

1.背景
最近线上一套 TiDB 4.0.9 集群发生一起"热点"问题导致的集群 Duration 升高,解决过程可谓一波三折,借此简单回顾一下问题处理的整个流程和解决思路。
2.问题描述
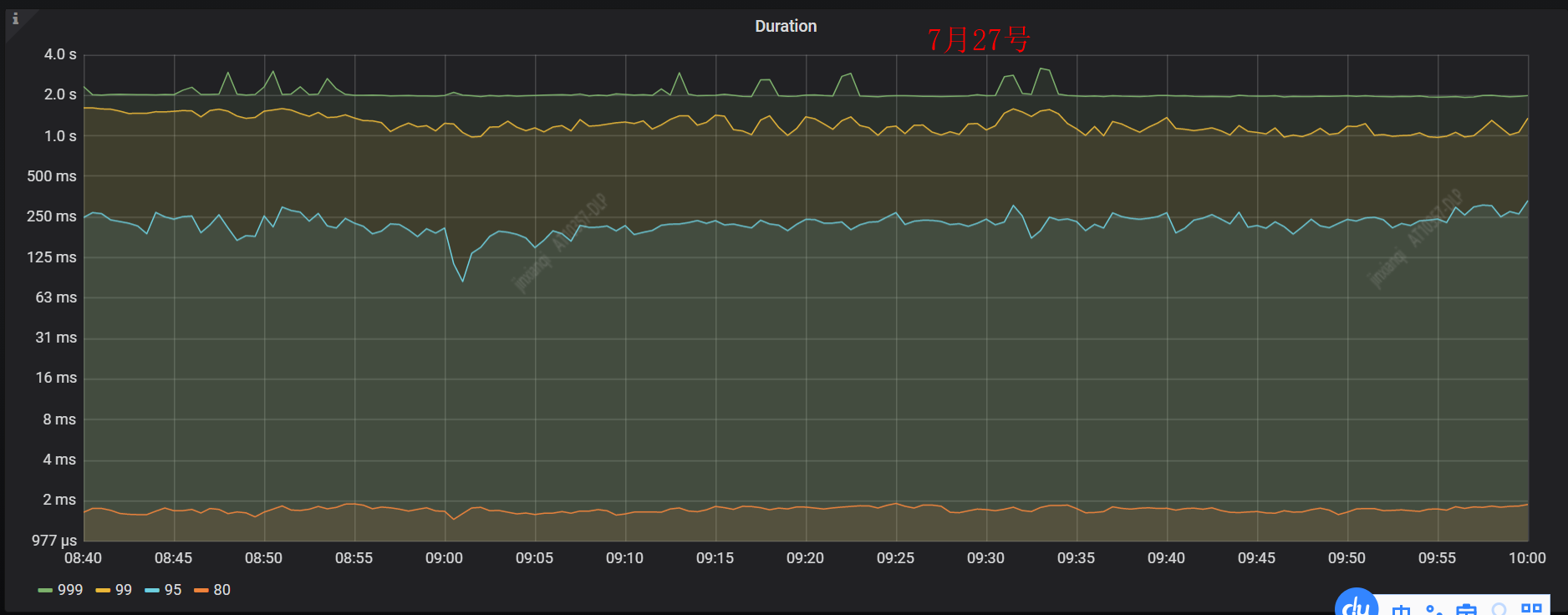
7月27号收到 TiDB 告警信息,SQL 99 duration 大于1秒,相关监控如下所示,可以看到 SQL 99 duration 1 秒多,SQL 95 在 250ms 附近,相比前一天同一时间段的 duration上升了 1 倍左右。
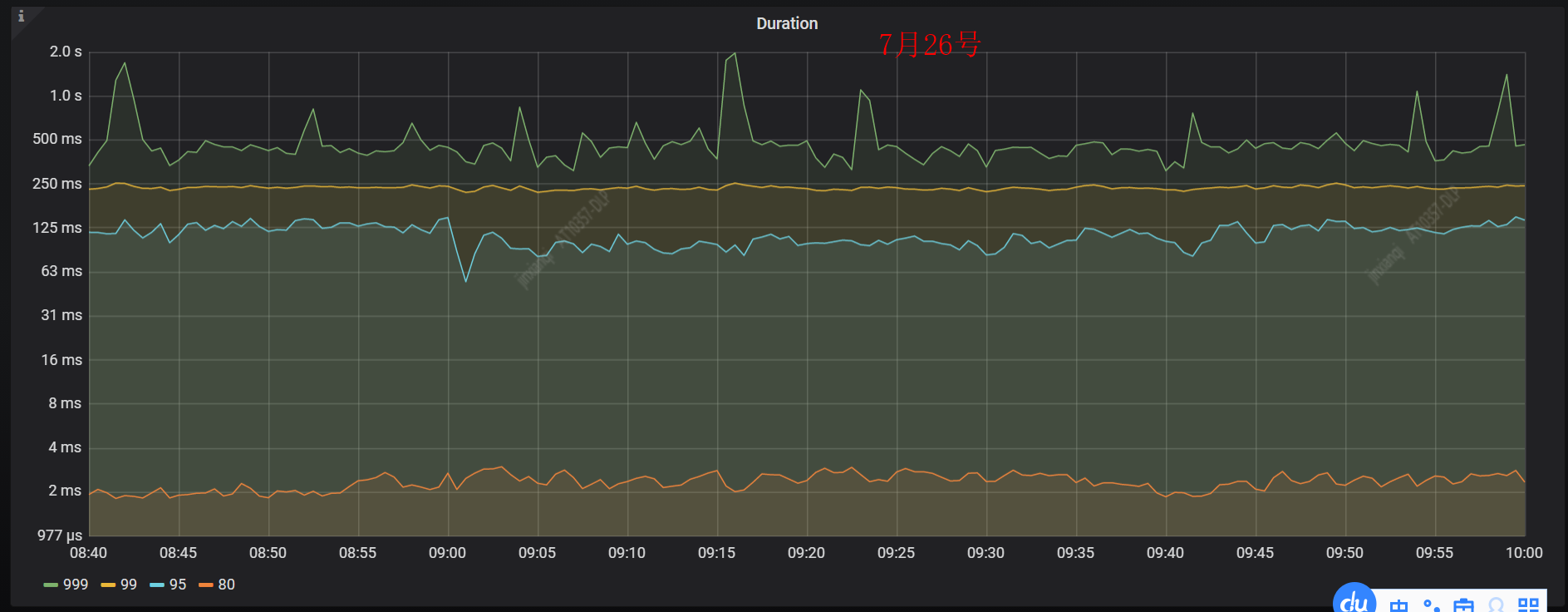
下面是前一天(7月26号)同一时间段 duration 的监控图:
3.问题分析
收到告警信息后,DBA 立刻联系业务方,确认对业务是否有影响,然后开始排查导致 Duration 升高的原因。
3.1分析慢日志
很多时候,通过分析慢日志可以快速定位问题,本次未发现异常。
3.2分析监控
先整体看下集群各个组件服务器的负载情况,通过 tidb overview 监控,发现一台 TiKV 服务器 CPU 明显高于其它服务器,进一步分析 TiKV 的详细监控信息。
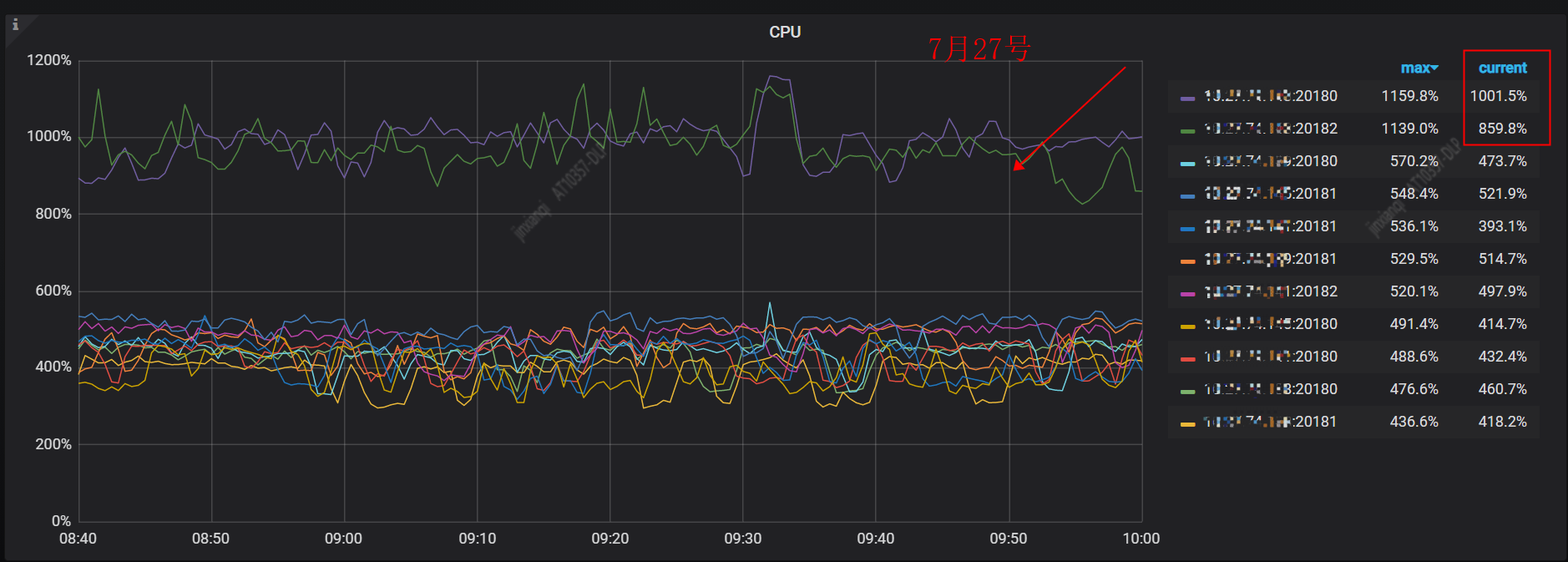
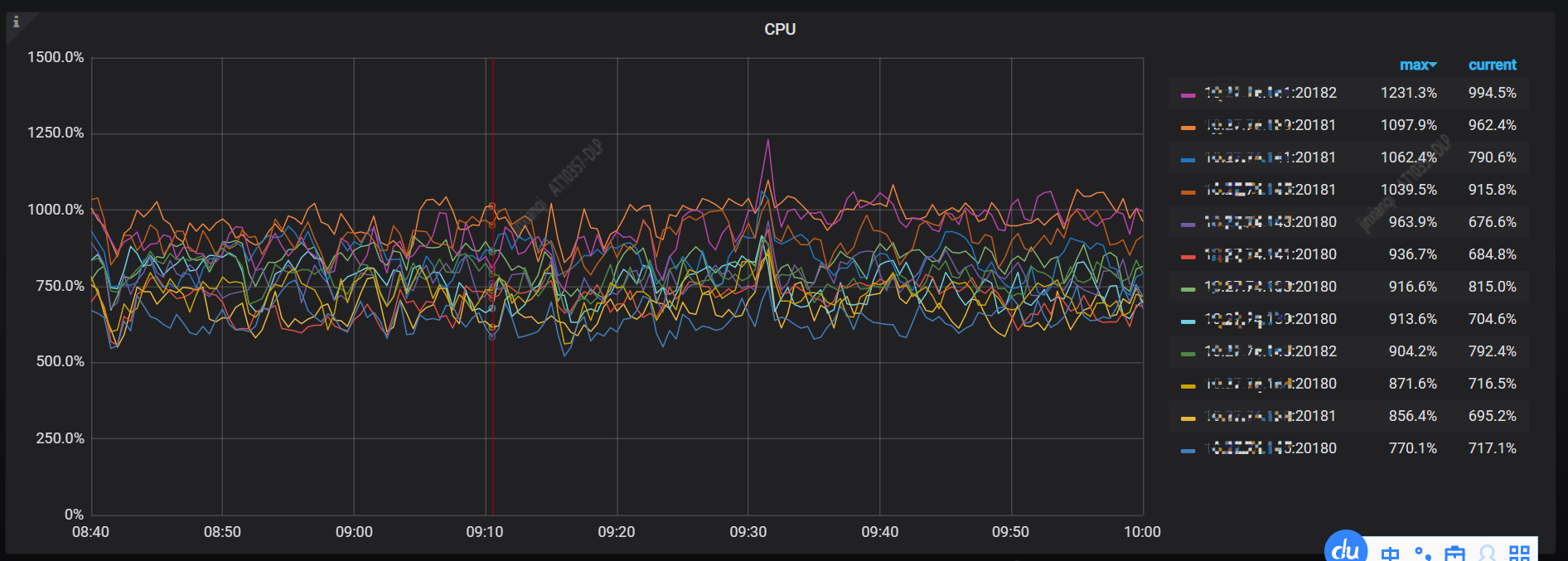
下图是 TiKV 服务器的 CPU 监控指标,可以看到 192.168.1.143(IP 已脱敏)这台服务器上的2个 TiKV 进程占用的 CPU 明显高于其他服务器,大概是其他服务器的2倍,往往这时我们会怀疑集群存在热点问题。
既然怀疑是热点问题,我们继续分析是读热点还是写热点,读写热点问题判断方法如下:
对于 TiDB 3.0 版本
(1)判断写热点依据:打开监控面板 TiKV-Trouble-Shooting 中 Hot Write 面板,观察 Raftstore CPU 监控是否存在个别 TiKV 节点的指标明显高于其他节点的现象。
(2)判断读热点依据:打开监控面板 TIKV-Details 中 Thread_CPU,查看 coprocessor cpu 有没有明显的某个 TiKV 特别高。
对于 TiDB 4.0 版本
(1)判断写热点依据:打开监控面板 TIKV-Details 中 Thread_CPU,观察 Raftstore CPU 监控是否存在个别 TiKV 节点的指标明显高于其他节点的现象。
(2)判断读热点依据:打开监控面板 TIKV-Details 中 Thread_CPU,查看 Unified read pool CPU 有没有明显的某个 TiKV 特别高。
备注:
(1) Raftstore 线程池是 TiKV 的一个线程池,默认大小(raftstore.store-pool-size)为 2。负责处理所有的 Raft 消息以及添加新日志的提议 (Propose)、将日志写入到磁盘,当日志在多数副本中达成一致后,它就会把该日志发送给 Apply 线程。Raftstore CPU 为 Raftstore 线程的 CPU 使用率,通常代表写入的负载。
(2) Unified read pool 线程池是 TiKV 的另一个线程池,默认配置(readpool.unified.max-thread-count)大小为机器 CPU 数的 80%。由 Coprocessor 线程池与 Storage Read Pool 合并而来,所有的读取请求包括 kv get、kv batch get、raw kv get、coprocessor 等都会在这个线程池中执行。Unified read pool CPU 为 Unified read pool 线程的 CPU 使用率,通常代表读取的负载。
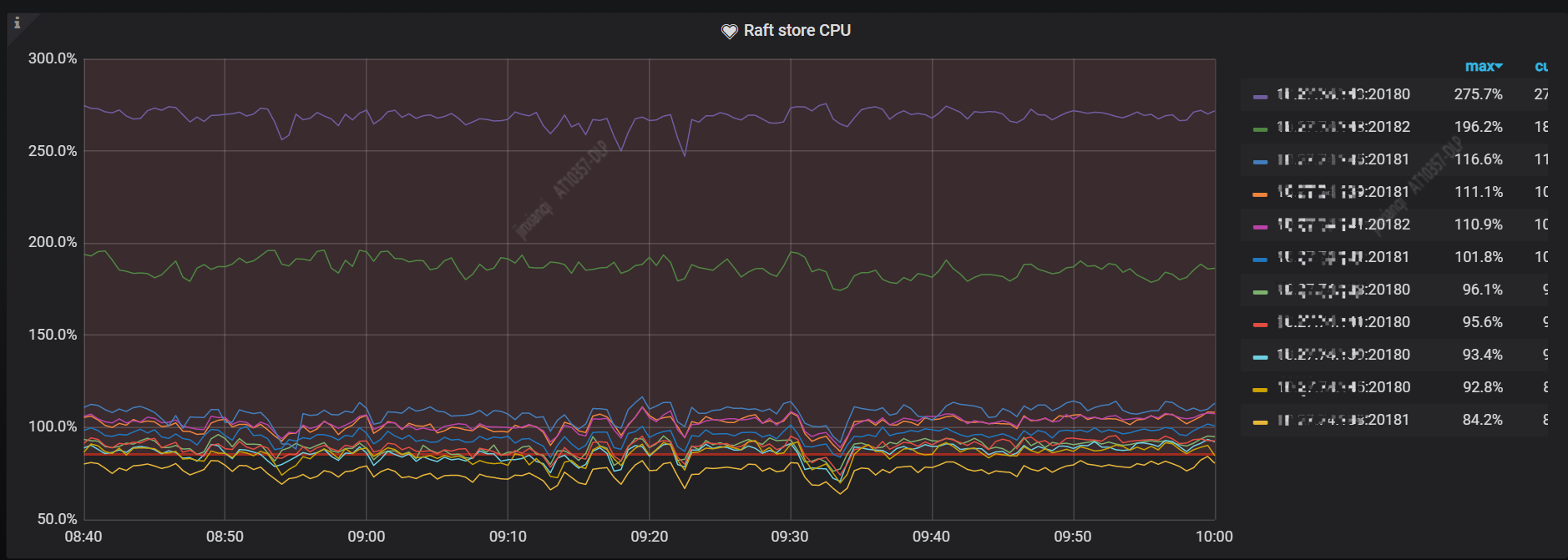
从下图 Raft store CPU 监控中可以看到有明显的写热点,CPU 排名第一的2个 TiKV 实例都在 192.168.1.143 服务器上。
Unified read pool CPU 除了有一个尖刺外,没有明显异常,不存在读热点问题。
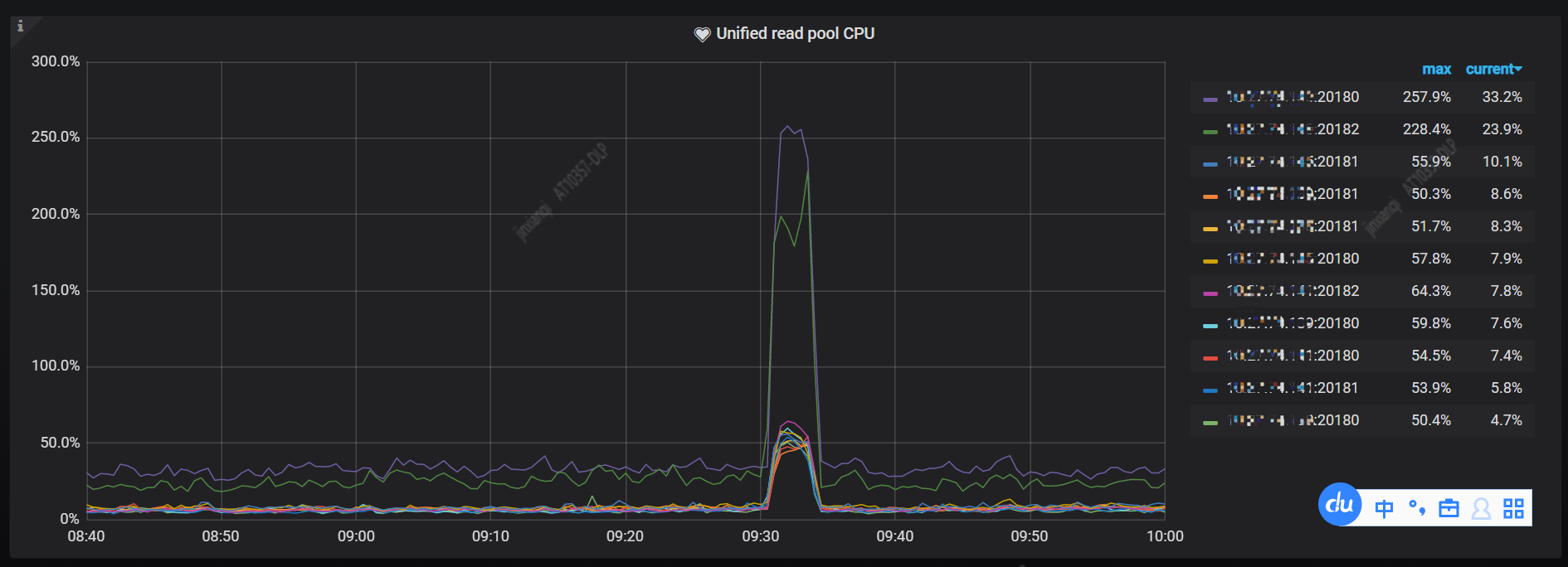
我们来对照着看下前一天(7月26号)同一时间段 TiKV CPU 的监控图,压力相对均衡。
3.3分析热力图
从以上分析,我们已经判断出集群有写入热点问题,接下来排查一下是哪个表导致的写入热点或者具体 SQL ,便于后续改造优化。
TiDB 集群 Dashboard 自带热力图,我们看下是否可以从这里找到蛛丝马迹,热力图看着一切正常,这里贴一个历史的热力图截图。

备注:
热力图是流量可视化页面的核心,它显示了一个指标随时间的变化。热力图的横轴 X 是时间,纵轴 Y 则是按 Key 排序的连续 Region,横跨 TiDB 集群上所有数据库和数据表。颜色越暗 (cold) 表示该区域的 Region 在这个时间段上读写流量较低,颜色越亮 (hot) 表示读写流量越高,即越热。
吐槽一下:
热力图无法选择时间范围,查看历史信息很不方便,期待改进。
3.4分析系统表
既然热力图没发现热点表,我们继续分析一下 TiDB 系统表,比如 TIDB_HOT_REGIONS,是否能找到一些有用的信息。
备注:
information_schema 库下的 TIDB_HOT_REGIONS 表提供了关于热点 Region 的相关信息,这个库下有很多有用的系统表,比如 TIKV_REGION_STATUS,TIKV_REGION_PEERS,TIKV_STORE_STATUS 等,可以学习一下。
从前几节分析得知,192.168.1.143服务器(TiKV)存在热点,按照下面步骤尝试定位具体表。
(1)查找 TiKV 对应的 store id
192.168.1.143 实例上部署了2个 TiKV 实例,通过下面 SQL 找到实例对应的 store id
select * from information_schema.TIKV_STORE_STATUS where ADDRESS like '%192.168.1.143%'\"G
查到的 store id 是 9 和 11
(2)查看上一步 store id 上表的读写排名情况
SELECT count(*), r.db_name, r.table_name, r.type
FROM information_schema.tidb_hot_regions r
JOIN information_schema.TIKV_REGION_PEERS p ON r.REGION_ID = p.REGION_ID
WHERE p.store_id IN (9,11)
GROUP BY r.db_name, r.table_name, r.type
ORDER BY count(*) DESC
LIMIT 20;
从上面 SQL 显示的结果看到一个 UserBehaviorHistory_hash 的表写入较多,这个表是一个 HASH 分区表,数据量30亿,每天写入1亿,删除1亿。但是在一年前由于热点问题专门改造过,表结构改为联合主键(自增id + 设备字段),并使用了 SHARD_ROW_ID_BITS=4 打散热点。
令人困惑的是:
(a)表结构已经改造过,删除操作是 append 操作,理论上应该不会导致写入热点问题才对。
(b)删除操作每天都会进行,以前没出现过类似问题,为什么却今天出现了?
带着这些问题,我们继续往下分析。
(3)查看集群中所有 TiKV 读写字节排名情况,判断写入热点是否就是上面查到的 store id 9 和 11
SELECT
ss.ADDRESS,
h.type,
p.store_id,
sum(FLOW_BYTES),
count(1),
count(DISTINCT p.store_id),
group_concat(p.region_id)
FROM
information_schema.TIDB_HOT_REGIONS h
JOIN information_schema.tikv_region_peers p ON h.region_id = p.region_id
AND p.IS_LEADER = 1
JOIN information_schema.TIKV_STORE_STATUS ss ON p.store_id = ss.store_id
GROUP BY
h.type,
p.store_id,
ss.ADDRESS
ORDER BY
sum(FLOW_BYTES) DESC;
查出来的结果也挺诡异,找到的热点 store 和之前查到的不一致,并不完全是 192.168.1.143,感觉到了山穷水尽的地步。
下面列举一些常用的 SQL ,在一些分析中会用到
查看指定表的数据和索引在各个 TiKV 实例上的 leader 数量分布情况,检查分布是否均匀。
select p.store_id,count(distinct p.peer_id),count( case p.is_leader when 1 then 1 end),count(case when s.is_index= 1 and p.is_leader =1 then 1 end ) from information_schema.TIKV_REGION_STATUS s join information_schema.TIKV_REGION_PEERS p on s.region_id=p.region_id where s.db_name='personalspace' and s.table_name= 'UserBehaviorHistory_hash' group by p.store_id order by p.store_id;
吐槽一下:
(1) 遗憾的是无法查看分区表的 leader 数量分布,期待后续改进。
(2) 小 bug:当输入的 store id 15 不存在时,会报错,报错信息如下所示
information_schema > SELECT count(*), r.db_name, r.table_name, r.type FROM information_schema.tidb_hot_regions r JOIN information_schema.TIKV_REGION_PEERS p ON r.REGION_ID = p.REGION_ID WHERE p.store_id IN (15) GROUP BY r.db_name, r.table_name, r.type ORDER BY count(*) DESC LIMIT 20;
ERROR 1105 (HY000): json: cannot unmarshal number 18446744073709550735 into Go struct field RegionInfo.regions.written_bytes of type int64
3.5原因和解决办法
- 问题原因
经过以上分析,不仅没定位到具体的热点表,是不是热点问题都产生动摇了,感觉前后现象矛盾。突然想到会不会是硬件问题导致的服务器 CPU 高呢?
查看了系统日志 /var/log/messages ,发现了新大陆,出现大量如下错误日志,看着像是内存有问题
Jul 27 14:31:00 xx.xx.xx.xx mcelog[1358]: Running trigger `socket-memory-error-trigger'
Jul 27 14:31:00 xx.xx.xx.xx mcelog[1358]: Running trigger `socket-memory-error-trigger'
Jul 27 14:31:00 xx.xx.xx.xx mcelog[27281]: Fallback Socket memory error count 17871 exceeded threshold: 2061474779 in 24h
Jul 27 14:31:00 xx.xx.xx.xx mcelog[27282]: Location: SOCKET:0 CHANNEL:? DIMM:? []
Jul 27 14:31:00 xx.xx.xx.xx mcelog[27283]: Fallback Socket memory error count 22160 exceeded threshold: 2061496940 in 24h
Jul 27 14:31:00 xx.xx.xx.xx mcelog[27284]: Location: SOCKET:0 CHANNEL:? DIMM:? []
Jul 27 14:31:01 xx.xx.xx.xx kernel: EDAC MC0: 17872 CE memory read error on CPU_SrcID#0_Ha#0_Chan#0_DIMM#0 (channel:0 slot:0 page:0xdc4bad offset:0x640 grain:32 syndrome:0x0 - OVERFLOW area:DRAM err_code:0001:0090 socket:0 ha:0 channel_mask:1 rank:1)
联系 IDC 的同事帮忙检测了硬件,确定了内存条问题,至此问题原因已经确认,CPU 高的那台服务器由于内存故障导致了"热点"问题。
- 解决办法
先向集群加入一台新服务器,再下掉有问题的服务器。既先在新服务器上扩容2个 TiKV 实例,再逐个缩容(缩容过程注意限速,store limit all 5,默认值是15,可以根据实际情况修改)掉问题服务器上的2个 TiKV 实例,完毕以后,集群 Duration 恢复到之前状态,TiKV 服务器的 CPU 比较均衡,目前已稳定运行一周多。
4.总结
虽然本次"热点"问题并不是真正的热点写入导致的,但是提供了一些解决问题的思路,遇到类似问题,可以参考以上排查思路进行分析,希望能够对其他小伙伴有所帮助。概括一下上面"热点"问题分析的整个过程:
(1)分析慢日志,是否存在异常 SQL
(2)分析监控
查看监控 Overview,先简单判断各组件服务器是否存在 CPU、内存、IO 、网络等问题
再根据实际问题查看详细监控,分析具体问题,例如判断读热点还是写热点
(3)分析系统表,尝试查找具体的热点表
(4)分析服务器硬件,是否正常
5.展望
对于分布式数据库,热点问题的确是一个令人头疼的问题,一旦发生热点问题,多少都会影响到业务,比如集群 Duration 升高,接口响应时间变长。
当发生热点问题时,业务方一般都会让 DBA 提供出现热点问题的 SQL ,至少要知道哪个表导致的热点问题,来做进一步处理。但是目前对于 TiDB 来说,这个难度有点大,有些时候很难定位到热点表,更别说具体 SQL 了。
虽然 TiDB 目前提供的分析热点问题的方法很多,例如热力图,系统表(information_schema.tidb_hot_regions),详细的监控,但是这些方法有时还是显得力不从心,无法快速定位热点问题,甚至根本无法定位。
热点问题,同事闫长杰也在2021年 DevCon 吐槽大会上提到过,期待官方在不久的将来可以提供更好,更快,更强的热点问题排查工具。
DBA 也应该多和业务方沟通,培训,让业务方以正确的姿势使用分布式数据库,尽量避免热点问题。
6.感谢
感谢苏丹老师和王贤静老师在排查问题中给予的大力支持和帮助。