

概述
Tiflash是4.0的一个巨大的提升,补充了Tidb对OLAP的支持。对OLAP型的分析而言,列存是最合适的。举例来说,用户表User有50个字段,如果想统计用户地域,年龄某些维度的分布情况,那么由于地域信息都一起存在某些block中,粗略来算,存储密度是行存的50倍。换言之,磁盘IO就减少了50倍,而在数据库系统中,IO普遍是最慢的。因此,整个请求的时间,资源消耗就减少至1/50。而且在列存的组织方式下,压缩效率比行存要高,使得IO进一步减少(思考下why)。让我们开始动手试试看吧。。。
安装Tiflash
之前的开发环境是ansible安装的,官方回复以后会用tiup逐步替代ansible,那就直接用Tiup。导入升级,然后安装tiflash,过程非常顺利,有不懂的可以–help看下tiup的具体用法。
tiup cluster import -d /home/tidb/tidb-ansible
tiup cluster upgrade develop v4.0.0-rc
tiup cluster scale-out develop scale-out.yaml
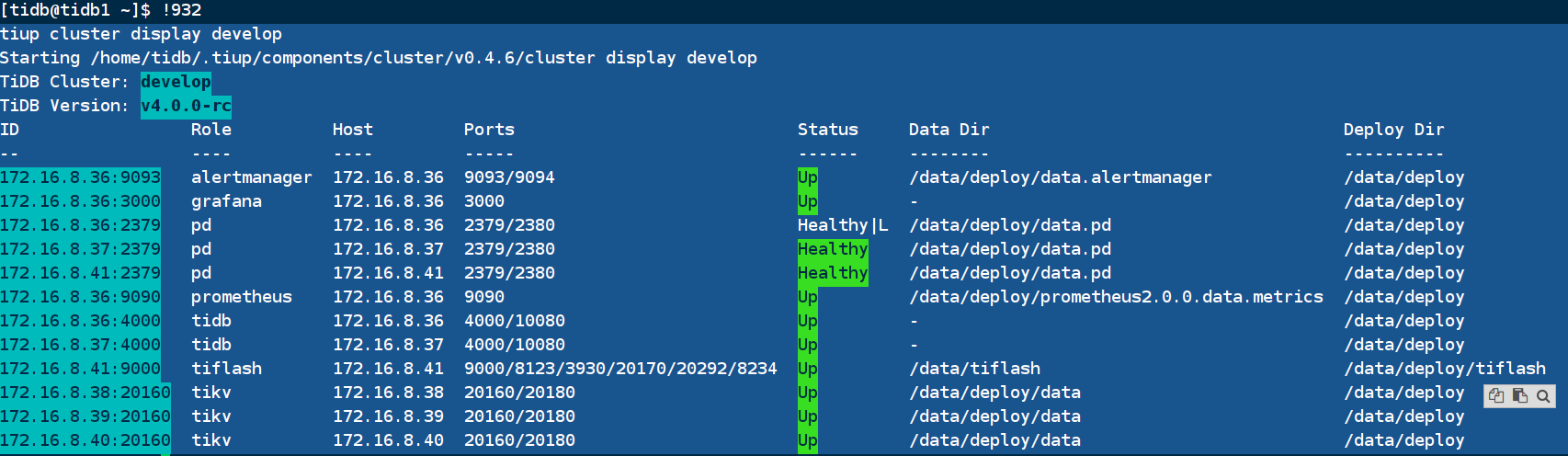
安装完成后,用tiup cluster display develop查看下相应的组件是否正确安装及更新。
tiflash复制
设置复制
alter table dim.dim_worker_info_df set tiflash replica 1;
这里有个疑问,replica>1的用途是?
删除复制
alter table dim.dim_worker_info_df set tiflash replica 0;
查看复制进度
select * from information_schema.tiflash_replica
where table_schema = 'dim' and table_name = 'dim_worker_info_df'
其中progress是同步进度,0-1,1代表同步进度100%,同步已完成。available=1代表此表可对外提供服务。实测中,600W的表3秒同步完成,还是挺快的。

SQL测试
tiflash 73ms
set @@session.tidb_isolation_read_engines=‘tikv,tiflash’
explain analyze select a.nation ,count(1) from dim.dim_worker_info_df a group by a.nation

tikv 429ms
set @@session.tidb_isolation_read_engines=‘tikv’
将读引擎设置为tikv,来强制使用tikv。 explain analyze select a.nation,count(1) from dim.dim_worker_info_df a group by a.nation

join中的运用
explain select a.*,b.birth_place from dwd.dwd_worker_attendance_day_df a inner join dim.dim_worker_info_df b on a.worker_id = b.worker_id
tidb的执行计划会根据SQL中具体的列来选择合适的引擎。

总结
由于实测的表数据量不是很大,都进了tikv/tiflash节点的cache中了,两者相差了6倍的性能,差距不大,建议测试表的体量在1000w以上,字段50左右会更明显。