

作者:李坤、高振娇
背景
TiDB 的 GC 相关的问题比如 GC 的流程、参数设置、监控以及日志解析,GC 设置多大比较合适,设置过大对集群会产生什么样的影响,GC 卡住了应该从哪里排查等等一系列的问题,是笔者在使用 TiDB 过程中经常遇到的问题。
故笔者将 GC 相关的内容进行了相关的整理,一共分为 3 篇,第一篇为 『GC 原理浅析』,第二篇为『GC 监控及日志解读』,而最后一篇则为『GC 处理案例 & FAQ』。
本文从 GC Leader 的选举,流程等维度简要分析了 GC 相关的原理,希望能够帮助大家理解 GC 的流程,表示不严谨或者错误的地方,欢迎大家批评指正 ~~~
GC
TiDB 的事务的实现采用了 MVCC(多版本并发控制)机制,当新写入的数据覆盖旧的数据时,旧的数据不会被替换掉,而是与新写入的数据同时保留,并以时间戳来区分版本,GC 的任务便是清理不再需要的旧数据。
整体流程
GC Leader 的选举
一个 TiDB 集群中会有一个 TiDB 实例被选举为 GC leader,GC 的运行由 GC leader 来控制。GC Leader 的选举是从 TiDB Server 中选出一个作为 GC Leader ,GC Worker 是 TiDB Server 上的一个模块,只有 GC Leader 会处理 GC 的工作,其他 TiDB Server 上的 GC Worker 是不工作的。选举 GC Leader 的方式很简单,GC Worker 每分钟 Tick 时,如果发现没有 Leader 或 Leader 失效,就把自己写进去,成为 GC Leader。
Safepoint
每次 GC 时,首先 TiDB 会计算一个称为 Safepoint 的时间戳,接下来 TiDB 会在保证 Safepoint 之后的快照全部拥有正确数据的前提下,删除更早的过期数据。
GC 流程
每一轮 GC 分为以下三个步骤,这三个步骤在整个 GC 的流程中是串行执行。如果一轮 GC 运行时间太久,上次 GC 还在前两个阶段,下轮 GC 又开始了,下一轮 GC 会忽略,GC Leader 会报 “there’s already a gc job running,skipped”:
- Resolve Locks:该阶段会对所有 Region 扫描 Safepoint 之前的锁,并清理这些锁。
- Delete Ranges:该阶段快速地删除由于 DROP TABLE/DROP INDEX 等操作产生的整区间的废弃数据。
- Do GC:该阶段每个 TiKV 节点将会各自扫描该节点上的数据,并对每一个 key 删除其不再需要的旧版本。
默认配置下,GC 每 10 分钟触发一次,每次 GC 会保留最近 10 分钟内的数据( 即默认 GC Life Time 为 10 分钟,Safepoint 的计算方式为当前时间减去 GC Life Time )。
为了使持续时间较长的事务能在超过 GC Life Time 之后仍然可以正常运行,Safepoint 不会超过正在执行中的事务的开始时间 (start_ts)。
实现细节
Resolve Locks(清理锁)
TiDB 的事务是基于 Google Percolator 模型实现的,事务的提交是一个两阶段提交的过程。第一阶段完成时,所有涉及的 key 都会上锁,其中一个锁会被选为 Primary,其余的锁 ( Secondary ) 则会存储一个指向 Primary 的指针;第二阶段会将 Primary 锁所在的 key 加上一个 Write 记录,并去除锁。
如果因为某些原因(如发生故障等),这些 Secondary 锁没有完成替换、残留了下来,那么也可以根据锁中的信息找到 Primary,并根据 Primary 是否提交来判断整个事务是否提交。但是,如果 Primary 的信息在 GC 中被删除了,而该事务又存在未成功提交的 Secondary 锁,那么就永远无法得知该锁是否可以提交。这样,数据的正确性就无法保证。
Resolve Locks 这一步的任务即对 Safepoint 之前的锁进行清理。即如果一个锁对应的 Primary 已经提交,那么该锁也应该被提交;反之,则应该回滚。而如果 Primary 仍然是上锁的状态(没有提交也没有回滚),则应当将该事务视为超时失败而回滚。
Resolve Locks 的执行方式是由 GC leader 对所有的 Region 发送请求扫描过期的锁,并对扫到的锁查询 Primary 的状态,再发送请求对其进行提交或回滚。
从 3.0 版本开始,Resolve Locks 实现了并行,把所有 Region 分配给各个线程,所有线程并行的向各个 Region 的 Leader 发送请求:
- 并发线程数
若tikv_gc_auto_concurrency = 1,则每个 TiKV 自动一个线程。
若tikv_gc_auto_concurrency = 0,则由tikv_gc_concurrency决定总线程数,但每个 tikv 最多一个线程。 - 实际清锁的操作,是调用了 RocksDB 的 Delete ,RocksDB 的内部实现原理是写一个删除标记,需要等 RocksDB 执行 Compaction 回收空间,通常这步骤涉及的数据非常少。
Delete Ranges(删除区间)
在执行 Drop/Truncate Table ,Drop Index 等操作时,会有大量连续的数据被删除。如果对每个 key 都进行删除操作、再对每个 key 进行 GC 的话,那么执行效率和空间回收速度都可能非常的低下。事实上,这种时候 TiDB 并不会对每个 key 进行删除操作,而是将这些待删除的区间及删除操作的时间戳记录下来。Delete Ranges 会将这些时间戳在 Safepoint 之前的区间进行快速的物理删除,而普通 DML 的多版本不在这个阶段回收。
- TiKV 默认使用 RocksDB 的 UnsafeDestroyRange 接口
- Drop/Truncate Table ,Drop Index 会先把 Ranges 写进 TiDB 系统表(
mysql.gc_delete_range),TiDB 的 GC worker 定期查看是否过了 Safepoint,然后拿出这些 Ranges,并发的给 TiKV 去删除 sst 文件,并发数和 concurrency 无关,而是直接发给各个 TiKV。删除是直接删除,不需要等 compact 。完成 Delete Ranges 后,会记录在 TiDB 系统表mysql.gc_delete_range_done,表中的内容过 24 小时后会清除:
mysql> select * from gc_delete_range_done;
+--------+------------+--------------------+--------------------+--------------------+
| job_id | element_id | start_key | end_key | ts |
+--------+------------+--------------------+--------------------+--------------------+
| 283 | 171 | 7480000000000000ab | 7480000000000000ac | 422048703668289538 |
| 283 | 172 | 7480000000000000ac | 7480000000000000ad | 422048703668289538 |
+--------+------------+--------------------+--------------------+--------------------+
2 rows in set (0.01 sec)
Do GC(进行 GC 清理)
这一步主要是针对 DML 操作产生的 key 的过期版本进行删除。为了保证 Safepoint 之后的任何时间戳都具有一致的快照,这一步删除 Safepoint 之前提交的数据,但是会对每个 key 保留 Safepoint 前的最后一次写入(除非最后一次写入是删除)。
在进行这一步时,TiDB 只需将 Safepoint 发送给 PD,即可结束整轮 GC。TiKV 会每 1 分钟自行检测是否 Safepoint 发生了更新,然后会对当前节点上所有 Region Leader 进行 GC。与此同时,GC Leader 可以继续触发下一轮 GC。
详细的流程如下:
-
调用 RocksDB 的 Delete 接口,打一个删除标记。
-
每一轮 GC 都会扫所有的 Region,但会根据 sst 上的元信息初步判断是否有较多的历史数据,进而来判断是否可以跳过。如果增量数据比较大,表示要打标记的老版本较多,会大幅增加耗时。
-
GC 打完标记后,不会立即释放空间,最终通过 RocksDB Compaction 来真正回收空间。
-
如果这时 TiKV 进程挂掉了,重启后,需要等下一轮 GC 开始继续。
-
并行度
- 3.0 开始,默认设置
tikv_gc_mode = distributed,无需 TiDB 通过对 TiKV 发送请求的方式来驱动,而是 TiDB 只需在每个 GC 周期发送 safepoint 到 PD 就可以结束整轮 GC,每台 TiKV 会自行去 PD 获取 safepoint 后分布式处理。
- 3.0 开始,默认设置
-
由于通常 Do GC 比较慢,下一轮 interval 到来时,上一轮 GC 还没有跑完:
- 3.0 开始,如果没有执行完,下一轮 GC 将新的 safepoint 更新到 PD 后,TiKV 每隔 1 分钟到 PD 获取新的 safepoint,获取后会使用新的 safepoint 将剩余的 Region 完成扫描,并尽量回头完成 100% 的 Region ( TiKV 会将执行到的 Region 位置在内存中,并按 Region 顺序扫描所有 Region )。
配置
TiDB 的 GC 相关的配置存储于 mysql.tidb 系统表中,可以通过 SQL 语句对这些参数进行查询和更改:
select VARIABLE_NAME, VARIABLE_VALUE from mysql.tidb where VARIABLE_NAME like "tikv_gc%";
+--------------------------+----------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+--------------------------+----------------------------------------------------------------------------------------------------+
| tikv_gc_leader_uuid | 5afd54a0ea40005 |
| tikv_gc_leader_desc | host:tidb-cluster-tidb-0, pid:215, start at 2019-07-15 11:09:14.029668932 +0000 UTC m=+0.463731223 |
| tikv_gc_leader_lease | 20190715-12:12:14 +0000 |
| tikv_gc_enable | true |
| tikv_gc_run_interval | 10m0s |
| tikv_gc_life_time | 10m0s |
| tikv_gc_last_run_time | 20190715-12:09:14 +0000 |
| tikv_gc_safe_point | 20190715-11:59:14 +0000 |
| tikv_gc_auto_concurrency | true |
| tikv_gc_mode | distributed |
+--------------------------+----------------------------------------------------------------------------------------------------+
13 rows in set (0.00 sec)
例如,如果需要将 GC 调整为保留最近一天以内的数据,只需执行下列语句即可:
update mysql.tidb set VARIABLE_VALUE="24h" where VARIABLE_NAME="tikv_gc_life_time";
注意:
mysql.tidb 系统表中除了下文列出的 GC 的配置以外,还包含一些 TiDB 用于储存部分集群状态(包括 GC 状态)的记录。请勿手动更改这些记录。其中,与 GC 有关的记录如下:
- tikv_gc_leader_uuid,tikv_gc_leader_desc 和 tikv_gc_leader_lease 用于记录 GC Leader 的状态
- tikv_gc_last_run_time:最近一次 GC 运行的时间(每轮 GC 开始时更新)
- tikv_gc_safe_point:当前的 Safepoint (每轮 GC 开始时更新)
tikv_gc_enable
控制是否启用 GC。
默认值:true
tikv_gc_run_interval
指定 GC 运行时间间隔。Duration 类型,使用 Go 的 Duration 字符串格式,如 “1h30m”,“15m” 等。
默认值:“10m0s”
tikv_gc_life_time
每次 GC 时,保留数据的时限。Duration 类型。每次 GC 时将以当前时间减去该配置的值作为 Safepoint。
默认值:“10m0s”
注意:
在数据更新频繁的场景下,如果将
tikv_gc_life_time设置得比较大(如数天甚至数月),可能会有一些潜在的问题,如:
- 磁盘空间占用较多。
- 大量的历史版本会在一定程度上影响性能,尤其是范围查询(如 select count(*) from t)。
如果存在运行时间很长、超过了
tikv_gc_life_time的事务,那么在 GC 时,会保留自该事务的开始时间 (start_ts) 以来的数据,以允许该事务继续运行。例如,如果tikv_gc_life_time配置为 10 分钟,而某次 GC 时,集群中正在运行的事务中开始时间最早的一个事务已经运行了 15 分钟,那么本次 GC 便会保留最近 15 分钟的数据。
tikv_gc_mode
指定 GC 模式。可选值如下:
- “distributed”(默认):分布式 GC 模式。在此模式下,Do GC 阶段由 TiDB 上的 GC leader 向 PD 发送 Safepoint,每个 TiKV 节点各自获取该 Safepoint 并对所有当前节点上作为 leader 的 Region 进行 GC。此模式于 TiDB 3.0 引入。
- “central”:集中 GC 模式。在此模式下,Do GC 阶段由 GC leader 向所有的 Region 发送 GC 请求。TiDB 2.1 及更早版本采用此 GC 模式。
tikv_gc_auto_concurrency
控制是否由 TiDB 自动决定 GC concurrency,即同时进行 GC 的线程数。
当 tikv_gc_mode 设为 “distributed”,GC concurrency 将应用于 Resolve Locks 阶段。当 tikv_gc_mode 设为 “central” 时,GC concurrency 将应用于 Resolve Locks 以及 Do GC 两个阶段。
- true(默认):自动以 TiKV 节点的个数作为 GC concurrency
- false:使用 tikv_gc_concurrency 的值作为 GC 并发数
tikv_gc_concurrency
手动设置 GC concurrency。要使用该参数,必须将 tikv_gc_auto_concurrency 设为 false 。
默认值:2
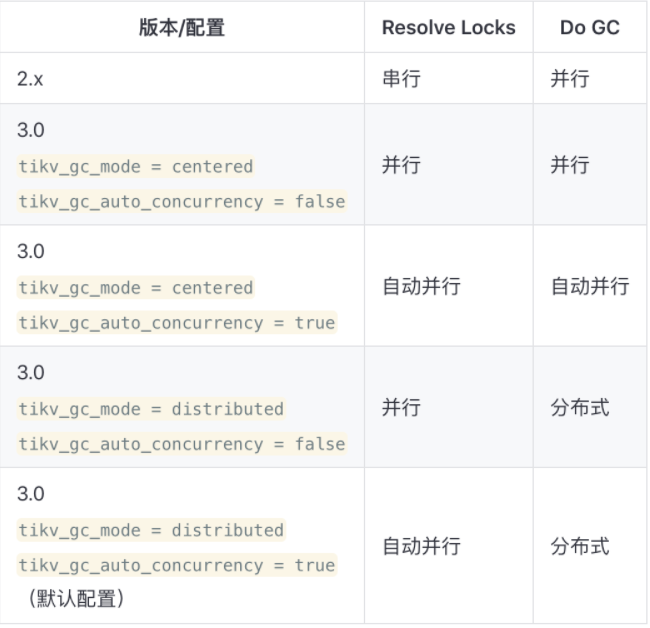
表格内容说明:
- 串行:由 TiDB 逐个向 Region 发送请求。
- 并行:使用 tikv_gc_concurrency 选项所指定的线程数,并行地向每个 Region 发送请求。
- 自动并行:使用 TiKV 节点的个数作为线程数,并行地向每个 Region 发送请求。
- 分布式:无需 TiDB 通过对 TiKV 发送请求的方式来驱动,而是每台 TiKV 自行工作。
流控
TiKV 在 3.0.6 版本开始支持 GC 流控,并且仅仅针对 GC 的 DO GC 阶段进行限流。可通过配置 gc.max-write-bytes-per-sec 限制 GC worker 每秒数据写入量,降低对正常请求的影响,0 为关闭该功能。该配置可通过 tikv-ctl 动态修改:
tikv-ctl --host=ip:port modify-tikv-config -m server -n gc.max_write_bytes_per_sec -v 10MB