

背景:
目前Tidb 备份方案有很多,比如BR 和 dumpling/lightning 全量备份,但是从4.0.6之后TICDC 的出现,让我对备份产生了新的认识,可以实现在线热备份,还可以对备份集群进行查询或者数据分析等场景非常多,于是想尝试一下
一 、 单向同步
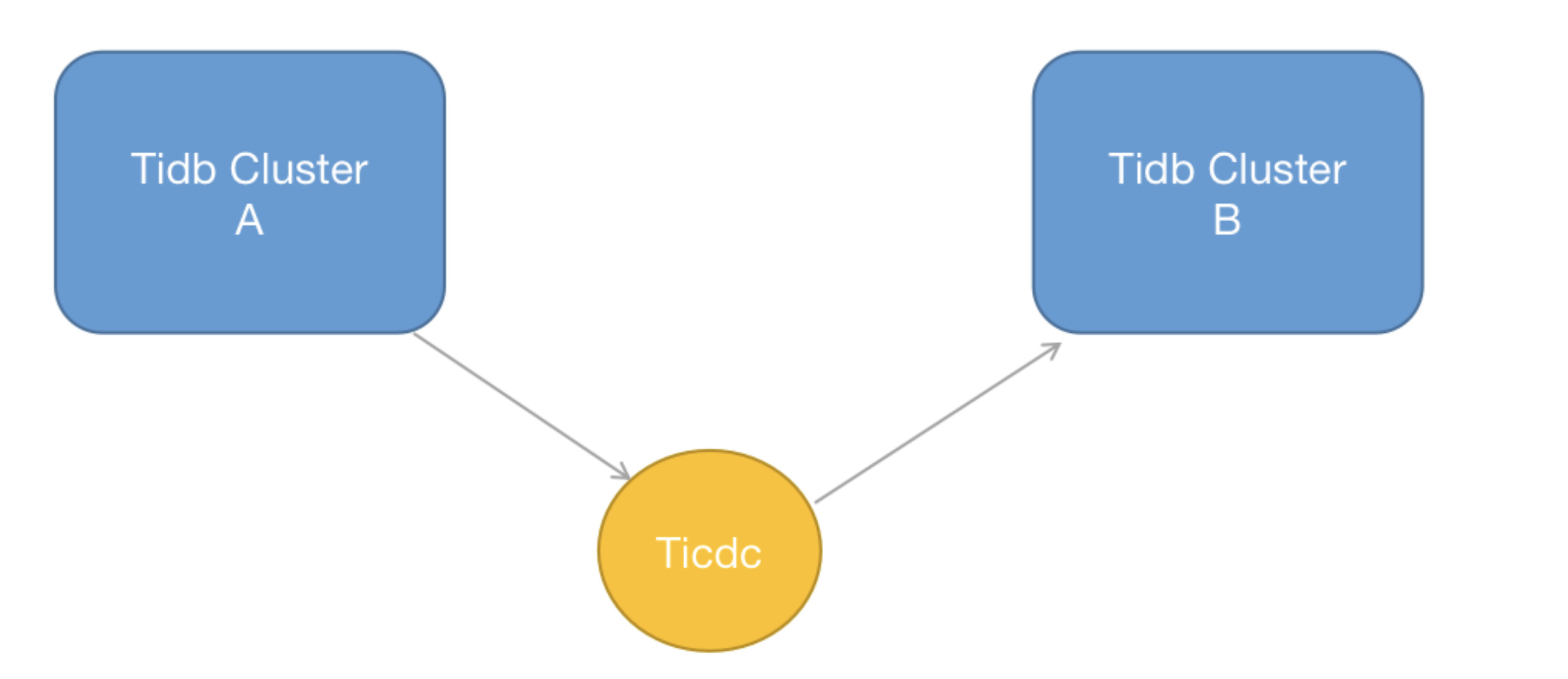
B 集群可以作为A 集群的热备份,另一个也可以分摊一定的读流量
二 、 双向同步
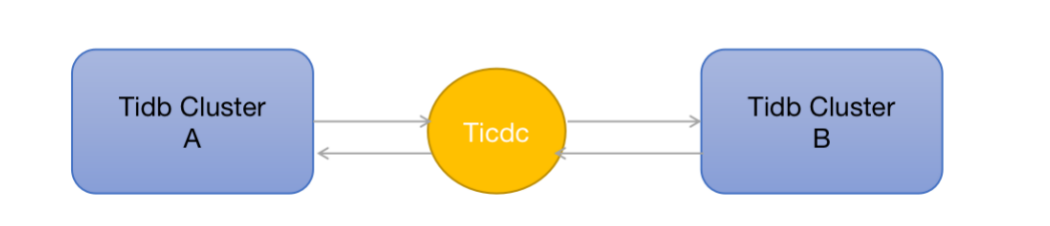
双向同步可以用来针对两个不同的业务,创建不同的数据库,分别进行对应的库表读写业务分离,彼此互为热备
三 、 多库合一
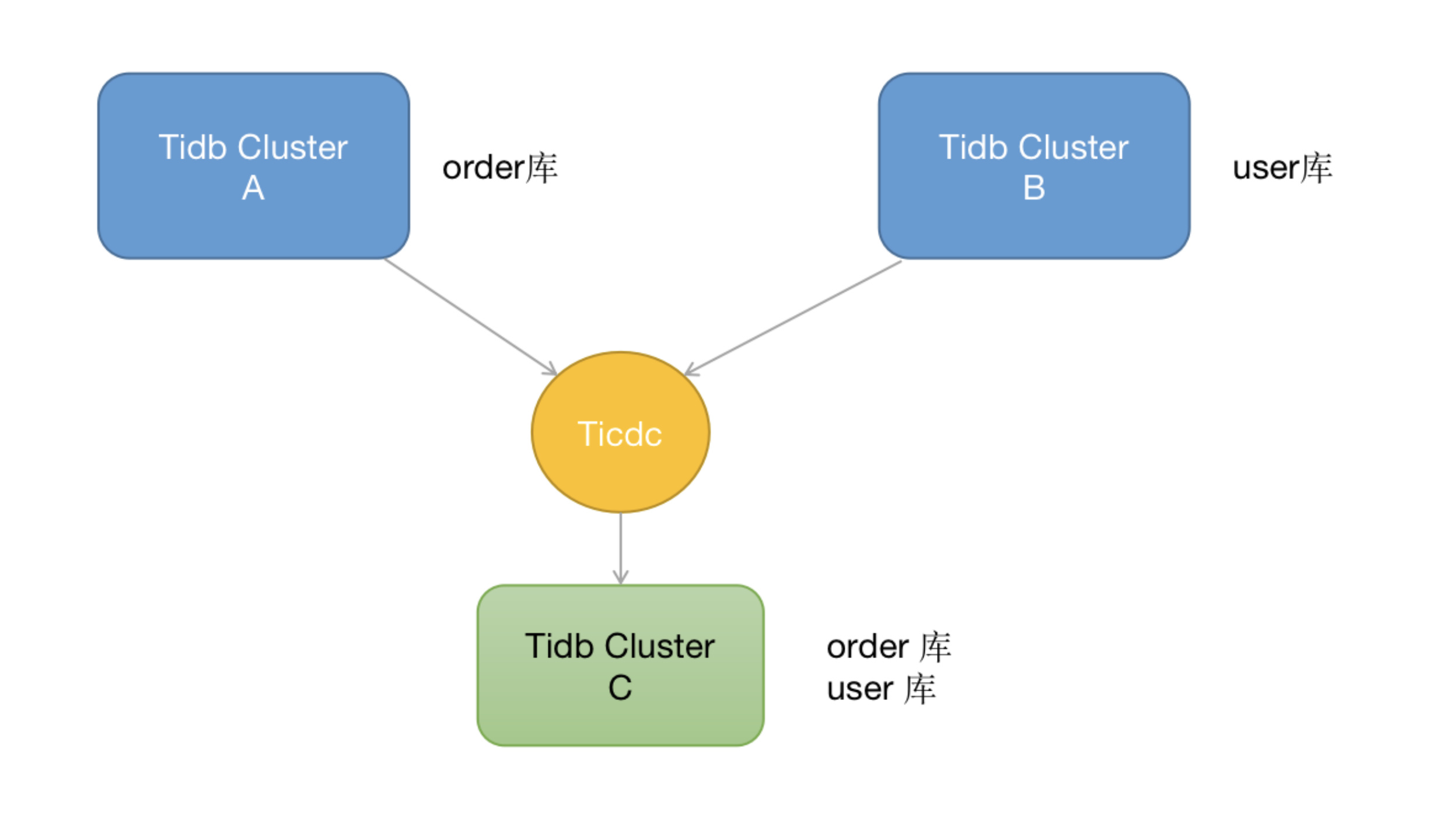
这种模式主要针对数据汇总场景,上游多个tidb 集群可以把自己的库表同步到下游c中,在c 中拥有上游AB集群的某些库表,在C中进行数据分析汇总
四 、 我想的备份恢复方案

我的想法是集群数据量特别大的话,可以跟业务协商只备份某些重要的表到备份集群B,小集群可以全备,同时设置备份B集群的gc 时间长一点,gc 设置时间变长会有旧版本积累,对应数据量会增大,对这个表进行查询更新会变慢,不过B集群没有对应的业务进行读写还好,当真的发生误操作的时候来快速恢复数据,高级权限必须做好限制,当然一般业务是没有drop/truncate 这些高危命令权限的
五、模拟误删除故障
版本:
Tidb 5.2.1
TICDC 5.2.1
假设出现误删除操作,前提已经创建好了TICDC,以truncate table test为例:
test 有一条数据2

同时设置备份集群B的GC 时间改为1h
set global tidb_gc_life_time=‘1h’;
#5.x 建议通过系统变量直接修改,之前版本通过 mysql.tidb这个表来更新,5.x也可以
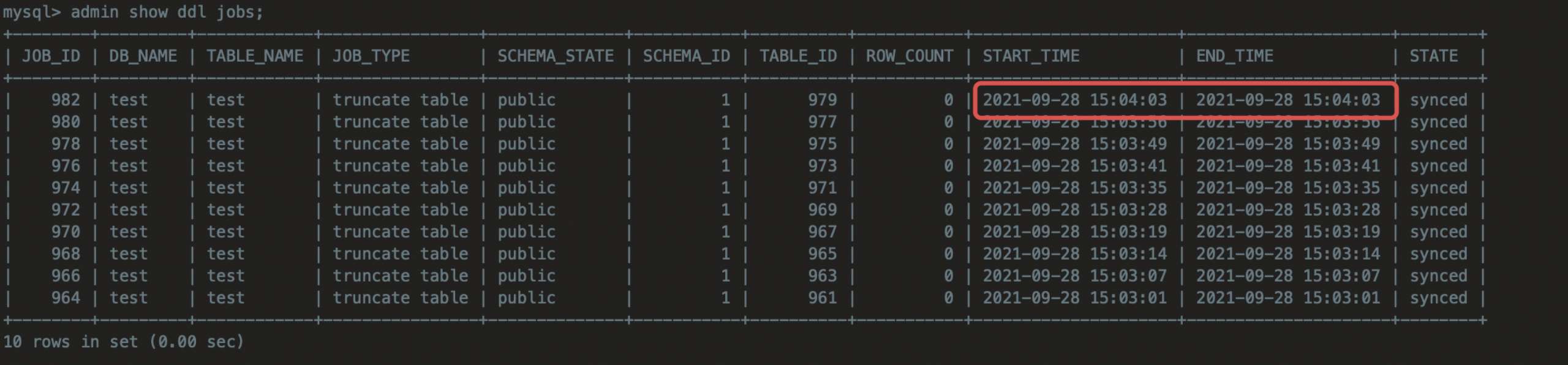
14:25 删除,等待超过10分钟,在15:04再去尝试恢复test 表
在A 集群执行 :
admin show ddl jobs;
#发现删除表的时间一直在实时更新…懵…感觉是集群应用来ticdc之后的bug,希望官方能测试下,不过现实中对具体误操作时间也是很难把握准,所以我们可以按照某个时间点依次尝试即可
A集群GC设置的时间是默认10分钟,15点的时候恢复早就过了GC时间所以产生如下提示

B集群执行:

此时我们就可以通过dumping 或者flahsback table 来恢复数据,具体恢复步骤可以参考海军这篇备份恢复文章还是比较全面的

读取历史数据 TiDB 使用 MVCC 管理版本,当更新/删除数据时,不会做真正的数据删除,只会添加一个新版本数据,所以可以保留历史数据。历史数据不会全部保留,超过一定时间的历史数据会被彻底删除,以减小空间占用以及避免历史版本过多引入的性能开销。 TiDB 使用周期性运行的 GC(Garbage Collection,垃圾回收)来进行清理,关于 GC 的详细介绍参见 TiDB 垃圾回收 (GC)…
注意!!!
以上方案目前是测试环境尝试的案例,生产还未上线,希望有实现的或者感觉有啥问题的多多交流下,非常感谢~