

1月22日,以“一源 · 三生 · 共进化”为主题的 2026 平凯数据库新品分享会成功举办。会上,平凯星辰正式发布了平凯数据库(TiDB 企业版)的全新形态——基于同一套内核衍生的三种部署模式,并发布了新一代内核以及平凯数据库云服务。
本次分享会不仅是一次产品的迭代,更是一场关于数据基础设施未来的深度对话。从创始团队的全球化经验分享,到产品团队对数据库选型“不可能三角”的突破,再到与 AI Agent 开发、 Agent 基础设施领域先行者的思想碰撞,平凯星辰向业界展示了一家技术驱动型公司如何以全球视野深耕中国市场,用技术前瞻性引领数据库未来。
创始人对话:全球极限场景淬炼,铸就“产品根系”
在大会第一篇章“一源 · 共进化”中,刘奇、黄东旭、崔秋三位平凯星辰创始人回顾了 TiDB 十年全球化征程,分享了 TiDB 的技术演进逻辑:主动置身于全球最先进、最严苛、最复杂的场景中千锤百炼,打磨出通用的数据库产品根系,再将这种能力根植到不同的市场落地。
创始人团队一致认为,数据库作为基础软件,必须面向未来构建核心竞争力、保持架构的持续领先。过去十年,TiDB 始终坚持与全球最具创新力的技术领军者同行,在中国以及北美、欧洲、亚太地区,深入各领域的顶级客户核心场景,在这些代表多元化需求与领先业务形态的极限场景中,沉淀出能够从容应对未来不确定性的通用“产品根系”。如今,这种源自全球前沿实战沉淀的硬核能力,正为国内企业的数字化转型提供兼具前瞻性与确定性有力支撑。


刘奇表示,最好的全球化就是本地化。两年前,平凯星辰面向中国市场推出的平凯数据库(TiDB 企业版),首批通过分布式数据库安全可靠测评,并在金融、能源、医疗、交通、运营商、制造、公共事业等行业加速落地。
针对中国市场,崔秋表示,当前的国产化替代已进入深水区,客户需要的不能仅仅是面向过去的简单“平替”,更应是面向未来的架构升级。以建设银行、中国人寿财险、杭州银行等核心系统为例,通过应用层改造适配平凯数据库(TiDB 企业版)原生分布式架构,客户不仅实现了国产化转型,更获得了数倍的性能与效率提升,真正实现了“换道超车” 。
此外,刘奇分享了一个标志着时代转折的数据:在 TiDB Cloud 上,超过 90% 的数据库实例已由 AI Agent 自动创建。这一趋势表明,数据库的用户正在从人类转变为智能体,而平凯数据库正是那个能够满足未来先进生产力需求的坚实底座。
“如果我们能一直满足最先进客户的需求,实际上我们就满足了先进生产力的需求。” 黄东旭表示。从 TiDB 诞生最初解决 MySQL 扩容痛点,到如今支撑 AI Agent 的海量并发,TiDB 始终坚持面向未来的研发策略。
一套内核,三种模式:破解数据库选型的“不可能三角”
一直以来,数据库选型面临“水平扩展、业务透明、极致性能”难以兼得的“不可能三角”,结合客户在选型时面临的业务场景多、技术路线多等复杂困境,本次发布会,平凯数据库给出了解决方案——基于同一个内核,衍生出“敏捷模式、标准模式、聚能模式”三种部署模式,满足企业不同场景、不同阶段的需求。
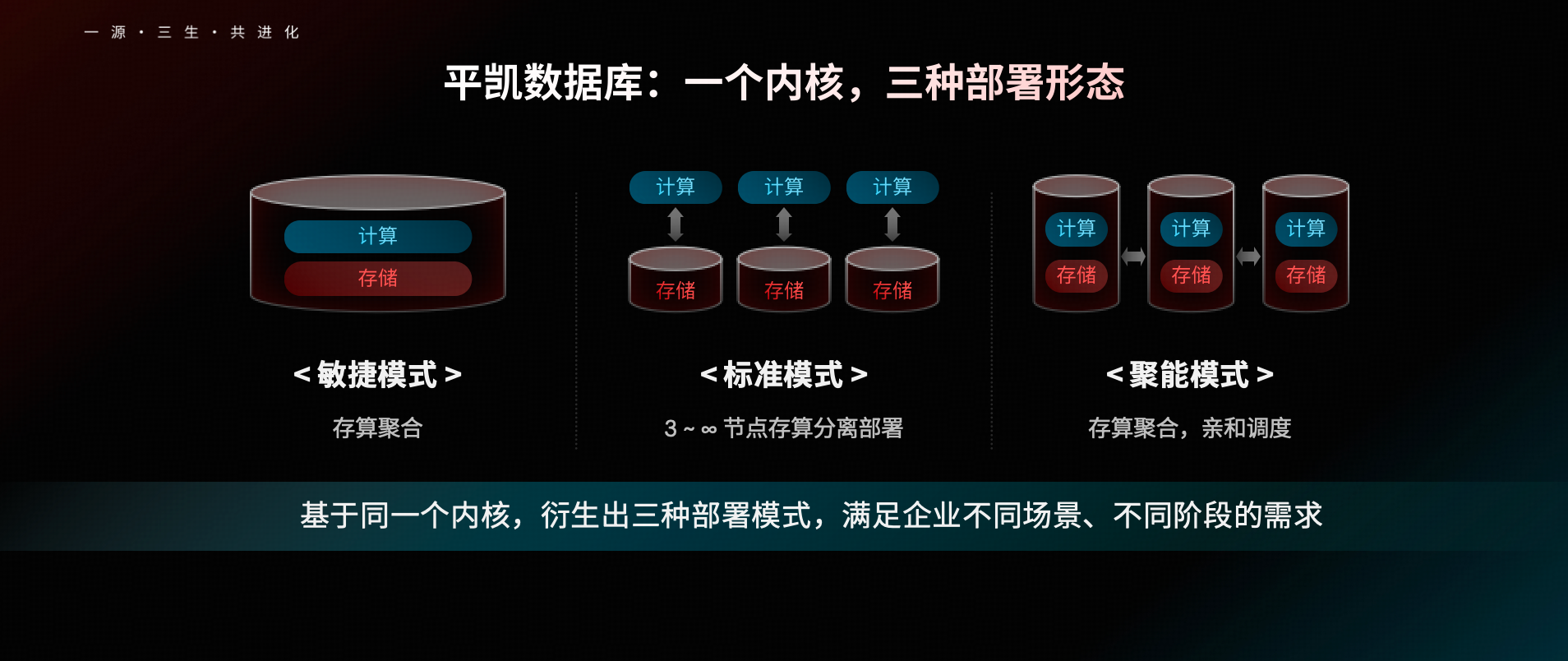
不同于为不同场景分别设计独立产品,平凯数据库选择从底层统一内核出发,通过计算与存储的聚合与解耦、以及数据组调度机制,实现数据库在不同形态之间的灵活切换。这使得数据库既可以在资源受限或业务简单时高效“聚合”,也能够在规模扩展或负载变化时自然“分散”,从而实现真正的数据自适应。

基于这一设计理念,平凯数据库能够在同一技术体系内,支持不同规模、不同复杂度的业务场景,并为企业在未来业务增长或技术升级过程中,提供更低成本、更平滑的演进路径。
- 敏捷模式: 专为 TB 级以下数据量及创新业务设计。敏捷模式仅需 1-3 个节点即可起步,不仅读写性能大幅优于 MySQL,压缩率更提升 3 倍以上,提供了优于单机主从架构的高可用能力,极大地降低了客户的试错成本与使用门槛。
- 标准模式: 延续经典的存算分离架构,在水平扩展与业务透明性上保持业界标杆水准,完美适配数据量快速增长的成长型与核心业务场景。
- 聚能模式: 专为对延迟极度敏感的场景打造。通过内存直连与亲和性调度等技术创新,将延迟降低至原来的 1/4,吞吐提升 2-3 倍,让客户无需牺牲分布式弹性即可享受单机般的极致性能。

这三种模式彻底打通了客户业务发展的全生命周期,让企业无需在早期为未来押注,真正做到了“随需而变” 。
平凯星辰研发副总裁姚维在分享中表示,数据库架构的关键不在于预设某一种“最优形态”,而在于是否具备顺应业务变化而动态调整的能力。“可聚可散,意味着客户可以根据业务实际需要,自然地使用数据库,而不是被架构所限制。”
新一代存算分离 2.0 内核:源于极端场景,验证极致稳定与韧性
会上,平凯星辰也展现了对未来的深刻洞察,发布了新一代内核,旨在提前应对未来业务负载高度动态化带来的挑战。黄东旭表示,未来的数据基础设施必须具备极高的灵活性与成本效率 。新一代内核通过存算分离 2.0 架构,实现了对数据库内部模块的深度解耦与抽象。这一技术突破使得在线任务、离线计算与 AI 引擎(如向量、全文索引)之间能够实现“零干扰”的资源隔离。

这种设计理念体现了极强的技术前瞻性:不再仅仅针对确定的业务负载进行优化,而是为 AI 时代不可预测的脉冲式流量和多模态数据需求预留了架构空间。无论是传统的交易处理,还是未来 Agent 驱动的复杂工作流,新一代内核都能提供稳健、高效的支撑,确保企业技术底座“十年不落后” 。

姚维在现场发布时表示,与传统业务负载相比,AI 场景下的数据访问模式更加动态,计算与存储资源需求波动更大,对数据库架构的弹性与调度能力提出了更高要求。平凯数据库的新一代内核,正是在这样的“极限条件”下进行设计与打磨,通过更彻底的存储层解耦与更灵活的资源调度机制,使数据库能够在复杂、多变的负载环境中保持稳定运行。
得益于架构的深度解耦,新一代内核在部署形态上也实现了真正的统一:既支持在私有化部署中实现极致的资源利用率,也能在云环境下实现秒级弹性伸缩。平凯星辰在会上正式宣布,基于该内核的平凯数据库云服务将于 2026 年上半年正式推出,届时将为带来全托管、免运维及极致成本效益的云端新体验。

姚维表示:“新一代内核能够支撑 AI 等高不确定性的场景,并会逐步融入平凯数据库的产品体系中,提供更高上限的底层架构,为所有业务场景提供更可靠的基础支撑。当数据库能够应对最复杂的变化,其在更常规业务场景中的适用性与稳定性也将得到充分验证。”
AI 圆桌对话:携手先锋,指引数据基础设施演进方向
在大会的压轴环节,TiDB 联合创始人兼 CTO 黄东旭及平凯星辰中国区总经理龙恒特邀了头部 LLM 应用开发平台 Dify 的创始团队成员与 Agent Infra 创业者代表,共同探讨 AI 时代的演进方向,进一步印证了数据基础设施变革的必要性。
基础设施的轻量化:张宇辰提出,随着 AI 灵活性增加,未来可能出现“一次会话一套基础设施”的极致轻量化场景,这对数据库的隔离性提出了更高要求。
统一底座的需求: 面对向量、图、全文检索等割裂的数据栈,黄东旭认为数据库必须提供统一、灵活的服务接口,“AI 不想在完成一个任务时还要到处安装组件” 。
SQL 的未来角色: 尽管自然语言交互日益普及,嘉宾们一致认为 SQL 将作为连接 AI 与数据的“通用汇编语言”长期存在,提供确定性的逻辑支撑 。
Dify 资深架构师姜勇分享了实战经验:在海量知识库检索中,交互延迟是落地生根的最大阻碍。而平凯星辰新一代内核的高并发与多模融合能力,正是解决这一痛点、支撑 Agent 规模化落地的关键。
通过与行业先锋的深度对话,平凯星辰进一步明确了“统一数据底座”的战略价值——即通过一个灵活、融合的平台,屏蔽底层复杂性,让开发者与 AI Agent 能够专注于业务创新。
发布会以“一源 · 三生 · 共进化”为主题,不仅完成了平凯数据库从“规模化优势”到“全场景覆盖”的形态进化,更展示了新一代内核在全球极限场景中锤炼出的深厚产品根系力量。三种部署形态和新一代存算分离 2.0 内核,为中国企业数字化转型提供了兼具确定性与前瞻性的数据底座。
面向未来,平凯星辰将继续以“一源之力”和“三生之态”,陪伴中国企业穿越技术周期的不确定性,降低数据底座选型的复杂性,从容驾驭数据、决胜未来。
