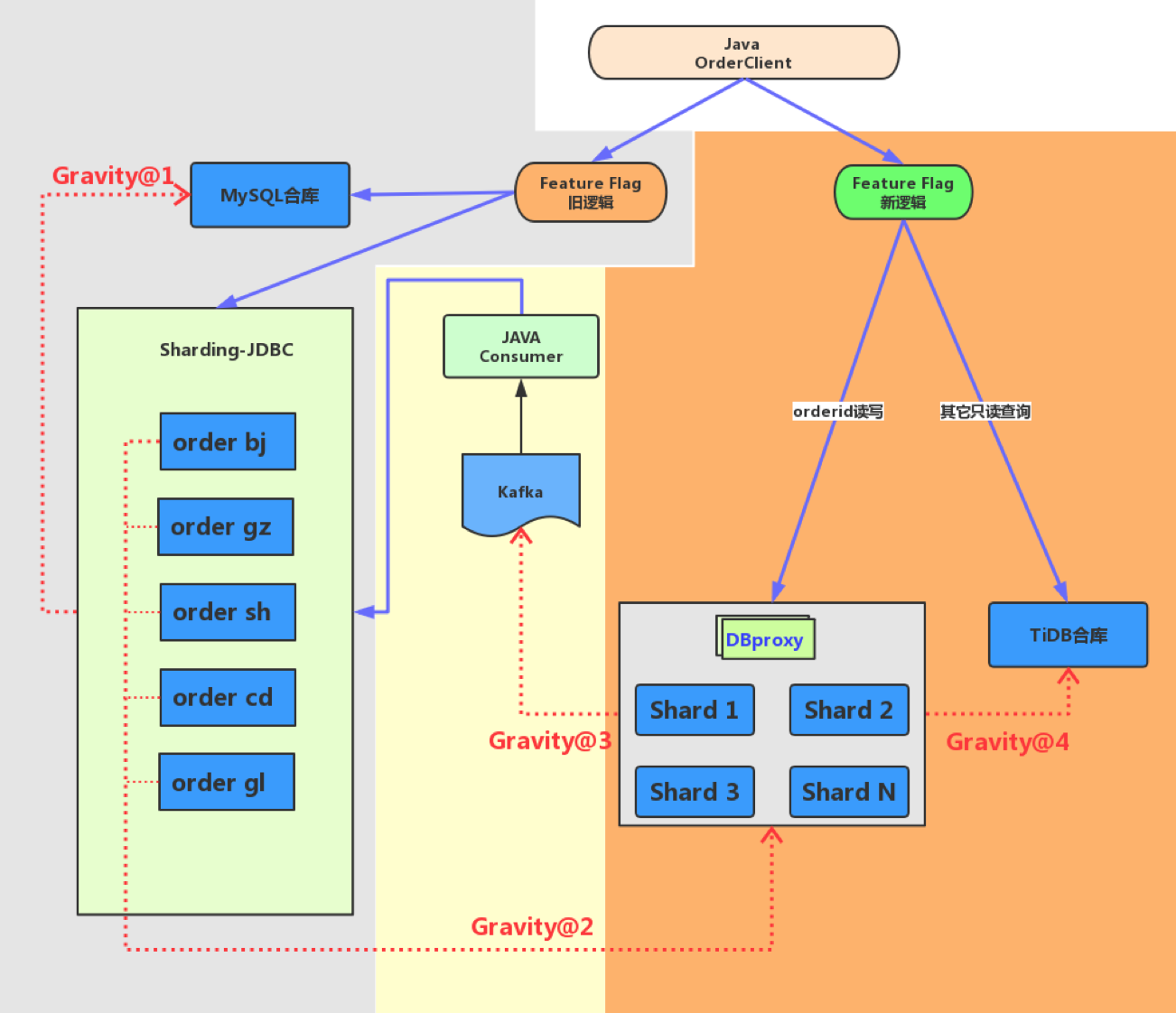
背景
左侧为按照城市分库的sharding集群,右侧是按照orderid取模的新sharding集群。
老方案存在的问题
- 订单合库数据量持续增长,合库单机容量已经不足以支撑业务发展需求
- 热点城市访问量大,单实例故障,影响面大
- 数据分布不均匀
新sharding集群按照order_id取模通过DBproxy写入各分表,解决数据分布不均、热点等问题
- gravity@2: 同步老分库数据到新分库 使用gravity的replication模式将老sharding集群数据同步到新集群,并将增量数据进行打标,反向同步链路忽略带标记的流量,避免循环复制
- gravity@3: 订阅分库数据到Kafka 为支持业务恢复及回滚,且数据写老的sharding集群带业务逻辑;Gravity将新集群产生的订单数据同步到Kafka,由业务组件负责消费,并更新回老集群
- gravity@4: 同步分库数据到合库 新的TiDB集群作为订单合库,使用gravity从新sharding集群同步数据到TiDB
运维管理平台
- 支持Pipeline创建
- 支持Pipeline删除
- 支持Pipeline修改
监控平台
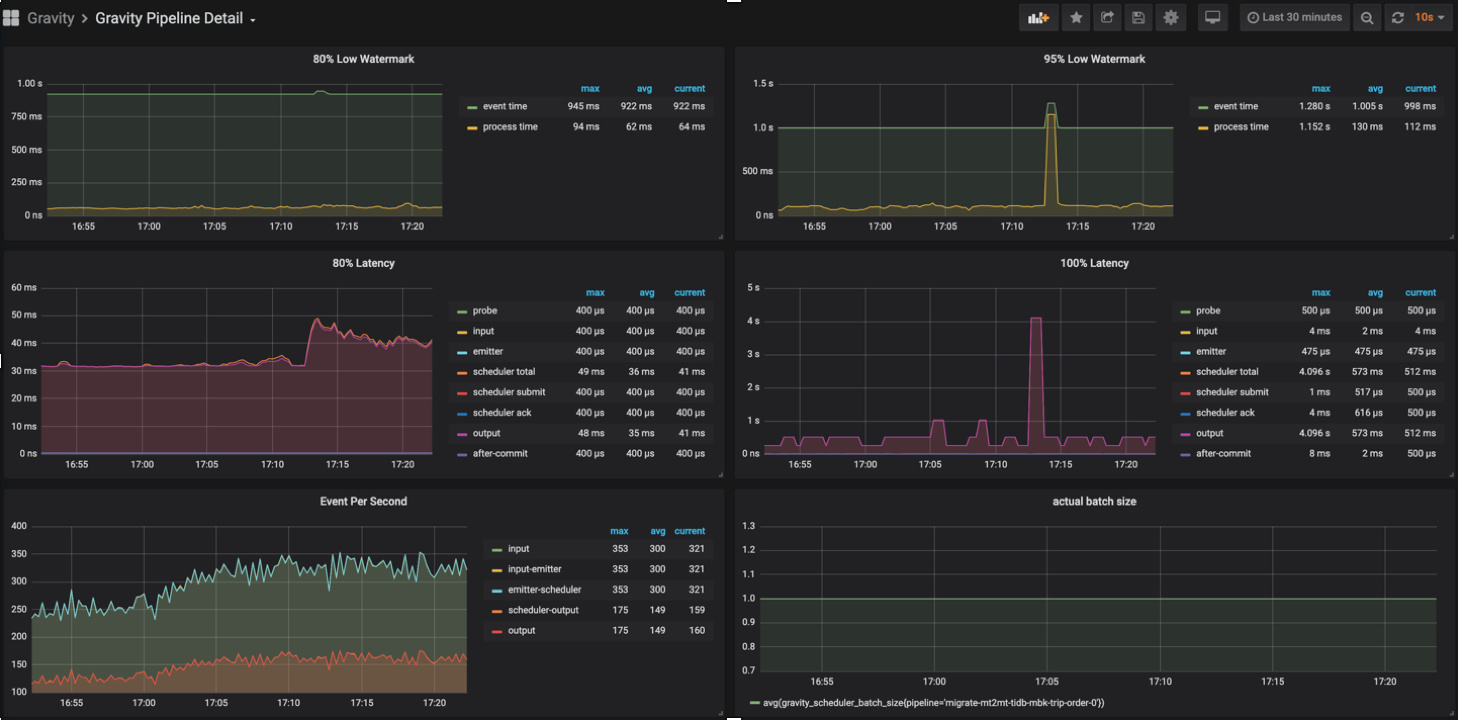
- 支持端到端的延迟监控
- 支持表级别流量监控
- 支持pipeline运行状态检测