

导语
在制造业向数字化、智能化深度转型的浪潮中,数据正成为驱动企业创新与效率的核心生产力。然而,数据体量激增、类型日益多元、AI 应用落地复杂等挑战,也让传统数据架构捉襟见肘。数据孤岛林立、AI 应用开发成本高昂、海量数据扩展受限,已成为制约智能制造发展的“三座大山”。
在此背景下,构建一个敏捷、智能、可信赖的现代化数据底座,成为企业破局的关键。9 月 27 日,在深圳举办的第 12 届湾区数智汇 AiOT 创新沙龙上,平凯星辰解决方案总监周辉分享了基于其分布式数据库的“All-in-One”解决方案,旨在为制造企业提供应对数据挑战的一体化答案。

演讲嘉宾:周辉 平凯星辰解决方案总监
智能制造行业的三大核心数据痛点
- 数据割裂与实时性不足:制造企业的生产数据(如设备传感器数据)、业务数据(如订单、库存数据)、非结构化数据(如工艺文档、设备运维视频)分散在 ERP、MES、CRM 等多套系统中,形成“数据孤岛”。传统架构下,数据需通过 ETL 工具跨系统流转,导致 BI 报表延迟常达 T+1,无法支撑实时生产调度与质量管控。
- AI 应用落地成本高:智能制造场景中,AI 质检、数字员工、智能运维等应用需依赖向量数据(如图片特征向量)、图数据(如供应链关系图谱)、结构化数据的协同分析。传统方案需部署关系型数据库、向量数据库、图数据库等多套技术栈,不仅增加硬件采购与运维成本,还需解决多系统数据同步问题,开发效率大幅降低。
- 海量数据扩展性受限:随着新能源车 OTA 升级、智能产线传感器部署等场景的普及,企业日均数据写入量可达亿级,单表数据量常突破百亿行。传统 MySQL 分库分表架构需手动拆分数据、提前规划扩容,不仅操作复杂,还易因分片不均导致性能瓶颈,无法适配智能制造的动态数据增长需求。
平凯数据库 (TiDB 企业版):“All-in-One”的一体化解决方案
平凯数据库(TiDB 企业版)作为原生分布式多模态数据库,以“All-in-One”架构打破传统数据库的功能边界,通过“一套集群支持多场景需求”的核心能力,成为智能制造的数据底座首选:
- 架构层面:采用“计算与存储分离”的分布式设计,支持按需扩展计算节点(TiDB)与存储节点(TiKV),单集群可支撑 PB 级数据存储与百万级 QPS,轻松应对智能制造的海量数据增长。
- 功能层面:融合关系型数据库(SQL 支持)、向量数据库(向量检索)、全文检索(FTS)、图数据库(知识图谱)的核心能力,无需多套系统协同,即可满足 AI Agent 质检、实时生产分析、供应链图谱分析等场景需求。
- 安全与合规层面:首批通过中国信息安全测评中心分布式数据库安全可靠测评(I 级),开源架构确保代码透明可审计,符合智能制造企业对数据安全与供应链自主可控的要求。
平凯数据库智能制造数据底座的核心技术架构
平凯数据库(TiDB 企业版)针对智能制造场景,构建了“数据接入-存储计算-智能分析-AI 应用”的全链路技术架构,核心分为四层: 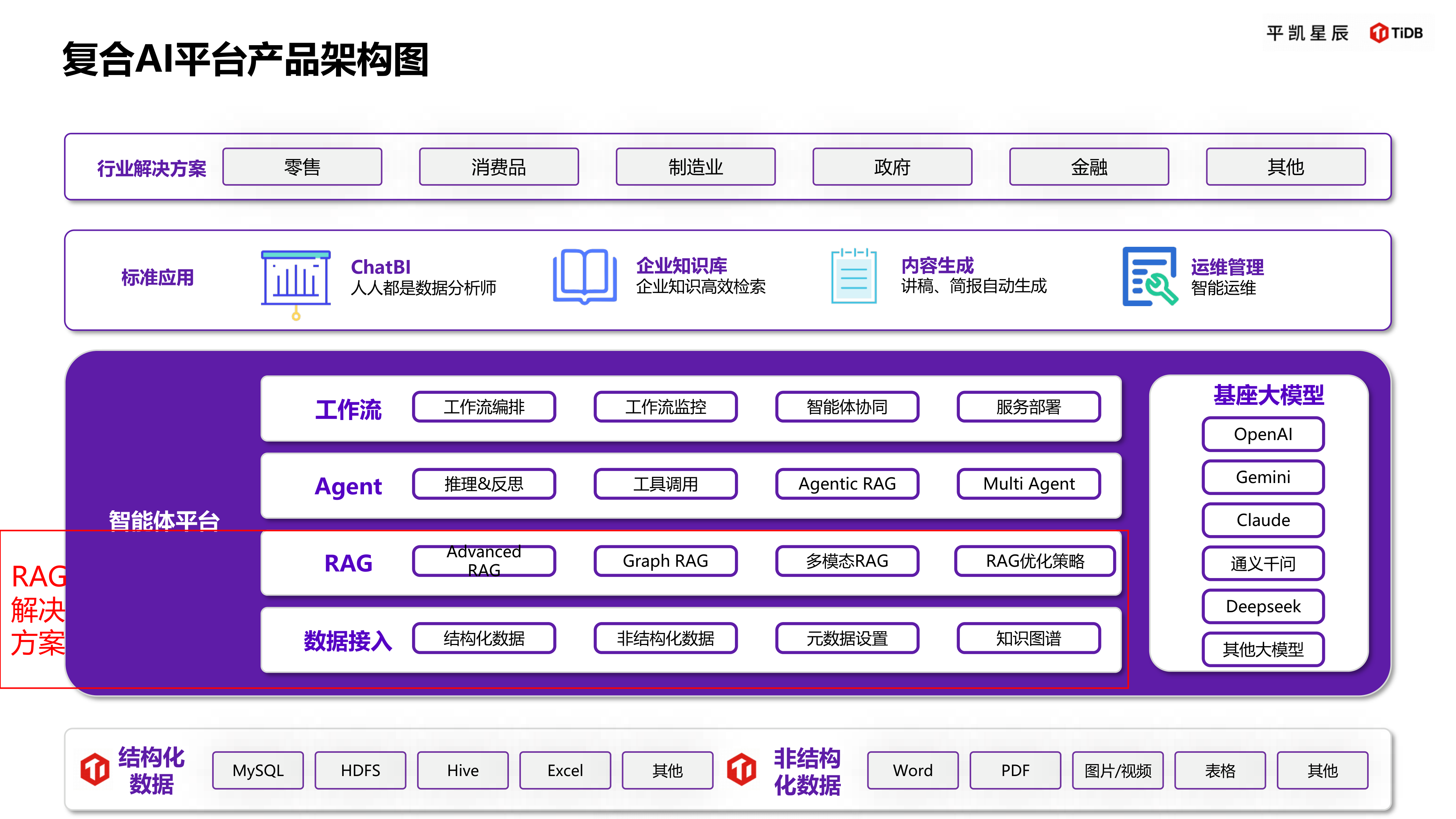
复合 AI 平台产品架构图
数据接入层:全类型数据统一接入
支持智能制造场景下的多源数据接入,包括:
- 结构化数据:通过 MySQL 协议兼容 MES 系统、ERP 系统的生产订单、设备状态等数据,无需修改应用代码即可平滑迁移;
- 非结构化数据:集成工艺文档(PDF/Word)、技术设计说明文档、设备运维视频、质检图片等数据,结合平凯数据库(TiDB 企业版)的向量存储能力,实现非结构化数据的特征提取与存储;
- 实时流数据:实时捕获设备传感器的时序数据(如温度、压力、转速),写入平凯数据库(TiDB 企业版)集群延迟低至毫秒级,支撑实时生产监控,并可以通过 TiCDC(TiDB Change Data Capture)实时流转数据到外围业务。
存储计算层:分布式架构支撑高可用与弹性扩展
1. 核心组件协同
- TiDB(计算层):负责 SQL 解析、优化与执行,支持分布式事务(ACID 兼容),确保生产订单、库存等核心数据的一致性;
- TiKV(存储层):采用 Raft 协议实现数据多副本(默认 3 副本)存储,单个节点故障不影响业务连续性,满足智能制造“7×24 小时不中断生产”的需求;
- TiFlash(列存分析引擎):基于列存储优化,为生产报表分析、质量追溯等 OLAP 场景提供 10 倍以上的查询加速,同时与 TiKV 共享数据,无需数据冗余存储。
2. 多模态数据处理能力
- 向量存储与检索:支持将质检图片、工艺文档转换为向量 Embedding 后存入平凯数据库(TiDB 企业版),通过余弦相似度算法实现毫秒级向量检索,为 AI 质检提供数据支撑;
- 知识图谱(GraphRAG):通过平凯数据库(TiDB 企业版)的图存储能力,构建供应链关系图谱(如供应商-零部件-产线关联)、设备故障诊断图谱(如故障现象-原因-解决方案关联),助力智能决策;
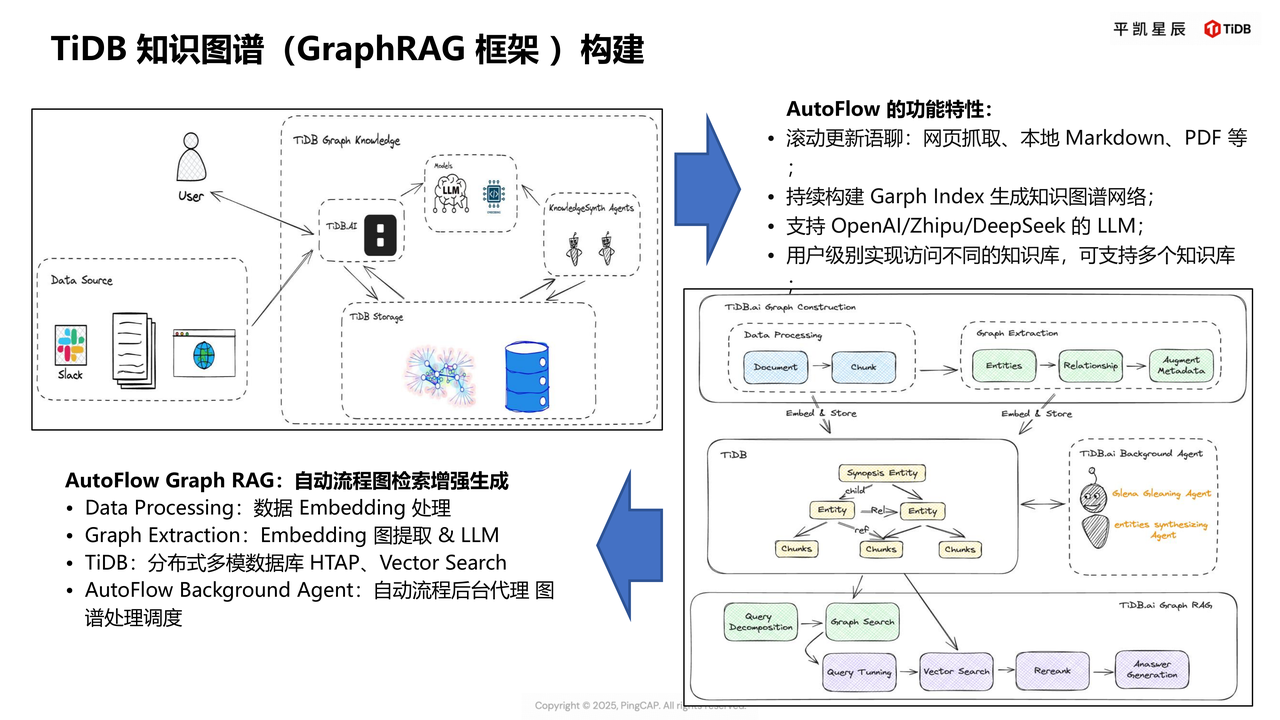
知识图谱(GraphRAG 框架)构建
- 全文检索(TiDB Cloud):内置 FTS 引擎,支持对工艺文档、设备运维日志的关键词检索,解决非结构化数据的高效查询问题。
智能分析层:Data+AI 融合的核心能力
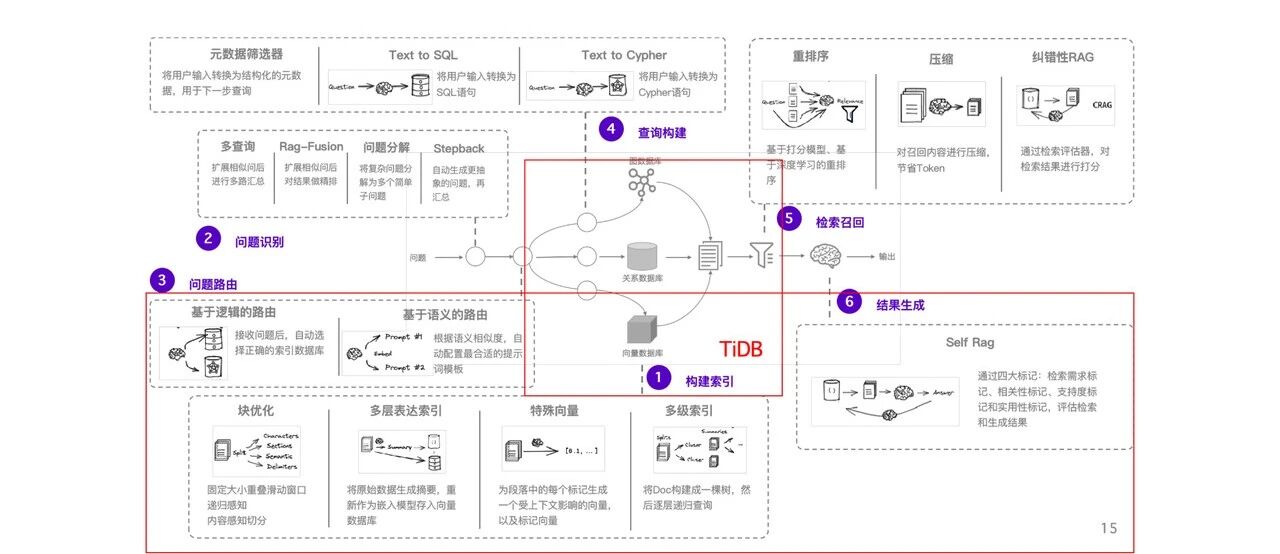
一个复杂的企业知识库场景需要的数据库技术
平凯数据库(TiDB 企业版)通过“原生集成 AI 工具链+简化数据流转”,降低智能制造 AI 应用的开发门槛:
1. RAG(检索增强生成)优化:针对制造企业知识库场景,平凯数据库(TiDB 企业版)支持“问题拆解-语义路由-多源检索-结果重排”全链路自动化——用户提出“设备故障排查方案”时,系统自动混合检索通过 SQL 查询设备历史故障数据,通过向量检索匹配相似故障案例,最终生成结构化解决方案,无需人工跨系统查询。
2. AI Agent 协同:支持与 DeepSeek、通义千问等大模型集成,将企业 SOP(标准作业流程)、PDCA(质量管理循环)等流程融入 AI Agent,实现“数字员工”的工程化落地。例如,生产线上的数字员工可通过平凯数据库(TiDB 企业版)实时获取设备数据,结合工艺知识图谱,自动判断故障原因并推送维修指导。
TiDB GraphRAG 案例:已经支持 DeepSeek 本地部署
3. 实时数据驱动模型迭代:平凯数据库(TiDB 企业版)的实时数据同步能力(TiCDC)可将生产数据实时推送至 AI 模型训练平台,实现“数据-模型-应用”的闭环迭代。例如,AI 质检模型可通过实时获取的产品质检数据,持续优化识别精度,提升质检效率。
应用适配层:低门槛迁移与场景化支持
为降低智能制造企业的迁移与应用成本,平凯数据库(TiDB 企业版)提供全方位的适配能力:
1. 协议兼容:高度兼容 MySQL 协议,MES、ERP 等传统业务系统无需修改代码即可接入,迁移周期缩短至 3 周以内;
2. 工具链支撑:提供 DM(数据迁移工具)、BR(备份恢复工具)、TiDB Operator(K8s 编排工具)等全套工具,支持从 MySQL、Oracle 等数据库的平滑迁移,以及云上云下统一部署;
3. 场景化方案:针对新能源车 OTA、智能产线监控、供应链协同等细分场景,提供预配置的参数模板与最佳实践,减少企业的定制化开发成本。
平凯数据库在智能制造场景的典型案例实践
奥尼电子——出海制造企业的多模态数据中枢
1. 企业痛点
奥尼电子是音视频制造领域头部企业,业务覆盖全球 20 多个国家,面临三大核心问题:
- 数据孤岛:生产数据(MES)、订单数据(ERP)、海外客服数据分散,BI 报表延迟 T+1,无法实时调整海外生产计划;
- 多语言服务低效:产品手册翻译存在时间差,海外客服面对专业术语(如音视频编码标准)时响应准确率低;
- AI 开发成本高:尝试落地“数字员工”时,传统架构方式需部署 MySQL、Milvus(向量数据库)、Neo4j(图数据库)多套系统,运维成本激增。
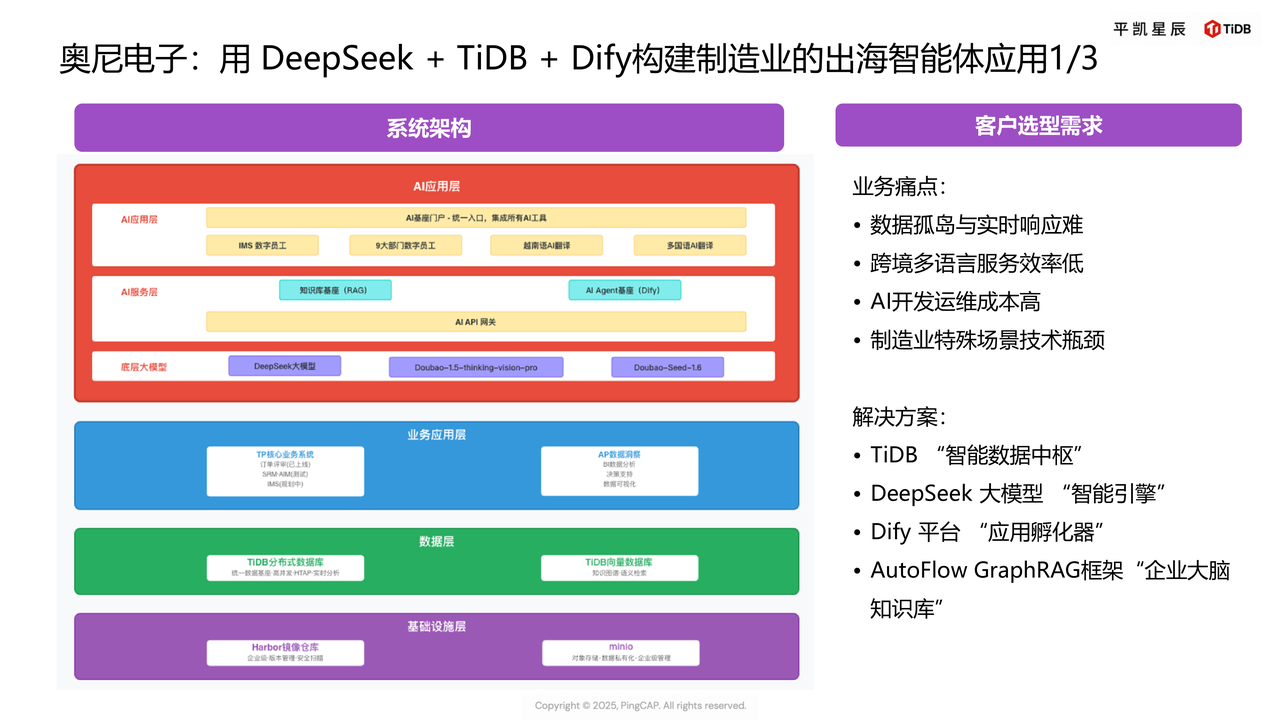
奥尼电子:用 DeepSeek+TiDB +Dify 构建制造业的出海智能体应用
2.TiDB 解决方案
- 数据统一存储:用 TiDB 一套集群存储结构化数据(生产/订单数据)、向量数据(产品图片特征)、图数据(供应链关系),一体化融合数据,消除数据孤岛;
- 知识图谱构建:基于 TiDB 的 GraphRAG 框架,将工艺文档、客服对话历史转化为知识图谱,结合 DeepSeek 大模型及 Dify 构建多功能 AI Agent 实现多语言实时翻译与故障解答;
- 实时分析支撑:通过 TiFlash 列存引擎,将 BI 报表延迟从 T+1 降至秒级,海外分公司可实时查看生产进度。
3.落地成效
- 基础设施成本降低 80%,无需维护多套数据库;
- 海外客服响应准确率提升 60%,专业术语解答误差率降至 5%以下;
- 生产计划调整周期从 7 天缩短至 1 天,库存周转率提升 30%。


某头部新能源车企业——OTA 系统的海量数据底座
1.企业痛点
该企业新能源车年销量超 100 万辆,OTA 升级频率达每月 1 次,面临:
- 数据量激增:每辆车日均产生 1000+条数据(如空调调节、驾驶模式切换),日均写入量 1 亿条,单表数据量突破 500 亿行;
- 扩容困难:原 MySQL 分库分表架构需手动拆分数据,扩容时需停机 4 小时以上,影响车主 OTA 使用体验;
- 混合负载压力:需同时支撑 C 端车主的高并发查询(如 APP 端查看升级进度)与 B 端的数据分析(如用户驾驶习惯统计),传统架构难以兼顾。
2.TiDB 解决方案
- 弹性扩展:采用 TiDB“计算-存储分离”架构,存储节点(TiKV)从 10 个扩展至 20 个仅需 30 分钟,无需停机;
- 混合负载优化:交易类请求(车主查询)路由至 TiKV,分析类请求(驾驶习惯统计)路由至 TiFlash,物理隔离确保两者性能互不影响;
- 数据平滑迁移:通过 DM 工具将 MySQL 分库分表数据迁移至 TiDB,迁移过程中业务无感知,零 downtime。
3.落地成效
- 支持百万级车辆的 OTA 数据管理,单集群存储容量达 3PB;
- APP 端查询响应延迟从 200ms 降至 50ms,高并发场景下 P99 延迟稳定在 100ms 以内;
- 扩容效率提升 10 倍,运维成本降低 60%,彻底解决分库分表的扩容痛点。
某知名制造企业——营销业务中台的全链路数据协同
1.企业痛点
该企业为家电制造龙头,线上线下渠道并行,面临:
- 数据管理复杂:20 多个微服务(商品中心、订单中心、库存中心)的数据分散在不同数据库,线上线下价格不一致导致渠道冲突;
- 供应链协同滞后:供应商数据与生产数据不同步,库存预警延迟,导致生产断料风险;
- 报表分析低效:原架构需通过消息中间件将数据同步至数仓,AP 查询延迟超 2 分钟,无法支撑实时营销决策。
2.TiDB 解决方案
- 微服务统一支撑:用 TiDB 一套集群支撑 20 个微服务,通过“资源组”功能为每个服务分配独立资源,避免相互干扰;
- 线上线下数据打通:将线上电商数据与线下门店数据统一存储至 TiDB,实时同步价格与库存信息,消除渠道冲突;
- 实时分析加速:引入 TiFlash 只读节点,将 AP 查询延迟从 2 分钟降至 8 秒,营销团队可实时查看促销活动效果。
3.落地成效
- 微服务运维成本降低 90%,无需管理多套数据库;
- 供应链库存准确率提升至 98%,生产断料风险降低 70%;
- 营销活动调整周期从 3 天缩短至 1 小时,促销转化率提升 15%。
结语
在 AI 与智能制造深度融合的时代,数据底座的“敏捷性、智能性、可信赖性”成为企业竞争的核心壁垒。平凯数据库(TiDB 企业版)通过“All-in-One”的多模态架构,打破传统数据库的功能边界,为智能制造企业提供了从数据接入、存储计算到 AI 应用的全链路解决方案。截至目前,平凯数据库/TiDB 已服务理想汽车、吉利汽车、TCL、奥尼电子等数十家制造头部企业,未来将继续以技术创新为驱动,成为智能制造数字化转型的“核心引擎”。