

[toc]
理解Raft复制状态机才能更好的理解TiKV引擎,后续分成三篇文章由浅入深来逐步讲解Raft相关的内容:
- Raft复制状态机
- TiKV中的Multi Raft
- TiKV中关于Raft的优化
本文重点介绍Raft的入门基础,也就是Raft的复制状态机。
1. Raft背景以及基础概念
1.1 Raft提出背景
分布式存储系统通常通过维护多个副本来进行容错,提高系统的可用性。要实现此目标,就必须要解决分布式存储系统的最核心问题:维护多个副本的一致性。
首先需要解释一下什么是一致性(consensus),它是构建具有容错性(fault-tolerant)的分布式系统的基础。 在一个具有一致性的性质的集群里面,同一时刻所有的结点对存储在其中的某个值都有相同的结果,即对其共享的存储保持一致。集群具有自动恢复的性质,当少数结点失效的时候不影响集群的正常工作,当大多数集群中的结点失效的时候,集群则会停止服务(不会返回一个错误的结果)。一致性协议就是用来干这事的,用来保证即使在部分(确切地说是小部分)副本宕机的情况下,系统仍然能正常对外提供服务。
1.2 TiKV为什么选择Raft?
- Raft 提供了线性一致性的保证,适合数据库等一致性要求高的系统。
- Raft过半节点失败不可用,延迟稳定,适合事务处理;对比全部节点失败才不可用,
- 工程实现成熟,实现简单。
- 选举算法、成员变更算法实现细节完备。
1.3 Raft基础概念
1.3.1 Raft复制状态机
一致性协议通常基于复制状态机,即所有结点都从同一个状态出发,都经过同样的一些指令,最后到达同一个状态。复制状态机用于解决分布式系统中的各种容错问题,例如具有单个Leader的大规模系统,GFS、HDFS等等通常使用单独的复制状态机来进行Leader的选举和存储Leader崩溃后重新选举需要的配置信息。Chubby、Zookeeper等都是复制状态机。复制状态机要能容忍很多错误场景。复制状态机的典型实现是基于复制日志,如下图所示:
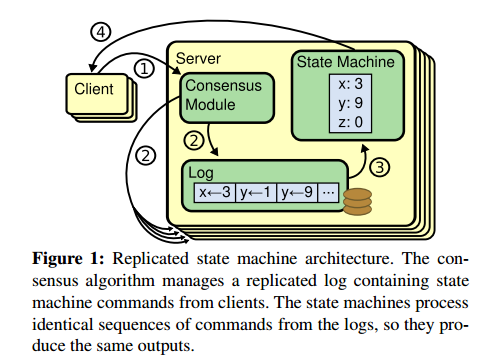
复制状态机包含了三个组件:
状态机: 当我们说一致性的时候,实际就是在说要保证这个状态机的一致性。状态机会从日志里面取出所有的命令,然后顺序执行一遍,得到的结果就是我们对外提供的保证了一致性的数据。
Log: 保存了所有修改指令的日志。
一致性模块: 一致性模块算法就是用来保证写入的日志的一致性,这也是Raft算法核心内容。
状态机可以理解为一个确定的应用程序,所谓确定是指只要是相同的输入,那么任何状态机都会计算出相同的输出。至于如何实现日志完全一致的复制,则是Raft一致性模块(Consensus Module)需要做的事。
每个节点上存储了一个包含一系列指令的日志,复制状态机按序执行这些指令。每一个日志在相同的位置存放相同的指令,所以每一个状态机都执行了相同序列的指令。
1.3.2 Raft节点状态
Raft的节点被称为peer,节点的状态是Raft算法的关键属性,在任何时候,Raft节点可能处于以下三种状态:
- Leader:Leader负责处理客户端的请求,同时还需要协调日志的复制。在任意时刻,最多允许存在1个Leader,其他节点都是Follower。注意,集群在选举期间可能短暂处于存在0个Leader的场景。
- Follower:Follower是被动的,它们不主动提出请求,只是响应Leader和Candidate的请求。注意,节点之间的通信是通过RPC进行的。
- Candidate:Candidate是节点从Follower转变为Leader的过渡状态。因为Follower是一个完全被动的状态,所以当需要重新选举时,Follower需要将自己提升为Candidate,然后发起选举。
下图展示了这些状态以及它们之间的转化:
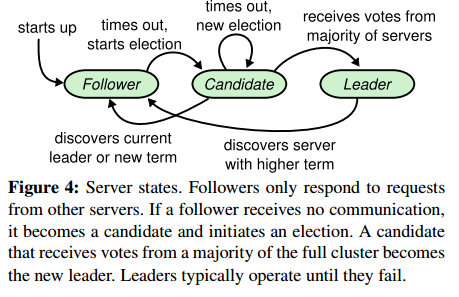
从状态转换图可以看到,所有的节点都是从Follower开始,如果Follower经过一段时间后收不到来自Leader的心跳,那么Follower就认为需要Leader已经崩溃了,需要进行新一轮的选举,因此 Follower的状态变更为Candidate。Candidate有可能被选举为Leader,也有可能回退为 Follower。如果Leader发现自己已经过时了,它会主动变更为Follower。Leader如何发现自己过时了?下文会引入Term继续分析。
1.3.3 Term
Raft的一个关键属性是任期(Term),在分布式系统中,由于节点的物理时间戳都不统一,因此需要一个逻辑时间戳来表明事件发生的先后顺序,Term正是起到了逻辑时间戳的作用。Raft的运行过程被划分为一系列任意长度的Terms,一次Leader选举会开启一个新的Term,如下图所示:
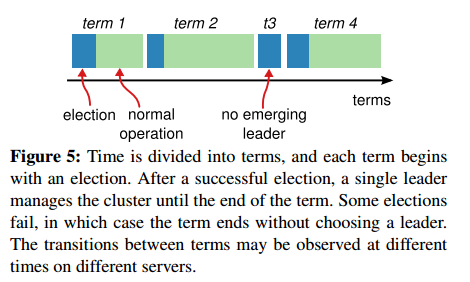
Terms有连续单调递增的编号,每个Term开始于选举,这一阶段每个Candidate都试图成为Leader。如果一个Candidate选举成功,它就在该Term剩余周期内履行leader职责。一次Term 也可能选不出Leader,这是因为可能多个Candidate都获得了相同数量的选票,此时下一次会进行下一次选举。
每个节点都会维护自己当前的Term(Current Term),并且持久化存储 Current Term。当Leader宕机后再恢复,Leader仍然会认为自己是Leader,除非发现自己已经过时了。节点利用Current Term判断过时的信息。节点的Term在节点之间通信时改变:如果某个节点的当前Term小于其它节点,那么这个节点必须更新它的Term,与集群其他节点保持一致;如果一个Candidate或者Leader发现自己的Term过期,它就必须要放下身段变成Follower;如果某个节点收到一个过时的请求(拥有过时的Term),它会拒绝该请求。
目前我们需要知道的是Term在Raft中是一个非常关键的属性,Term始终保持单调递增,而Raft认为一个节点的Term越大,那么它所拥有的日志就越准确。
前面对Raft算法进行了简要的介绍,这里开始对它进行深入分析。Raft实现一致性的机制是这样的:日志是由Leader到Follower的单向传递。也就是说Leader相当于一个总控节点,由它负责接受Client的请求,并且把日志发送各个Follower,进行复制。也是只有Leader能决定何时提交一个日志。通过Leader机制,Raft将一致性难题分解为三个相对独立的子问题:
- Leader选举:一开始每个节点都是Follower,那么需要决定由谁来做Leader,这里延伸出Leader选举的问题,而且当Leader宕机的时候也需要重新进行选举。
- 日志复制:当Leader选举出来之后,需要把日志复制到每个Follower。这里复制需要保证所有日志都有序且正确的复制到Follower上。也就是说Follower上的日志不管是顺序还是内容都要和Leader上的一样。
- 安全性:一但Leader把一项日志复制到绝大多数的Follower时,需要执行这个日志。这里的安全性是指所有的服务器都要在这同一个位置执行同一个Log,通俗的说,就是集群中所有节点都需要按照相同的顺序执行相同的日志。