

https://blog.csdn.net/qq_22351805/article/details/113566849
本人博客原地址:TiDB调优小结
创作时间: 2020.12.25 19:03:42
TiDB概览
先来一段官网的描述


TiDB server: 无状态SQL解析层,支持二级索引,在线ddl,兼容MySQL协议,数据转储
SQL输入->解析语法树(AST)->逻辑计划分析->执行计划优化
->cost-base model->物理计划选择->计算下推tikv->聚合tikv执行结果
PD server: 协调层,存储集群元数据,region调度,事务时间戳TSO。存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,内置仪表盘dashboard.
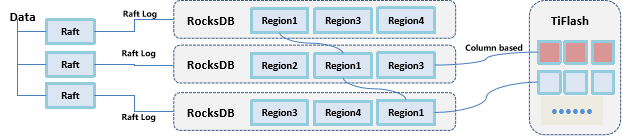
TiKV/TiFlash: 存储层,tikv行存储引擎,事务类处理走tikv;tiFlash列存储引擎,分析类处理走tiFlash。tikv,基于LSM算法的RocksDB单机Key-Value 存储引擎,TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。
tikv存储单位为region,关于region的介绍可以参考这里同时里面还有raft的相关介绍,目前最主要记住TIKV以 Region 为单位做 Raft 的复制和成员管理同时只需要同步复制到多数节点,即可安全地认为数据写入成功
特性:
易拓展:计算能力(TiDB)和存储能力(TiKV)均可水平拓展,但集群中只有一个PD能被选举为leader
高可用:TiDB/TiKV/PD 三大组件均可cluster模式部署
高效存储:基于LSM算法的RocksDB单机存储引擎,lz4、zstd等高效压缩算法,除了 RocksDB之外,TiDB 还支持一些流行的单机存储引擎,比如 GolevelDB、BoltDB 等
安全存储:采用Raft 协议复制数据,多副本防止单机失效
分布式事务:支持ACID事务,不同于XA,客户端调用无需设置数据源为xa,天然分布式事务
易用性:支持MySQL协议,使用MySQL语法,MySQL客户端均可直接连接登陆

因测试环境受限,我们的环境较多软硬件都不符合官方配置要求,啊哈哈哈。。。但这并不影响我们对技术的研究和使用,再穷也要创造条件顶硬上。
##一、部署环境
| 对比项 | 官方配置 | 实际配置 |
|---|---|---|
| 操作系统 | Red Hat Enterprise Linux7.3 及以上 | Red Hat 4.8.5-36 |
| 硬盘 | 部分组件ssd,部分组件sas | 机械硬盘raid |
其余硬件,实际部署环境CPU 8核,内存16G,千兆网卡。
官网推荐如下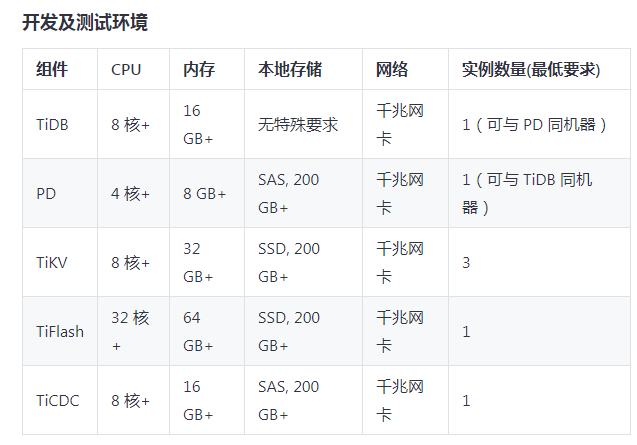
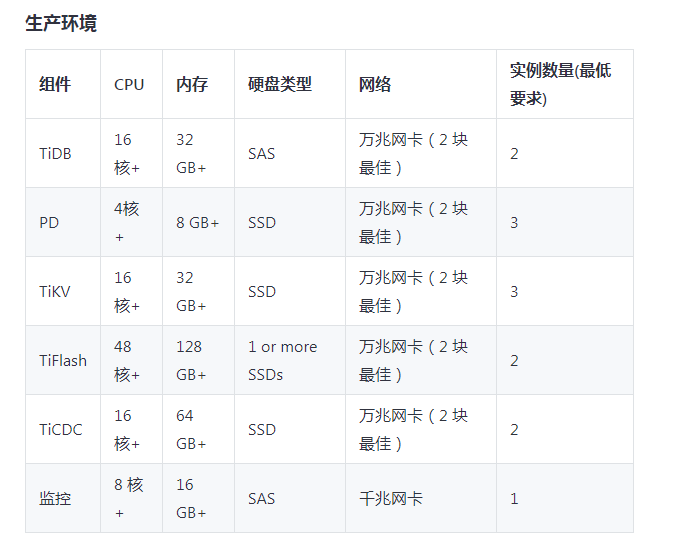
TiDB 和 PD 可以部署在同一台服务器上。
如对性能和可靠性有更高的要求,应尽可能分开部署。
官网参考
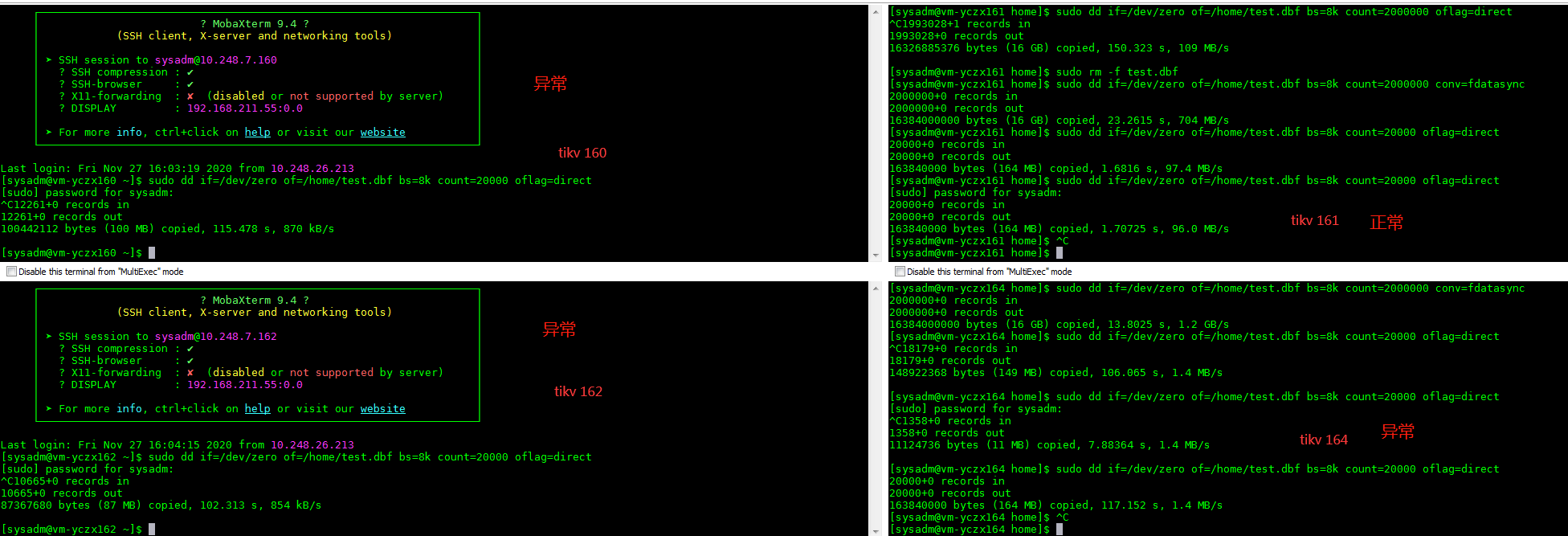
虽然实际测试环境,使用的raid挂载的是机械硬盘,但是读写能力并不弱,dd指令数据如下:
本次使用主机11台(10.248.7.154-164)

二、拓扑
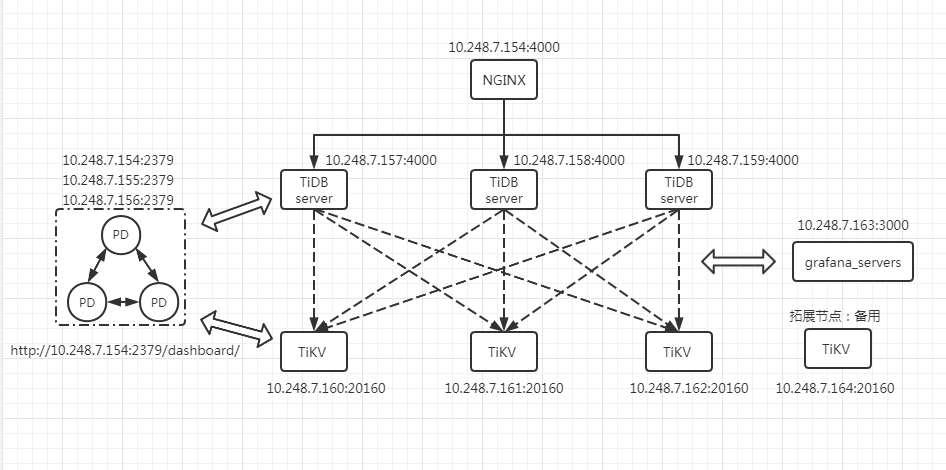
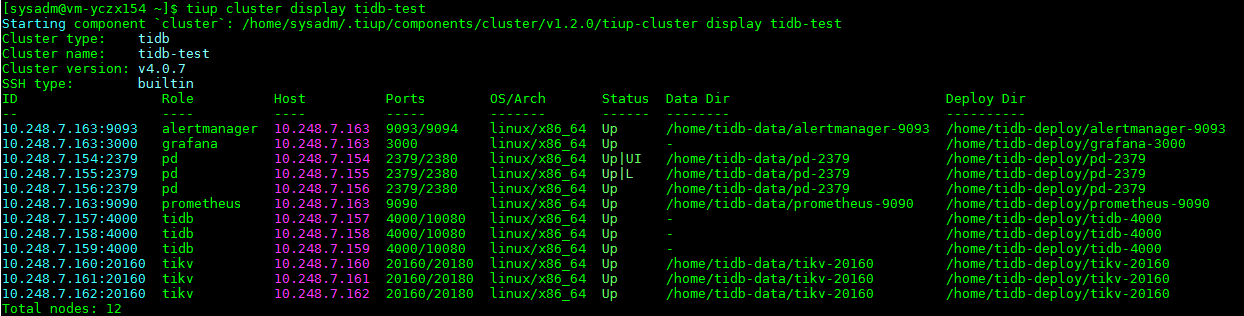
查看集群状态
tiup cluster display tidb-test
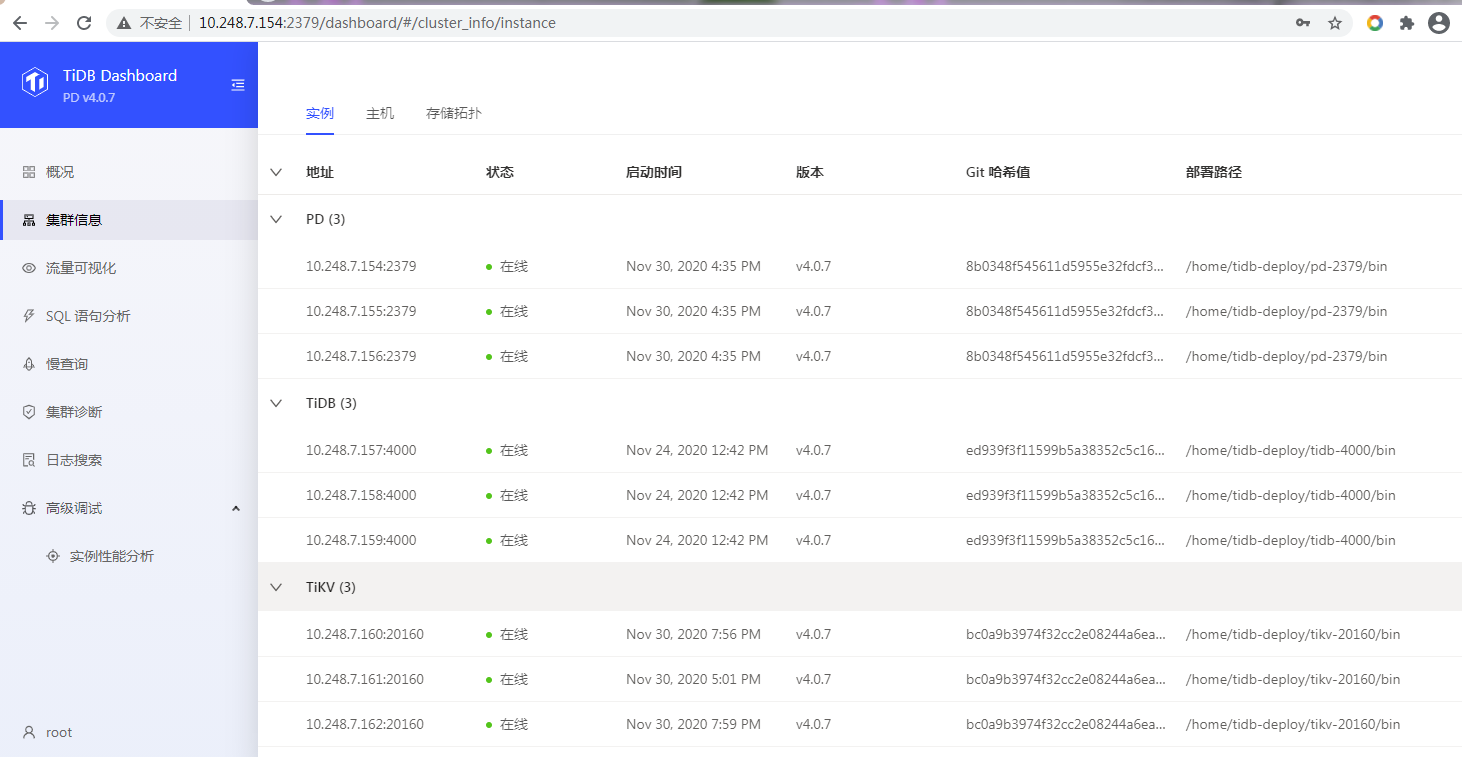
当然还有更直观的仪表盘(PD内置,访问PD服务http:ip+port/dashboard).也可以先在部署TiUP的机器执行 tiup cluster display tidb-test --dashboard得到,即
使用数据库用户root登陆
还可以使用额外部署的grafana:http://10.248.7.163:3000


三、测试与优化
场景:大文件,多文件数据入库,入库首先保证速度,最终一致即可(CAP中的AP)文件有备份,可重新入库。入库后简单OLAP操作。
测试准备:入库应用(可配置单次入库记录数),500万行数据文件(写成6个文件)
这里先来说一个异常场景,这个场景刚好可以对比磁盘性能差异引起的tidb性能差异,同时对理解热点问题和对应调优有一定帮助。
在最开始压测的时候,tikv节点的三台主机(raid 22块磁盘),其中有两台主机raid cache电池故障,导致raid cache失效,这两台主机的IO性能严重受影响
当然,在测试的时候,事先是并不知道这个问题的,并在此基础上做了一些研究和调优。接下来简要说下过程(以下过程均访问单个TiDB-server):
1、首次压测(单批次5000行记录,5线程)
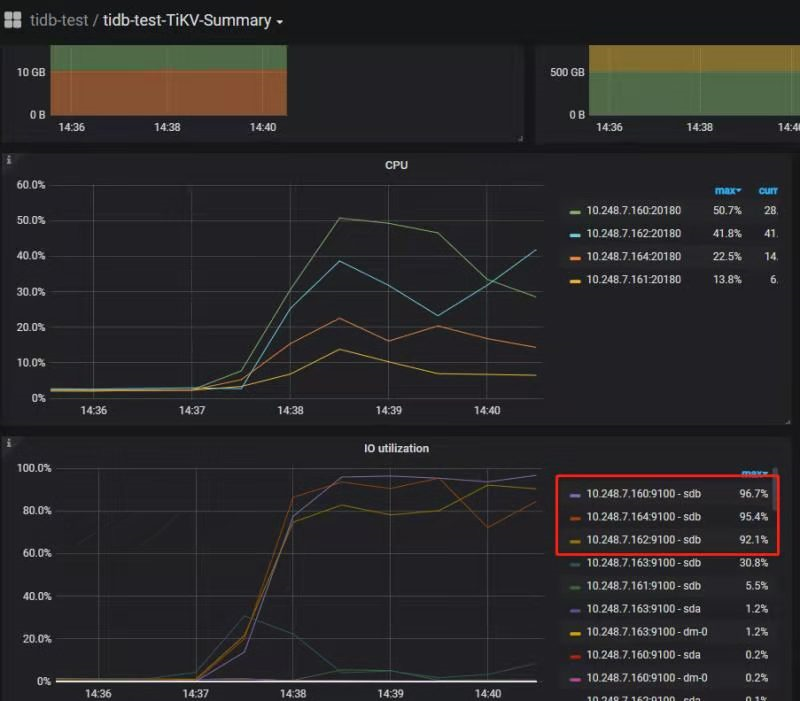
由于扩展tikv前的图已丢失(现raid电池问题已修复,无法重现),只能贴上4tikv的图了,不过除了加多一个节点,现象差不多,后面再做扩缩容的演示
由图可以看出,除了正常的161外,其余的tikv节点,IO均已跑满(163为应用部署主机)。考虑两点,磁盘性能差异、region分布不均匀。
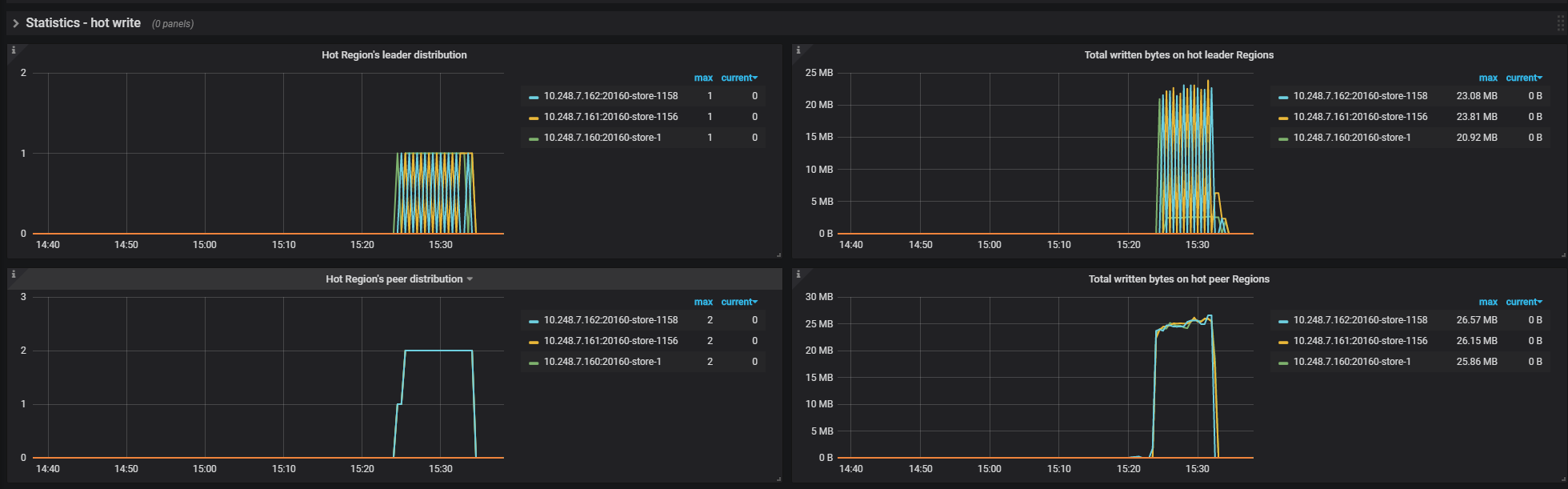
再来看下热点region的图:
可以看出,hot region leader的分布非常不均匀。以三副本(peer)为例,根据raft协议,当写入时,首先写入到region leader,写完leader之后再同步拷贝到其余两个节点的region follower 参考官网说明。这里就考虑两个热点部分不均匀的可能:1、单批次提交事务过大,导致同一时间内数据集中在一个region,在未超过一定大小时(默认 96M)并没有分裂region;2、主键有序程度高,导致排序分裂region时,数据在region中比较集中。
入库结果:
平均一百万行需要6-7分钟。从文件数据看,先慢后快,这跟初始化时只有单个region有关,只有达到单个region限制后才会分裂。参考这里可先不对此过度优化。
2、第二次压测(单批次2000行记录,10线程)
基于第一次的压测结果,修改单批次提交记录数,并加大线程分散提交的事务。修改后tikv节点的IO使用率并无太多变化。入库速度略有上升:
3、第三次压测(单批次2000行记录,10线程,乱序)
在修改了批次大小后,继续修改使主键乱序,同上,IO使用率依旧没有多大变化。不过入库速度有较大提升(平均一百万3分钟):
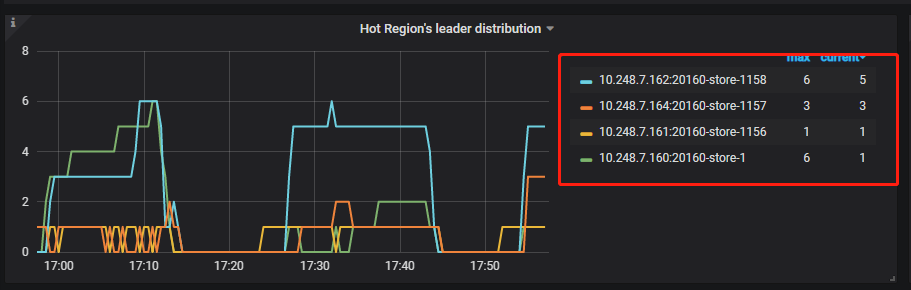


经此两次调整后,region leader热点已分布比较均匀: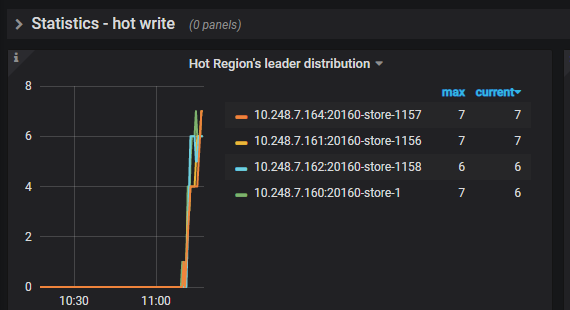
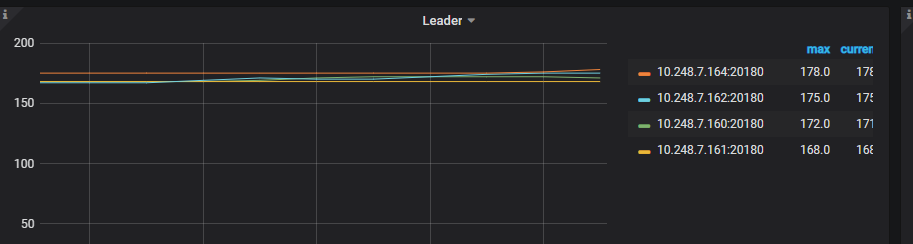
到目前为止,一直忽略了一个事情,没有观察总的region leader情况:
从图看,总的leader分布是很均匀的,且写入字节总量各个tikv节点也大致相同,但是hot leader为什么这么不均匀而且为什么其中一个tikv IO使用率低这么多呢,矛头指向了磁盘性能问题,经排查后发现,磁盘电池故障,raid cache失效。
4、第四次压测(单批次2000行记录,10线程,乱序,sync-log = false)
在磁盘问题修复前,我们找到一处关于sync-log的说明
以三副本为例,需要至少写完两个副本之后,才能向客户端返回ack。因此关闭同步日志,异步写follower的副本,相当于写单机的时间。这里牺牲了CAP中的C,只需最终一致即可。我们的应用场景适用,同时我们文件有备份,即便出错可以重新导入。但是对于实时性较强,对一致性要求较高的金融场景,不建议关闭同步日志。
操作需使用Tiup:
执行tiup cluster edit-config tidb-test修改完成后执行:tiup cluster reload tidb-test -R tikv 重启tikv
修改后入库效率如下:
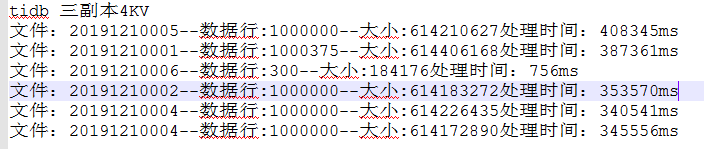
一百万行记录入库时间优化到2分钟。


不过在修复磁盘后发现,这个参数在我们的场景影响并不是很大,良好的io性能使得这个参数设置变得不那么重要,因此在修复磁盘后的测试中,我们都是基于开启同步日志的场景
修复磁盘后测试
修复后的tikv 磁盘性能均有如下表现:
修复磁盘后,我们测试的条件为:3TiKV3副本,单批次2000行记录,10线程,乱序。恢复同步日志配置的修改。
来看下修复后的TiDB表现:
hot region leader 均匀分布,peer(副本)也是均匀分布
入库效率如下(平均100万行记录1.5分钟):
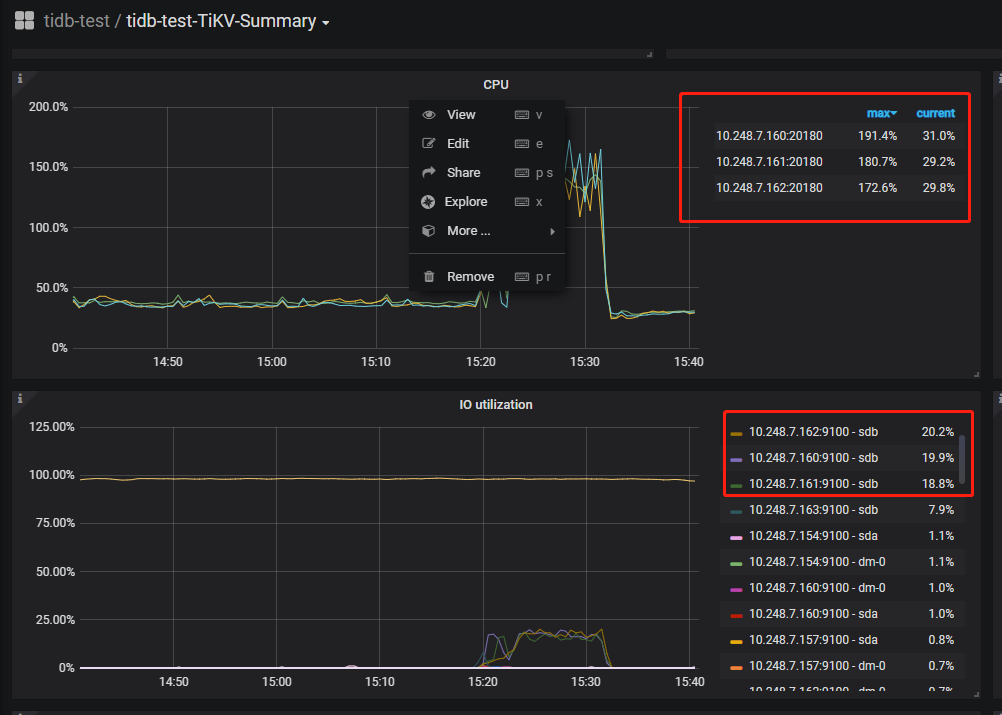
直觉告诉我们,事情肯定还没有结束,应该还有优化的空间。似乎到目前为止,我们都没有好好看看TiDB-server的情况:
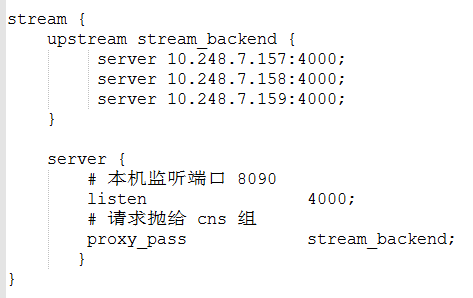
到目前为止,我们都是直接访问单个的TiDB-server。因此出现了如图的CPU负载情况,只有157的tidb CPU快到7个核的使用率。由于tidb-server是无状态的,可以通过负载来给另外两个tidb-server分活了。本例使用NGINX,配置如下:
修改访问地址,客户端通过连接NGINX访问tidb 10.248.7.154:4000
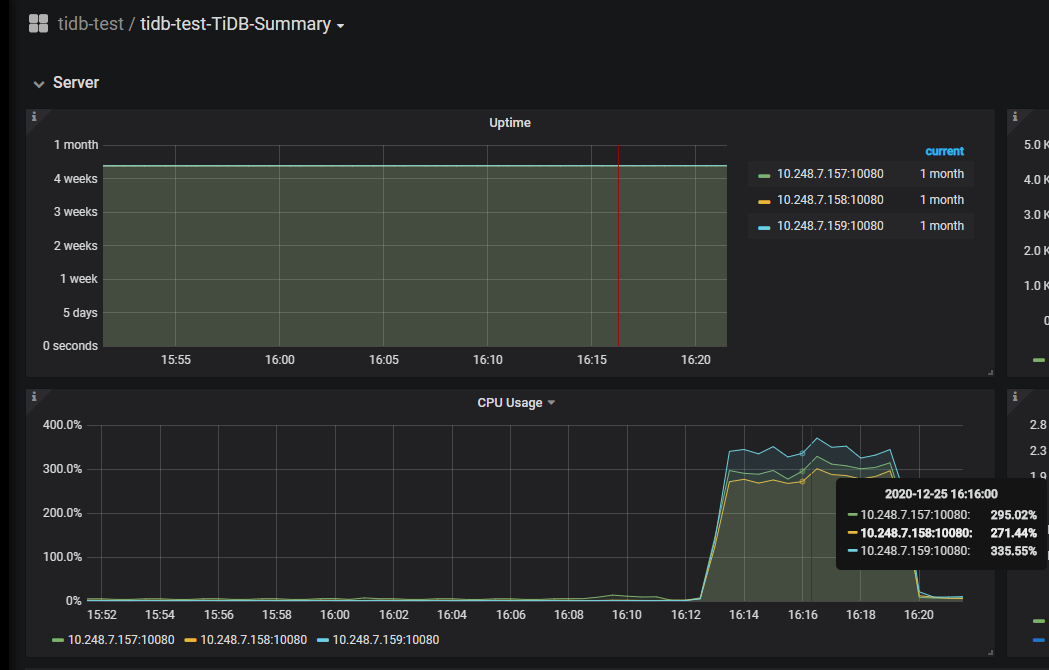
通过NGINX负载后,每个tidb-server的cpu都得到了利用,同时平均一百万行记录入库时间优化到1分钟。




按照对官方文档的理解,tidb的计算能力和存储能力都可以扩展,目前我们通过NGINX负载实现了tidb-server计算能力的负载。但是计算不仅仅在tidb-server。tidb-server 解析SQL生成执行计划之后,会有一部分的计算下推到tikv。这也是为何tikv和tidb 这两个组件的实例不能部署在同一台主机。那么扩充tikv节点后,性能会有多大程度提高?另外扩充的节点会不会自动协调原有节点的region呢?
扩展tikv节点
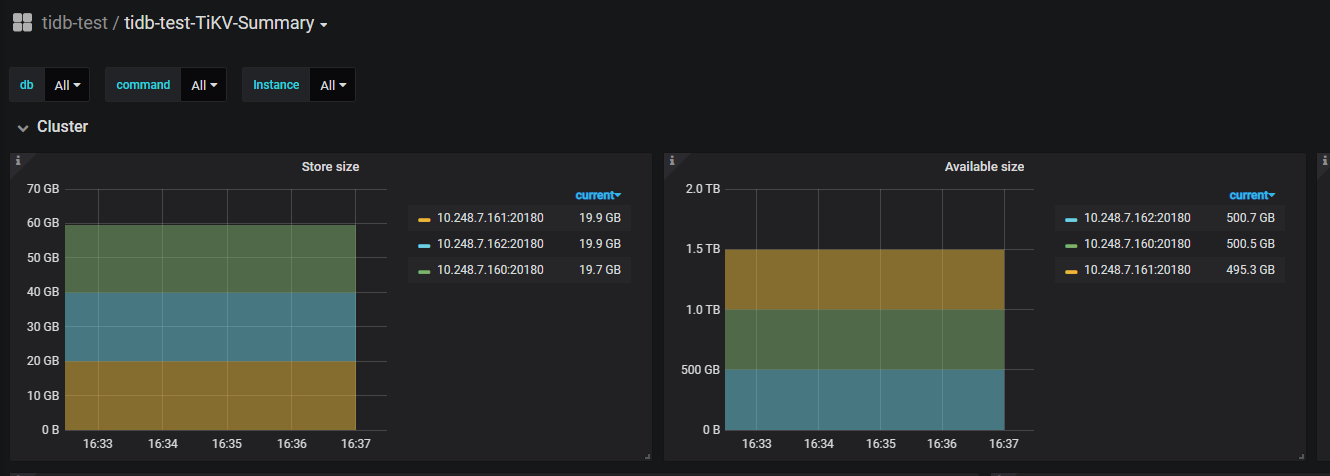
扩展前,肯定要先看看原有的磁盘占用情况:
扩容过程中,正逐渐转移数据到新的tikv节点。稳定后如下图:
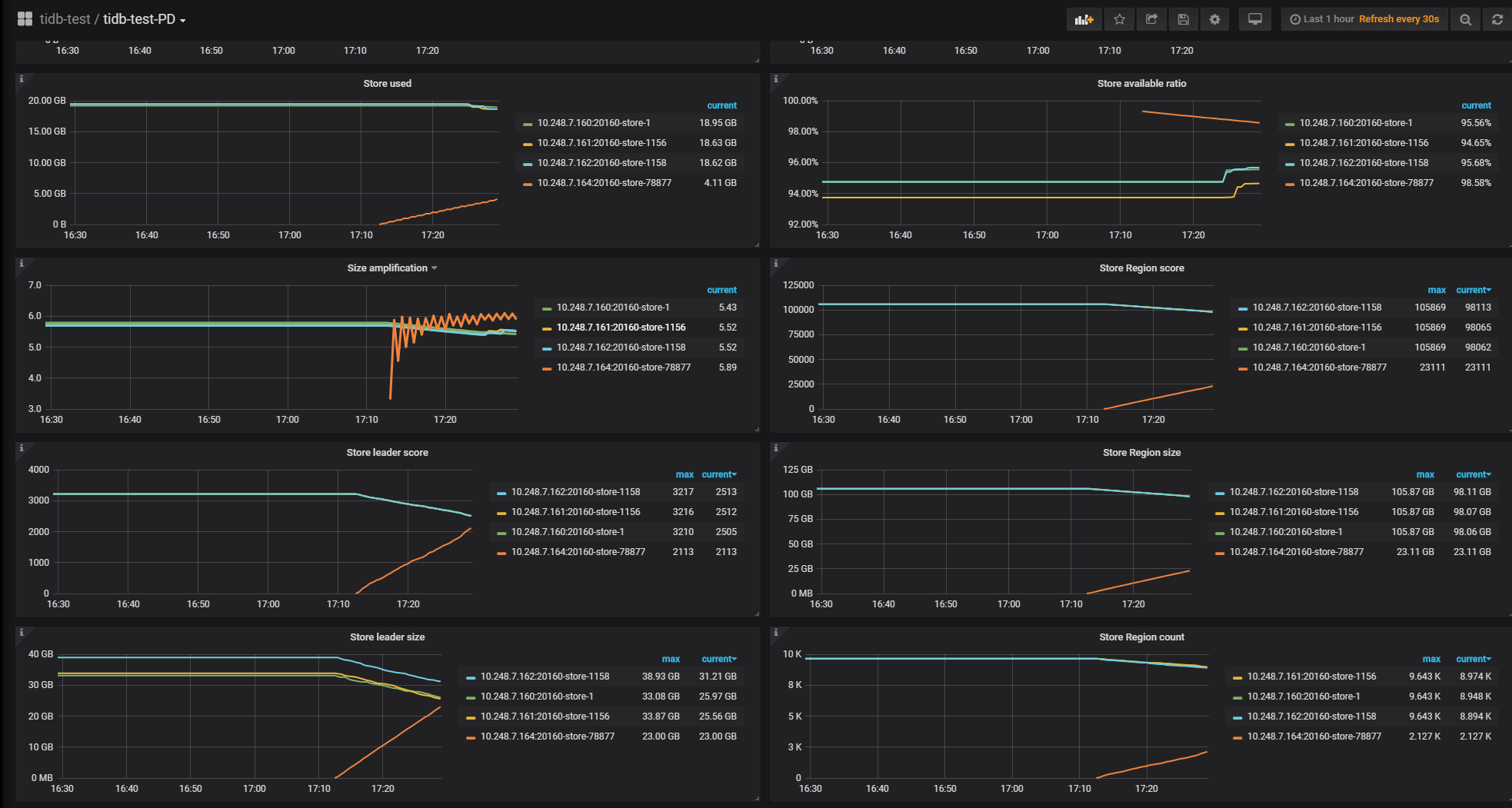
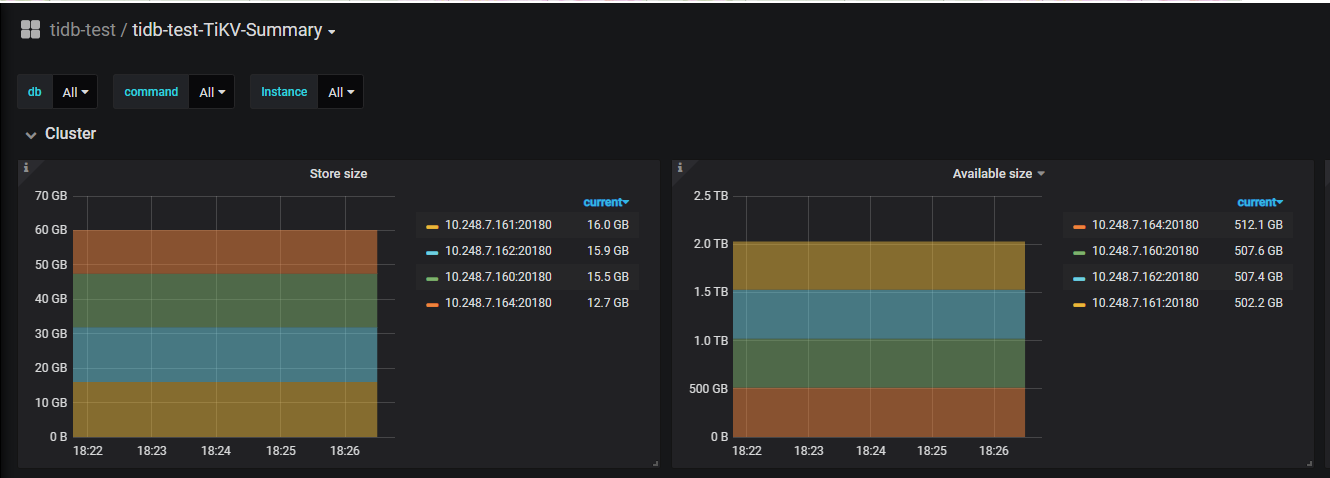
不过在入库效率上,提升并不明显,时间上和扩容前相差不多。有以下原因,原本的三节点并行入库性能还有较多可利用空间,相当于只是把部分处理迁移到新节点,单原先节点的处理能力还有很多富余,需要原先的节点IO和CPU有较高使用率时,扩充节点才能有较多的性能提升region调度策略
CPU和IO使用率都不大。
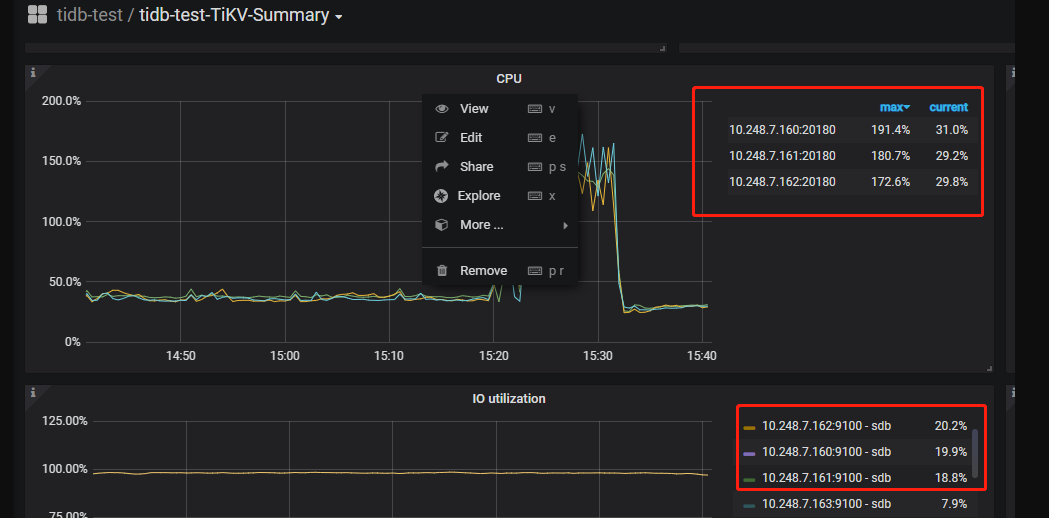
同等主机环境的MySQL入库情况如下:
在主键无序的情况下,随着数据量的增大,入库性能急剧下滑,这跟索引树叶子节点在主键无序时,频繁分裂调整树结构有关。主键有序时,入库性能中 规中矩,不过即便是有序,在数据量多了以后,入库性能也会下滑。所以MySQL单表有大小要求,超过一定大小之后最好选择分库分表,但是这也会引入另外的问题,业务应用测也要对此做大量的改造。
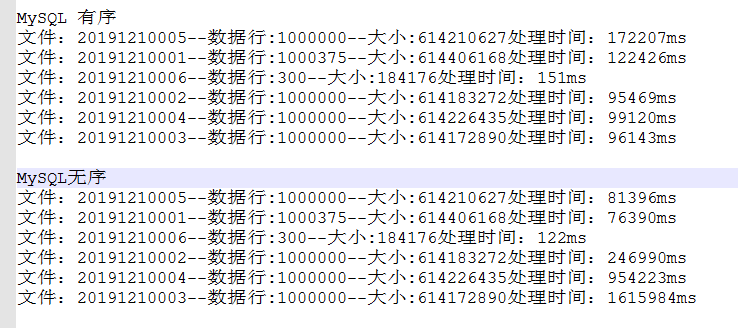
同等主机环境MySQL与tidb查询性能对比:
当前分区500万行记录查询,查询SQL
select SETTLE_DATE AS "账期日",COUNT(0) AS 成功条数,SUM(JSON_EXTRACT(JSON,'$.Payment')) AS 成功总金额(分)
FROM BL_BATCH_TEST TDP
WHERE TDP.SETTLE_DATE = '20201201' and JSON_EXTRACT(JSON,'$.IsSuccess') = '0' and JSON_EXTRACT(JSON,'$.Result') = '0' group by SETTLE_DATE;

TIDB
mysql
(mysql的数据同事帮我跑的,啊哈哈)
对比来看,tidb查询性能较为稳定,即便重启所有组件清楚缓存后(图中第二次查询 ),单个分区500万行记录,查询8s,再次查询时间减半,MySQL第一次查询耗时80+s,第二次查询也能维持较好的性能。通常业务查询(OLAP),最重要的是首次时间,第二次的查询时间参考意义不大,因此稳定的查询时间尤为重要。MySQL和tidb在重启后,首次查询时间都相对要久一点,这跟加载磁盘数据到内存耗费有关,tikv几个节点堆起来的内存跟MySQL单机的内存比,是不太公平的,但这也正是tidb的优势。



总结:
1、TiDB-server是计算密集型组件,同时也会将部分计算下推到TiKV,而TiKV是IO密集型组件,因此TiDB和TiKV不能在同一台主机部署。PD存储元数据会频繁写磁盘,对磁盘IO要求高,因此也不能和TiKV同部署,PD可以和TiDB-server同主机部署。
2、TiKV (集成raft协议)以region为存储单位,超过默认96M后会分裂,通过raft协议做leader选举和副本(即peer)复制,每个region都会有leader 副本,其余的副本为follower,客户端读写只会通过region的leader节点,写入时,写完leader后再复制到follower,超半数以上副本写入完成即认为写入成功。
增减tikv节点,或者修改replication.max-replicas后,PD会通过region的心跳判断当前副本情况,从而调度副本到新节点或者增减副本。
3、通过grafana和PD自带的dashBoard可以实时查看当前系统的问题,比如TIDB节点的CPU使用率、QPS;TIKV节点的CPU、IO使用率;通过PD查看热点分布和region分布于调度情况;通过PD 的dashBoard查看慢sql,集群状态,调用栈火焰图等等。
CPU使用率单核不要超过80%,超过不管是TIDB节点和TIKV都要考虑扩容
tikv节点内存不要超过60%使用率,IO达到80%可视为到达瓶颈
4、region数量单个tikv小于50K, grpc延迟尽可能小于100ms。过多的region会导致调度频繁影响性能,grpc延迟增大。可考虑设置region合并参数
以下配置意为:key数目小于200000,region大小小于20M的合并(默认)
set config pd `schedule.max-merge-region-keys`=200000;
set config pd `schedule.max-merge-region-size`=20;
5、当TIDB节点CPU过高时,如是正常SQL执行需要,可考虑增加TIDB节点,并通过Nginx,HaProxy等负载工具分发到不同节点执行。当Tikv 出现较高水平的cpu使用率或者IO使用率,可考虑增加TiKV节点。TiKV对磁盘要求较高,尽量使用SSD磁盘,或者多磁盘raid。
6、出现热点region的时候,有几个地方可以查看,比如grafana监控中的PD可以看相关的hot region分布情况,这是最直观的方式;还可以通过监控中的tikv,查看各节点CPU和IO使用情况,当出现热点问题是,这两个指标在各个节点时很不均匀的,尤其THread cpu的corprocessor 或 scheduler(负责读/写模块的线程)。
7、解决热点region的问题,主要在于分散region数据的分布,减少频繁读写同一个region。通过减少单批次提交记录数(小事务),非自增乱序的主键(官网要求int类型的主键。5.0之后将支持vchar),频繁访问相同数据通过内存访问,从业务层面拆分热点数据等手段减少热点。但在所有的tikv都出现较多热点region时,这时应考虑扩充tikv节点。当tikv节点region分布不均匀,CPU和IO使用率不均匀时,还应考虑硬件性能问题,部分硬件性能会影响整体系统性能。
8、RocksDB默认使用snappy压缩算法,不过TiKV有分层使用压缩算法,默认[“no”, “no”, “lz4”, “lz4”, “lz4”, “zstd”, “zstd”]当数据量超过 500G 时 RocksDB 的层数才会超过 4, 超过 500G 部分的数据才会启动 ZSTD 压缩算法。lz4解压缩速度及压缩比都优于snappy;ZSTD压缩比更高,解压缩比lz4慢,适合层级高的老数据。
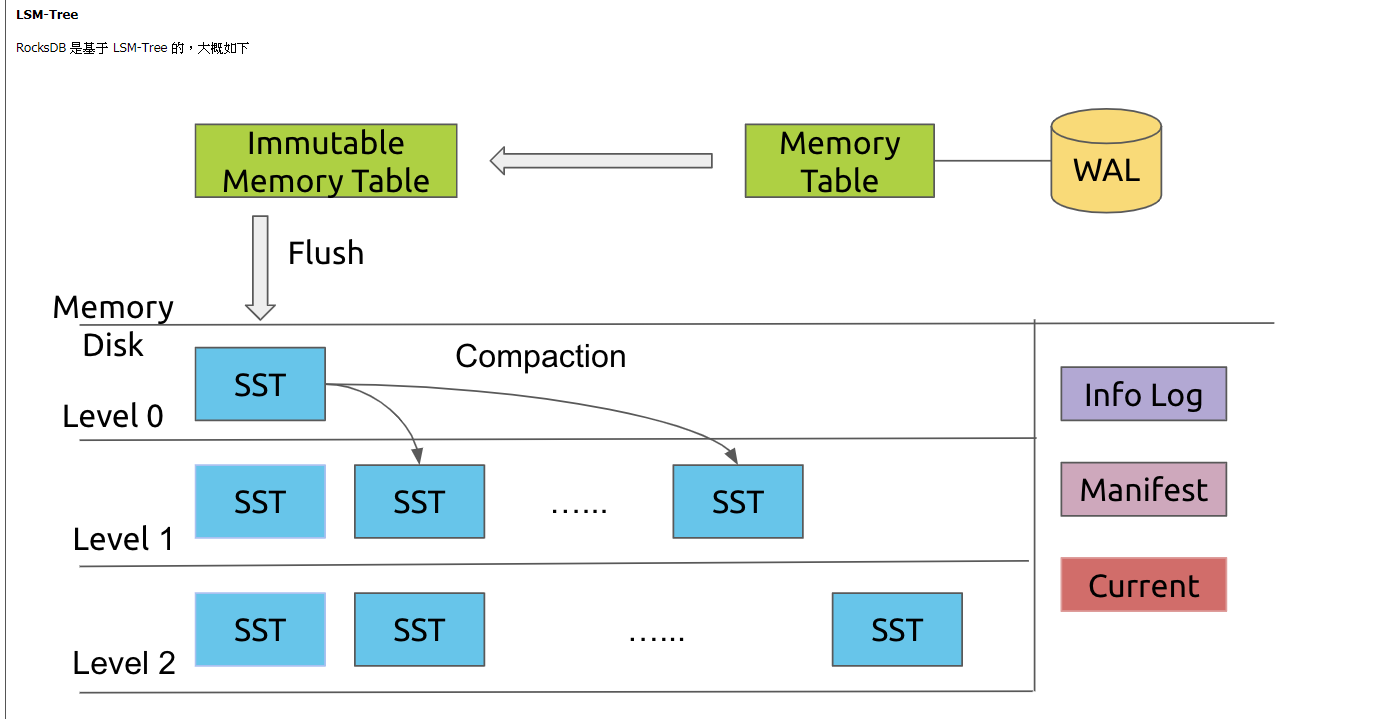
9、RocksDB的LSM树,
如图:wal相当于MySQL 的redo log。从wal->menorytable(可修改Memtable–》不可修改immutable Memtable)->SST,读放大和写放大问题都会存在,写放大在于sst逐渐往下compact(异步线程);而读放大在于需要逐层查找,且层数越往下,压缩率越高,效率越低。
10、理论上,tidb-server节点和tikv节点都可以无限扩充,但是PD整个集群只能有一个leader,因此扩充能力受限于PD节点的处理能力,此外网络带宽也是限制因素之一。
未完待续…
raft算法与分布式事务percolator、两阶段提交
raft算法笔记
为何使用kv存储引擎
两个tidb集群间实时同步(异地双中心双活)
参考资料
TiDB官网
官网FAQ
TiDB in action
在线修改配置,非持久化配置
LSM && RocksDB compaction策略
RocksDB解析
region调度策略
TiDB 高并发写入场景最佳实践
TiDB 热点问题处理
海量 Region 集群调优
Percolator 和 TiDB 事务算法
TiDB 集群推荐使用 SSD 的原因